Python数据分析基础——CSV文件——筛选特定的行
CSV文件——筛选特定的行
参考文献:《Python数据分析基础》《Python标准库》《Python编程从入门到实践》
一.行中的值满足某个条件
有时,当行中的值满足一个具体条件时,才需要保留这些行。在这种情况下,可以检验行中的值是否满足具体的条件,然后筛选出满足条件的行。
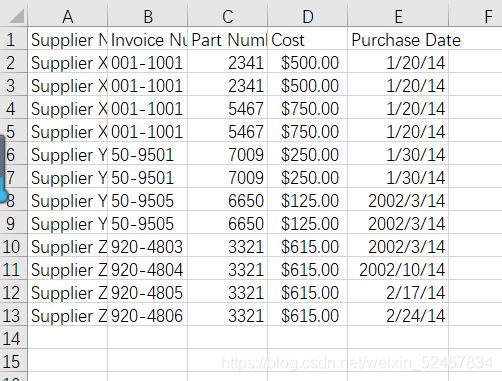
例如在如图给出的supplier_data.csv文件中,假设需要保留供应商名字(Supplier Name)为Supplier Z或者成本(Cost)大于$600.00的行。要完成此项操作,不难想到,构建符合筛选条件的控制流语句即可。
下面我们就来实现上述的构想。
首先在文本编译器(小编使用的是Pycharm)中输入以下代码,保存为:3csv_reader_value_meets_condition.py
#!/usr/bin/env python3
import csv
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'w', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
header = next(filereader)
filewriter.writerow(header)
for row_list in filereader:
supplier = str(row_list[0]).strip()
cost = str(row_list[3]).strip('$').replace(',', '')
if supplier == 'Supplier Z' or float(cost) > 600.0:
filewriter.writerow(row_list)
由于与《CSV文件读写》中主体代码相同,所以下面讨论一下与其相异代码块的含义
header = next(filereader)
这一行代码使用了csv模块的next函数读出输入文件的第一行,赋给名为header的列表变量。简单介绍一下next函数,它常常用来打印文件头,在本例中即为标题行。
supplier = str(row_list[0]).strip()
这一行代码使用了str函数与strip函数组合的方式,将每一行中第一个元素,即供应商名称,转换成一个字符型,并删除两端的空格、制表符和换行符。最后赋给变量supplier。
cost = str(row_list[3]).strip('$').replace(',', '')
这一行代码,同上,使用了str函数与strip函数组合的方式,将每行数据中的成本(Cost),变换为字符串的形式并删除$。接着使用replace函数从字符串中删除逗号。最后赋给变量cost。
if supplier == 'Supplier Z' or float(cost) > 600.0:
这一行代码就是上文提到需要构建的控制流语句,这里需要注意一个细节,变量cost需要使用float函数变换为浮点数再与600.0进行比较。
运行这个脚本
在《CSV文件读写》中有详细的运行脚本操作,这里不再进行赘述了。
输入以下命令:
![]()
在这里提示一点:千万不要忘记开头的python!
