数据库中间件 Mycat(一)读写分离、分库分表
Table of Contents
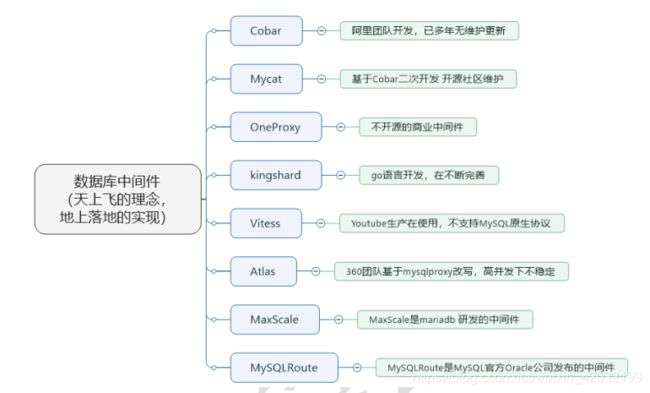
1.数据库中间件
2.Mycat介绍
3.Mycat 安装与使用(linux)
3.1下载
3.2解压后即可使用
3.3运行命令
3.4内存配置
4.Mycat配置
4.1修改配置文件server.xml
4.2修改配置文件 schema.xml
5.验证数据库访问情况
6.启动程序
7.登录
7.1登录后台管理窗口
7.2登录数据窗口
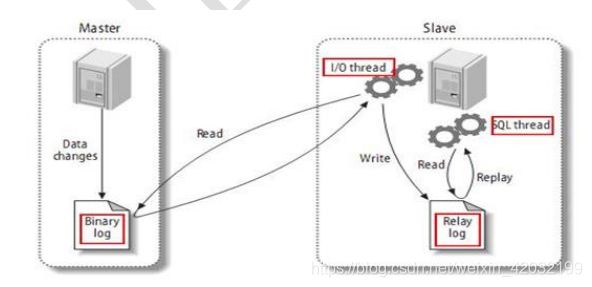
8.搭建读写分离
8.1搭建一主一从
8.2读写分离
8.3搭建双主双从
8.4双主双从读写分离
9.垂直拆分——分库
10.水平拆分——分表
10.1修改配置文件 schema.xml
10.2修改配置文件 rule.xml
10.3 在数据节点 dn2 上建 orders 表
10.4重启 Mycat 测试
11.分表后的“join”查询解决
11.1 ER Join
11.2 全局表
12.常用分片规则
12.1 取模
12.2 分片枚举
12.3 范围约定
12.4 按日期(天)分片
13.全局序列
13.1 本地文件
13.2 数据库方式
13.3 时间戳方式
13.4 自主生成全局序列
1.数据库中间件
2.Mycat介绍
官网:
http://mycat.org.cn/
https://github.com/MyCATApache/Mycat-Server/wiki
Mycat 的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的 SQL 语句,首先对 SQL 语句做了 一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此 SQL 发往后端的真实数据库, 并将返回的结果做适当的处理,最终再返回给用户。
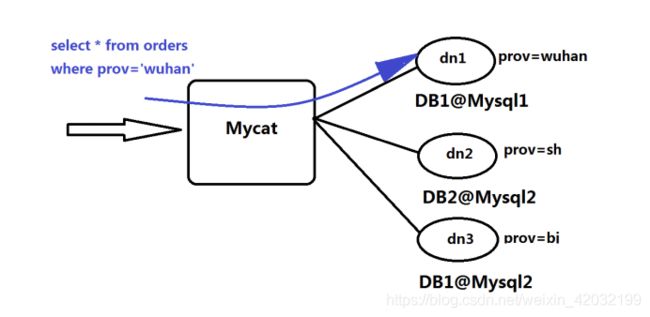
当 Mycat 收到一个 SQL 时,会先解析这个 SQL,查找涉及到的表,然后看此表的定义,如果有分片规则, 则获取到 SQL 里分片字段的值,并匹配分片函数,得到该 SQL 对应的分片列表,然后将 SQL 发往这些分片去执 行,最后收集和处理所有分片返回的结果数据,并输出到客户端。以 select * from Orders where prov=?语句为 例,查到 prov=wuhan,按照分片函数,wuhan 返回 dn1,于是 SQL 就发给了 MySQL1,去取 DB1 上的查询 结果,并返回给用户。
3.Mycat 安装与使用(linux)
3.1下载
https://github.com/MyCATApache/Mycat-download
3.2解压后即可使用
tar -zxvf Mycat-server-1.6-release-20190627191042-linux.tar.gz 
3.3运行命令
./mycat start 启动
./mycat stop 停止
./mycat console 前台运行
./mycat install 添加到系统自动启动(暂未实现)
./mycat remove 取消随系统自动启动(暂未实现)
./mycat restart 重启服务
./mycat pause 暂停
./mycat status 查看启动状态
3.4内存配置
启动前,一般需要修改JVM配置参数,打开conf/wrapper.conf文件,如下行的内容为2G和2048,可根据本机配置情况修改为512M或其它值。 以下配置跟jvm参数完全一致,可以根据自己的jvm参数调整。
Java Additional Parameters
wrapper.java.additional.1=
wrapper.java.additional.1=-DMYCAT_HOME=.
