Python爬虫实战(十一) B站热门信息爬取(窗口版)| Tkinter实现GUI交互式界面
目录
-
-
- 一、主页面设计
-
- 1.1 Tkinter基本介绍
- 1.2 设计布局
- 二、查询功能实现
-
- 2.1 分区字典构建
- 2.2 输入日期处理
- 2.3 书写爬虫函数
- 三、全部代码
- 思考与优化
-
之前,我们系统地介绍了两种爬取B站热门视频的方法。今天,就来分享一下如何组合Tkinter实现一键即可查询B站各区最火视频。首先,来看看最终的效果图吧:
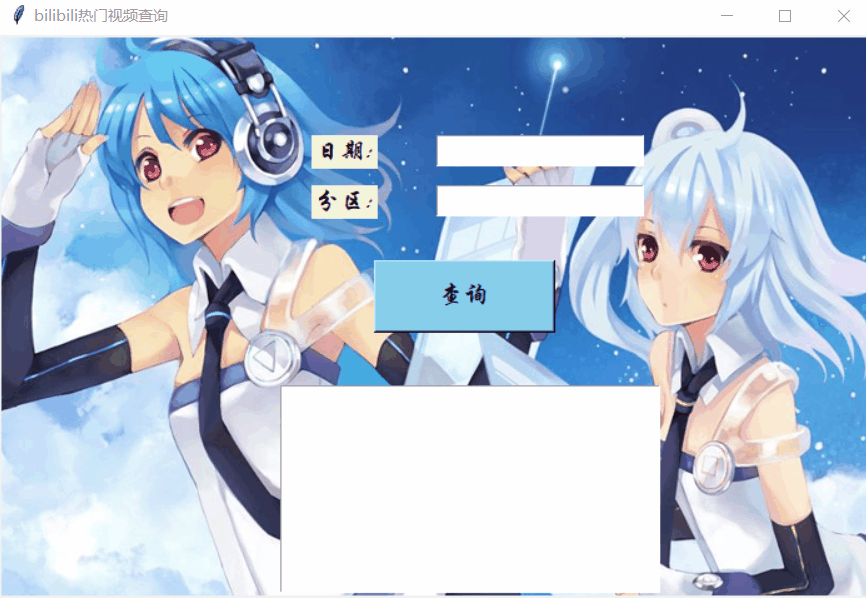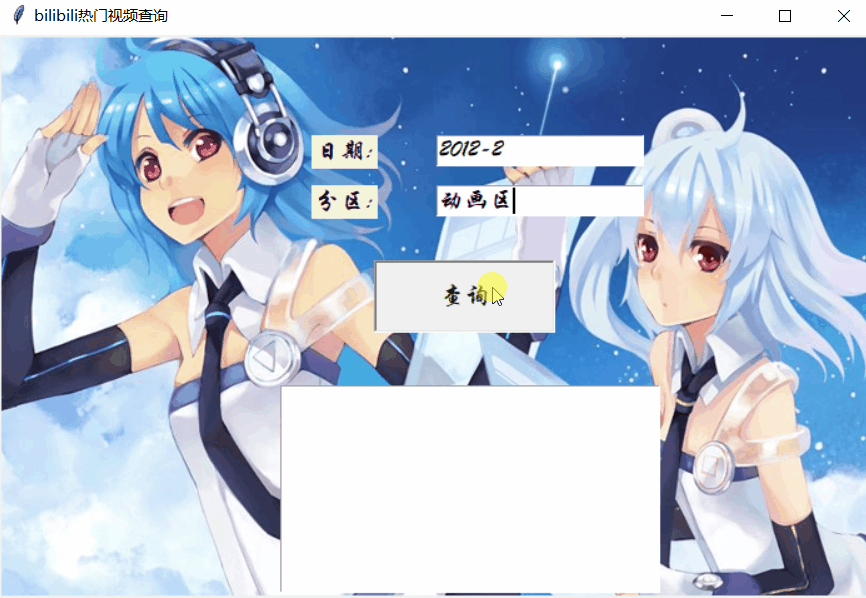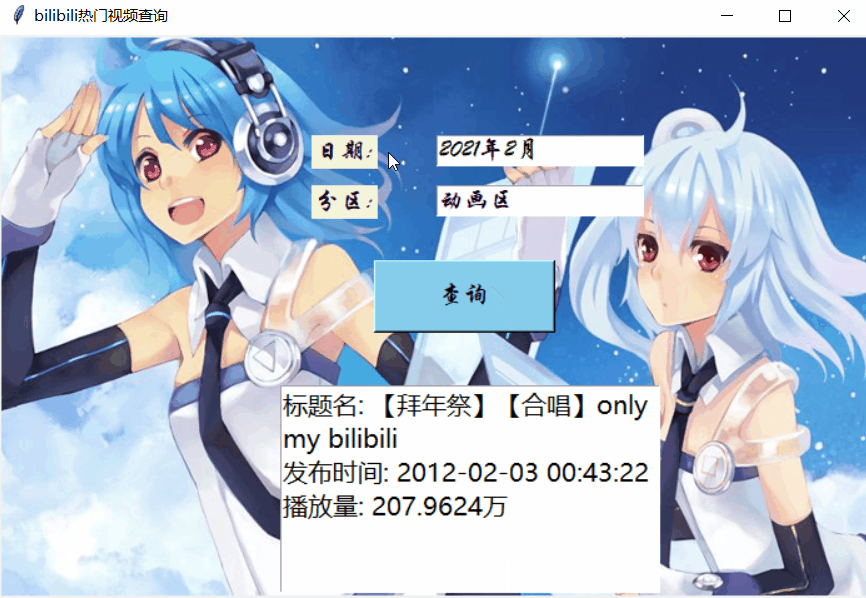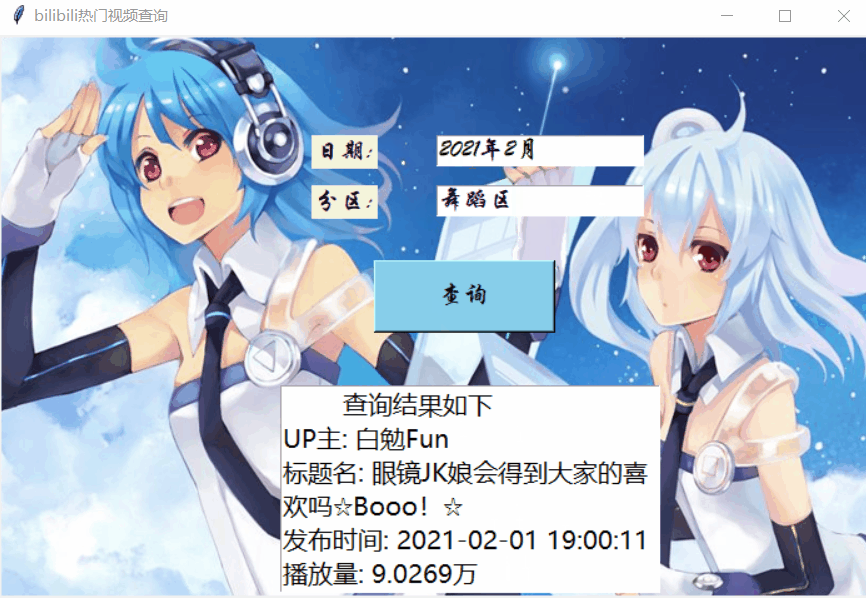
一、主页面设计
1.1 Tkinter基本介绍
Tkinter是一款Python自带的GUI可视化界面库,对于新手来说还是易于上手的。本文使用的基本控件主要有Label、Entry、Text、Button、Cavas。其基本作用如下表所示:
| 控件 | 描述 |
|---|---|
| Label (标签) | 用于显示文本和位图 |
| Entry (输入) | 用于显示简单的文本内容 |
| Button(按钮) | 在程序中显示按钮 |
| Text(文本) | 用于显示多行文本 |
| Cavas(画布) | 显示图形元素如线条或文本 |
从之前的爬虫API接口爬取B站热门视频信息可知,用户想要查询B站热门视频信息,需要提前确定两个参数:分区ID和查询热门视频时间范围。因此,我们设计的主要想法为:将分区名称和日期设置为两个Entry控件,便于接受用户所输入的信息,然后通过Button控件组合这两个信息交给相应的爬虫函数,最终由爬虫函数获取到的视频信息再交给Text控件呈现。
1.2 设计布局
首先,我们先来设计整个页面布局,各个控件基本使用方法详细可参照菜鸟教程Tkinter入门,在此不再详细说明。该部分的代码如下
import tkinter as tk
from PIL import Image, ImageTk
def get_image(file_name, width, height): #读取图片
im = Image.open(file_name).resize((width, height))
return ImageTk.PhotoImage(im)
window = tk.Tk(className='bilibili热门视频查询') #创建窗口,并对其命名
window.geometry('700x450') # 窗口大小设置
# 背景画布设置,读取桌面的2233娘的照片
canvas = tk.Canvas(window, width=700, height=450)
img = get_image('C:/Users/dell/Desktop/2233.jpg', 700, 450)
canvas.create_image(350, 225, image=img)
canvas.pack()
# 标签
L1 = tk.Label(window, bg='Beige', text='日期:', font=('华文行楷', 15))
L2 = tk.Label(window, bg='Beige', text='分区:', font=('华文行楷', 15))
L1.place(x=250, y=80)
L2.place(x=250, y=120)
# 输入文本
E1 = tk.Entry(window, font=("华文行楷", 15), show=None, width=18)
E2 = tk.Entry(window, font=("华文行楷", 15), show=None, width=18)
E1.place(x=350, y=80)
E2.place(x=350, y=120)
# 显示多行文本
t = tk.Text(window, width=25, height=6, font=("微软雅黑", 15), selectforeground='red')
t.place(x=225, y=280)
