Scrapy学习——爬取智联招聘网站案例
Scrapy学习——爬取智联招聘网站案例
- 安装scrapy
-
- 下载
- 安装
- 准备
- 分析
- 代码
- 结果
安装scrapy
如果直接使用pip安装会在安装Twisted报错,所以我们需要手动安装。
下载
安装scrapy需要手动下载Twisted、pyOpenSSL。
Twisted:https://www.lfd.uci.edu/~gohlke/pythonlibs/
pyOpenSSL:https://pypi.org/simple/pyopenssl/
注:选择与自己python版本一致的安装包
安装
pip install 下载的文件名
准备
创建项目:
scrapy startproject zhaopin
这里是引用
创建爬虫:
scrapy genspider zp zhaopin.com
分析
我们爬取一个网站就得需要分析他的网页源代码
我分析之后发现,可以直接爬取每个城市的每页,他的所有信息都是可以直接在每页的找到,下面就是每个职位的所有信息
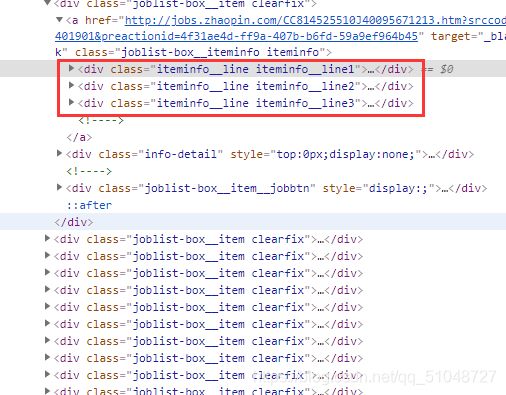
通过xpath来获取标签
智联招聘网站需要登陆才能爬取,我使用的是cookie登陆,先登陆之后将cookie复制下来

将cookie复制下来,然后使用复制的cookice进行登陆
代码
zhaopin爬虫文件代码
import scrapy
import re,json
import time
import requests
class ZhaopinSpider(scrapy.Spider):
name = 'zhaopin'
allowed_domains = ['zhaopin.com']
def start_requests(self):
cookies = 浏览器上面的cookie复制粘贴在这里
self.cookies = {
i.split("=")[0]: i.split("=")[1] for i in cookies.split("; ")}
self.headers = {
'User-Agent':"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",}
yield scrapy.Request(
'https://www.zhaopin.com/',
callback=self.parse,
cookies=self.cookies,
headers=self.headers
)
def parse(self, response):
# 自动添加第一次请求的cookie
start_city = 480
end_city = 950
print("开始爬取")
for i in range(start_city,end_city):
print("城市ID:",i)
url_city = "https://sou.zhaopin.com/?jl={0}".format(i)
yield scrapy.Request(
url=url_city,
callback=self.parse_page,
cookies=self.cookies,
headers=self.headers
)
def parse_page(self, response):
page = 1
next_page = response.xpath("//div[@class='pagination clearfix']//div[@class='pagination__pages']//button[@class='btn soupager__btn soupager__btn--disable']/text()").extract_first()
if next_page == "下一页":
print("正在爬取1:")
yield scrapy.Request(
url=response.request.url,
callback=self.parse_zp,
cookies=self.cookies,
headers=self.headers
)
elif response.xpath("//div[@class='sou-main']//div[@class='sou-main__center clearfix']//div[@class='positionList-hook']//div[@class='page-empty__tips']//span/text()").extract_first() != None:
print("未搜索到:",response.request.url)
return
else:
print("正在爬取2:")
for i in range(2, 40, 1):
url_page = response.request.url + "&p={0}".format(page)
page += 1
yield scrapy.Request(
url=url_page,
callback=self.parse_zp,
cookies=self.cookies,
headers=self.headers
)
def parse_zp(self, response):
item = {
}
list_body = response.xpath("//div[@class='joblist-box__item clearfix']")
print("URL:",response.request.url)
for body in list_body:
#工作名字
