Word2vec---经典的 Embedding 方法
文章目录
- 什么是 Word2vec?
- Word2vec 的样本是怎么生成的?
- Word2vec 模型的结构是什么样的?
- 怎样把词向量从 Word2vec 模型中提取出来?
- Word2vec 对 Embedding 技术的奠基性意义
- Item2Vec:Word2vec 方法的推广
- Word2vec代码实现
提到 Embedding,就一定要深入讲解一下 Word2vec。它不仅让词向量在自然语言处理领域再度流行,更关键的 是,自从 2013 年谷歌提出 Word2vec 以来,Embedding 技术从自然语言处理领域推广到广告、搜索、图像、推 荐等几乎所有深度学习的领域,成了深度学习知识框架中不可或缺的技术点。Word2vec 作为经典的 Embedding 方法,熟悉它对于我们理解之后所有的 Embedding 相关技术和概念都是至关重要的。下面,我就给你详细讲一讲 Word2vec 的原理。
什么是 Word2vec?
Word2vec 是“word to vector”的简称,顾名思义,它是一个生成对“词”的向量表达的模型。 想要训练 Word2vec 模型,我们需要准备由一组句子组成的语料库。假设其中一个长度为 T 的句子包含的词有 w1,w2……wt,并且我们假定每个词都跟其相邻词的关系最密切。
根据模型假设的不同,Word2vec 模型分为两种形式,CBOW 模型(图 3 左)和 Skip-gram 模型(图 3 右)。其 中,CBOW 模型假设句子中每个词的选取都由相邻的词决定,因此我们就看到 CBOW 模型的输入是 wt周边的词, 预测的输出是 wt。Skip-gram 模型则正好相反,它假设句子中的每个词都决定了相邻词的选取,所以你可以看到 Skip-gram 模型的输入是 wt,预测的输出是 wt周边的词。按照一般的经验,Skip-gram 模型的效果会更好一些, 所以我接下来也会以 Skip-gram 作为框架,来给你讲讲 Word2vec 的模型细节

Word2vec 的样本是怎么生成的?
我们先来看看训练 Word2vec 的样本是怎么生成的。 作为一个自然语言处理的模型,训练 Word2vec 的样本当然 来自于语料库,比如我们想训练一个电商网站中关键词的 Embedding 模型,那么电商网站中所有物品的描述文字 就是很好的语料库。
我们从语料库中抽取一个句子,选取一个长度为 2c+1(目标词前后各选 c 个词)的滑动窗口,将滑动窗口由左至 右滑动,每移动一次,窗口中的词组就形成了一个训练样本。根据 Skip-gram 模型的理念,中心词决定了它的相邻 词,我们就可以根据这个训练样本定义出 Word2vec 模型的输入和输出,输入是样本的中心词,输出是所有的相邻 词。
为了方便你理解,我再举一个例子。这里我们选取了“Embedding 技术对深度学习推荐系统的重要性”作为句子样 本。首先,我们对它进行分词、去除停用词的过程,生成词序列,再选取大小为 3 的滑动窗口从头到尾依次滑动生 成训练样本,然后我们把中心词当输入,边缘词做输出,就得到了训练 Word2vec 模型可用的训练样本。
Word2vec 模型的结构是什么样的?
有了训练样本之后,我们最关心的当然是 Word2vec 这个模型的结构是什么样的。我相信,通过第 3 节课的学习, 你已经掌握了神经网络的基础知识,那再理解 Word2vec 的结构就容易多了,它的结构本质上就是一个三层的神经 网络(如图 5)。
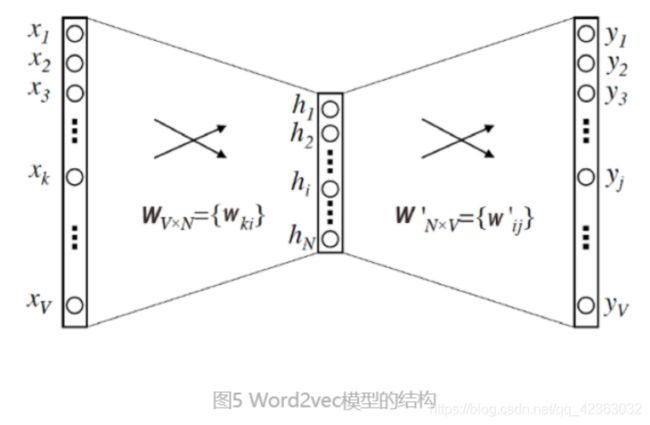
它的输入层和输出层的维度都是 V,这个 V 其实就是语料库词典的大小。假设语料库一共使用了 10000 个词,那 么 V 就等于 10000。根据图 4 生成的训练样本,这里的输入向量自然就是由输入词转换而来的 One-hot 编码向 量,输出向量则是由多个输出词转换而来的 Multi-hot 编码向量,显然,基于 Skip-gram 框架的 Word2vec 模型解 决的是一个多分类问题。
隐层的维度是 N,N 的选择就需要一定的调参能力了,我们需要对模型的效果和模型的复杂度进行权衡,来决定最 后 N 的取值,并且最终每个词的 Embedding 向量维度也由 N 来决定。
最后是激活函数的问题,这里我们需要注意的是,隐层神经元是没有激活函数的,或者说采用了输入即输出的恒等 函数作为激活函数,而输出层神经元采用了 softmax 作为激活函数。
你可能会问为什么要这样设置 Word2vec 的神经网络,以及我们为什么要这样选择激活函数呢?因为这个神经网络 其实是为了表达从输入向量到输出向量的这样的一个条件概率关系,我们看下面的式子:

这个由输入词 WI 预测输出词 WO 的条件概率,其实就是 Word2vec 神经网络要表达的东西。我们通过极大似然的 方法去最大化这个条件概率,就能够让相似的词的内积距离更接近,这就是我们希望 Word2vec 神经网络学到的。
当然,如果你对数学和机器学习的底层理论没那么感兴趣的话,也不用太深入了解这个公式的由来,因为现在大多 数深度学习平台都把它们封装好了,你不需要去实现损失函数、梯度下降的细节,你只要大概清楚他们的概念就可 以了
