数学建模:模拟退火和遗传算法
目录
- 启发式算法 (Heuristic Algorithm)
-
- 智能算法概述
- 模拟退火算法
- 遗传算法
启发式算法 (Heuristic Algorithm)
启发式算法 (Heuristic Algorithm) 兴起于上世纪 80 年代, 启发式算法是一种基于直观或经验的局部优化算法, 人们常常把从大自然的运行规律或者面向具体问题的经验和规则中启发出来的方法称之为启发式算法. 现在的启发式算法也不是全部来自然的规律, 也有来自人类积累的工作经验. 这些算法包括
- 禁忌搜索 (tabu search)
- 模拟退火 (simulated annealing)
- 遗传算法 (genetic algorithms)
- 人工神经网络 (artificial neural networks)
- 蚁群算法 (Ant Algorithm)
智能算法概述
智能优化算法要解决的一般是最优化问题。最优化问题可以分为(1)求解一个函数中,使得函数值最小的自变量取值的函数优化问题和(2)在一个解空间里面,寻找最优解,使目标函数值最小的组合优化问题。典型的组合优化问题有:旅行商问题(TravelingSalesman Problem,TSP),加工调度问题(SchedulingProblem),0-1背包问题(Knapsack Problem),以及装箱问题(Bin Packing Problem)等。
优化算法有很多,经典算法包括:有线性规划,动态规划等;改进型局部搜索算法包括爬山法,最速下降法等,本文介绍的模拟退火、遗传算法以及禁忌搜索称作指导性搜索法。而神经网络,混沌搜索则属于系统动态演化方法。
模拟退火算法
模拟退火是通过模拟物理退火过程搜索最优解的方法。
相似之处:
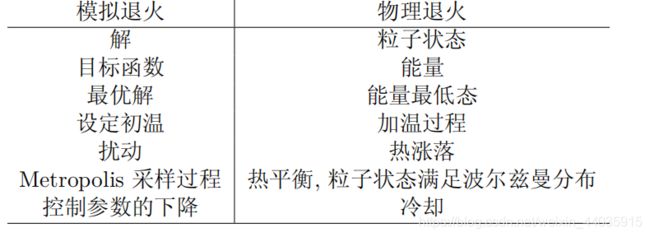
- 初始化:取初始温度T0足够大,令T = T0,任取初始解S1。
- 对比GA、ACA、PSO之类的群优化算法,需要在解空间中产生多个个体,再继续寻优。而SA算法只需要一个点即可。 对当前温度T,重复第(3)~(6)步。
- 对当前解S1随机扰动产生一个新解S2。
- 此处随机的扰动没有定义。结合实际例子做选择。 计算S2的增量df = f(S2) - f(S1),其中f(S1)为S1的代价函数。
- 代价函数相当于之前群优化算法中讲的适应度函数。 若df < 0,则接受S2作为新的当前解,即S1 = S2;否则,计算S2的接受概率exp(-df/T), T是温度。随机产生(0,1)区间上均匀分布的随机数rand,若exp(-df/T)rand,也接受S2作为新的当前解S1 = S2,否则保留当前解S1。
- 这是SA算法的核心部分,即有一定概率接受非最优解。 如果满足终止条件Stop,则输出当前解S1为最优解,结束程序,终止条件Stop通常取为在连续若干个Metropolis链中新解S2都没有被接受时终止算法或者是设定结束温度。否则按衰减函数衰减T后返回第(2)步,即被接受的新的解一直在产生,则我们要对问题进行降温,使得非最优解被接受的可能不断降低,结果愈发收敛于最优解。
例1:
![]() 其中
其中![]()
求解函数的最小值。
%%main.m
T=1000; %初始化温度值
T_min=1e-12; %设置温度下界
alpha=0.98; %温度的下降率
k=1000; %迭代次数(解空间的大小)
x=getX; %随机得到初始解
while(T>T_min)
for I=1:100
fx=Fx(x);
x_new=getX;
if(x_new>=-2 && x_new<=2)
fx_new=Fx(x_new);
delta=fx_new-fx;
if (delta<0)
x=x_new+(2*rand-1);
else
P=getP(delta,T);
if(P>rand)
x=x_new;
end
end
end
end
T=T*alpha;
end
disp('最优解为:')
disp(x)
%%getX.m
function x=getX
x=4*rand-2;
end
%%Fx.m
function fx=Fx(x)
fx=(x-2)^2+4;
end
%%getP.m
function p=getP(c,t)