wrapper.java.additional.2=-server
wrapper.java.additional.3=-XX:MaxPermSize=64M
wrapper.java.additional.4=-XX:+AggressiveOpts
wrapper.java.additional.5=-XX:MaxDirectMemorySize=100m
wrapper.java.additional.6=-Dcom.sun.management.jmxremote
wrapper.java.additional.7=-Dcom.sun.management.jmxremote.port=1984
wrapper.java.additional.8=-Dcom.sun.management.jmxremote.authenticate=false
wrapper.java.additional.9=-Dcom.sun.management.jmxremote.ssl=false
wrapper.java.additional.10=-Xmx100m
wrapper.java.additional.11=-Xms100m
wrapper.java.additional.12=-XX:+UseParNewGC
wrapper.java.additional.13=-XX:+UseConcMarkSweepGC
wrapper.java.additional.14=-XX:+UseCMSCompactAtFullCollection
wrapper.java.additional.15=-XX:CMSFullGCsBeforeCompaction=0
wrapper.java.additional.16=-XX:CMSInitiatingOccupancyFraction=70
4.Mycat配置
--server.xml:是Mycat服务器参数调整和用户授权的配置文件。
--schema.xml:是逻辑库定义和表以及分片定义的配置文件。
--rule.xml: 是分片规则的配置文件,分片规则的具体一些参数信息单独存放为文件,也在这个目录下,配置文件修改需要重启MyCAT。
--log4j.xml: 日志存放在logs/log中,每天一个文件,日志的配置是在conf/log4j.xml中,根据自己的需要可以调整输出级别为debug debug级别下,会输出更多的信息,方便排查问题。
--autopartition-long.txt,partition-hash-int.txt,sequence_conf.properties, sequence_db_conf.properties 分片相关的id分片规则配置文件
--lib MyCAT自身的jar包或依赖的jar包的存放目录。
--logs MyCAT日志的存放目录。日志存放在logs/log中,每天一个文件
4.1修改配置文件server.xml
修改用户信息,与MySQL区分,如下:

4.2修改配置文件 schema.xml
se nu展示行号,dd删除一行,d2d删除两行
select user()
5.验证数据库访问情况
错误代码: 1064
You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'IDENTIFIED BY '123456'' at line 1
原因:主机的mysql版本为8.0,授权不支持:GRANT ALL PRIVILEGES ON *.* TO 'root'@'192.168.71.128' IDENTIFIED BY '123456';
需拆分(主机执行):
CREATE USER 'root'@'192.168.71.128' IDENTIFIED BY '123456';
GRANT ALL PRIVILEGES ON *.* TO 'root'@'192.168.71.128' WITH GRANT OPTION;
6.启动程序
启动方式看前面运行命令【3.运行命令】

7.登录
7.1登录后台管理窗口
此登录方式用于管理维护 Mycat
mysql -umycat -p123456 -P9066 -h192.168.71.128

7.2登录数据窗口
8.搭建读写分离
8.1搭建一主一从

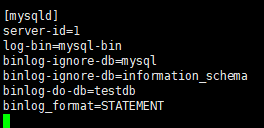
#修改配置文件:vim /etc/my.cnf (docker安装的db,vim/etc/mysql/my.cnf)
[mysqld]
#主服务器唯一ID
server-id=1
#启用二进制日志
log-bin=mysql-bin
# 设置不要复制的数据库(可设置多个)
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
#设置需要复制的数据库
binlog-do-db=需要复制的主数据库名字
#设置logbin格式
binlog_format=STATEMENT
#改配置文件:vim /etc/my.cnf (docker安装的db,vim/etc/mysql/my.cnf)
[mysqld]
#从服务器唯一ID
server-id=2