如果你是一个理论派,其实 Word2vec 还有很多值得挖掘的东西,比如,为了节约训练时间,Word2vec 经常会采 用负采样(Negative Sampling)或者分层 softmax(Hierarchical Softmax)的训练方法。
怎样把词向量从 Word2vec 模型中提取出来?
在训练完 Word2vec 的神经网络之后,可能你还会有疑问,我们不是想得到每个词对应的 Embedding 向量嘛,这 个 Embedding 在哪呢?其实,它就藏在输入层到隐层的权重矩阵 WVxN 中。我想看了下面的图你一下就明白了。
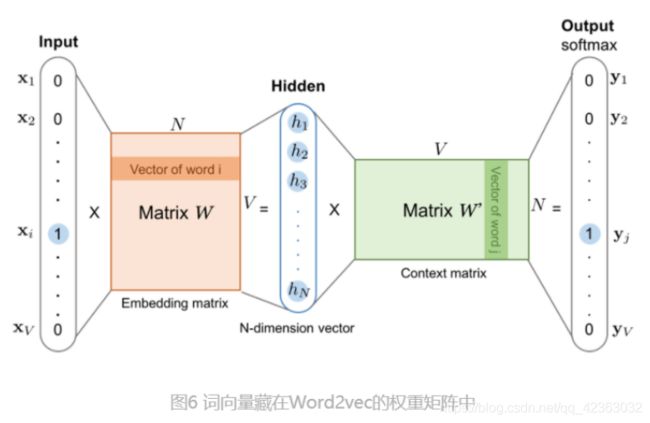
你可以看到,输入向量矩阵 WVxN 的每一个行向量对应的就是我们要找的“词向量”。比如我们要找词典里第 i 个词 对应的 Embedding,因为输入向量是采用 One-hot 编码的,所以输入向量的第 i 维就应该是 1,那么输入向量矩 阵 WVxN 中第 i 行的行向量自然就是该词的 Embedding
细心的你可能也发现了,输出向量矩阵 W′ 也遵循这个道理,确实是这样的,但一般来说,我们还是习惯于使用输 入向量矩阵作为词向量矩阵。
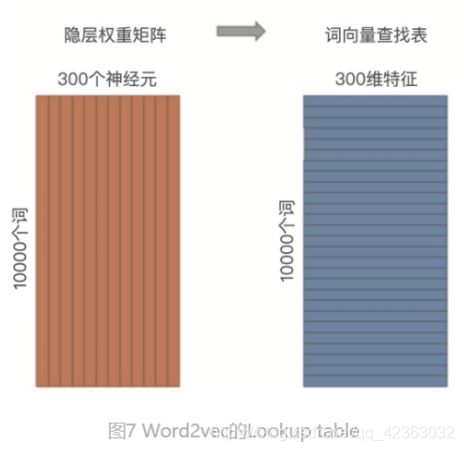
在实际的使用过程中,我们往往会把输入向量矩阵转换成词向量查找表(Lookup table,如图 7 所示)。例如,输 入向量是 10000 个词组成的 One-hot 向量,隐层维度是 300 维,那么输入层到隐层的权重矩阵为 10000x300 维。在转换为词向量 Lookup table 后,每行的权重即成了对应词的 Embedding 向量。如果我们把这个查找表存 储到线上的数据库中,就可以轻松地在推荐物品的过程中使用 Embedding 去计算相似性等重要的特征了。
Word2vec 对 Embedding 技术的奠基性意义
Word2vec 是由谷歌于 2013 年正式提出的,其实它并不完全是原创性的,学术界对词向量的研究可以追溯到 2003 年,甚至更早的时期。但正是谷歌对 Word2vec 的成功应用,让词向量的技术得以在业界迅速推广,进而使 Embedding 这一研究话题成为热点。毫不夸张地说,Word2vec 对深度学习时代 Embedding 方向的研究具有奠基 性的意义。
从另一个角度来看,Word2vec 的研究中提出的模型结构、目标函数、负采样方法、负采样中的目标函数在后续的 研究中被重复使用并被屡次优化。掌握 Word2vec 中的每一个细节成了研究 Embedding 的基础。从这个意义上 讲,熟练掌握本节课的内容是非常重要的。
Item2Vec:Word2vec 方法的推广
在 Word2vec 诞生之后,Embedding 的思想迅速从自然语言处理领域扩散到几乎所有机器学习领域,推荐系统也 不例外。既然 Word2vec 可以对词“序列”中的词进行 Embedding,那么对于用户购买“序列”中的一个商品,用户观 看“序列”中的一个电影,也应该存在相应的 Embedding 方法。

于是,微软于 2015 年提出了 Item2Vec 方法,它是对 Word2vec 方法的推广,使 Embedding 方法适用于几乎所 有的序列数据。Item2Vec 模型的技术细节几乎和 Word2vec 完全一致,只要能够用序列数据的形式把我们要表达 的对象表示出来,再把序列数据“喂”给 Word2vec 模型,我们就能够得到任意物品的 Embedding 了。
Item2vec 的提出对于推荐系统来说当然是至关重要的,因为它使得“万物皆 Embedding”成为了可能。对于推荐系 统来说,Item2vec 可以利用物品的 Embedding 直接求得它们的相似性,或者作为重要的特征输入推荐模型进行 训练,这些都有助于提升推荐系统的效果
Embedding 就是用一个数值向 量“表示”一个对象的方法。通过 Embedding,我们又引出了 Word2vec,Word2vec 是生成对“词”的向量表达的模 型。其中,Word2vec 的训练样本是通过滑动窗口一一截取词组生成的。在训练完成后,模型输入向量矩阵的行向 量,就是我们要提取的词向量。最后,我们还学习了 Item2vec,它是 Word2vec 在任意序列数据上的推广

Word2vec代码实现
import itertools
import joblib
import numpy as np
from word2vec.utils import distance, unitvec
class WordVectors(object):
def __init__(self, vocab, vectors, clusters=None):
"""
Initialize a WordVectors class based on vocabulary and vectors
This initializer precomputes the vectors of the vectors
Parameters
----------
vocab : np.array
