Python学习笔记8——Series与DataFrame中的层次化索引
目录
- 前言
- Series层次化索引
- DataFrame层次化索引
- 总结
- 附录代码
前言
层次化索引又叫多级索引,是指单个轴上的数据有两个或以上的索引。
以二级索引为例,在Series中表现为一个元素由两个索引值共同确定;在DataFrame中表现为一个元素由两个行索引和两个列索引(即4个索引)共同确定。
Series层次化索引
构建一个简单的二级索引序列:

左边红色框中为索引值,右边蓝色框中为元素值。
可以查看该序列的索引信息:

可以看到索引值为一个二维表。
按索引值访问序列 S1 的元素:

这里就很明显看出,在这个序列中,单单靠一级或者二级索引是不能访问到唯一值的。
当然,默认的索引值访问依然是可行的:

看看切片访问:

由于二级索引的存在,通过 unstack() 方法就可以将序列 S1 转换为一个二维表:

也可以逆向将二维表转换为含有二级索引的序列,使用 stack() 方法:

DataFrame层次化索引
数据准备:这里的数据样本直接选取了一小部分之前的爬虫数据(20行)。jingdian2.csv
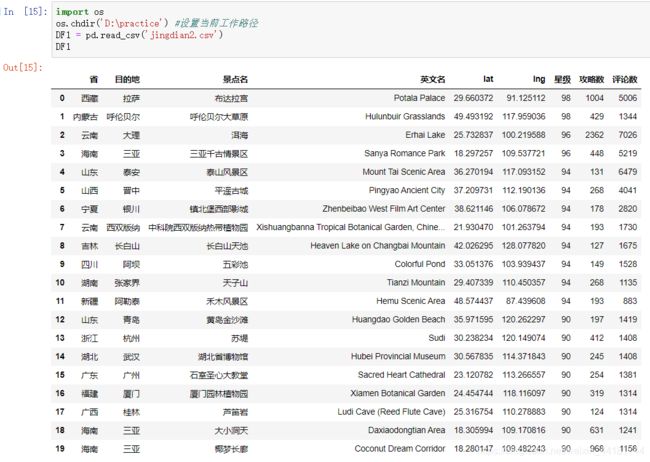
构建多级索引:在数据导入的这一步,可以利用原数据表直接构建多级索引。
这里将“星级”、“攻略数”、“评论数”三列(最后3列)作为行索引:

#导入时也可以直接使用列名进行列的选择
DF2 = pd.read_csv('jingdian2.csv',index_col=['星级','攻略数','评论数'])
#还可以通过 set_index()方法设置索引,导入表格时无需其他操作
DF3 = pd.read_csv('jingdian2.csv')
DF33 = DF3.set_index(['星级','攻略数','评论数'])
DF33
#可以添加参数“drop=False”将转换为索引的列保留在DataFrame中
DF333 = DF3.set_index(['星级','攻略数','评论数'],drop=False)
DF333 #输出结果如下图
#与set_index()相逆的函数是reset_index(),它可以将多级的索引转换到二维表中作为列
DF3333 = DF33.reset_index() #这里就不展示结果了
DF3333