p=exp(-c/t);
end
例2:
在循环中,通过随机扰动产生一个新的解,然后求得新解和原解之间的能量差,如果差小于0,则采用新解作为当前解。
如果差大于0,则采用一个当前温度与能量差成比例的概率来选择是否接受新解。温度越低,接受的概率越小,差值越大,同样接受概率越小。
是否接受的概率用此公式计算:p=exp(-ΔE/T)。这里ΔE为新解与原解的差,T为当前的温度。
由于温度随迭代次数逐渐降低,因此获得一个较差的解的概率较小。
典型的模拟退火算法还使用了蒙特卡洛循环,在温度降低之前,通过多次迭代来找到当前温度下比较好的解。
这里使用模拟退火解旅行商问题,因为这个问题本身是一个NP难问题,所以也就求不到最优解,不过应该可以求得一个比较好的解,然后再手工优化。
具体到程序中,这里的随机扰动就是随机置换两个城市的位置,能量就是旅行商路线的总长度。
main.m
clear all;close all;clc
n=20; %城市个数
temperature=100*n; %初始温度
iter=100; %内部蒙特卡洛循环迭代次数
%随机初始化城市坐标
city=struct([]);
for i=1:n
city(i).x=floor(1+100*rand());
city(i).y=floor(1+100*rand());
end
l=1; %统计迭代次数
len(l)=computer_tour(city,n); %每次迭代后的路线长度
netplot(city,n); %初始旅行路线
while temperature>0.001 %停止迭代温度
for i=1:iter %多次迭代扰动,一种蒙特卡洛方法,温度降低之前多次实验
len1=computer_tour(city,n); %计算原路线总距离
tmp_city=perturb_tour(city,n); %产生随机扰动
len2=computer_tour(tmp_city,n); %计算新路线总距离
delta_e=len2-len1; %新老距离的差值,相当于能量
if delta_e<0 %新路线好于旧路线,用新路线代替旧路线
city=tmp_city;
else %温度越低,越不太可能接受新解;新老距离差值越大,越不太可能接受新解
if exp(-delta_e/temperature)>rand() %以概率选择是否接受新解
city=tmp_city; %可能得到较差的解
end
end
end
l=l+1;
len(l)=computer_tour(city,n); %计算新路线距离
temperature=temperature*0.99; %温度不断下降
end
figure;
netplot(city,n); %最终旅行路线
figure;
plot(len)
computer_tour.m
function len=computer_tour(city,n) %计算路线总长度,每个城市只计算和下家城市之间的距离。
len=0;
for i=1:n-1
len=len+sqrt((city(i).x-city(i+1).x)^2+(city(i).y-city(i+1).y)^2);
end
len=len+sqrt((city(n).x-city(1).x)^2+(city(n).y-city(1).y)^2);
end
perturb_tour.m
function city=perturb_tour(city,n)
%随机置换两个不同的城市的坐标
%产生随机扰动
p1=floor(1+n*rand());
p2=floor(1+n*rand());
while p1==p2
p1=floor(1+n*rand());
p2=floor(1+n*rand());
end
tmp=city(p1);
city(p1)=city(p2);
city(p2)=tmp;
end
netplot.m
function netplot(city,n) %连线各城市,将路线画出来
hold on;
for i=1:n-1
plot(city(i).x,city(i).y,'r*');
line([city(i).x city(i+1).x],[city(i).y city(i+1).y]); %只连线当前城市和下家城市
end
