
文章来源:有道技术团队
一、概述
云侧是一种集中式服务,把所有图像、音频等数据通过网络传输到云中心进行处理然后把结果反馈回去。云侧资源集中通用性强,但是随着数据的指数爆发式增长,云侧已暴露出了很多不足,比如数据处理的实时性、网络条件制约、数据安全等。
基于云测的局限性,端侧的推理越来越重要。
端侧推理具体以下优势:1)低延时;2) 保证数据隐私;3)不依赖网络。然而端侧的计算资源、内存、存储都比较有限,如何满足性能的需求至关重要。日趋异构化的终端硬件平台,能够提升端侧的计算能力,然而复杂的开发环境让AI技术在端侧的应用落地颇受挑战。
语音识别(Automatic Speech Recognition,简称ASR),是语音交互中最基础的一个AI技术环节,常见的应用场景如智能音箱、同传、通话翻译等。ASR识别需要强大的计算能力,如何实现一个低延迟、高性能、低功耗的端侧ASR面临着重大挑战。
ARM(CPU)是目前AI端侧推理的主要计算平台,随着技术的发展和数据的增长,端侧对性能和功耗要求越来越高,单纯的ARM平台不再能满足新的需求,终端异构计算平台可以提供更强大的计算能力,逐步成为AI端侧推理的主流计算平台。
DSP(Digital Signal Process)芯片,也称数字信号处理器,是一种进行数字信号处理运算的微处理器。相比强大的CPU,DSP尤其擅长在低功耗下处理这些任务。
高通骁龙芯片提供了ARM+DSP异构计算平台,可以更好的服务于AI端侧推理,我们实现了基于高通骁龙865平台上的CPU+DSP协同计算离线ASR系统,该方法保证识别质量降低一个百分点以内,计算性能相对CPU版本加速3.89-4.42倍,功耗降低30.3%,异构计算平台降低了延迟和功耗,提高端侧设备待机时间。
二、离线 ASR
有道离线ASR是运行在移动设备端的应用程序。离线与在线的区别是,离线ASR是运行在设备端,不需要联网就可以进行语音识别的应用程序,而在线是必须依靠网络服务才可以获取语音识别结果的过程。
有道离线ASR引擎,采用了Pipeline形式的架构设计。Pipeline包含如提取声学特征(GenerateFeature)、声学模型(Forward)、解码器(Decode)、反正则化(Rescore)、归一化(Normalize)、加标点(addPunc)等Stage。
各个Stage之间独立运行,保证了在语音识别过程中,各模块单元的运行效率和识别质量。
离线ASR可以运行在安卓系统和ios系统中,支持armV7和armV8等多种arm处理器的指令集。离线ASR引擎以其轻量、简洁、扩展性强等特点,可以便捷的集成在如智能手机、智能手表、智能音箱等设备中。
有道离线ASR已在翻译王、词典笔、电子词典、某手机离线通话翻译等产品中广泛使用。
三、DSP
DSP架构与CPU或GPU截然不同,DSP具有两个关键的特点:1)DSP充分体现了每个时钟周期的计算能力;2)DSP在较低时钟频率下也可以提供高性能的计算能力,以低时钟频率节省功耗。
在移动端应用中,利用本地资源进行计算越来越重要。CPU计算带来功耗高的问题,导致移动终端的续航时间短、温度高等问题突出。DSP相对于CPU更擅长在低功耗下处理这些任务,具有高性能、低功耗等特性,提供更好的用户体验。
高通芯片在手机移动应用中广泛使用。高通骁龙865处理器,如表 1所示。在CPU方面,搭载了三丛集的架构设计结构,1个大核最高主频2.84GHz,3个主频2.42GHz的中核,还有主频为1.8GHz的4个小核。除了CPU架构,865还搭配了高性能、低功耗的DSP——Qualcomm Hexagon 698。

Hexagon DSP能够通过硬件多线程技术和最大化每个时钟周期所能完成的工作,在低时钟频率下运行,同时又能提供高性能。
Hexagon DSP核心计算模块为cDSP(Compute DSP),Hexagon 698使用的是cDSP V66架构,如图 1所示。cDSP支持4个硬线程,有2组标量计算模块和2组Hexagon向量计算模块。cDSP通过多线程和SIMD指令获得性能。cDSP上浮点计算性能较差,更擅长做8位、16位和32位定点数计算,因此,在DSP上实现深度学习推理服务时,量化是获得高性能的重要手段。