#启用中继日志
relay-log=mysql-relay
GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%' IDENTIFIED BY '123456';
#如果之前挂载过主机,需重置
STOP SLAVE;
RESET MASTER;
#复制主机的命令
CHANGE MASTER TO MASTER_HOST='192.168.71.128',
MASTER_USER='slave',
MASTER_PASSWORD='123456',
MASTER_PORT=13306,
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=430;
#启动从服务器复制功能
START SLAVE;
#查看从服务器状态
SHOW SLAVE STATUS;
8.2读写分离
①验证是否读写分离
SELECT @@hostname;
13306主机:

23306从机:

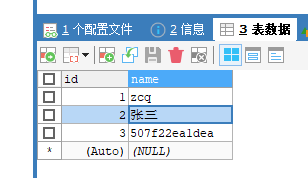
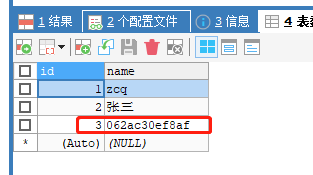
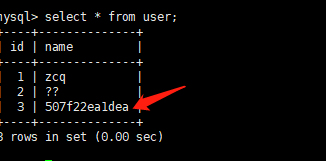
主从主机数据不一致了,查询是主机的数据。
原因:balance=“0“
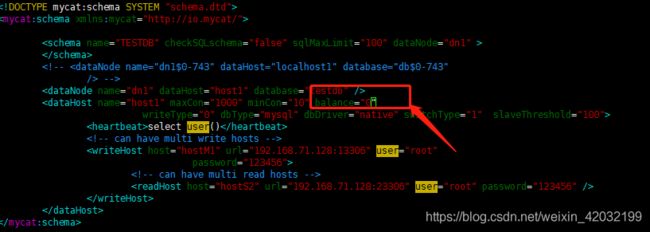
(1)balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost 上。
(2)balance="1",全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从
模式(M1->S1,M2->S2,并且 M1 与 M2 互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载均衡。
(3)balance="2",所有读操作都随机的在 writeHost、readhost 上分发。
(4)balance="3",所有读请求随机的分发到 readhost 执行,writerHost 不负担读压力
故:一主一从应配置为 3,多主多从应配置为 1.
重启mycat即可
8.3搭建双主双从
| 编号 | 角色 | IP 地址 | |
| 1 | Master1 | 192.168.71.128:13306 | |
| 2 | Slave1 | 192.168.71.128:23306 | |
| 3 | Master2 | 192.168.71.128:13307 | |
| 4 | Slave2 | 192.168.71.128:23307 |

①把前面的13306和23306的主从删除,并删除testdb
②分别修改my.cnf
Master1(13306)
[mysqld]
#主服务器唯一ID
server-id=1
#启用二进制日志
log-bin=mysql-bin
# 设置不要复制的数据库(可设置多个)
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
#设置需要复制的数据库
binlog-do-db=testdb
#设置logbin格式
binlog_format=STATEMENT
# 在作为从数据库的时候,有写入操作也要更新二进制日志文件
log-slave-updates
#表示自增长字段每次递增的量,指自增字段的起始值,其默认值是1,取值范围是1 .. 65535
auto-increment-increment=2
# 表示自增长字段从哪个数开始,指字段一次递增多少,他的取值范围是1 .. 65535
auto-increment-offset=1
Master2(13307)
[mysqld]
#主服务器唯一ID
server-id=3
#启用二进制日志
log-bin=mysql-bin
# 设置不要复制的数据库(可设置多个)
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
#设置需要复制的数据库
binlog-do-db=testdb
#设置logbin格式
binlog_format=STATEMENT
# 在作为从数据库的时候,有写入操作也要更新二进制日志文件
log-slave-updates
#表示自增长字段每次递增的量,指自增字段的起始值,其默认值是1,取值范围是1 .. 65535
auto-increment-increment=2
# 表示自增长字段从哪个数开始,指字段一次递增多少,他的取值范围是1 .. 65535
auto-increment-offset=2
Slave1(23306)
[mysqld]
#从服务器唯一ID
server-id=2
#启用中继日志
relay-log=mysql-relay
Slave2(23307)
[mysqld]
#从服务器唯一ID
server-id=4
#启用中继日志
relay-log=mysql-relay
③重启 mysql 服务、检查防火墙
④在两台主机上建立帐户并授权 slave 并查询主机状态
GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%' IDENTIFIED BY '123456';
SHOW MASTER STATUS;Master1(13306)

Master2(13307)
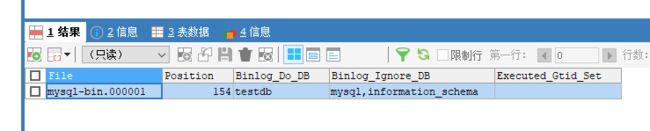
⑤在从机上配置需要复制的主机
Slave1(23306)
#如果之前挂载过主机,需重置
STOP SLAVE;
RESET MASTER;
#复制主机的命令
CHANGE MASTER TO MASTER_HOST='192.168.71.128',
MASTER_USER='slave',
MASTER_PASSWORD='123456',
MASTER_PORT=13306,
MASTER_LOG_FILE='mysql-bin.000002',
MASTER_LOG_POS=324;
#启动从服务器复制功能
START SLAVE;
#查看从服务器状态
SHOW SLAVE STATUS;Slave2(23307)
#如果之前挂载过主机,需重置
STOP SLAVE;
RESET MASTER;
#复制主机的命令
CHANGE MASTER TO MASTER_HOST='192.168.71.128',
MASTER_USER='slave',
MASTER_PASSWORD='123456',
MASTER_PORT=13307,
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=154;
#启动从服务器复制功能
START SLAVE;
#查看从服务器状态
SHOW SLAVE STATUS;⑥两个主机互相复制
Master1(13306)
#复制主机的命令
CHANGE MASTER TO MASTER_HOST='192.168.71.128',
MASTER_USER='slave',
MASTER_PASSWORD='123456',
MASTER_PORT=13307,
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=154;
#启动从服务器复制功能
START SLAVE;
#查看从服务器状态
SHOW SLAVE STATUS;Master2(13307)
#复制主机的命令
CHANGE MASTER TO MASTER_HOST='192.168.71.128',
MASTER_USER='slave',
MASTER_PASSWORD='123456',
MASTER_PORT=13306,
MASTER_LOG_FILE='mysql-bin.000002',
MASTER_LOG_POS=324;
#启动从服务器复制功能
START SLAVE;
#查看从服务器状态
SHOW SLAVE STATUS;⑦Master1 主机新建库、新建表、insert 记录,Master2 和从机都会复制。
8.4双主双从读写分离
修改 mycat schema.xml
负载均衡类型,目前的取值有4 种:
(1)balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost 上。
(2)balance="1",全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从
模式(M1->S1,M2->S2,并且 M1 与 M2 互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载均衡。
(3)balance="2",所有读操作都随机的在 writeHost、readhost 上分发。
(4)balance="3",所有读请求随机的分发到 readhost 执行,writerHost 不负担读压力#writeType="0": 所有写操作发送到配置的第一个writeHost,第一个挂了切到还生存的第二个
#writeType="1",所有写操作都随机的发送到配置的 writeHost,1.5 以后废弃不推荐
#writeHost,重新启动后以切换后的为准,切换记录在配置文件中:dnindex.properties 。
#switchType="1": 1 默认值,自动切换。
# -1 表示不自动切换
# 2 基于 MySQL 主从同步的状态决定是否切换。
select user()
重启mycat测试
验证:Master1、Master2 互做备机,负责写的主机宕机,备机切换负责写操作,保证数据库读写分离高
可用性。
1.mycat中插入数据,只会查询 M2、S1、S2,M1只写操作。
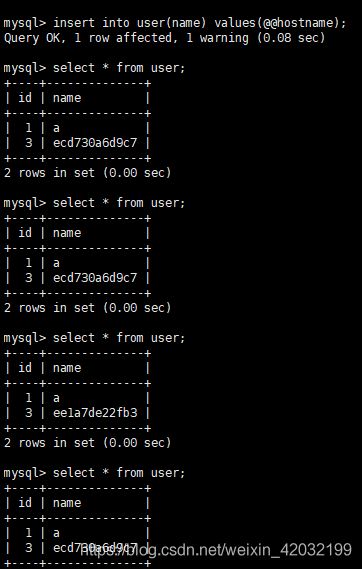
根据M1中的数据查询不到

2.关闭M1,会切换到 M2为写主机,mycat中写入数据只有存在M2、S2
3.启动M1后,前面写的数据会同步到M1和S1,且M1为读的主机。
根据查询条件,M1中可以查询到,M2查询不到
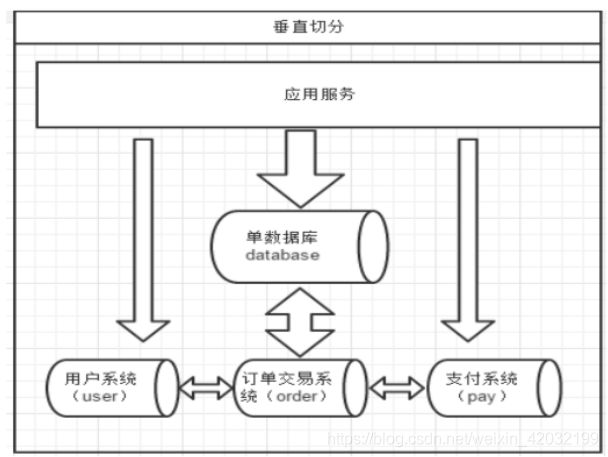
9.垂直拆分——分库