1d array with the vocabulary
vectors : np.array
2d array with the vectors calculated by word2vec
clusters : word2vec.WordClusters (optional)
1d array with the clusters calculated by word2vec
"""
self.vocab = vocab
self.vectors = vectors
self.clusters = clusters
# Used to make indexing faster
self.vocab_hash = {
}
for i, word in enumerate(vocab):
self.vocab_hash[word] = i
def ix(self, word):
"""
Returns the index on `self.vocab` and `self.vectors` for `word`
"""
return self.vocab_hash[word]
def word(self, ix):
"""Returns the word that corresponds to the index.
Parameters
-------
ix : int
The index of the word
Returns
-------
str
The word that corresponds to the index
"""
return self.vocab[ix]
def __getitem__(self, word):
return self.get_vector(word)
def __contains__(self, word):
return word in self.vocab_hash
def get_vector(self, word):
"""
Returns the vector for a `word` in the vocabulary
"""
return self.vectors[self.ix(word)]
def distance(self, *args, **kwargs):
"""
Compute the distance distance between two vectors or more (all combinations) of words
Parameters
----------
words : one or more words
n : int (default 10)
number of neighbors to return
metric : string (default "cosine")
What metric to use
"""
metric = kwargs.get("metric", "cosine") # Default is cosine
combinations = list(itertools.combinations(args, r=2))
ret = []
for word1, word2 in combinations:
dist = distance(self[word1], self[word2], metric=metric)
ret.append((word1, word2, dist))
return ret
def closest(self, vector, n=10, metric="cosine"):
"""Returns the closest n words to a vector
Parameters
-------
vector : numpy.array
n : int (default 10)
Returns
-------
Tuple of 2 numpy.array:
1. position in self.vocab
2. cosine similarity
"""
distances = distance(self.vectors, vector, metric=metric)
best = np.argsort(distances)[::-1][1 : n + 1]
best_metrics = distances[best]
return best, best_metrics
def similar(self, word, n=10, metric="cosine"):
"""
Return similar words based on a metric
Parameters
----------
word : string
n : int (default 10)
Returns
-------
Tuple of 2 numpy.array:
1. position in self.vocab
2. cosine similarity
"""
return self.closest(self[word], n=n, metric=metric)
def analogy(self, pos, neg, n=10, metric="cosine"):
"""
Analogy similarity.