图 1 cDSP V66架构图
四、CPU+DSP协同计算ASR实现与优化
4.1 ASR子模块分析
ASR包含以下几个子模块:GenerateFeature、Forward、Decode、Rescore、Normalize 、addPunc, 表2展示了openslr数据集中一条测试语句(4507-16021-0047)的各个子模块的运行时间和比重。从子模块时间上分析,forward模块占比重最高,达到87.3%,是计算性能的关键子模块。进一步分析,forward最耗时的部分为gemm计算,占比达到95%,如表3所示。

从算法角度分析,forward最核心的计算为Tdnnf,Tdnnf先做一次矩阵重组,input相邻两行组成新矩阵aux的一行,然后做全连接计算,如图 2所示,同样分析得到gemm是最核心、最耗时计算。

图 2 Tdnnf计算过程
4.2 CPU+DSP协同计算离线ASR
4.2.1 量化计算
Hexagon DSP更擅长8位、16位和32位定点计算,浮点计算能力较差,因此,大量的计算需要使用定点计算,量化是唯一的解决方法。根据forward子模块计算过程,需要实现以下几个矩阵或向量的量化计算函数库。
1)8bit量化和反量化
8bit量化是深度学习训练和推理中提高计算性能的一种常用方法,量化方法分为对称量化和非对称量化两种方法,如图 2所示。我们在DSP上采用了uint8(无符号8bit)非对称量化的方法。

