HanLP《自然语言处理入门》笔记--9.关键词、关键句和短语提取
文章目录
-
- 9. 信息抽取
-
- 9.1 新词提取
- 9.2 关键词提取
- 9.3 短语提取
- 9.4 关键句提取
- 9.5 总结
- 9.6 GitHub
笔记转载于GitHub项目:https://github.com/NLP-LOVE/Introduction-NLP
9. 信息抽取
信息抽取是一个宽泛的概念,指的是从非结构化文本中提取结构化信息的一类技术。这类技术依然分为基于规则的正则匹配、有监督学习和无监督学习等各种实现方法。我们将使用一些简单实用的无监督学习方法。由于不需要标注语料库,所以可以利用海量的非结构化文本。
本章按照颗粒度从小到大的顺序,介绍抽取新词、关键词、关键短语和关键句的无监督学习方法。
9.1 新词提取
-
概述
新词是一个相对的概念,每个人的标准都不一样,所以我们这里定义: 词典之外的词语(OOV)称作新词。
新词的提取对中文分词而言具有重要的意义,因为语料库的标注成本很高。那么如何修订领域词典呢,此时,无监督的新词提取算法就体现了现实意义。
-
基本原理
- 提取出大量文本(生语料)中的词语,无论新旧。
- 用词典过滤掉已有的词语,于是得到新词。
步骤 2 很容易,关键是步骤 1,如何无监督的提取出文本中的单词。给定一段文本,随机取一个片段,如果这个片段左右的搭配很丰富,并且片段内部成分搭配很固定,则可以认为这是一个词。将这样的片段筛选出来,按照频次由高到低排序,排在前面的有很高概率是词。
如果文本足够大,再用通用的词典过滤掉“旧词”,就可以得到“新词”。
片段外部左右搭配的丰富程度,可以用信息熵来衡量,而片段内部搭配的固定程度可以用子序列的互信息来衡量。
-
信息熵
在信息论中,信息熵( entropy )指的是某条消息所含的信息量。它反映的是听说某个消息之后,关于该事件的不确定性的减少量。比如抛硬币之前,我们不知道“硬币正反”这个事件的结果。但是一旦有人告诉我们“硬币是正面”这条消息,我们对该次抛硬币事件的不确定性立即降为零,这种不确定性的减小量就是信息熵。公式如下:
H ( X ) = − ∑ x p ( x ) log p ( x ) H(X)=-\sum_{x} p(x) \log p(x) H(X)=−x∑p(x)logp(x)
给定字符串 S 作为词语备选,X 定义为该字符串左边可能出现的字符(左邻字),则称 H(X) 为 S 的左信息熵,类似的,定义右信息熵 H(Y),例如下列句子:两只蝴蝶飞啊飞
这些蝴蝶飞走了
那么对于字符串蝴蝶,它的左信息熵为1,而右信息熵为0。因为生语料库中蝴蝶的右邻字一定是飞。假如我们再收集一些句子,比如“蝴蝶效应”“蝴蝶蜕变”之类,就会观察到右信息熵会增大不少。
左右信息熵越大,说明字符串可能的搭配就越丰富,该字符串就是一个词的可能性就越大。
光考虑左右信息熵是不够的,比如“吃了一顿”“看了一遍”“睡了一晚”“去了一趟”中的了一的左右搭配也很丰富。为了更好的效果,我们还必须考虑词语内部片段的凝聚程度,这种凝聚程度由互信息衡量。
-
互信息
互信息指的是两个离散型随机变量 X 与 Y 相关程度的度量,定义如下:
I ( X ; Y ) = ∑ x , y p ( x , y ) log p ( x , y ) p ( x ) p ( y ) = E p ( x , y ) log p ( x , y ) p ( x ) p ( y ) \begin{aligned} I(X ; Y) &=\sum_{x, y} p(x, y) \log \frac{p(x, y)}{p(x) p(y)} \\ &=E_{p(x, y)} \log \frac{p(x, y)}{p(x) p(y)} \end{aligned} I(X;Y)=x,y∑p(x,y)logp(x)p(y)p(x,y)=Ep(x,y)logp(x)p(y)p(x,y)
互信息的定义可以用韦恩图直观表达: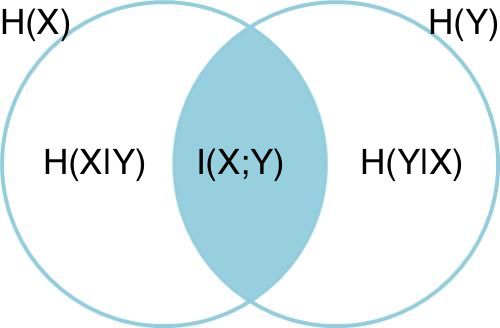
其中,左圆圈表示H(X),右圆圈表示H(Y)。它们的并集是联合分布的信息熵H(X,Y),差集有多件嫡,交集就是互信息。可见互信息越大,两个随机变量的关联就越密切,或者说同时发生的可能性越大。
片段可能有多种组合方式,计算上可以选取所有组合方式中互信息最小的那一种为代表。有了左右信息熵和互信息之后,将两个指标低于一定阈值的片段过滤掉,剩下的片段按频次降序排序,截取最高频次的 N 个片段即完成了词语提取流程。
-
实现
我们用四大名著来提起100个高频词。