原则:有紧密关联关系的表应该在一个库里,相互没有关联关系的表可以分到不同的库里。
#客户表
CREATE TABLE customer(
id INT AUTO_INCREMENT,
NAME VARCHAR(200),
PRIMARY KEY(id)
);
#订单表
CREATE TABLE orders(
id INT AUTO_INCREMENT,
order_type INT,
customer_id INT,
amount DECIMAL(10,2),
PRIMARY KEY(id));
#订单详细表
CREATE TABLE orders_detail(
id INT AUTO_INCREMENT,
detail VARCHAR(2000),
order_id INT,
PRIMARY KEY(id)
);
#订单状态字典表
CREATE TABLE dict_order_type(
id INT AUTO_INCREMENT,
order_type VARCHAR(200),
PRIMARY KEY(id)
);客户表分在一个数据库:13306数据库orders
另外三张都需要关联查询,分在另外一个数据库:13307数据库orders
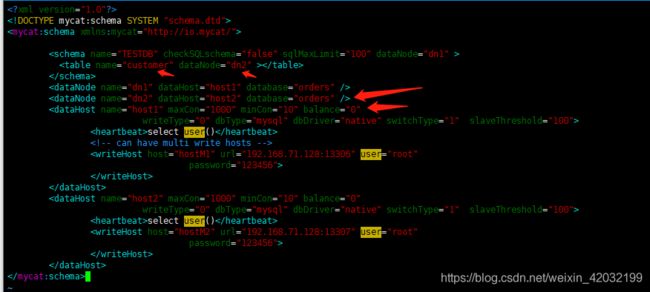
修改 schema 配置文件
select user()
select user()
在数据节点 dn1、dn2 上分别创建数据库 orders
CREATE DATABASE orders;重启mycat,执行上面建表语句
结果:
13306数据库orders:只创建customer表
13307数据库orders:创建其他三个表
10.水平拆分——分表
按照数据行的切分,将表中的某些行切分 到一个数据库,而另外的某些行又切分到其他的数据库中。
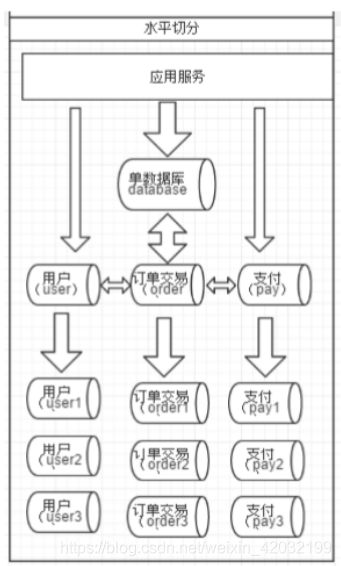
针对订单表,可根据customer_id(客户 id) 去分,两个节点访问平均,一个客户的所
有订单都在同一个节点。
10.1修改配置文件 schema.xml
为 orders 表设置数据节点为 dn1、dn2,并指定分片规则为 mod_rule(自定义的名字),
选择分片算法 mod-long(对字段求模运算),customer_id 对两个节点求模,根据结果分片

10.2修改配置文件 rule.xml
在 rule 配置文件里新增分片规则 mod_rule,并指定规则适用字段为 customer_id
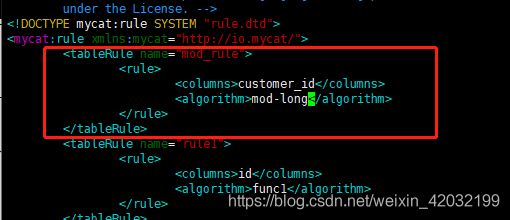
配置算法 mod-long 参数 count 为 2,两个节点

10.3 在数据节点 dn2 上建 orders 表
到13307数据库执行
CREATE TABLE orders(
id INT AUTO_INCREMENT,
order_type INT,
customer_id INT,
amount DECIMAL(10,2),
PRIMARY KEY(id)); 10.4重启 Mycat 测试
#在 mycat 插入数据,表字段不能省略,因为mycat要根据字段customer_id分片
INSERT INTO orders(id,order_type,customer_id,amount) VALUES (1,101,100,100100);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(2,101,100,100300);
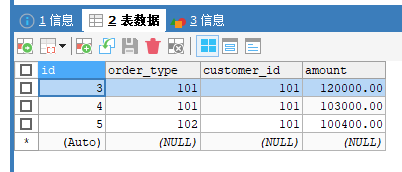
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(3,101,101,120000);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(4,101,101,103000);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(5,102,101,100400);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(6,102,100,100020);
13306
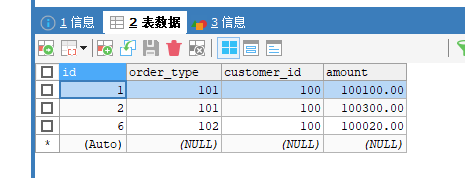
13307
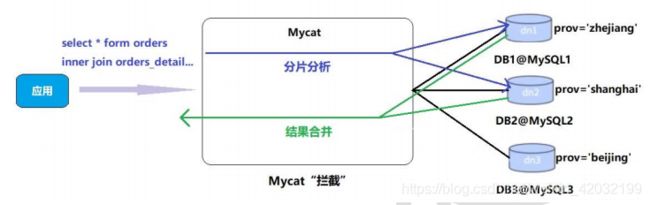
11.分表后的“join”查询解决
Mycat 目前版本支持跨分片的 join,主要实现的方式有四种:全局表,ER 分片,catletT(人工智能)和 ShareJoin,ShareJoin 在开发版中支持,前面三种方式 1.3.0.1 支持。
Orders 订单表已经进行分表操作了,和它关联的 orders_detail 订单详情表只存在13306机器,此时进行 join 查询会报错。因此要对 orders_detail 也要进行分片操作。Join 的原理如下图
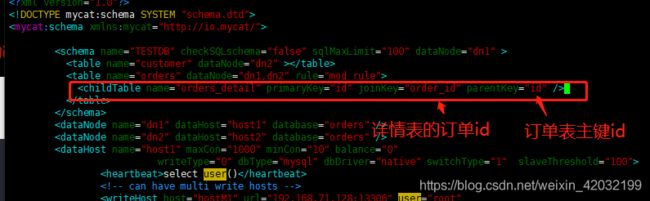
11.1 ER Join