# 查询按钮
button = tk.Button(window, bg='SkyBlue', text="查询", font=('华文行楷', 15), width=15, height=2
)
button.place(x=300, y=180)
window.mainloop()
最终得到的页面图如下:
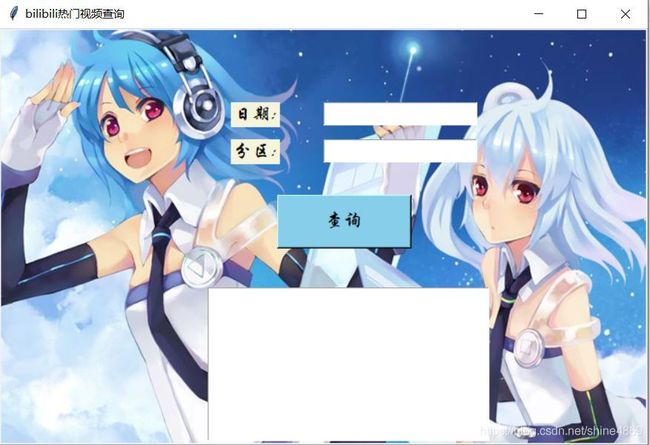
此时的查询只是一个空的按钮,无法通过用户输入的日期与分区名称进行查询的。因此,我们要写一个爬虫函数,整合输入的信息,传入Button控件中的command参数来赋予其查询功能。
二、查询功能实现
在这篇博客API接口爬取B站热门视频信息中,我们知道实现B站热门视频信息爬虫主要依赖于以下四个重要参数:card_id(分区ID)、page(爬取页数)、time_from(最早视频发布时间)、time_to(最晚视频发布时间)。由于本次实现GUI可视化只需要播放量最高的视频信息,故参数page不用考虑,设定为1即可,只需关注card_id和time_from、time_to即可。
2.1 分区字典构建
首先,我们需要将用户输入的分区名称与各分区的ID一一对应,因此我们需要先构建一个分区字典。由于B站每个大分区下还有若干子区(例如:生活区下有搞笑区、日常区等8个子区),这里仅以各分区第一个子区代表该分区。(例如,以搞笑区代表生活区)
最终,构建的字典如下
tagid_dict = {
'动画区': 24,
'音乐区': 28,
'舞蹈区': 20,
'知识区': 201,
'生活区': 138,
'时尚区': 157,
'娱乐区': 71,
'游戏区': 17,
'数码区': 95,
'鬼畜区': 22,
'影视区': 182
}
2.2 输入日期处理
考虑到不同用户输入习惯的差异,本文设计了两种输入日期的格式,用于查询当月最热视频信息,形如2021年2月和2021-2
time_from和time_to参数的基本形式为20210204,其中time_to参数不能出现日期溢出现象,例如:查询2020年2月时time_to不可以为20200231,查询2021年2月时time_to不可以为202102014(以今天2021年2月4日为准)
基于此,我们将得到以下判断日期逻辑:
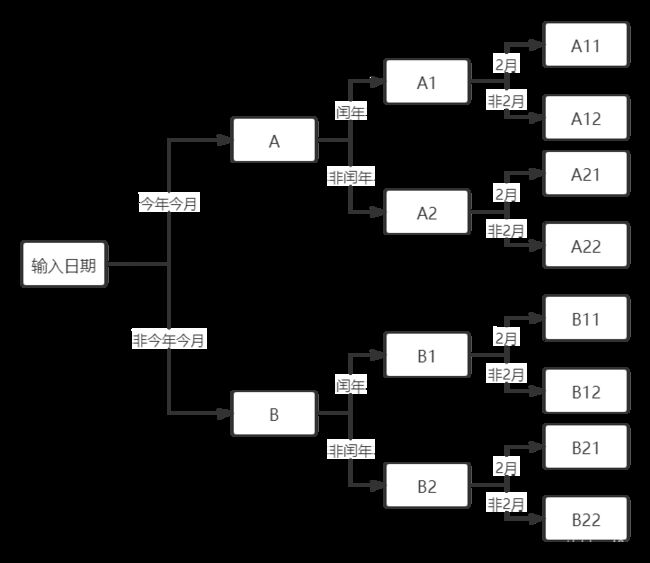
该部分代码如下
from datetime import datetime
def get_full_date(year, month): # 返回除2月外起始日期样式,类似20200504
month_31 = [1, 3, 5, 7, 8, 10, 12]
time_from = year + '%02d' % int(month) + '01'
if int(month) in month_31:
time_to = year + '%02d' % int(month) + '31'
else:
time_to = year + '%02d' % int(month) + '30'
return time_from, time_to
def time_from_to(year, month):
now_year = datetime.now().year
now_month = datetime.now().month
now_day = datetime.now().day
if (int(month) == now_month) & (int(year) == now_year): # 判断是否为今年本月,若是time_to最大只能为当前日期
time_from = str(now_year) + '%02d' % now_month + \
'01' # 十位数以下数字以0补全可用%02d
time_to = str(now_year)+'%02d' % now_month + '%02d' % now_day
else:
if int(year) % 4 == 0: #判断是否闰年
if int(month) == 2: #判断是否为二月,若输入2020年,则time_from和time_to为20200201、20200229
time_from = year + '0201'
time_to = year + '0229'
else:
time_from, time_to = get_full_date(year, month) #非二月份时间处理
else:
if int(month) == 2: #非闰年,对二月单独处理
time_from = year + '0201'
time_to = year + '0228'
else:
time_from, time_to = get_full_date(year, month) #非二月份时间处理
return time_from, time_to
2.3 书写爬虫函数
经过以上两部分的处理,我们再写爬虫函数就很简单啦。只需要将该两部分的信息,传给相应位置的参数即可,基本代码如下:
import re
import requests
import json
def crawl_hot_video():
tagid_dict = {
'动画区': 24,
'音乐区': 28,
'舞蹈区': 20,
'知识区': 201,
'生活区': 138,
'时尚区': 157,
'娱乐区': 71,
'游戏区': 17,
'数码区': 95,
'鬼畜区': 22,
'影视区': 182
}
date = E1.get() #获取用户输入的日期
tag_name = E2.get() #获取用户输入的分区名称
tag_id = tagid_dict[tag_name] #将分区名称转为ID
if '-' in date:
year = date.split('-')[0]
month = date.split('-')[1]
time_from, time_to = time_from_to(year, month)
else:
year = re.findall('\d+', date)[0]
month = re.findall('\d+', date)[1]
time_from, time_to = time_from_to(year, month)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.0; rv:2.0) Gecko/20100101 Firefox/4.0 Opera 12.14',
'refer': 'https://www.bilibili.com/'
}
url = 'https://s.search.bilibili.com/cate/search?'
params = {
'main_ver': 'v3',
'search_type': 'video',
'view_type': 'hot_rank',
'order': 'click',
'copy_right': -1,
'cate_id': tag_id, #传入ID
'page': 1,
'pagesize': 20,
'jsonp': 'jsonp',
'time_from': time_from, #传入查询视频初始时间
'time_to': time_to #传入查询视频结束时间
}
try:
r = requests.get(url, headers=headers, params=params)
data = json.loads(r.text)
inf_list = data['result']
author = data['result'][0]['author']
title = data['result'][0]['title']
pubdate = data['result'][0]['pubdate']
play = str(int(data['result'][0]['play'])/10000)+'万'
df = [author, title, pubdate, play]
column = ['UP主: ', '标题名: ', '发布时间: ', '播放量: ']
data1 = [i + j for i, j in zip(column, df)]
content = '\n'.join(data1)
t.insert('insert', ' 查询结果如下 \n')
t.insert('insert', content)
except Exception as result:
print(result)
三、全部代码
组合Tkinter部分及爬虫部分,最终代码如下:
import tkinter as tk