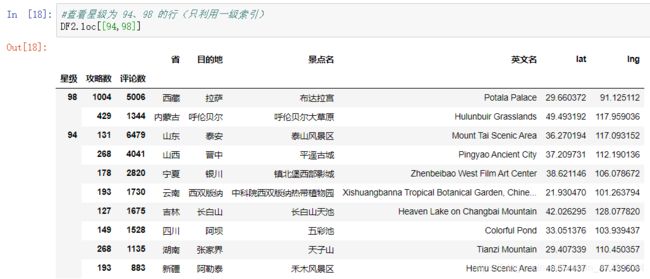
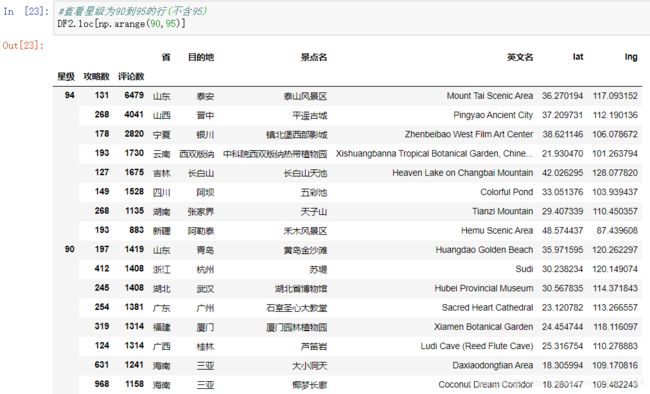
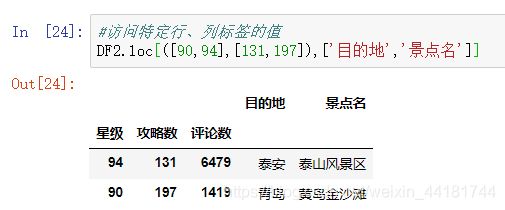
访问二维表的元素:这里列出各种具体的访问方法,读者自行实操体会。



总结
1) 由于层次化索引的存在,高纬度的数据也可以通过低纬度的展示方法来查看,如可通过一维的 Series 查看二维的 DataFrame 数据;
2) 通过 unstack() 和 stack() 方法可实现 Series 和 DataFrame 之间的转换;
3) 在 DataFrame 的多级索引中访问特定行或元素,通常使用 loc 方法,也可以使用 iloc ;
4) 在访问 DataFrame 的多级索引时,选择同一级索引中的多个要用方括号“[ ]”,同时选择多个层级的索引时用小括号“( )”。
附录代码
import pandas as pd
import numpy as np
****Series篇****
#创建二级索引的Series
S1 = pd.Series(np.arange(1,10),index = [['A','A','A','B','B','B','C','C','C'],
['a','b','c','a','b','c','a','b','c']])
S1
#查看序列S1的索引
S1.index
#按一级索引访问
S1['A']
#按二级索引访问
S1[:,'a']
#同时确定一、二级索引访问
S1['A','b']
#访问 S1 中第二个元素
S1[1]
#切片访问
S1['A':'B']
#利用unstack()方法将二级索引的序列转换成二维表
S1.unstack()
#stack()逆操作
S1.unstack().stack()
****DataFrame篇****
import os
os.chdir('D:\practice') #设置当前工作路径
DF1 = pd.read_csv('jingdian2.csv')
DF1
#将原表格的7、8、9三列作为索引
DF2 = pd.read_csv('jingdian2.csv',index_col=[6,7,8]) #方法1
DF2
DF2 = pd.read_csv('jingdian2.csv',index_col=['星级','攻略数','评论数']) #方法2
DF2
###############
#通过 set_index()方法设置索引,导入表格时无需其他操作
DF3 = pd.read_csv('jingdian2.csv')
DF33 = DF3.set_index(['星级','攻略数','评论数'])
DF33
#添加参数“drop=False”将转换为索引的列保留在DataFrame中
DF333 = DF3.set_index(['星级','攻略数','评论数'],drop=False)
DF333
#reset_index()可将多级的索引转换到二维表中作为列
DF3333 = DF33.reset_index()
DF3333
###############
#查看星级为 96 的行(只利用一级索引)
DF2.loc[96]
#查看星级为 94、98 的行(只利用一级索引)
DF2.loc[[94,98]]
#查看星级为90到95的行(不含95)(只利用一级索引)
DF2.loc[np.arange(90,95)]
#查看星级为 94,攻略数为 193 的行(利用一、二级索引)
DF2.loc[(94,193),] #方法1
DF2.loc[94].loc[193] #方法2
#定向访问多个二级索引
DF2.loc[(94,[131,178]),]
#访问特定行、列标签所对应的值
DF2.loc[([90,94],[131,197]),['目的地','景点名']]