MyCAT 借鉴了 NewSQL 领域的新秀 Foundation DB 的设计思路,Foundation DB 创新性的提出了 Table
Group 的概念,其将子表的存储位置依赖于主表,并且物理上紧邻存放,因此彻底解决了 JION 的效率和性能问
题,根据这一思路,提出了基于 E-R 关系的数据分片策略,子表的记录与所关联的父表记录存放在同一个数据分
片上。
修改 schema.xml 配置文件
在 dn2 创建 orders_detail 表
CREATE TABLE orders_detail(
id INT AUTO_INCREMENT,
detail VARCHAR(2000),
order_id INT,
PRIMARY KEY(id)
);重启 Mycat
访问 Mycat 向 orders_detail 表插入数据
INSERT INTO orders_detail(id,detail,order_id) values(1,'detail1',1);
INSERT INTO orders_detail(id,detail,order_id) VALUES(2,'detail1',2);
INSERT INTO orders_detail(id,detail,order_id) VALUES(3,'detail1',3);
INSERT INTO orders_detail(id,detail,order_id) VALUES(4,'detail1',4);
INSERT INTO orders_detail(id,detail,order_id) VALUES(5,'detail1',5);
INSERT INTO orders_detail(id,detail,order_id) VALUES(6,'detail1',6);在mycat、dn1、dn2中运行两个表join语句
Select o.*,od.detail from orders o inner join orders_detail od on o.id=od.order_id;
11.2 全局表
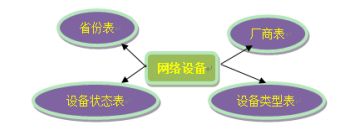
一个真实的业务系统中,往往存在大量的类似字典表的表格,它们与业务表之间可能有关系,这种关系,可
以理解为“标签”,而不应理解为通常的“主从关系”,这些表基本上很少变动,可以根据主键 ID 进行缓存,下
面这张图说明了一个典型的“标签关系”图:
在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间的关联,就成了比较
棘手的问题,考虑到字典表具有以下几个特性:
- 变动不频繁
- 数据量总体变化不大
- 数据规模不大,很少有超过数十万条记录。
鉴于此,MyCAT 定义了一种特殊的表,称之为“全局表”,全局表具有以下特性:
- 全局表的插入、更新操作会实时在所有节点上执行,保持各个分片的数据一致性
- 全局表的查询操作,只从一个节点获取
- 全局表可以跟任何一个表进行 JOIN 操作
将字典表或者符合字典表特性的一些表定义为全局表,则从另外一个方面,很好的解决了数据 JOIN 的难题。
通过全局表+基于 E-R 关系的分片策略,MyCAT 可以满足 80%以上的企业应用开发。
修改 schema.xml 配置文件

在 dn2 创建 dict_order_type 表
CREATE TABLE dict_order_type(
id INT AUTO_INCREMENT,
order_type VARCHAR(200),
PRIMARY KEY(id)
);重启 Mycat
访问 Mycat 向 dict_order_type 表插入数据
INSERT INTO dict_order_type(id,order_type) VALUES(101,'type1');
INSERT INTO dict_order_type(id,order_type) VALUES(102,'type2');
12.常用分片规则
12.1 取模
此规则为对分片字段求摸运算。也是水平分表最常用规则。前面的配置orders分表中采用了此规
则。
12.2 分片枚举
通过在配置文件中配置可能的枚举 id,自己配置分片,本规则适用于特定的场景,比如有些业务
需要按照省份或区县来做保存,而全国省份区县固定的,这类业务使用本条规则。
#(2)修改rule.xml配置文件
areacode
hash-int
partition-hash-int.txt
1
0
# columns:分片字段,algorithm:分片函数
# mapFile:标识配置文件名称,type:0为int型、非0为String【即areacode的类型】
#defaultNode:默认节点:小于 0 表示不设置默认节点,大于等于 0 表示设置默认节点,设置默认节点如果碰到不识别的枚举值,就让它路由到默认节点,如不设置不识别就报错
#(3)修改partition-hash-int.txt配置文件
110=0
120=1
#(4)重启 Mycat
#(5)访问Mycat创建表
#订单归属区域信息表
CREATE TABLE orders_ware_info
(