from datetime import datetime
import re
import requests
import json
from PIL import Image, ImageTk
def get_full_date(year, month): # 返回除2月外起始日期样式,类似20200504
month_31 = [1, 3, 5, 7, 8, 10, 12]
time_from = year + '%02d' % int(month) + '01'
if int(month) in month_31:
time_to = year + '%02d' % int(month) + '31'
else:
time_to = year + '%02d' % int(month) + '30'
return time_from, time_to
def time_from_to(year, month): #考虑年份因素,返回日期样式
now_year = datetime.now().year
now_month = datetime.now().month
now_day = datetime.now().day
if (int(month) == now_month) & (int(year) == now_year): # 判断是否为今年本月,若是time_to最大只能为当前日期
time_from = str(now_year) + '%02d' % now_month + \
'01' # 十位数以下数字以0补全可用%02d
time_to = str(now_year)+'%02d' % now_month + '%02d' % now_day
else:
if int(year) % 4 == 0: #判断是否闰年
if int(month) == 2: #判断是否为二月,若输入2020年,则time_from和time_to为20200201、20200229
time_from = year + '0201'
time_to = year + '0229'
else:
time_from, time_to = get_full_date(year, month) #非二月份时间处理
else:
if int(month) == 2: #非闰年,对二月单独处理
time_from = year + '0201'
time_to = year + '0228'
else:
time_from, time_to = get_full_date(year, month) #非二月份时间处理
return time_from, time_to
def crawl_hot_video():
tagid_dict = {
'动画区': 24,
'音乐区': 28,
'舞蹈区': 20,
'知识区': 201,
'生活区': 138,
'时尚区': 157,
'娱乐区': 71,
'游戏区': 17,
'数码区': 95,
'鬼畜区': 22,
'影视区': 182
}
date = E1.get()
tag_name = E2.get()
tag_id = tagid_dict[tag_name]
if '-' in date:
year = date.split('-')[0]
month = date.split('-')[1]
time_from, time_to = time_from_to(year, month)
else:
year = re.findall('\d+', date)[0]
month = re.findall('\d+', date)[1]
time_from, time_to = time_from_to(year, month)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.0; rv:2.0) Gecko/20100101 Firefox/4.0 Opera 12.14',
'refer': 'https://www.bilibili.com/'
}
url = 'https://s.search.bilibili.com/cate/search?'
params = {
'main_ver': 'v3',
'search_type': 'video',