Parameters
----------
pos : list
neg : list
Returns
-------
Tuple of 2 numpy.array:
1. position in self.vocab
2. cosine similarity
Example
-------
`king - man + woman = queen` will be: `pos=['king', 'woman'], neg=['man']`
"""
exclude = pos + neg
pos = [(word, 1.0) for word in pos]
neg = [(word, -1.0) for word in neg]
mean = []
for word, direction in pos + neg:
mean.append(direction * self[word])
mean = np.array(mean).mean(axis=0)
metrics = distance(self.vectors, mean, metric=metric)
best = metrics.argsort()[::-1][: n + len(exclude)]
exclude_idx = [
np.where(best == self.ix(word)) for word in exclude if self.ix(word) in best
]
new_best = np.delete(best, exclude_idx)
best_metrics = metrics[new_best]
return new_best[:n], best_metrics[:n]
def generate_response(self, indexes, metrics, clusters=True):
"""
Generates a pure python (no numpy) response based on numpy arrays
returned by `self.cosine` and `self.analogy`
"""
if self.clusters and clusters:
return np.rec.fromarrays(
(self.vocab[indexes], metrics, self.clusters.clusters[indexes]),
names=("word", "metric", "cluster"),
)
else:
return np.rec.fromarrays(
(self.vocab[indexes], metrics), names=("word", "metric")
)
def to_mmap(self, fname):
joblib.dump(self, fname)
@classmethod
def from_binary(
cls,
fname,
vocab_unicode_size=78,
desired_vocab=None,
encoding="utf-8",
new_lines=True,
):
"""
Create a WordVectors class based on a word2vec binary file
Parameters
----------
fname : path to file
vocabUnicodeSize: the maximum string length (78, by default)
desired_vocab: if set any words that don't fall into this vocab will be droped
Returns
-------
WordVectors instance
"""
with open(fname, "rb") as fin:
# The first line has the vocab_size and the vector_size as text
header = fin.readline()
vocab_size, vector_size = list(map(int, header.split()))
vocab = np.empty(vocab_size, dtype=" % vocab_unicode_size)
vectors = np.empty((vocab_size, vector_size), dtype=np.float)
binary_len = np.dtype(np.float32).itemsize * vector_size
for i in range(vocab_size):
# read word
word = b""
while True:
ch = fin.read(1)
if ch == b" ":
break
word += ch
include = desired_vocab is None or word in desired_vocab
if include:
vocab[i] = word.decode(encoding)
# read vector
vector = np.fromstring(fin.read(binary_len), dtype=np.float32)
if include:
vectors[i] = unitvec(vector)
if new_lines:
fin.read(1) # newline char
if desired_vocab is not None:
vectors = vectors[vocab != "", :]
vocab = vocab[vocab != ""]
return cls(vocab=vocab, vectors=vectors)
@classmethod
def from_text(
cls, fname, vocabUnicodeSize=78, desired_vocab=None, encoding="utf-8"
):
"""
Create a WordVectors class based on a word2vec text file
Parameters
----------
fname : path to file
vocabUnicodeSize: the maximum string length (78, by default)
desired_vocab: if set, this will ignore any word and vector that
doesn't fall inside desired_vocab.
Returns
-------
WordVectors instance
"""
with open(fname, "rb") as fin:
header = fin.readline()
vocab_size, vector_size = list(map(int, header.split()))
vocab = np.empty(vocab_size, dtype=" % vocabUnicodeSize)
vectors = np.empty((vocab_size, vector_size), dtype=np.float)
for i, line in enumerate(fin):
line = line.decode(encoding).rstrip()
parts = line.split(" ")
word = parts[0]
include = desired_vocab is None or word in desired_vocab
if include:
vector = np.array(parts[1:], dtype=np.float)
vocab[i] = word
vectors[i] = unitvec(vector)
if desired_vocab is not None:
vectors = vectors[vocab != "", :]
vocab = vocab[vocab != ""]
return cls(vocab=vocab, vectors=vectors)
@classmethod
def from_mmap(cls, fname):
"""
Create a WordVectors class from a memory map
Parameters
----------
fname : path to file
Returns
-------
WordVectors instance
"""
memmaped = joblib.load(fname, mmap_mode="r+")
return cls(vocab=memmaped.vocab, vectors=memmaped.vectors)