Python爬虫入门笔记
最近又学了一遍爬虫的入门,记住步骤立刻就上手了
爬虫四大步骤
- 1.获取页面源代码
- 2.获取标签
- 3.正则表达式匹配
- 4.保存数据
1.获取页面源代码
5个小步骤:
1.伪装成浏览器
2.进一步包装请求
3.网页请求获取数据
4.解析并保存
5.返回数据
代码:
import urllib.request,urllib.error #指定URL,获取页面数据
#爬取指定url
def askUrl(url):
#请求头伪装成浏览器(字典)
head = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3776.400 QQBrowser/10.6.4212.400"}
#进一步包装请求
request = urllib.request.Request(url = url,headers=head)
#存储页面源代码
html = ""
try:
#页面请求,获取内容
response = urllib.request.urlopen(request)
#读取返回的内容,用"utf-8"编码解析
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reson"):
print(e.reson)
#返回页面源代码
return html
2.获取标签
通过BeautifulSoup进一步解析页面源代码
from bs4 import BeautifulSoup #页面解析,获取数据
Beautiful Soup 将复杂 HTML 文档转换成一个复杂的树形结构,每个节点都是 Python 对象,可分为四大对象种类,这里主要用到Tag类的对象,还有三种,有兴趣可以自己去深入学习~~
#构建了一个BeautifulSoup类型的对象soup
#参数为网页源代码和”html.parser”,表明是解析html的
bs = BeautifulSoup(html,"html.parser")
#找到所有class叫做item的div,注意class_有个下划线
bs.find_all('div',class_="item")
3.正则表达式匹配
先准备好相应的正则表达式,然后在上面得到的标签下手
#Python正则表达式前的 r 表示原生字符串(rawstring)
#该字符串声明了引号中的内容表示该内容的原始含义,避免了多次转义造成的反斜杠困扰
#re.S它表示"."的作用扩展到整个字符串,包括“\n”
#re.compile()编译后生成Regular Expression对象,由于该对象自己包含了正则表达式
#所以调用对应的方法时不用给出正则字符串。
#链接
findLink = re.compile(r'',re.S)
#找到所有匹配的
#参数(正则表达式,内容)
#[0]返回匹配的数组的第一个元素
link = re.findall(findLink,item)[0]
4.保存数据
两种保存方式
1.保存到Excel里
import xlwt #进行excel操作
def saveData(dataList,savePath):
#创建一个工程,参数("编码","样式的压缩效果")
woke = xlwt.Workbook("utf-8",style_compression=0)
#创建一个表,参数("表名","覆盖原单元格信息")
sheet = woke.add_sheet("豆瓣电影Top250",cell_overwrite_ok=True)
#列明
col = ("链接","中文名字","英文名字","评分","标题","评分人数","概况")
#遍历列名,并写入
for i in range (7):
sheet.write(0,i,col[i])
#开始遍历数据,并写入
for i in range (0,250):
for j in range (7):
sheet.write(i+1,j,dataList[i][j])
print("第%d条数据"%(i+1))
#保存数据到保存路径
woke.save(savePath)
print("保存完毕")
结果文件:![]()

2.保存到数据库
import sqlite3 #进行sql操作
#新建表
def initdb(dataPath):
#连接dataPath数据库,没有的话默认新建一个
conn = sqlite3.connect(dataPath)
#获取游标
cur = conn.cursor()
#sql语句
sql = '''
create table movie(
id Integer primary key autoincrement,
info_link text,
cname varchar ,
fname varchar ,
rating varchar ,
inq text,
racount varchar ,
inf text
)
'''
#执行sql语句
cur.execute(sql)
#提交事物
conn.commit()
#关闭游标
cur.close()
#关闭连接
conn.close()
def savedb(dataList,dataPath):
#新建表
initdb(dataPath)
#连接数据库dataPath
conn = sqlite3.connect(dataPath)
#获取游标
cur = conn.cursor()
#开始保存数据
for data in dataList:
for index in range(len(data)):
#在每个数据字段两边加上""双引号
data[index] = str('"'+data[index]+'"')
#用","逗号拼接数据
newstr = ",".join(data)
#sql语句,把拼写好的数据放入sql语句
sql ="insert into movie(info_link,cname,fname,rating,inq,racount,inf)values(%s)"%(newstr)
print(sql)
#执行sql语句
cur.execute(sql)
#提交事务
conn.commit()
#关闭游标
cur.close()
#关闭连接
conn.close()
print("保存完毕")
结果文件:
![]()
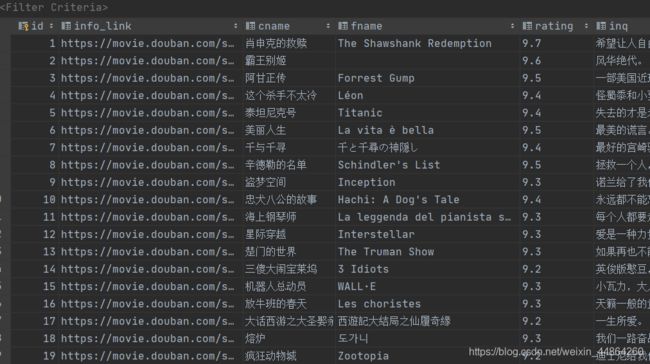
爬取豆瓣TOP250的所有代码
from bs4 import BeautifulSoup #页面解析,获取数据
import re #正则表达式
import urllib.request,urllib.error #指定URL,获取页面数据
import xlwt #进行excel操作
import sqlite3 #进行sql操作
def main():
baseUrl = "https://movie.douban.com/top250?start="
#1.爬取网页,并解析数据
dataList = getData(baseUrl)
# savePath=".\\豆瓣电影Top250.xls"
savePath = "movies.db"
#2.保存数据
# saveData(dataList,savePath)
savedb(dataList,savePath)
#---正则表达式---
#链接
findLink = re.compile(r'',re.S)
#电影名字
findName = re.compile(r'(.*?)',re.S)
#评分
findRating = re.compile(r'')
#标题
findInq = re.compile(r'(.*?)',re.S)
#评分人数
findCount = re.compile(r'(.*?)人评价')
#电影信息
findInf = re.compile(r'(.*?)
',re.S)
#1.爬取网页
def getData(baseUrl):
dataList = []
for i in range(10):
html = askUrl(baseUrl + str(i * 25))
# 2.逐一解析数据
bs = BeautifulSoup(html,"html.parser")
for item in bs.find_all('div',class_="item"):
data = []
item = str(item)
#链接
link = re.findall(findLink,item)[0]
#名字
name = re.findall(findName,item)
if len(name) == 1:
cName = name[0]
fName = " "
else:
name[1] = name[1].replace(" / ","")
cName = name[0]
fName = name[1]
#评分
rating = re.findall(findRating,item)[0]
#标题
inq = re.findall(findInq,item)
if len(inq) < 1:
inq = " "
else:
inq= inq[0]
#评分人数
racount = re.findall(findCount,item)[0]
#电影信息
inf = re.findall(findInf,item)[0]
inf = re.sub("...愉快爬虫:
遵守 Robots 协议,但有没有 Robots 都不代表可以随便爬,可见下面的大众点评百度案;
限制你的爬虫行为,禁止近乎 DDOS的请求频率,一旦造成服务器瘫痪,约等于网络攻击;
对于明显反爬,或者正常情况不能到达的页面不能强行突破,否则是 Hacker行为;
最后,审视清楚自己爬的内容,以下是绝不能碰的红线(包括但不限于): 作者:张凯强
链接:https://www.zhihu.com/question/291554395/answer/514982754
来源:知乎
著作权归作者所有。