item['title'] = body.xpath(".//div[@class='iteminfo__line iteminfo__line1']//div[@class='iteminfo__line1__jobname']//span[@class='iteminfo__line1__jobname__name']/text()").extract_first()
list_li = body.xpath(".//div[@class='iteminfo__line iteminfo__line2']//ul//li")
#学历
item['Education'] = list_li[2].xpath("./text()").extract_first()
# 工作地点
item['job_location'] = list_li[0].xpath("./text()").extract_first()
#工作时间
item['job_time'] = list_li[1].xpath("./text()").extract_first()
#工资
money = body.xpath(".//div[@class='iteminfo__line iteminfo__line2']//div[@class='iteminfo__line2__jobdesc']//p/text()").extract_first()
item['money'] = money.split()
#工作需要
info = body.xpath(".//div[@class='iteminfo__line iteminfo__line3']//div[@class='iteminfo__line3__welfare']//div")
info_list = []
for i in info:
info_list.append(i.xpath("./text()").extract_first())
item['job_info'] = " ".join(info_list)
# #公司名
item['Company_name'] = body.xpath("//div[@class='iteminfo__line iteminfo__line1']//div[@class='iteminfo__line1__compname']//span[@class='iteminfo__line1__compname__name']/text()").extract_first()
company = body.xpath(".//div[@class='iteminfo__line iteminfo__line2']//div[@class='iteminfo__line2__compdesc']//span")
# 公司人数
item['company_number'] = company[1].xpath("./text()").extract()
# 公司类型
item['company_type'] = company[0].xpath("./text()").extract()
yield item
先在items写入以下代码
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class RecruitmentItem(scrapy.Item):
# 工作名字
title = scrapy.Field()
# 工资
money = scrapy.Field()
# 学历
Education = scrapy.Field()
# 工作描述
# job_desc = scrapy.Field()
#工作时间
job_time = scrapy.Field()
#工作需要
job_info = scrapy.Field()
# 工作地点
job_location = scrapy.Field()
# 公司名
Company_name = scrapy.Field()
# 公司类型
company_type = scrapy.Field()
# 公司人数
company_number = scrapy.Field()
pipelines代码
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class RecruitmentPipeline:
def process_item(self, item, spider):
print(item)
with open("智联招聘.txt", "a+", encoding="utf-8") as f:
for i in dict(item).items():
f.write("".join(i[1])+"\t")
f.write("\n")
# return item
def open_spider(self,spider):
with open("智联招聘.txt", "w", encoding="utf-8") as f:
f.write("工作名\t学历\t工作地点\t工作时间\t工资\t公司名\t企业人数\t企业类型\n")
settings.py
需要在配置文件中放开几个配置
#管道文件
ITEM_PIPELINES = {
‘Recruitment.pipelines.RecruitmentPipeline’: 300,
}
#是否使用自定义的cookies
COOKIES_ENABLED = True
#是否遵循robots.txt规则
ROBOTSTXT_OBEY = False
结果
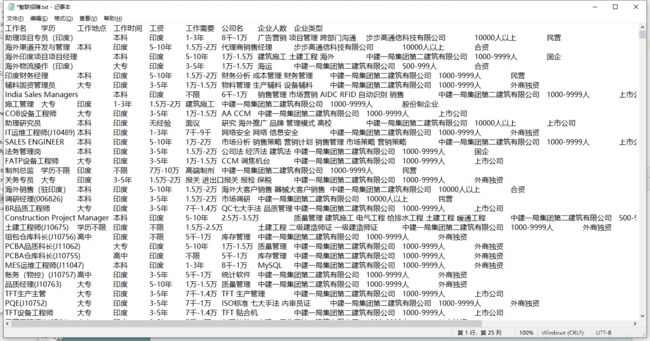
结语 :scrapy爬虫之爬取智联招聘笔记