plot(city(n).x,city(n).y,'r*');
line([city(n).x city(1).x],[city(n).y city(1).y]); %最后一家城市连线第一家城市
hold off;
end
遗传算法
遗传算法是通过模拟自然进化过程搜索最优解的方法。
初始化种群相当于确定原始解的位置,交叉是利用亲代信息来生成下一代个体,变异是基因的变异,并以此来丰富基因匹配的种类,适应度即构造的函数所对应的函数值,自然选择是根据特定的规律选择进入下一代的个体。 其涉及到的算法参数有:
-
种群数量:每一次迭代中保留下来的个体数量,一般设置为20~200,少了算法稳定性差,多了增加计算量且求解能力不是线性提升。
-
迭代次数:种群的进化代数,简易的问题100代~300代即可,1000代左右最常见,若问题复杂度高,可以适当增加迭代次数。
-
交叉概率:个体进行基因交叉的概率,通常取为0.3~0.9。
-
变异概率:个体基因突变的概率,通常取为0.001~0.1。对于遗传算法的原型而言,变异概率大了,种群不稳定。
遗传算法中基因的编码方式大致有二进制编码、十进制编码这两种,二进制编码属于算法原型中的编码方式,因其转码时会徒增额外的计算量,且在做离散型编码时,二进制远没有十进制便捷、快速,故笔者不推荐使用二进制的编码方式,后续的例题将在基于十进制编码的基础上进行讲解,对二进制编码感兴趣的同学可以自己去尝试,对比一下究竟哪种方法更好。
例1:
现有一个函数,y = sin(x) + x * cos(x),求该函数在区间[0,2π]上的最大值。首先我们需要画出函数的图像,如下图:

几乎所有的实际问题转化成函数之后都无法画出图像,这里只是为了好观察才画图的,解决问题的第一步就像之前说的,先编码,该问题中只有一个变量需要编码,即x。
- 编码
假设编码长度取5,即将求解区间划分了10^5份,但是要注意第一份是0,而不是1,长度越长精度越高。
解码的方式非常简单,举个例子,基因12345对应的x就是12345÷99999×(2π-0)+0 ~= 0.7757 。可以很明显的看出,基因00000代表x = 0,99999代表x = 2π 。对于连续型的问题编码大多采取这样的方式,但对于离散型的编码,需要根据具体的问题而设计,编码设计的优劣直接影响算法最终的结果。
离散型的编码也很常见,如TSP问题的编码、NP问题的编码等决策型的实际问题大多都需要使用离散型编码,基础阶段不要深究这个,此处不多做介绍。
- 交叉
交叉是遗传算法中一个非常重要的操作,其优劣影响算法的收敛速度。假设需要交叉的基因为 12345 与 66666,则断点随机取3,将第三个位置之后的序列交换生成两个新解,123 66与666 45 。这个应该很好理解,断点的选取应满足均匀分布。
- 变异
变异是遗传算法中另一个重要的操作,其优劣影响算法的最终结果与全局最优的接近程度。假设满足变异条件的基因为 66666,则当变异点随机取2时,将第二个位置处的值随机替换,生成一个新解,6 0 666 。这个0的生成与变异点的选取应该满足均匀分布。也就是变异成6 8 666也是可以的,且这两个出现的期望应该相等。
- 自然选择
通常来说,自然选择包括轮盘法和排名法。
轮盘法是通过每个个体与总体的适应度占比来衡量其优劣,比值越大越不容易被淘汰,当然轮盘法的计算法复杂度也相对较高:Pi = Fi ÷ ΣF
排名法是通过每个个体的适应度排名来看的,排名越靠前越不容易被淘汰,排名法的计算法复杂度相对较低:Pi = Ri ÷ N 或 P = (Ri - 1) ÷ N
Pi 是第i个个体被淘汰的概率,Fi 是第i个个体的适应度,Ri 是第i个个体的适应度排名,N 是种群个体数。遗传原型中使用的是轮盘法,但该方法除了计算快之外缺点太多,故推荐使用排名法。即适应度排名越靠后,其被淘汰的几率越高。
代码如下:
clear
clc
close all
f = @(x) sin(x) + x .* cos(x); % 函数表达式
ezplot(f, [0, 2*pi]) % 画出函数图像
N = 50; % 种群上限
ger = 100; % 迭代次数
L = 5; % 基因长度
pc = 0.8; % 交叉概率
pm = 0.1; % 变异概率
dco = [10000; 1000; 100; 10 ;1]; % 解码器
