一、前言
当业务系统发生安全事件时,我们除了需要对客户的主机进行排查找出入侵来源、还原入侵事故过程,还需要对网络流量持续性地跟踪监测。
虽然市面上那么多的安全监控分析设备、软件,产生了大量的安全日志。可还是要将尝试攻击、已经攻击成功的情况判断出来有针对性地进行排查、防御。
针对常见的攻击事件,结合监测工作中分析流量的方法,总结了几个网络流量分析排查思路。
本文将顺序从工作场景中遇到的协议分析,内网中毒主机定位思路与pcap解析提取问题逐步介绍现场工作的思路。
二、协议分析基础
(一)攻击成功-钓鱼邮件
正常邮件传输协议的流程是用户发送邮件产生、邮件服务器正常通信产生。
SMTP协议作为邮件传输协议,需要关注的安全问题:
1、邮箱账户受到黑客控制向外发送钓鱼邮件。关注重点
对SMTP协议进行分析,查看账户频繁登录群发类的内容是否为正常业务内容。如果出现业务内容外的广告邮件、钓鱼邮件等类型邮件则说明邮箱账户已经受到控制。
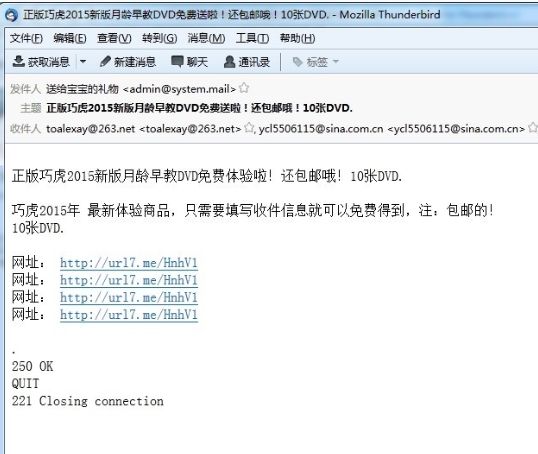
图1
(二)攻击成功-服务器受控
中了木马后门的傀儡主机会通过HTTP协议或其它协议去连接攻击者远控服务器。攻击者的远控服务器发现傀儡主机在线,就可以随时控制。
需要关注的安全问题:
1、单一主机有时间规律地向外发送大量的HTTP协议请求关注重点
对服务器资产表的IP搜索,wireshark搜索服务器IP语法:
# 搜索HTTP
ip.src eq 服务器资产IP and http
ip.src == 服务器资产IP and http
# 过滤DNS
ip.src == 服务器资产IP and dns
图2
(三)暴力破解
重要管理系统的登录权限受到爆破攻击行为较多,即用暴力穷举的方式大量尝试性地猜破密码。
需要关注的安全问题:
暴力破解涉及到WEB、邮件、FTP服务、数据库服务、远程服务等。
关注重点
即使产生了暴破数据,是否足以判断攻击成功还需要进一步排查。关注同一个账户是否密码输入错误多次,且错误密码符合字典破解规律。如123@qwe、123456、12345678等。
POP3/SMTP/IMAP/HTTP/HTTPS/RDP协议认证过程的常见数据格式如下:
1)POP3协议
CAPA //用于取得此服务器的功能选项清单
+OK Capability list follows
TOP
USER
PIPELINING
EXPIRE NEVER
UIDL
+OK Mail Server POP3 ready
user [email protected] ---------------------输入用户名, username 为具体的用户名
+OK -------------------------------执行命令成功
pass q1q1q1q1 ---------------------输入用户密码,password 为具体的密码,这里要注意,当密码输入错误后要重新user username后再运行此命令,否则提示命令无效
+OK 2 messages ---------------------密码认证通过
(-ERR authorization failed ---------密码认证失败)
(+OK User successfully logged on. --认证成功)
stat -------------------------------邮箱状态
+OK 2 6415 -------------------------2 为该信箱总邮件数,6415 为总字节数
list -------------------------------列出每封邮件的字节数
+OK --------------------------------执行命令成功,开始显示,左边为邮件的序号,右边为该邮件的大小
1 537 ------------------------------第 1 封邮件,大小为 537 字节
2 5878 -----------------------------第 2 封邮件,大小为 5878 字节
+OK Microsoft Exchange Server 2003 POP3 .......... 6.5.6944.0 ..........暴力破解特征:
攻击者不断输入用户名jufeng001,不同的密码进行尝试,服务器也大量报错:-ERR Logon failure: unknown user name or bad password。
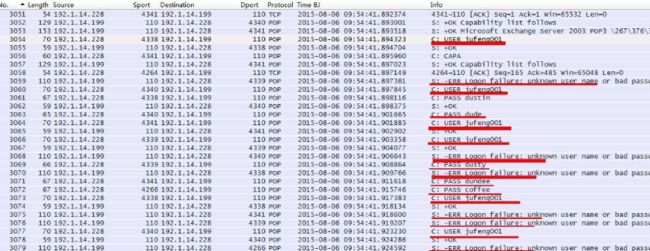
图3
2)SMTP协议
220 a-ba21a05129e24.test.org Microsoft ESMTP MAIL Service, Version: 6.0.3790.3959 ready at Thu, 6 Aug 2015 11:10:17 +0800 //服务就绪
EHLO Mr.RightPC //主机名
250-a-ba21a05129e24.test.org Hello [192.1.14.228]
……
250 OK
AUTH LOGIN // 认证开始
334 VXNlcm5hbWU6 // Username:
cGFzc0AxMjM= // 输入用户名的base64编码
334 UGFzc3dvcmQ6 // Password:
MXFhekBXU1g= // 输入密码的base64编码
235 2.7.0 Authentication successful. //认证成功暴力破解特征:
攻击者不断输入用户名jufeng001,不同的密码进行尝试,服务器也大量报错:535 5.7.3 Authentication unsuccessful。
图4
3)IMAP协议
bf8p CAPABILITY
* CAPABILITY IMAP4 IMAP4rev1 IDLE LOGIN-REFERRALS MAILBOX-REFERRALS NAMESPACE LITERAL+ UIDPLUS CHILDREN
bf8p OK CAPABILITY completed.