对称量化

非对称量化
Uint8量化和反量化可以用下面的公式表达:
量化公式:q = r/S + Z (1)
反量化公式:r = S(q – Z) (2)
其中,r表示float真实值,q表示量化值,S为缩放系数,Z为零值量化值,S和Z用公式3和4表达,S数据类型为float,Z数据类型为uint8。(3)
z=(-min)/s (4)
2)gemm量化计算
r3 = r1 * r2
= S1(q1 – Z1) * S2(q2 – Z2)
= S1 S2 [(q1 - Z1) * (q2 - Z2)] (5)
其中,r1,r2是两个矩阵,r3是结果矩阵,为float类型
根据int32对称量化方法,公式5可以得到:
S3_int32 = S1 S2, q3_int32 = [(q1 - Z1) (q2 - Z2)] (6)
其中,q3_int32为int32对称量化的结果,S3_int32为int32对称量化的缩放系数,q1和q2为矩阵,(q1 – Z1) * (q2 – Z2)表示矩阵乘积。
3) 重量化
为了能把所有层的计算都转完uint8量化计算,需要把int32中间结果重新量化成uint8类型,称为重量化。
查找q3_int32中的最小最大值:q3_int32_min, q3_int32_max
得到float真实值的最小最大值:
r3_min = S3_int32 q3_int32_min, r3_max = S3_int32 q3_int32_max (7)
根据公式3、4、7可以得到S3和Z3,从而得到
q3 = r3/S3 + Z3
= (S3_int32 * q3_int32)/S3 + Z3
= S3_int32/S3 * q3_int32 + Z3
= (S3_int32/S3 L) q3_int32 / L + Z3
= L1 * q3_int32 / L + Z3 (8)
其中,L为较大整数,如2的8 -16次幂,L1=(int32)(S3_int32/S3 * L)
4)向量求和量化计算
Forward模块中,fc计算以及其他计算模块需要做向量求和或矩阵求和的计算,需要实现其量化计算。
r3 = r1 + r2
= S1(q1 – Z1) + S2(q2 – Z2)
= S2*[S1/S2(q1 - Z1) + (q2 - Z2)]
= S2/L [(L S1/S2)(q1 - Z1) + L(q2 - Z2)]
= S2/L [L1(q1 - Z1) + L*(q2 - Z2)] (9)
其中,L为较大整数,如2的8 -16次幂,L1=(int32)(L*S1/S2),上面公式为S1 > S2的情况,S2>S1类似计算。
公式9结果为int32对称量化,其中:
S3_int32 = S2/L ,q3_int32 = L1(q1 – Z1) + L*(q2 – Z2) (10)
5)向量乘向量量化计算
r3_i = r1_i * r2_i
= S1(q1_i – Z1) * S2(q2_i – Z2)
= S1 S2 [(q1_i - Z1) * (q2_i - Z2)] (11)
公式11中表示的是两个向量或矩阵中对应的元素值相乘,_i表示第i个元素,结果为int32对称量化。
6)系数乘向量量化计算
r2 = c * r1
= c * S1(q1_i – Z1)
= (c S1) (q1_i – Z1) (12)
一个系数乘向量的量化计算,不需要做向量的计算,只需要使用原向量的缩放因子S乘以系数c做结果向量的缩放因子,Z值和uint8量化值保持不变。
4.2.2 CPU+DSP协同计算性能优化方法
1)内存优化
DSP通过ION实现与CPU端的zero-copy的内存共享,初始化时分配DSP上需要的内存,迭代计算中不再新申请内存,减少申请内存的开销。内存申请时,为了获得更好的性能,采用128B对齐。
DSP版本采用了uint8量化计算,只需申请量化的权重空间,比float32节省75%的空间,并且加载数据量也只有原来的1/4,既节省了内存空间,又减少了数据加载的时间。
DSP程序开辟太多的内存buffer数量会严重影响性能,我们对buffer数量进行了缩减,把所有层权重申请在一块buffer中,通过偏移量进行控制。
2)Fastrpc性能优化
Hexagon SDK公开了FastRPC,FastRPC是一个远程调用框架,允许在CPU端调用DSP应用程序,实现CPU和DSP的协同计算、内存共享。FastRPC调用DSP端函数就像CPU端调用本地函数一样,通过IDL(Interface Description Language,接口描述语言)提供函数定义。
FastRPC调用一次需要0.5-2毫秒,调用次数将会影响整个应用程序的性能,因此,FastRPC调用次数越少越好,把一次forward计算做一次FastRPC调用,IDL接口如下所示。
AEEResult forward(in sequenceinput_buf,in sequence weight_buf,rout sequence output_buf,in long svd_unit, in long hidden_unit, in long …);
3)DSP计算优化
DSP计算采用前面章节介绍的uint8量化的方案,把各个量化计算组合成ASR forward中需要的算子,从而实现forward整体计算过程。
forward模块DSP计算采用了以下优化方法:
a)多线程
cDSP支持4个硬线程,forward DSP底层计算中均采用了4线程并行计算。Gemm 4线程并行计算如图 4所示,由于ASR forward计算中,结果矩阵行大小N较小,不适合并行,我们划分列大小M并采用4线程并行计算。

图 4 gemm 4线程并行计算
b)SIMD
DSP上采用宽向量SIMD引擎Hexagon Vector eXtensions (HVX),HVX提供1024bit寄存器指令,可以并行执行128*8bit计算。Gemm中乘加SIMD操作如图 5所示,通过HVX指令可以提高DSP计算性能。