`id` INT AUTO_INCREMENT comment '编号',
`order_id` INT comment '订单编号',
`address` VARCHAR(200) comment '地址',
`areacode` VARCHAR(20) comment '区域编号',
PRIMARY KEY(id)
);
#(6)插入数据
INSERT INTO orders_ware_info(id, order_id,address,areacode) VALUES (1,1,'北京','110');
INSERT INTO orders_ware_info(id, order_id,address,areacode) VALUES (2,2,'天津','120');
#(7)查询Mycat、dn1、dn2可以看到数据分片效果
12.3 范围约定
此分片适用于,提前规划好分片字段某个范围属于哪个分片。
#(2)修改rule.xml配置文件
order_id
rang-long
autopartition-long.txt
0
#(3)修改autopartition-long.txt配置文件
#(4)重启 Mycat
#(5)访问Mycat创建表
# 支付信息表
CREATE TABLE payment_info
(
`id` INT AUTO_INCREMENT comment '编号',
`order_id` INT comment '订单编号',
`payment_status` INT comment '支付状态',
PRIMARY KEY(id)
);
#(6)插入数据
INSERT INTO payment_info (id,order_id,payment_status) VALUES (1,101,0);
INSERT INTO payment_info (id,order_id,payment_status) VALUES (2,102,1);
INSERT INTO payment_info (id,order_id ,payment_status) VALUES (3,103,0);
INSERT INTO payment_info (id,order_id,payment_status) VALUES (4,104,1);
#(7)查询Mycat、dn1、dn2可以看到数据分片效果
12.4 按日期(天)分片
此规则为按天分片。设定时间格式、范围
#(2)修改rule.xml配置文件
login_date
shardingByDate
yyyy-MM-dd
2019-01-01
2019-01-04
2
#(3)重启 Mycat
#(4)访问Mycat创建表
# 用户信息表
CREATE TABLE login_info
(
`id` INT AUTO_INCREMENT comment '编号',
`user_id` INT comment '用户编号',
`login_date` date comment '登录日期',
PRIMARY KEY(id)
);
#(5)插入数据
INSERT INTO login_info(id,user_id,login_date) VALUES (1,101,'2019-01-01');
INSERT INTO login_info(id,user_id,login_date) VALUES (2,102,'2019-01-02');
INSERT INTO login_info(id,user_id,login_date) VALUES (3,103,'2019-01-03');
INSERT INTO login_info(id,user_id,login_date) VALUES (4,104,'2019-01-04');
INSERT INTO login_info(id,user_id,login_date) VALUES (5,103,'2019-01-05');
INSERT INTO login_info(id,user_id,login_date) VALUES (6,104,'2019-01-06');
#(6)查询Mycat、dn1、dn2可以看到数据分片效果
13.全局序列
在实现分库分表的情况下,数据库自增主键已无法保证自增主键的全局唯一。为此,Mycat 提供
了全局 sequence,并且提供了包含本地配置和数据库配置等多种实现方式。目前在分布式中大多使用雪花算法。
13.1 本地文件
此方式 Mycat 将 sequence 配置到文件中,当使用到 sequence 中的配置后,Mycat 会更新
classpath 中的 sequence_conf.properties 文件中 sequence 当前的值。
① 优点:本地加载,读取速度较快
② 缺点:抗风险能力差,Mycat 所在主机宕机后,无法读取本地文件。
13.2 数据库方式
利用数据库一个表来进行计数累加。但是并不是每次生成序列都读写数据库,这样效率太低。
Mycat 会预加载一部分号段到 Mycat 的内存中,这样大部分读写序列都是在内存中完成的。
如果内存中的号段用完了 Mycat 会再向数据库要一次。
问:那如果 Mycat 崩溃了 ,那内存中的序列岂不是都没了?
