python爬虫——二八原则(股票信息)
python爬虫——二八原则(股票资源方面)
- 前言
- 一、关于选题
- 二、爬虫
- 三、数据分析
- 四、数据可视化——pyecharts
-
-
- 总结
-
前言
这篇博客是关于python程序设计课程期末大作业选题——二八原则的部分内容,整个选题有需求分析设计,报告编写等等各种环节组成,这里就python的使用进行代码共享。tip:下面的部分代码由我们小组成员共同编写,同时参考了一些网上的代码,具体网址没有标注(因为是比较早之前了),若有侵犯请留言。
一、关于选题
选题15:28原则。难度:四星。
现实生活中一个非常著名的28原则,就是20%的人占据了80%的资源,而80%人只能占用剩下20%的资源。
现在,请你用数据来验证一下,在哪些行业里,这个原则的确是在发挥作用,并且再分析一下,对剩下的80%的人,还有机会逆袭吗?

需要爬取的数据
2010年到2020年,A股每天所有股票的股票代码、股票名称、当前价、市值。以及各行业的分类,便于后期数据的分析处理。
二、爬虫
首先通过www.banban.cn获取所有沪深A股的股票代码,通过requests库进行发送请求,获取响应数据,利用beautifulSoup对返回的数据进行处理。
def downStockCode():
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36'
}
stockAllCodeList = []
print('开始获取上证、深证股票代码')
count = 0
urlList = ['https://www.banban.cn/gupiao/list_sh.html', 'https://www.banban.cn/gupiao/list_sz.html']
for url in urlList:
stockCodeList = []
res = requests.get(url=url, headers=headers)
bs_res = BeautifulSoup(res.text, 'html.parser')
stocklist = bs_res.find('div', id='ctrlfscont').find_all('li')
for stock in stocklist:
stockhref = stock.find('a')['href']
list_stockhref = stockhref.strip().split('/')
stock_code = list_stockhref[2]
stockCodeList.append(stock_code)
count += 1
print('当前已获取{}只股票代码'.format(count), end='\r')
stockAllCodeList.append(stockCodeList)
print('已获取所有上证、深证股票代码:{}个'.format(count))
print(stockAllCodeList)
return stockAllCodeList
downStockFile():
通过正则表达式选出股票代码然后,然后通过股票代码在 网易财经 上通过下载链接下载对应股票每年的股票信息保存在当前目录的allstock文件下 3000多个股票文件信息,耗时较久
获取所有上证、深证的股票代码,return:[‘600001’,‘600002’,‘600003’…]
def downStockFile():
stockCodeList = downStockCode()
for tag in stockCodeList:
for i in tag:
code = (re.findall(r"\d+", i))
code = "".join(code)
file = './allstock/' + code + '.csv'
if (code == ""):
continue
print(code)
url = 'http://quotes.money.163.com/service/chddata.html?' \
'code=' + str(stockCodeList.index(tag)) + code + \
'&start=20100101' \
'&end=20201231' \
'&fields=TCLOSE;HIGH;LOW;TOPEN;LCLOSE;CHG;PCHG;TURNOVER;VOTURNOVER;VATURNOVER;TCAP;MCAP'
r = requests.get(url)
with open(file, "wb") as code:
code.write(r.content)
爬取的所有文件的列表,如下图所示:
每个文件内部的数据格式,如下图所示:
getEveTradeStockList():
获取所有行业的股票代码
在网易财经爬取对应行业的股票列表
def getEveTradeStockList():
# 行业名称和对应url的片段
tradeCodeList = [['农林牧渔', '001000'], ['采矿业', '002000'],
['粮食加工', '003001'], ['食品制造', '003002'],
['茶酒饮料', '003003'], ['纺织业', '003004'],
['服装制造', '003005'], ['皮毛制鞋', '003006'],
['木材加工', '003007'], ['家具制造', '003008'],
['造纸', '003009'], ['印刷', '003010'],
['传媒艺术', '003011'], ['石油加工', '003012'],
['化学制品', '003013'], ['医药制造', '003014'],
['化纤制造', '003015'], ['橡胶塑料', '003016'],
['非金属制品', '003017'], ['黑色金属', '003018'],
['有色金属', '003019'], ['金属制品', '003020'],
['专用设备制造', '003022'], ['汽车制造', '003023'],
['交运设备', '003024'], ['电器制造', '003025'],
['通信设备', '003026'], ['仪器仪表', '003027'],
['其他制造业', '003028'], ['废品利用', '003029'],
['水电燃气', '004000'], ['建筑业', '005000'],
['批发零售', '006000'], ['交通物流', '007000'],
['餐饮酒店', '008000'], ['信息技术', '009000'],
['金融业', '010000'], ['房地产业', '011000'],
['租赁和商务', '012001'], ['科研技术', '013000'],
['旅游环境', '014000'], ['服务业', '015000'],
