用python进行数据分析,挖掘及机器学习流程实项-天津租房
用python进行数据分析,挖掘及机器学习流程
目的:本篇给大家介绍一个数据分析的入门项目,目的是通过项目了解使用Python进行数据分析,模型建立,机器学习的整体流程。
数据源:通过爬虫采集的链家网天津租房数据(链家网广告少,易于采集)。
源代码与原始数据链接:[https://github.com/yb705/tianjin_renting_Analysis]
初始的数据探索
首先要导入一些第三方库有科学计算包numpy,pandas,可视化matplotlib,seaborn,以及机器学习包sklearn,以及前期的一些初始设置。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
import seaborn as sns
%matplotlib inline#在ipython或jupyter notebook保证可以在线显示图片
plt.style.use("fivethirtyeight")
sns.set_style({
'font.sans-serif':['SimHei','Arial']})#设置图片字体,不然中文会显示乱码
original=pd.read_csv('C:\\Users\\1994y\\Desktop\\data_1.csv')#读取数据
初步观察是否含有缺失值的情况
original.isnull().sum()
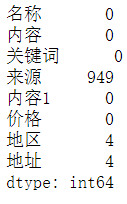
可以看到在“来源”这一方面有很多的缺失值,鉴于后期要进行数据挖掘,“来源”也是一项重要的特征值,所以这里删掉含有缺失值的项。
b=original.dropna()
b

好的,那么在简单处理完缺失值之后,可以看到这是一个需要大量整理的原始数据。这样的数据有些冗杂重复,而且难于在其基础上进行清洗整理(主要是博主的爬虫技术有点差),所以我们干脆对原数据进行提取,另建一份新的数据表。
cleaned=pd.DataFrame([])
那么在提取之前首先要明确,需要什么样的特征值,也就是这份数据表需要什么样的属性。经过对原表格的分析,我把特征值归结为以下几个:
 即状态,规格,楼层,面积,朝向,价格,地区,地址,来源。
即状态,规格,楼层,面积,朝向,价格,地区,地址,来源。
首先”状态“来源于原表的”名称“列,所以对这一列进行提取:
c=b["名称"].str.strip()#去除左右两边的空格
c

cleaned['状态']=c.str.split('·').str[0]
cleaned
通过split()进行分组提取字符串,当然也可以通过正则表达式进行特定提取。结果如下:

剩下的属性以此类推:
cleaned['规格']=c.str.split(' ').str[-2]
cleaned['楼层']=b['内容'].str.strip().str.split(' ').str[-25]
cleaned['面积']=b['内容'].str.strip().str.split('/').str[1].str.strip()
cleaned['面积']=cleaned['面积'].str[:-1].astype('int64')
cleaned['朝向']=b['内容'].str.strip().str.split('/').str[2].str.strip()
cleaned['价格']=b['价格'].str.split('元').str[0].astype('int64')
cleaned['地区']=b["地区"]
cleaned['地址']=b["地址"]
cleaned['来源']=b['来源'].str.strip()
cleaned
结果如下: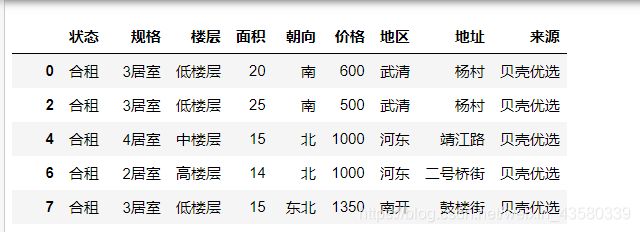
这样的表看着就舒服多了。
小tips:无论是数据分析或挖掘,尽量不要在原始数据表上进行,因为有很多方法,函数最后返回的对象都是原始数据表,容易造成不必要的麻烦,可以使用.copy()方法对复制出来的表进行操作。
数据分析与可视化
这里我们简单的看一下天津各个区的租房数量分布情况,以及各个区的租金对比。
house_count = cleaned.groupby('地区')['价格'].count().sort_values(ascending=False).reset_index()#重新调整为默认索引
f, [ax1,ax2] = plt.subplots(2,1,figsize=(20,15))
sns.barplot(x='地区', y='价格', palette="Greens_d",data=house_count, ax=ax1)
ax1.set_title('天津各区租房数量对比',fontsize=15)
ax1.set_xlabel('地区')
ax1.set_ylabel('数量')
sns.boxplot(x=cleaned['地区'].astype('str'),y=cleaned['价格'].astype('int'),ax=ax2)
ax2.set_title('天津各区租房房租',fontsize=15)
ax2.set_xlabel('地区')
ax2.set_ylabel('租金')
通过pandas对象的groupby机制,我们对相关数据整理组合,最后以柱状图
和箱型图的子图形式表现出来,结果如下:
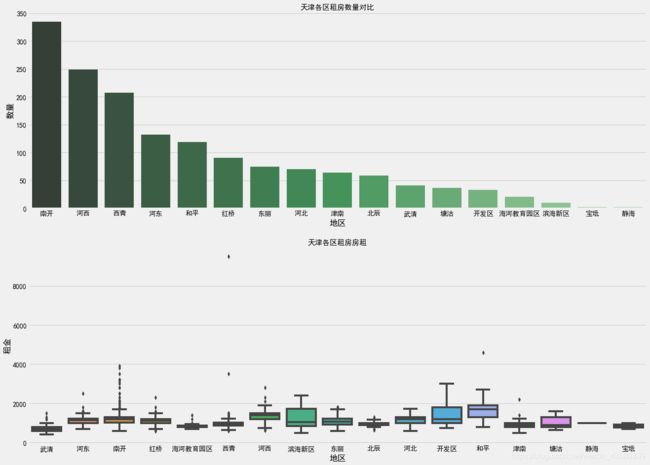
可以看到天津的租房越靠近市中心,出租屋的数量就越高,而大部分租金处在1000上下,有的地方租金达到了每月2000以上(住不起),不过价格整体还是比较平稳的。
数据挖掘
在进行数据挖掘之前,我们要对数据进行进一步的整理:
cleaned['规格'].value_counts()
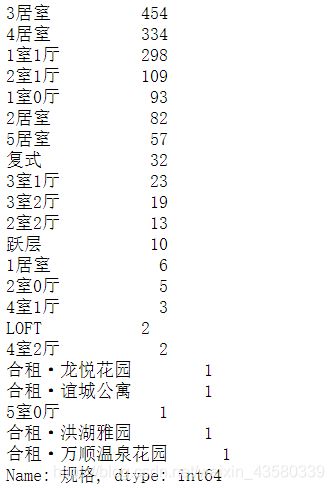
可以看到有一些不符合“规矩”的数据,数量不多的情况下,我们直接移除掉
move=['LOFT','合租·龙悦花园','合租·洪湖雅园','合租·万顺温泉花园','合租·谊城公寓']
cleaned=cleaned[~cleaned['规格'].isin(move)]
cleaned['规格'].value_counts()

还有一列数据比较特殊
cleaned=cleaned[~cleaned['朝向'].isin(['3室1厅1卫'])]
cleaned['朝向'].value_counts()
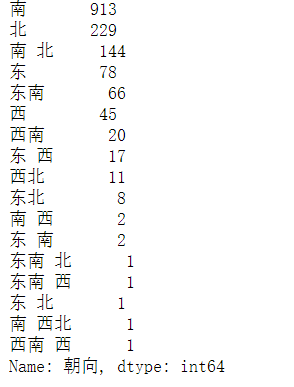
可以看到有一些"朝向"中间夹杂空格,还有一些意义不明的方向,譬如“西南西”,这些对于接下来的数据挖掘是有很大影响的,所以我们要整理分类一下:
move_direction=['南 北','东 西','东 南','南 西','西南 西','东南 西','东 北','南 西北','东南 北']
correct_direction=['南北','东西','东南','西南','西南','东西南','东北','南西北','东南北']
def direction_correct(x):
for i in range(len(move_direction)):
if x == move_direction[i]:
x=correct_direction[i]
return x
这里我编了一个小函数,用于对”朝向“列进行修正
cleaned['朝向']=cleaned['朝向'].apply(direction_correct)
cleaned['朝向'].value_counts()