代码请见(语料库自动下载): extract_word.py
https://github.com/NLP-LOVE/Introduction-NLP/tree/master/code/ch09/extract_word.py
运行结果如下:
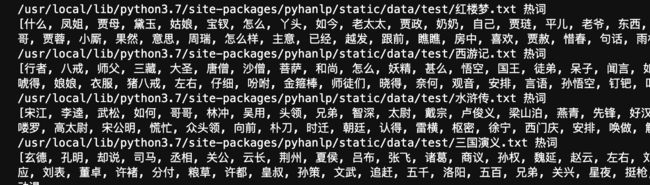
虽然我们没有在古典文学语料库上进行训练,但新词识别模块成功的识别出了麝月、高太尉等生僻词语,该模块也适用于微博等社交媒体的不规范文本。
9.2 关键词提取
词语颗粒度的信息抽取还存在另一个需求,即提取文章中重要的单词,称为关键词提起。关键词也是一个没有定量的标准,无法统一语料库,所以就可以利用无监督学习来完成。
分别介绍词频、TF-IDF和TextRank算法,单文档提起可以用词频和TextRank,多文档可以使用TF-IDF来提取关键词。
-
词频统计
关键词通常在文章中反复出现,为了解释关键词,作者通常会反复提及它们。通过统计文章中每种词语的词频并排序,可以初步获取部分关键词。
不过文章中反复出现的词语却不一定是关键词,例如“的”。所以在统计词频之前需要去掉停用词。
词频统计的流程一般是分词、停用词过滤、按词频取前 n 个。其中,求 m 个元素中前 n (n<=m) 大元素的问题通常通过最大堆解决,复杂度为 O(mlogn)。HanLP代码如下:
from pyhanlp import * TermFrequency = JClass('com.hankcs.hanlp.corpus.occurrence.TermFrequency') TermFrequencyCounter = JClass('com.hankcs.hanlp.mining.word.TermFrequencyCounter') if __name__ == '__main__': counter = TermFrequencyCounter() counter.add("加油加油中国队!") # 第一个文档 counter.add("中国观众高呼加油中国") # 第二个文档 for termFrequency in counter: # 遍历每个词与词频 print("%s=%d" % (termFrequency.getTerm(), termFrequency.getFrequency())) print(counter.top(2)) # 取 top N # 根据词频提取关键词 print('') print(TermFrequencyCounter.getKeywordList("女排夺冠,观众欢呼女排女排女排!", 3))运行结果如下:
中国=2 中国队=1 加油=3 观众=1 高呼=1 [加油=3, 中国=2] [女排, 观众, 欢呼]用词频来提取关键词有一个缺陷,那就是高频词并不等价于关键词。比如在一个体育网站中,所有文章都是奥运会报道,导致“奥运会”词频最高,用户希望通过关键词看到每篇文章的特色。此时,TF-IDF 就派上用场了。
-
TF-IDF
TF-IDF (Term Frequency-lnverse Document Frequency,词频-倒排文档频次)是信息检索中衡量一个词语重要程度的统计指标,被广泛用于Lucene、Solr、Elasticsearch 等搜索引擎。
相较于词频,TF-IDF 还综合考虑词语的稀有程度。在TF-IDF计算方法中,一个词语的重要程度不光正比于它在文档中的频次,还反比于有多少文档包含它。包含该词语的文档趣多,就说明它越宽泛, 越不能体现文档的特色。 正是因为需要考虑整个语料库或文档集合,所以TF-IDF在关键词提取时属于多文档方法。
计算公式如下:
T F − IDF ( t , d ) = T F ( t , d ) D F ( t ) = T F ( t , d ) ⋅ I D F ( t ) \begin{aligned} \mathrm { TF } - \operatorname { IDF } ( t , d ) & = \frac { \mathrm { TF } ( t , d ) } { \mathrm { DF } ( t ) } \\ & = \mathrm { TF } ( t , d ) \cdot \mathrm { IDF } ( t ) \end{aligned} TF−IDF(t,d)=DF(t)TF(t,d)=TF(t,d)⋅IDF(t)
其中,t 代表单词,d 代表文档,TF(t,d) 代表 t 在 d 中出现频次,DF(t) 代表有多少篇文档包含 t。DF 的导数称为IDF,这也是 TF-IDF 得名的由来。当然,实际应用时做一些扩展,比如加一平滑、IDF取对数以防止浮点数下溢出。HanLP的示例如下:
from pyhanlp import * TfIdfCounter = JClass('com.hankcs.hanlp.mining.word.TfIdfCounter') if __name__ == '__main__': counter = TfIdfCounter() counter.add("《女排夺冠》", "女排北京奥运会夺冠") # 输入多篇文档 counter.add("《羽毛球男单》", "北京奥运会的羽毛球男单决赛") counter.add("《女排》", "中国队女排夺北京奥运会金牌重返巅峰,观众欢呼女排女排女排!") counter.compute() # 输入完毕 for id in counter.documents(): print(id + " : " + counter.getKeywordsOf(id, 3).toString()) # 根据每篇文档的TF-IDF提取关键词 # 根据语料库已有的IDF信息为语料库之外的新文档提取关键词 print('') print(counter.getKeywords("奥运会反兴奋剂", 2))运行后如下:
《女排》 : [女排=5.150728289807123, 重返=1.6931471805599454, 巅峰=1.6931471805599454] 《女排夺冠》 : [夺冠=1.6931471805599454, 女排=1.2876820724517808, 奥运会=1.0] 《羽毛球男单》 : [决赛=1.6931471805599454, 羽毛球=1.6931471805599454, 男单=1.6931471805599454] [反, 兴奋剂]观察输出结果,可以看出 TF-IDF 有效的避免了给予“奥运会”这个宽泛的词语过高的权重。
TF-IDF在大型语料库上的统计类似于一种学习过程,假如我们没有这么大型的语料库或者存储IDF的内存,同时又想改善词频统计的效果该怎么办呢?此时可以使用TextRank算法。
-
TextRank
TextRank 是 PageRank 在文本中的应用,PageRank是一种用于排序网页的随机算法,它的工作原理是将互联网看作有向图,互联网上的网页视作节点,节点 Vi 到节点 Vj 的超链接视作有向边,初始化时每个节点的权重 S(Vi) 都是1,以迭代的方式更新每个节点的权重。每次迭代权重的更新表达式如下:
S ( V i ) = ( 1 − d ) + d × ∑ V j ∈ I n ( V i ) 1 ∣ O u t ( V j ) ∣ S ( V j ) S \left( V _ { i } \right) = ( 1 - d ) + d \times \sum _ { V _ { j \in I n \left( V _ { i } \right) } } \frac { 1 } { \left| O u t \left( V _ { j } \right) \right| } S \left( V _ { j } \right) S(Vi)=(1−d)+d×Vj∈In(Vi)∑∣Out(Vj)∣1S(Vj)
其中 d 是一个介于 (0,1) 之间的常数因子,在PagRank中模拟用户点击链接从而跳出当前网站的概率,In(Vi) 表示链接到 Vi 的节点集合,Out(Vj) 表示从 Vj 出发链接到的节点集合。可见,开不是外链越多,网站的PageRank就越高。网站给别的网站做外链越多,每条外链的权重就越低。如果一个网站的外链都是这种权重很低的外链,那么PageRank也会下降,造成不良反应。正所谓物以类聚,垃圾网站推荐的链接往往也是垃圾网站。因此PageRank能够比较公正的反映网站的排名。将 PageRank 应用到关键词提取,无非是将单词视作节点而已,另外,每个单词的外链来自自身前后固定大小的窗口内的所有单词。
HanLP实现的代码如下:
from pyhanlp import * """ 关键词提取""" content = ( "程序员(英文Programmer)是从事程序开发、维护的专业人员。" "一般将程序员分为程序设计人员和程序编码人员," "但两者的界限并不非常清楚,特别是在中国。" "软件从业人员分为初级程序员、高级程序员、系统" "分析员和项目经理四大类。") TextRankKeyword = JClass("com.hankcs.hanlp.summary.TextRankKeyword") keyword_list = HanLP.extractKeyword(content, 5) print(keyword_list)运行结果如下:
[程序员, 程序, 分为, 人员, 软件]
9.3 短语提取
在信息抽取领域,另一项重要的任务就是提取中文短语,也即固定多字词表达串的识别。短语提取经常用于搜索引擎的自动推荐,文档的简介生成等。
利用互信息和左右信息熵,我们可以轻松地将新词提取算法拓展到短语提取。只需将新词提取时的字符替换为单词, 字符串替换为单词列表即可。为了得到单词,我们依然需要进行中文分词。 大多数时候, 停用词对短语含义表达帮助不大,所以通常在分词后过滤掉。
代码如下:
from pyhanlp import *
""" 短语提取"""
text = '''
算法工程师
算法(Algorithm)是一系列解决问题的清晰指令,也就是说,能够对一定规范的输入,在有限时间内获得所要求的输出。
如果一个算法有缺陷,或不适合于某个问题,执行这个算法将不会解决这个问题。不同的算法可能用不同的时间、
空间或效率来完成同样的任务。一个算法的优劣可以用空间复杂度与时间复杂度来衡量。算法工程师就是利用算法处理事物的人。
1职位简介
算法工程师是一个非常高端的职位;
专业要求:计算机、电子、通信、数学等相关专业;
学历要求:本科及其以上的学历,大多数是硕士学历及其以上;
语言要求:英语要求是熟练,基本上能阅读国外专业书刊;
必须掌握计算机相关知识,熟练使用仿真工具MATLAB等,必须会一门编程语言。
2研究方向
视频算法工程师、图像处理算法工程师、音频算法工程师 通信基带算法工程师
3目前国内外状况
目前国内从事算法研究的工程师不少,但是高级算法工程师却很少,是一个非常紧缺的专业工程师。
算法工程师根据研究领域来分主要有音频/视频算法处理、图像技术方面的二维信息算法处理和通信物理层、
雷达信号处理、生物医学信号处理等领域的一维信息算法处理。
在计算机音视频和图形图像技术等二维信息算法处理方面目前比较先进的视频处理算法:机器视觉成为此类算法研究的核心;
另外还有2D转3D算法(2D-to-3D conversion),去隔行算法(de-interlacing),运动估计运动补偿算法
(Motion estimation/Motion Compensation),去噪算法(Noise Reduction),缩放算法(scaling),
锐化处理算法(Sharpness),超分辨率算法(Super Resolution) 手势识别(gesture recognition) 人脸识别(face recognition)。
在通信物理层等一维信息领域目前常用的算法:无线领域的RRM、RTT,传送领域的调制解调、信道均衡、信号检测、网络优化、信号分解等。
另外数据挖掘、互联网搜索算法也成为当今的热门方向。
算法工程师逐渐往人工智能方向发展。'''
phrase_list = HanLP.extractPhrase(text, 5)
print(phrase_list)
运行结果如下:
[算法工程师, 算法处理, 一维信息, 算法研究, 信号处理]
目前该模块只支持提取二元语法短语。在另一些场合,关键词或关键短语依然显得碎片化,不足以表达完整的主题。这时通常提取中心句子作为文章的简短摘要,而关键句的提取依然是基于 PageRank 的拓展。
9.4 关键句提取
由于一篇文章中几乎不可能出现相同的两个句子,所以朴素的 PageRank 在句子颗粒度上行不通。为了将 PageRank 利用到句子颗粒度上去,我们引人 BM25 算法衡量句子的相似度,改进链接的权重计算。这样窗口的中心句与相邻的句子间的链接变得有强有弱,相似的句子将得到更高的投票。而文章的中心句往往与其他解释说明的句子存在较高的相似性,这恰好为算法提供了落脚点。本节将先介绍BM25算法,后介绍TextRank在关键句提取中的应用。
-
BM25
在信息检索领域中,BM25 是TF-IDF的一种改进变种。TF-IDF衡量的是单个词语在文档中的重要程度,而在搜索引擎中,查询串(query)往往是由多个词语构成的。如何衡量多个词语与文档的关联程度,就是BM25所解决的问题。
形式化的定义 Q 为查询语句,由关键字 q1 到 qn 组成,D 为一个被检索的文档,BM25度量如下:
BM 25 ( D , Q ) = ∑ i = 1 n IDF ( q i ) ⋅ TF ( q i , D ) ⋅ ( k 1 + 1 ) TF ( q i , D ) + k 1 ⋅ ( 1 − b + b ⋅ ∣ D ∣ avg D L ) \operatorname { BM } 25 ( D , Q ) = \sum _ { i = 1 } ^ { n } \operatorname { IDF } \left( q _ { i } \right) \cdot \frac { \operatorname { TF } \left( q _ { i } , D \right) \cdot \left( k _ { 1 } + 1 \right) } { \operatorname { TF } \left( q _ { i } , D \right) + k _ { 1 } \cdot \left( 1 - b + b \cdot \frac { | D | } { \operatorname { avg } D L } \right) } BM25(D,Q)=i=1∑nIDF(qi)⋅TF(qi,D)+k1⋅(1−b+b⋅avgDL∣D∣)TF(qi,D)⋅(k1+1) -
TextRank
有了BM25算法之后,将一个句子视作查询语句,相邻的句子视作待查询的文档,就能得到它们之间的相似度。以此相似度作为 PageRank 中的链接的权重,于是得到一种改进算法,称为TextRank。它的形式化计算方法如下:
W S ( V i ) = ( 1 − d ) + d × ∑ V j ∈ ln ( V i ) B M 25 ( V i , V j ) ∑ V k ∈ O u t ( V j ) Bu 2 s ( V k , V j ) W S ( V j ) \mathrm{WS}\left(V_{i}\right)=(1-d)+d \times \sum_{V_{j} \in \ln \left(V_{i}\right)} \frac{\mathrm{BM} 25\left(V_{i}, V_{j}\right)}{\sum_{V_{k} \in O u t\left(V_{j}\right)} \operatorname{Bu} 2 \mathrm{s}\left(V_{k}, V_{j}\right)} \mathrm{WS}\left(V_{j}\right) WS(Vi)=(1−d)+d×Vj∈ln(Vi)∑∑Vk∈Out(Vj)Bu2s(Vk,Vj)BM25(Vi,Vj)WS(Vj)
其中,WS(Vi) 就是文档中第 i 个句子的得分,重复迭代该表达式若干次之后得到最终的分值,排序后输出前 N 个即得到关键句。代码如下:from pyhanlp import * """自动摘要""" document = '''水利部水资源司司长陈明忠9月29日在国务院新闻办举行的新闻发布会上透露, 根据刚刚完成了水资源管理制度的考核,有部分省接近了红线的指标, 有部分省超过红线的指标。对一些超过红线的地方,陈明忠表示,对一些取用水项目进行区域的限批, 严格地进行水资源论证和取水许可的批准。''' TextRankSentence = JClass("com.hankcs.hanlp.summary.TextRankSentence") sentence_list = HanLP.extractSummary(document, 3) print(sentence_list)结果如下:
[严格地进行水资源论证和取水许可的批准, 水利部水资源司司长陈明忠9月29日在国务院新闻办举行的新闻发布会上透露, 有部分省超过红线的指标]
9.5 总结
我们看到,新词提取与短语提取,关键词与关键句的提取,在原理上都是同一种算法在不同文本颗粒度上的应用。值得一提的是, 这些算法都不需要标注语料的参与,满足了人们“不劳而获”的欲望。然而必须指出的是,这些算法的效果非常有限。对于同一个任务,监督学习方法的效果通常远远领先于无监督学习方法。
9.6 GitHub
HanLP何晗–《自然语言处理入门》笔记:
https://github.com/NLP-LOVE/Introduction-NLP
项目持续更新中…
目录
| 章节 |
|---|
| 第 1 章:新手上路 |
| 第 2 章:词典分词 |
| 第 3 章:二元语法与中文分词 |
| 第 4 章:隐马尔可夫模型与序列标注 |
| 第 5 章:感知机分类与序列标注 |
| 第 6 章:条件随机场与序列标注 |
| 第 7 章:词性标注 |
| 第 8 章:命名实体识别 |
| 第 9 章:信息抽取 |
| 第 10 章:文本聚类 |
| 第 11 章:文本分类 |
| 第 12 章:依存句法分析 |
| 第 13 章:深度学习与自然语言处理 |