Python数据分析基础——CSV文件——读取多个CSV文件
参考文献:《Python数据分析基础》
前言
在大多数情况下,需要处理的文件很多。在这种情况下,Python会给你带来惊喜,因为它可以让你自动化和规模化地进行数据处理,远远超过手工处理能够达到的限度。
创建多个CSV文件
为了处理多个CSV文件,首先需要创建多个CSV文件。在本文中只创建了三个文件,而在实际应用中,可以拓展为任意多的文件。
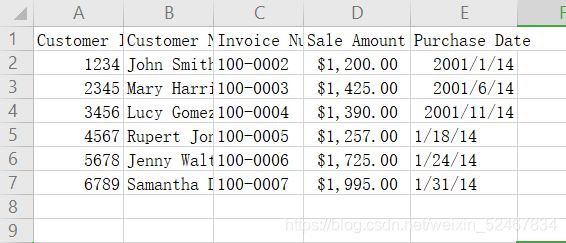
将第一个CSV文件命名为:sales_january_2014.csv
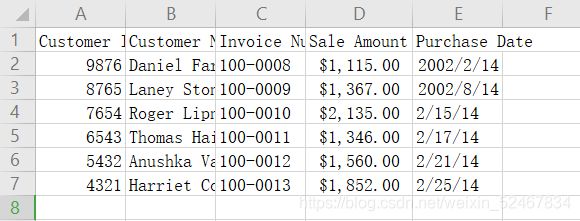
将第二个CSV文件命名为:sales_january_2014.csv
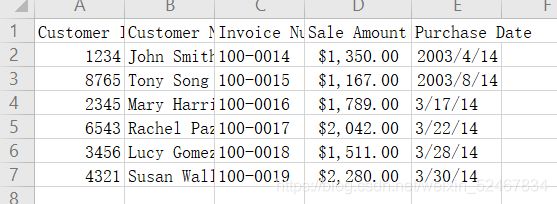
将第三个CSV文件命名为:sales_march_2014.csv
最后,将上述三个CSV文件存储在名为sale的文件夹中。
文件计数与文件中的行列计数
从简单的行列计数开始学习处理多个CSV文件。
创建脚本
在文本编辑器中输入一段代码,然后将文件保存为:8_csv_reader_counts_for_multiple_files.py
#!/usr/bin/env python3
import csv
import glob
import os
import sys
input_path = sys.argv[1]
file_counter = 0
for input_file in glob.glob(os.path.join(input_path,'sales_*')):
row_counter = 1
with open(input_file, 'r', newline='') as csv_in_file:
filereader = csv.reader(csv_in_file)
header = next(filereader)
for row in filereader:
row_counter += 1
print('{0!s}: \t{1:d} rows \t{2:d} columns'.format(os.path.basename(input_file), row_counter, len(header)))
file_counter += 1
print('Number of files: {0:d}'.format(file_counter))
脚本代码思想
脚本通过文件夹sale的文件路径(保存在argv[1]中),访问其中的三个文件。建立控制流语句和循环体进行系列操作。
脚本代码注释
input_path = sys.argv[1]
这一行代码创建了input_path变量,并将文件夹sale的文件路径赋值给它。
for input_file in glob.glob(os.path.join(input_path,'sales_*')):
这一行代码包含了glob模块和os模块。glob模块可以定位匹配于某个特定模式的所有路径名。os模块包含了用于解析路径名的函数。
此行代码创建了for循环,并使用glob模块和os模块创建了一个输入文件的列表。首先os.path.join函数将圆括号中的两部分连接起来,input_path是包含输入文件的文件夹的路径,'sales_* '代表任何以’sale_'开头的文件名。glob.glob函数将’sales_* ‘中的星号(*)转换为实际的文件名。’ * '为通配符。
这里简单区分一下通配符和正则表达式。通配符由shell解析,一般由于文件名匹配。正则表达式一般用来匹配字符串。
header = next(filereader)
这一行代码在之前处理单个CSV文件中很常见,大部分用作提取标题行。在这里,用来后续统计列数。
最后,小编提示一下,在这个脚本中,嵌套结构较多,进行缩进时要细心。
运行脚本
在命令行输入以下命令,然后按回车键:
![]()
查看结果

结语
本篇博客介绍读取多个CSV文件的方法,总结了实际操作,需重点理解处理思想,掌握各个函数模块的作用及知识。