['教育', '016000'], ['卫生', '017000'],
['出版传媒', '018000'], ['综合', '019000']]
number = 0
for i in tradeCodeList:
everyPageStockList = []
tradeName = []
tradeName.append(i[0])
everyPageStockList.append(tradeName)
for page in range(0, 50):
url = "http://quotes.money.163.com/hs/service/diyrank.php?" \
"host=http%3A%2F%2Fquotes.money.163.com%2Fhs%2Fservice%2Fdiyrank.php" \
"&page=" + str(page) + \
"&query=PLATE_IDS%3A" \
"hy" + str(i[1]) + \
"&fields=NO%2CSYMBOL%2CNAME%2CPRICE%2CPERCENT%2CUPDOWN%2CF" \
"IVE_MINUTE%2COPEN%2CYESTCLOSE%2CHIGH%2CLOW%2CVOLUME%2CTURNOVE" \
"R%2CHS%2CLB%2CWB%2CZF%2CPE%2CMCAP%2CTCAP%2CMFSUM%2CMFRATIO.MFRAT" \
"IO2%2CMFRATIO.MFRATIO10%2CSNAME%2CCODE%2CANNOUNMT%2CUVSNEWS&sort=PER" \
"CENT&order=desc&count=24&type=query"
# 设置请求头 伪装浏览器
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发起请求 获得响应
response = requests.get(url=url, headers=headers)
# 3.获取响应中的数据:text属性作用是可以获取响应对象中字符串形式的页面数据
data = response.json()
# 获取页数循环页数大于拥有的页数则跳出
pagecount = data['pagecount']
if (page > pagecount):
break
stocklist_data = data['list']
for j in stocklist_data:
tradecode = []
checkCode = j['CODE'][-6:-5]
if (checkCode == '6' or checkCode == '0'):
tradecode.append(j['CODE'][-6:])
everyPageStockList.append(tradecode)
number += 1
continue
filename = './trade/' + tradeName[0] + '.csv'
print(everyPageStockList)
with open(filename, "w", encoding="utf-8", newline="") as f:
writer = csv.writer(f, delimiter=',', quotechar='"', quoting=csv.QUOTE_MINIMAL)
writer.writerows(everyPageStockList)
print("数量:", number)
print("ok")
三、数据分析
数据分析的代码非常多,就不全部在这里粘贴了,直接上gitee看吧
gitee链接: https://gitee.com/chen_jiangtao/python.git.
预处理后的文件目录,如下图所示:
![]()

'''
calculateTotalValue()
这个函数处理3000多个股票文件获取每年市值信息,存为一个表
'''
def calculateTotalValue():
year = ['股票号', "名称", 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020]
filename = downloadFile.downStockCode()
b = [i for j in filename for i in j]
filename = b
newfile = open('各股每年平均总市值1.csv', 'w', encoding='ANSI', newline='')
csv_writer = csv.writer(newfile)
csv_writer.writerow(year)
# 循环所有的股票文件
print("开始计算每只股票每年总市值:")
print("开始写入:")
for fn in filename:
newlist = []
pathl = ('allstock/' + fn + '.csv')
try:
df = pd.read_csv(pathl, encoding="ANSI")
if df.empty:
print(fn + "股票信息为空!")
continue
else:
print(fn + "股票信息已经写入!")
newlist.append(fn)
newlist.append(df['名称'][0])
except FileNotFoundError: # 文件不能找到的异常处理
print(fn + "文件不存在")
continue
# 2010——2020年匹配是哪一年的
for k in range(2010, 2021):
sum = 0
count = 0
# 循环单个股票文件的所有行(每天的市值)
for i in range(len(df["日期"])):
time = re.findall(r"\d+", df["日期"][i])
if k == int(time[0]):
sum += df["总市值"][i]
count += 1
# 匹配不到日期
if count == 0:
newlist.append(0)
continue
ave = int(sum / count)
newlist.append(ave)
csv_writer.writerow(newlist)
# 完成所有股票遍历
其他的代码都是对这个函数生成的表进行一些数据提取分析。
四、数据可视化——pyecharts
这部分是由组员写的我也没取看过,所以大家就直接上git…
这里就直接放几张图。
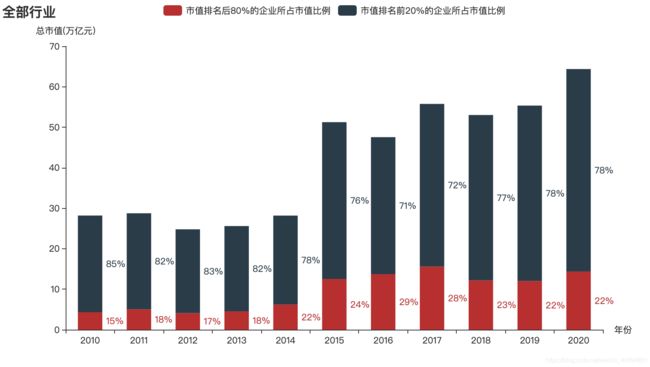
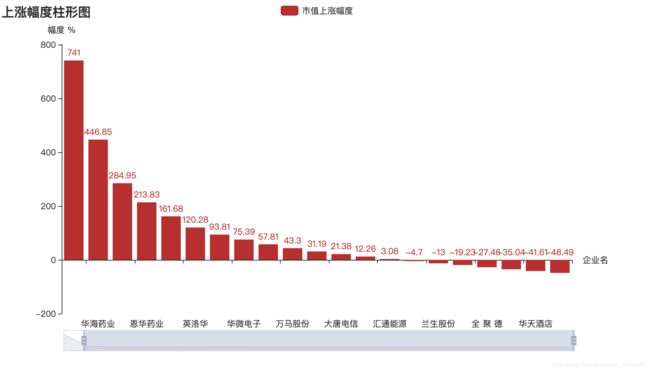
总结
完整的项目代码文件都在git上面,需要的自取。gitee链接: https://gitee.com/chen_jiangtao/python.git.