是的。如果是这样,那么 Mycat 启动后会向数据库申请新的号段,原有号段会弃用。
也就是说如果 Mycat 重启,那么损失是当前的号段没用完的号码,但是不会因此出现主键重复
① 建库序列脚本
#在 dn1 上创建全局序列表
CREATE TABLE MYCAT_SEQUENCE (NAME VARCHAR(50) NOT NULL,current_value INT NOT
NULL,increment INT NOT NULL DEFAULT 100, PRIMARY KEY(NAME)) ENGINE=INNODB;
#创建全局序列所需函数
DELIMITER $$
CREATE FUNCTION mycat_seq_currval(seq_name VARCHAR(50)) RETURNS VARCHAR(64)
DETERMINISTIC
BEGIN
DECLARE retval VARCHAR(64);
SET retval="-999999999,null";
SELECT CONCAT(CAST(current_value AS CHAR),",",CAST(increment AS CHAR)) INTO retval FROM
MYCAT_SEQUENCE WHERE NAME = seq_name;
RETURN retval;
END $$
DELIMITER ;
DELIMITER $$
CREATE FUNCTION mycat_seq_setval(seq_name VARCHAR(50),VALUE INTEGER) RETURNS
VARCHAR(64)
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = VALUE
WHERE NAME = seq_name;
RETURN mycat_seq_currval(seq_name);
END $$
DELIMITER ;
DELIMITER $$
CREATE FUNCTION mycat_seq_nextval(seq_name VARCHAR(50)) RETURNS VARCHAR(64)
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = current_value + increment WHERE NAME = seq_name;
RETURN mycat_seq_currval(seq_name);
END $$
DELIMITER ;
#初始化序列表记录
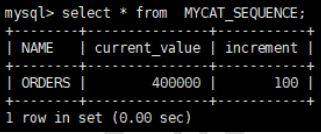
INSERT INTO MYCAT_SEQUENCE(NAME,current_value,increment) VALUES ('ORDERS', 400000,
100);
② 修改 Mycat 配置
#修改sequence_db_conf.properties
vim sequence_db_conf.properties
#意思是 ORDERS这个序列在dn1这个节点上,具体dn1节点是哪台机子,即如果实在dn2安装的,这里为dn2

#修改server.xml
vim server.xml
#全局序列类型:0-本地文件,1-数据库方式,2-时间戳方式。此处应该修改成1。

#重启Mycat
③ 验证全局序列
#登录 Mycat,插入数据
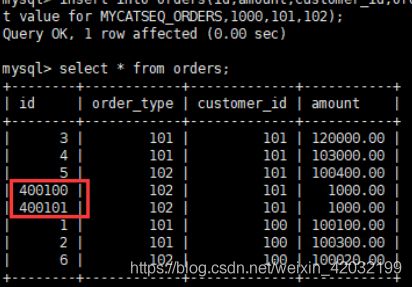
insert into orders(id,amount,customer_id,order_type) values(next value for
MYCATSEQ_ORDERS,1000,101,102);#查询数据
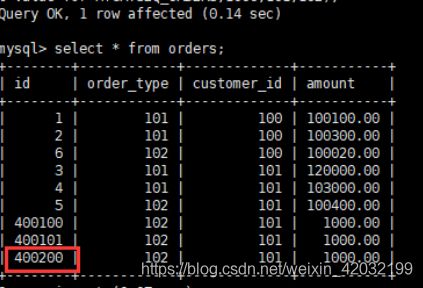
#重启Mycat后,再次插入数据,再查询
13.3 时间戳方式
全局序列ID= 64 位二进制 (42(毫秒)+5(机器 ID)+5(业务编码)+12(重复累加) 换算成十进制为 18 位数的
long 类型,每毫秒可以并发 12 位二进制的累加。
① 优点:配置简单
② 缺点:18 位 ID 过长
13.4 自主生成全局序列
可在 java 项目里自己生成全局序列,如下:
① 根据业务逻辑组合
② 可以利用 redis 的单线程原子性 incr 来生成序列
但,自主生成需要单独在工程中用 java 代码实现