好了,这样就顺眼多了,接下来我们在对”价格“进行简单的离散分箱:
cleaned['price']=pd.qcut(cleaned['价格'],4).astype('object')
cleaned['price']
值得注意的是,不管是qcut()还是cut(),都只能对数字进行操作,而有的数据虽然显示的是数字,但实际上却是字符串格式,所以有的时候要用astype()进行强制数值类型转换。

cleaned=cleaned.reset_index()#重置一下索引,避免在接下来的数据挖掘中造成麻烦
del cleaned['index']
del cleaned['地址']
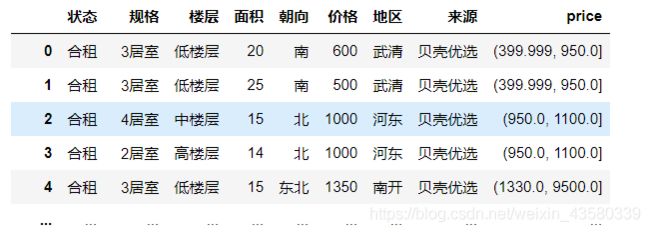
cleaned
最后的结果如下:
独热编码
具体的意义就不再多说了,有兴趣的同学可以自己去了解一下,链接:OneHotEncoder独热编码
简单来说就是对于非数值型类型,像”朝向“,”状态“等,我们需要将这些非数值量化来当作模型的输入,在pandas中非常简单,用get_dummies()方法就可以了。下面这个函数是一个独热编码封装函数,大家可以参考一下:
def one_hot_encoder(df, nan_as_category = True):
original_columns = list(df.columns) # 属性
categorical_columns = [col for col in df.columns if df[col].dtype == 'object']
df = pd.get_dummies(df, columns= categorical_columns, dummy_na= nan_as_category)
new_columns = [c for c in df.columns if c not in original_columns]
return df, new_columns
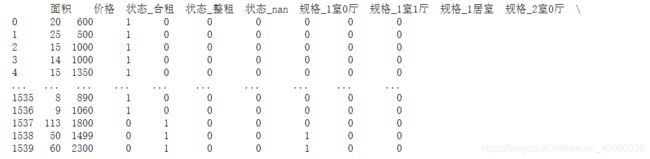
house,house_columns=one_hot_encoder(cleaned)#独热编码
print(house)
结果如下:
特征相关性
接下来要看的就是特征相关性,这是比较重要的一环,有一句话说的很好,“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已”,
所以特征值是非常重要的,
那么特征相关性指的是两个特征对于目标变量的影响程度相似,即存在严重的重复信息,会造成过拟合现象,通过特征相关性分析,我们可以找出哪些特征有严重的重叠信息,然后择优选择。
对于特征相关性比较好的表现形式就是热力图:
def one_hot_encoder(df, nan_as_category = True):
original_columns = list(df.columns) # 属性
categorical_columns = [col for col in df.columns if df[col].dtype == 'object']
df = pd.get_dummies(df, columns= categorical_columns, dummy_na= nan_as_category)
new_columns = [c for c in df.columns if c not in original_columns]
return df, new_columns
house,house_columns=one_hot_encoder(cleaned)#独热编码
print(house)
颜色偏红或者偏蓝都说明相关系数较大,可以进行取舍。
小tips:如果特征值过多的话,可能会造成图片不显示,或者直接显示会黑底的情况,这个时候就要检查一下,看看是不是可以适当整理一些意义重合的特征值。
机器学习
机器模型:XGBRegressor
这个模型是Boosting算法的其中一种,Boosting算法的思想是将许多弱分类器集成在一起,形成一个强分类器。因为Xgboost是一种提升树模型,所以它是将许多树模型集成在一起,形成一个很强的分类器。而所用到的树模型则是CART回归树模型。
Xgboost一般和sklearn一起使用,但是由于sklearn中没有集成Xgboost,所以需要单独下载安装。基础的同学可以选择其他简单的模型来练练。
优化方法:GridSearchCV
GridSearchCV的名字其实可以拆分为两部分,GridSearch和CV,即网格搜索和交叉验证。这两个名字都非常好理解。网格搜索,搜索的是参数,即在指定的参数范围内,按步长依次调整参数,利用调整的参数训练学习器,从所有的参数中找到在验证集上精度最高的参数,这其实是一个训练和比较的过程。
评分:R2
首先我们先导入train_test_split来对数据进行划分,分别划分为训练集和测试集
from sklearn.model_selection import train_test_split
import re
regex = re.compile(r"\[|\]|<", re.IGNORECASE)
cleaned.columns = [regex.sub("_", col) if any(x in str(col) for x in set(('[', ']', '<'))) else col for col in cleaned.columns.values]#避免出现符号读取错误
x=cleaned.iloc[:,:-1]
y=cleaned.iloc[:,5]
x_dum=pd.get_dummies(x) #独热编码
x_train,x_test,y_train,y_test = train_test_split(x_dum,y,test_size = 0.3,random_state = 1)
接下来就是建模型了
from sklearn.model_selection import KFold
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import make_scorer
from xgboost import XGBRegressor
def metric(y_true, y_predict):
from sklearn.metrics import r2_score
score = r2_score(y_true, y_predict)
return score#R2评分
other_params = {
'eta': 0.3, 'n_estimators': 200, 'gamma': 0.37, 'max_depth': 9, 'min_child_weight': 0,
'colsample_bytree': 1, 'colsample_bylevel':0.9, 'subsample': 0.2, 'reg_lambda': 1, 'reg_alpha': 0,
'seed': 33}#XGBRegressor的相关参数属性,有兴趣的小伙伴可以自行查阅
def fit_model(X, y,params):
cross_validator = KFold(10, shuffle=True)
regressor = XGBRegressor(**other_params)#要注意这里有两个*
cv_params =params
scoring_fnc = make_scorer(metric)
grid = GridSearchCV(estimator = regressor, param_grid = cv_params, scoring = scoring_fnc, refit=True,cv = cross_validator)
grid = grid.fit(X, y)#x是训练的特征值,y是训练标签
print("参数的最佳取值::", grid.best_params_)
print("最佳模型得分:", grid.best_score_)
我在上面专门编了一个函数用于调参测试,那么接下来的具体流程如下:
fit_model(x_train, y_train,{
'n_estimators': np.linspace(100, 1000, 10, dtype=int)})
对params传递了一个等差数列,结果如下:

最佳取值是166,准确度96%,那我们进一步查找最佳参数值,再用一个等差数列,[50,60,70,…,150]
fit_model(x_train, y_train,{
'n_estimators': np.linspace(100, 300, 10, dtype=int)})

可以看到模型得分有所提高,说明这个模型的准确度是在提高的,当然接下来还可以更加细化参数区间,有兴趣的小伙伴可以自行探索。
当然对于其他参数也是如此:
fit_model(x_train, y_train,{
'max_depth': np.linspace(1, 10, 10, dtype=int)})
fit_model(x_train, y_train,{
'min_child_weight': np.linspace(0, 10, 10, dtype=int)})
fit_model(x_train, y_train,{
'gamma': np.linspace(0.1, 0.5, 10)})
fit_model(x_train, y_train,{
'subsample': np.linspace(0, 1, 11)})
fit_model(x_train, y_train,{
'colsample_bytree': np.linspace(0, 2, 10)[1:]})
它们的结果如下:


等等,就不一一列举了。
总的来说,这就是一个不断调整各项参数,使模型精度无限提高的一个过程。
注意:在调参过程中,每调整好一个参数,都要在other_params中对相应的参数进行修改后,再去调整下一个参数
进阶篇—模型探讨
在房价预测回归模型里,有三个集成学习模型准度较高,分别是:
RandomForestRegressor(随机森林回归模型),XGBRegressor,GradientBoostingRegressor(集成学习梯度提升决策树),具体含义与用法,有兴趣的小伙伴们可以自行探索,接下来我们简单讨论一下看看哪一个精度更高。
from sklearn.ensemble import RandomForestRegressor
from xgboost import XGBRegressor
from sklearn.ensemble import GradientBoostingRegressor
models=[XGBRegressor(),RandomForestRegressor(),GradientBoostingRegressor()]
models_str=['XGBoost','RandomForest','GradientBoost','Bagging']
score_=[]
导入相关模块后,分别把它们放在表格里,以便接下来进行遍历评估,新建一个评分表用于记录分数。
for name,model in zip(models_str,models):
print('开始训练模型:'+name)
model=model #建立模型
model.fit(x_train,y_train)
y_pred=model.predict(x_test)
score=metric(y_test,y_pred)
score_.append(str(score))
print(name +' 得分:'+str(score))
还是之前的数据,进行遍历之后,我们分别进行评估打分,结果如下:

可以看到GradientBoostingRegressor的准度最高,有兴趣的小伙伴,也可以试试其他的模型,如线性模型等,看看分数怎么样。
总结
以上一个完整的从数据分析到挖掘再到机器学习的进阶项目就结束了,就项目而言比较简单,模型稍复杂一点,主要是为了让大家了解整个过程。有很多细节可以提升改进,还有很多更好的方案代替,一些改进思考如下:
获取更多有价值的特征信息,比如地段,交通等
完善特征工程,如进行有效的特征选择
选择更优秀的模型算法建模
这是博主的第一个实战项目,也是博主发的第一篇文章,有什么不足的地方希望大家多做自我批评 欢迎大家指出来,感谢阅读