dna = randi([0, 9], [N, L]); % 基因
hold on
x = dna * dco / 99999 * 2 * pi; % 对初始种群解码
plot(x, f(x),'ko','linewidth',3) % 画出初始解的位置
x1 = zeros(N, L); % 初始化子代基因,提速用
x2 = x1; % 同上
x3 = x1; % 同上
fi = zeros(N, 1); % 初始化适应度,提速
for epoch = 1: ger % 进化代数为100
for i = 1: N % 交叉操作
if rand < pc
d = randi(N); % 确定另一个交叉的个体
m = dna(d,:); % 确定另一个交叉的个体
d = randi(L-1); % 确定交叉断点
x1(i,:) = [dna(i,1:d), m(d+1:L)]; % 新个体 1
x2(i,:) = [m(1:d), dna(i,d+1:L)]; % 新个体 2
end
end
x3 = dna;
for i = 1: N % 变异操作
if rand < pm
x3(i,randi(L)) = randi([0, 9]);
end
end
dna = [dna; x1; x2; x3]; % 合并新旧基因
fi = f(dna * dco / 99999 * 2 * pi); % 计算适应度,容易理解
dna = [dna, fi];
dna = flipud(sortrows(dna, L + 1)); % 对适应度进行排名
while size(dna, 1) > N % 自然选择
d = randi(size(dna, 1)); % 排名法
if rand < (d - 1) / size(dna, 1)
dna(d,:) = [];
fi(d, :) = [];
end
end
dna = dna(:, 1:L);
end
x = dna * dco / 99999 * 2 * pi; % 对最终种群解码
plot(x, f(x),'ro','linewidth',3) % 画出最终解的位置
disp(['最优解为x=',num2str(x(1))]);
disp(['最优值为y=',num2str(fi(1))]);
例2:
TSP问题
- 先确定两个城市序列中进行交换的城市
- 交换城市时,若城市序列中包含重复城市,则增加一个交换操作
交叉函数
function [A,B]=cross(A,B)
L=length(A);
if L<10
W=L;
elseif ((L/10)-floor(L/10))>=rand&&L>10
W=ceil(L/10)+8;
else
W=floor(L/10)+8;
end
%%W为需要交叉的位数
p=unidrnd(L-W+1);%随机产生一个交叉位置
%fprintf('p=%d ',p);%交叉位置
for i=1:W
x=find(A==B(1,p+i-1));
y=find(B==A(1,p+i-1));
[A(1,p+i-1),B(1,p+i-1)]=exchange(A(1,p+i-1),B(1,p+i-1));
[A(1,x),B(1,y)]=exchange(A(1,x),B(1,y));
end
end
变异运算
变异算子随机进行多次,每次在个体基因序列中选择两个位置的基因进行交换。
即直接将同一序列中的两个城市进行交换。
变异函数
function a=Mutation(A)
index1=0;index2=0;
nnper=randperm(size(A,2));
index1=nnper(1);
index2=nnper(2);
%fprintf('index1=%d ',index1);
%fprintf('index2=%d ',index2);
temp=0;
temp=A(index1);
A(index1)=A(index2);
A(index2)=temp;
a=A;
end
适应度函数
遗传算法在进化搜索中基本不利用外部信息,仅以适应度函数为依据,利用种群中每个个体的适应度值来进行搜索。
%适应度函数fit.m,每次迭代都要计算每个染色体在本种群内部的优先级别,类似归一化参数。越大约好!