'view_type': 'hot_rank',
'order': 'click',
'copy_right': -1,
'cate_id': tag_id,
'page': 1,
'pagesize': 20,
'jsonp': 'jsonp',
'time_from': time_from,
'time_to': time_to
}
try:
r = requests.get(url, headers=headers, params=params)
data = json.loads(r.text)
inf_list = data['result']
author = data['result'][0]['author']
title = data['result'][0]['title']
pubdate = data['result'][0]['pubdate']
play = str(int(data['result'][0]['play'])/10000)+'万'
df = [author, title, pubdate, play]
column = ['UP主: ', '标题名: ', '发布时间: ', '播放量: ']
data1 = [i + j for i, j in zip(column, df)]
content = '\n'.join(data1)
t.insert('insert', ' 查询结果如下 \n')
t.insert('insert', content)
except Exception as result:
print(result)
def get_image(file_name, width, height):
im = Image.open(file_name).resize((width, height))
return ImageTk.PhotoImage(im)
window = tk.Tk(className='bilibili热门视频查询')
window.geometry('700x450') # 窗口大小设置
# 背景画布设置
canvas = tk.Canvas(window, width=700, height=450)
img = get_image('C:/Users/dell/Desktop/2233.jpg', 700, 450)
canvas.create_image(350, 225, image=img)
canvas.pack()
# 标签
L1 = tk.Label(window, bg='Beige', text='日期:', font=('华文行楷', 15))
L2 = tk.Label(window, bg='Beige', text='分区:', font=('华文行楷', 15))
L1.place(x=250, y=80)
L2.place(x=250, y=120)
# 输入文本
E1 = tk.Entry(window, font=("华文行楷", 15), show=None, width=18)
E2 = tk.Entry(window, font=("华文行楷", 15), show=None, width=18)
E1.place(x=350, y=80)
E2.place(x=350, y=120)
t = tk.Text(window, width=25, height=6, font=(
"微软雅黑", 15), selectforeground='red') # 显示多行文本
t.place(x=225, y=280)
# 查询按钮
button = tk.Button(window, bg='SkyBlue', text="查询", font=('华文行楷', 15), width=15, height=2,
command=crawl_hot_video)
button.place(x=300, y=180)
window.mainloop()
思考与优化
1、本次爬取的视频其实是按照播放量的高低进行降序排列的(URL中对应的参数为search_type),后续在Tkinter中设置个下拉菜单,然后根据评论数、弹幕数、点赞数等字段进行排序,然后爬取。
2、每次点击查询按钮后,应该可以设置一个清空上次查询的内容的功能,有时间再来优化。
以上就是本次分享的全部内容~