图 5 1024bit HVX乘加SMID示意图
c)ASM汇编指令
为了提高DSP计算性能,gemm、向量等计算均采用了asm汇编指令进行代码实现,如vmem、vshuff、vrmpy、add等指令。
d)矩阵分块
为了提高DSP cache命中率,对gemm计算进行了分块计算,如图 6所示,采用了4*32的分块,保证数据的cache以及SIMD宽度。
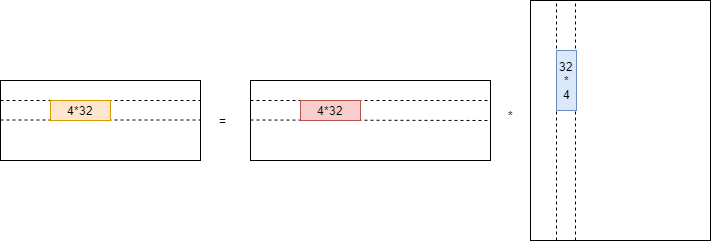
图 6 DSP gemm分块计算
e)预取
DSP计算时,访存往往成为性能瓶颈,对未来可能的访存单元预先取入Cache,从而在数据真正被用到时不会造成Cache失效。Gemm计算中采用了每次预取128B的数据,下轮计算时需要的数据直接从cache中即可获得,从而提高整体的性能。
f)对齐
为了进一步提高计算性能,还采用了对齐策略,训练模型大小设置为128的倍数,使DSP多线程并行和分块更容易。
4)亲和性设置
骁龙865芯片有大中小核三丛集的架构设计结构,离线ASR应用程序属于计算密集型,原CPU版本ASR程序会持续运行在中核或大核上,计算性能较好。把forward迁移到DSP计算后,CPU相对比较空闲,安卓系统会把其他模块计算自动切换到小核上执行,从而导致整体性能较差,为了解决这个问题,可以采用亲和性设置。亲和性是一种调度属性,它可以将一个进程”绑定” 到一个或一组CPU上。CPU+DSP协同计算的离线ASR应用程序做了中核和大核的亲和性设置如下:
define _GNU_SOURCE#define __USE_GNU#includecpu_set_t mask;CPU_ZERO(&mask);//高通骁龙865,0-3为小核,4-6核为中核,7核为大核CPU_SET(4, &mask);
CPU_SET(5, &mask);
CPU_SET(6, &mask);
CPU_SET(7, &mask);
int result = sched_setaffinity(0, sizeof(mask), &mask);
五、试验结果
5.1 试验环境
- 硬件环境
我们采用了高通865芯片做测试环境,具体参数如表 1所示。
- 软件环境
我们采用了android-ndk交叉编译器,在centos7系统上利用Hexagon SDK编译dsp程序、Android-ndk编译APP端应用程序,然后运行在手机Android10系统上。Hexagon SDK是一个软件开发套件,用于开发Hexagon DSP上的应用程序。

- 测试用例
测试集来自公开数据集aishell-1、openslr,使用test测试集验正确性,从中选择4条测试用例用于测试计算性能和功耗,如表 5所示。

5.2 试验结果与分析
5.2.1 识别质量
量化后会影响识别正确性,DSP量化之后,WER(Word error rate)值如表 6所示。
DSP量化后WER比CPU版本WER稍有提升,在测试集aishell-1和openslr分别为0.15和0.72个百分点。WER代表了错误率,值越低代表质量越好。

5.2.2 计算性能
1)整体计算性能
CPU+DSP协同计算ASR系统采用上面章节介绍的优化手段后的计算性能如表 7所示,相对纯CPU版本加速3.89-4.42倍,DSP获得较好的计算性能提升,大大降低了识别延迟。

2)Buffer数量对性能的影响
Fastrpc实现了CPU调用DSP模块的接口,接口buffer数量会对性能带来严重的影响,表 8展现了减少buffer数量对性能的影响,可以让fastrpc时间降低11.62倍,从而提升整体应用程序的性能。

3)设置Affinity
设置中大核之后,无论是在CPU上的计算模块还是DSP上计算模块性能都得到较大幅度的提升,如表 9所示,整体性能提升112%。

4)Fastrpc调用时间比例
进一步对优化后的DSP程序分析发现,fastrpc调用时间仍然较长,在forward计算中,fastrpc调用时间占比达到30%,如表 10所示,这是DSP硬件决定的,单次计算时间较少的模块迁移到DSP上时会因为fastrpc时间导致整体性能反而变差的情况发生,因此DSP应用具有一定的局限性。平均单次fastrpc调用时间达到了1.8ms以上,如果需要移植到DSP上的模块在CPU端运行时间小于这个时间是不适合迁移到DSP模块。

5.2.3 功耗测试
DSP相对CPU具有更好的功耗表现,CPU+DSP方案比纯CPU方案功耗下降30.3%。

六、结论
通过手机端CPU+DSP异构计算的离线ASR的实现,验证了其效果,在保证wer增加不超过1个百分点的前提下,计算性能相对纯CPU版本加速3.89-4.42倍,功耗降低30.3%,极大的提高了移动设备的续航时间。端侧异构计算,已经成为了端侧AI落地平台的发展趋势,DSP、NPU等AI芯片的发展将会大大促进AI在端侧的落地。结论
另外,DSP计算具有独特的特性,具有一定的适用性,需要在合适的应用场景选择性使用。
-END-
欢迎关注有道技术团队,我们会每周分享技术干货和技术实践。有道技术团队,与开发者同道。