python爬虫实例100例-Python爬虫 实例
基本GET请求1. 最基本的GET请求可以直接用get方法
response = requests.get("http://www.baidu.com/")
2. 添加 headers 和 查询参数
如果想添加 headers,可以传入headers参数来增加请求头中的headers信息。如果要将参数放在url中传递,可以利用 params 参数。
kw = {'wd':'长城'}
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# params 接收一个字典或者字符串的查询参数,字典类型自动转换为url编码,不需要urlencode()
response = requests.get("http://www.baidu.com/s?", params = kw, headers = headers)
# 查看响应内容,response.text 返回的是Unicode格式的数据
print response.text
2. 传入data数据
对于 POST 请求来说,我们一般需要为它增加一些参数。那么最基本的传参方法可以利用 data 这个参数。
formdata = {
"type":"AUTO",
"i":"i love python",
"doctype":"json",
"xmlVersion":"1.8",
"keyfrom":"fanyi.web",
"ue":"UTF-8",
"action":"FY_BY_ENTER",
"typoResult":"true"
}
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null"
headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"}
response = requests.post(url, data = formdata, headers = headers)
print response.text
# 如果是json文件可以直接显示
print response.json()
Cookies
response=requests.get('http://www.baidu.com/')
# 7. 返回CookieJar对象:
cookiejar=response.cookies
print(cookiejar)
# 8. 将CookieJar转为字典:
cookiedict=requests.utils.dict_from_cookiejar(cookiejar)
print(cookiedict)

Sission
在 requests 里,session对象是一个非常常用的对象,这个对象代表一次用户会话:从客户端浏览器连接服务器开始,到客户端浏览器与服务器断开。
会话能让我们在跨请求时候保持某些参数,比如在同一个 Session 实例发出的所有请求之间保持 cookie 。
# 1. 创建session对象,可以保存Cookie值
ssion = requests.session()
# 2. 处理 headers
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"}
# 3. 需要登录的用户名和密码
data = {"email":"12922215**", "password":"huang***521"}
# 4. 发送附带用户名和密码的请求,并获取登录后的Cookie值,保存在ssion里
ssion.post("http://www.renren.com/PLogin.do", data = data)
# 5. ssion包含用户登录后的Cookie值,可以直接访问那些登录后才可以访问的页面
response = ssion.get("http://www.renren.com/410043129/profile")
# 6. 打印响应内容
soup=BeautifulSoup(response.text,'html.parser')
#print(soup)
for ss in soup.find_all('span',class_='stage-name'):
print(ss.text)

获取所有课程信息
先访问所有课程页面,把html代码拿到,实际上就是拿到一个很长的文本,文本内容就是网页的html代码
分析html代码,找到我们需要获取信息的html特征
解析html代码,根据html特征,从里面抠出来课程的名称
打印出所有课程的名称
from selenium import webdriver
import requests
from bs4 import BeautifulSoup
'''首先要安装requests库'''
url='http://www.itest.info/courses'
#获取被抓取页面的HTML代码,并使用html.parser来实例化BeautiSoup,属于固定套路
soup=BeautifulSoup(requests.get(url).text,'html.parser')
#遍历页面上所有的h4
for course in soup.find_all('h4'):
print(course.text)
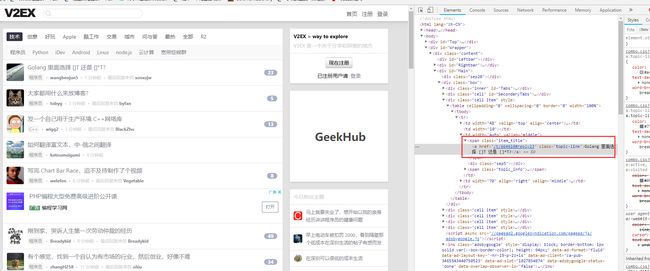
我们要找到的是所有class=item_hot_topic_title的span下面的a元素
from selenium import webdriver
import requests
from bs4 import BeautifulSoup
'''首先要安装requests库'''
url='https://www.v2ex.com/'
#获取被抓取页面的HTML代码,并使用html.parser来实例化BeautiSoup,属于固定套路
soup=BeautifulSoup(requests.get(url).text,'html.parser')
for span in soup.find_all('span',class_='item_hot_topic_title'):
print(span.find('a').text,span.find('a')['href'])
相关知识点
soup.find('span', class_='item_hot_topic_title') 这个是只能找到第一个span标签 样式为 class='item_hot_topic_title',就算后面还有匹配的也不去获取
span.find_all('span', class_='item_hot_topic_title') 这个就能找到页面上所有span标签 样式为 class='item_hot_topic_title'