在屏幕上不会看到任何输出,但可以打开输出文件0_3output.csv看一下结果。
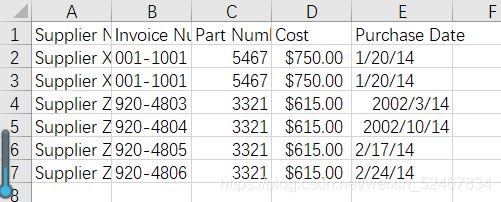
很显然,结果正确。
二.行中的值属于某个集合
有时,当行中的值属于某个集合时,才需要保留这些行。在这种情况下,可以检验行中的值是否属于某个集合,然后筛选出具有属于该集合的值的行。
例如在给出的supplier_data.csv文件中,需要保留那些购买日期属于集合{‘1/20/14’, ‘1/30/14’}的行,和上述介绍的方法大同小异,我们需要构建符合筛选条件的控制流语句。
首先,在文本编译器(小编使用的是Pycharm)中输入以下代码,保存为:4csv_reader_value_in_set.py
#!/usr/bin/env python3
import csv
import sys
input_file = sys.argv[1]
output_file = sys.argv[2]
important_dates = ['1/20/14', '1/30/14']
with open(input_file, 'r', newline='') as csv_in_file:
with open(output_file, 'w', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
header = next(filereader)
filewriter.writerow(header)
for row_list in filereader:
a_date = row_list[4]
if a_date in important_dates:
filewriter.writerow(row_list)
下面讨论一下部分代码的含义
important_dates = ['1/20/14', '1/30/14']
这一行代码创建了包含两个特定日期的列表,也就是筛选条件的集合。使用这种方式,如果变量值发生了改变,只需在一个地方修改代码(就是定义变量的地方),变量的变化就会反映到代码中所有引用该变量的地方。
a_date = row_list[4]
if a_date in important_dates:
这两行代码,第一行取出每一行的购买日期,第二行创建了一个if的控制流语句,判断取出的购买日期是否包含在集合里面。如果变量值在集合中,下一行代码就将这一行写入输出文件。
在命令行运行该脚本:
![]()
打开4output.csv文件查看一下结果:
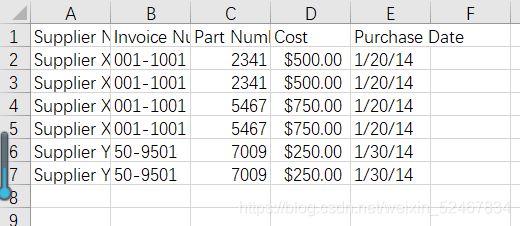
结果正确。
三.行中的值匹配于某个模式/正则表达式
有时,当行中的值匹配了或包含了一个特定模式(也就是正则表达式)时,才需要保留这些行。在这种情况下,你可以检验行中的值是否匹配或包含某种模式,然后筛选出匹配了或包含了该模式的行。例如,假设在此文件中,想要保留发票号开始于’001-'的行,或保留供应商名字中包含‘Y’的行。
简单引入正则表达式
Python包含了re模块,它提供了在文本中搜素特的特定模式(也就是正则表达式)的强大功能。要在脚本中使用re模块提供的功能,需要在脚本上方加入import re这行代码。如:
#!/usr/bin/env python3
import re
通过导入re模块,可以使用一大波函数和元字符来创建和搜素任意复杂的模式。
元字符是正则表达式中具有特殊意义的字符。每个字符都有特殊的意义,它们使正则表达式能够匹配特定的字符串。
(在这里只是简单的介绍一下正则表达式,可以在Python标准库(https://docs.python.org/zh-cn/3/library/re.html)或其他资料中获取更多的信息)
首先,在文本编译器(小编使用的是Pycharm)中输入以下代码,保存为:5csv_reader_value_matches_pattern.py
#!/usr/bin/env python3
import csv
import sys
import re
inputfile = sys.argv[1]
outputfile = sys.argv[2]
pattern = re.compile(r'(?P^001-.*)' ,re.I)
with open(inputfile, 'r', newline='') as csv_in_file:
with open(outputfile, 'w', newline='') as csv_out_file:
filereader = csv.reader(csv_in_file)
filewriter = csv.writer(csv_out_file)
header = next(filereader)
filewriter.writerow(header)
for row_list in filereader:
invoice_number = row_list[1]
if pattern.search(invoice_number):
filewriter.writerow(row_list)
下面重点刨析一下与正则表达式相关的代码
pattern = re.compile(r'(?P^001-.*)' ,re.I)
re.compile函数将文本形式的模式编译成为编译后的正则表达式。正则表达式不是必须编译的,但是编译是个好习惯,因为这样可以显著地提高程序运行速度。
(?P
这里实际搜索的实际模式是^001-.*。插入符号 ^ 表示只在字符串开头搜素模式。所以字符串需要以’001-‘开头。’.‘可以匹配任何字符,除了换行符。’ * ’ b表示重复前面的字符0次或者更多次。’. * '组合在一起,简而言之,在本例中,只要是字符串起始于’001-'就会匹配正则表达式。
re.I函数确保模式是不区分大小写的。
if pattern.search(invoice_number):
search函数则是寻找模式。
在命令行运行该脚本:
![]()
打开5_output.csv文件查看

结语
本篇博客主要介绍了CSV文件筛选特定行的知识及相关操作,同时引入了正则表达式的知识,对书上知识进行了实操并总结方法。