function fitness=fit(len,m,maxlen,minlen)
fitness=len;
for i=1:length(len)
fitness(i,1)=(1-(len(i,1)-minlen)/(maxlen-minlen+0.0001)).^m;
end
代码脚本
clear;
clc;
%%%%%%%%%%%%%%%输入参数%%%%%%%%
N=25; %%城市的个数
M=100; %%种群的个数
ITER=2000; %%迭代次数
%C_old=C;
m=2; %%适应值归一化淘汰加速指数
Pc=0.8; %%交叉概率
Pmutation=0.05; %%变异概率
%%生成城市的坐标
pos=randn(N,2);
%%生成城市之间距离矩阵
D=zeros(N,N);
for i=1:N
for j=i+1:N
dis=(pos(i,1)-pos(j,1)).^2+(pos(i,2)-pos(j,2)).^2;
D(i,j)=dis^(0.5);
D(j,i)=D(i,j);
end
end
%%生成初始群体
popm=zeros(M,N);
for i=1:M
popm(i,:)=randperm(N);%随机排列,比如[2 4 5 6 1 3]
end
%%随机选择一个种群
R=popm(1,:);
figure(1);
scatter(pos(:,1),pos(:,2),'rx');%画出所有城市坐标
axis([-3 3 -3 3]);
figure(2);
plot_route(pos,R); %%画出初始种群对应各城市之间的连线
axis([-3 3 -3 3]);
%%初始化种群及其适应函数
fitness=zeros(M,1);
len=zeros(M,1);
for i=1:M%计算每个染色体对应的总长度
len(i,1)=myLength(D,popm(i,:));
end
maxlen=max(len);%最大回路
minlen=min(len);%最小回路
fitness=fit(len,m,maxlen,minlen);
rr=find(len==minlen);%找到最小值的下标,赋值为rr
R=popm(rr(1,1),:);%提取该染色体,赋值为R
for i=1:N
fprintf('%d ',R(i));%把R顺序打印出来
end
fprintf('\n');
fitness=fitness/sum(fitness);
distance_min=zeros(ITER+1,1); %%各次迭代的最小的种群的路径总长
nn=M;
iter=0;
while iter<=ITER
fprintf('迭代第%d次\n',iter);
%%选择操作
p=fitness./sum(fitness);
q=cumsum(p);%累加
for i=1:(M-1)
len_1(i,1)=myLength(D,popm(i,:));
r=rand;
tmp=find(r<=q);
popm_sel(i,:)=popm(tmp(1),:);
end
[fmax,indmax]=max(fitness);%求当代最佳个体
popm_sel(M,:)=popm(indmax,:);
%%交叉操作
nnper=randperm(M);
% A=popm_sel(nnper(1),:);
% B=popm_sel(nnper(2),:);
%%
for i=1:M*Pc*0.5
A=popm_sel(nnper(i),:);
B=popm_sel(nnper(i+1),:);
[A,B]=cross(A,B);
% popm_sel(nnper(1),:)=A;
% popm_sel(nnper(2),:)=B;
popm_sel(nnper(i),:)=A;
popm_sel(nnper(i+1),:)=B;
end
%%变异操作
for i=1:M
pick=rand;
while pick==0
pick=rand;
end
if pick<=Pmutation
popm_sel(i,:)=Mutation(popm_sel(i,:));
end
end
%%求适应度函数
NN=size(popm_sel,1);
len=zeros(NN,1);
for i=1:NN
len(i,1)=myLength(D,popm_sel(i,:));
end
maxlen=max(len);
minlen=min(len);
distance_min(iter+1,1)=minlen;
fitness=fit(len,m,maxlen,minlen);
rr=find(len==minlen);
fprintf('minlen=%d\n',minlen);
R=popm_sel(rr(1,1),:);
for i=1:N
fprintf('%d ',R(i));
end
fprintf('\n');
popm=[];
popm=popm_sel;
iter=iter+1;
%pause(1);
end
%end of while
figure(3)
plot_route(pos,R);
axis([-3 3 -3 3]);
figure(4)
plot(distance_min);
参考链接:
模拟退火https://blog.csdn.net/qq_34554039/article/details/90294046
https://www.cnblogs.com/tiandsp/p/3167785.html
遗传算法https://blog.csdn.net/qq_43787814/article/details/103143679
本文大部分是搬运,仅做笔记。