s3yg LOGIN "administrator" "1qaz@WSX" //输入用户名:administrator,密码:1qaz@WSX
s3yg OK LOGIN completed. //认证成功暴力破解特征:
IMAP爆破会不断重复LOGIN "用户名" "密码",以及登录失败的报错:NO Logon failure: unknown user name or bad password。
图5
4)HTTP协议
HTTP登录页面看是否存在302页面跳转判断为登录成功。
Referer: http://192.1.14.199:8080/login.html //登录地址
uname=admin&upass=1qaz%40WSXHTTP/1.1 200 OK
…
//输入用户名admin,密码1qaz%40WSX,Web服务器返回HTTP/1.1 200和弹出对话框“OK”表示认证成功。暴力破解特征:
短时间内出现大量登录页面的请求包。
图6
5)HTTPS协议
HTTPS协议为加密协议,从数据很难判断认证是否成功,只能根据数据头部结合社会工程学才能判断。如认证后有无查看网页、邮件的步骤,如有,就会产生加密数据。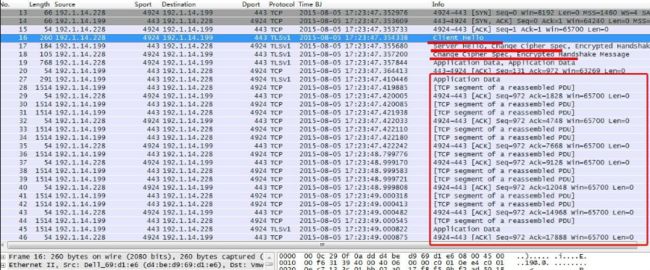
图7
暴力破解特征:
爆破过程中,不断出现认证过程:“Client Hello”、“Server Hello”等,并未出现登录成功后操作的大量加密数据。在不到2秒的时间就出现16次认证,基本可以判断为暴力破解。
图8
6)RDP协议
RDP为Windows远程控制协议,采用TCP3389端口。本版本采用的加密算法为:128-bit RC4;红线内为登陆认证过程,后为登陆成功的操作数据。
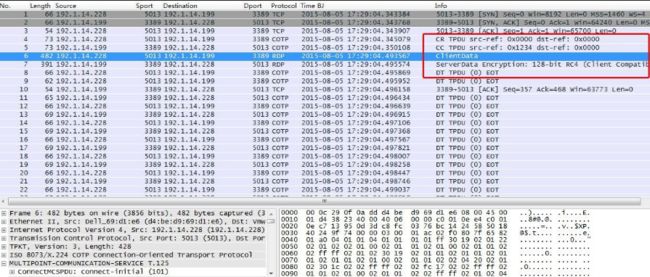
图9
暴力破解特征:
统计一下正常登录RDP协议的TCP端口等信息,可以看出正常登录的话,在一定时间内是一组“源端口和目的端口”。
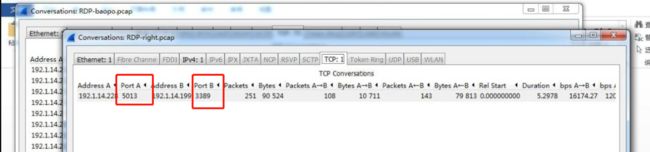
图10
爆破RDP协议的TCP端口等信息,可以看出短时间内出现大量不同的“源端口和目的端口”,且包数和字节长度基本相同。这就表明出现大量动作基本相同的“短通信”,再结合数据格式就可以确定为暴力破解行为。
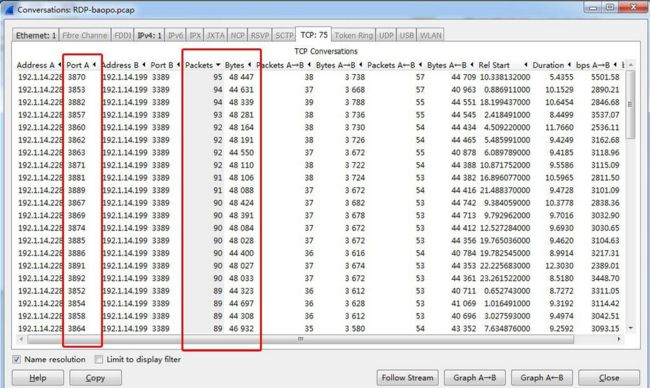
图11
7)多用户暴力破解判断
同一个攻击IP同时登录大量不同的用户名、尝试不同的口令、大量的登录失败的报错。
(四)扫描探测
1.地址扫描探测
192.1.14.235向指定网段发起ARP请求,如果IP不存在,则无回应。
图12
如果IP存在,该IP会通过ARP回应攻击IP,发送自己的MAC地址与对应的IP。
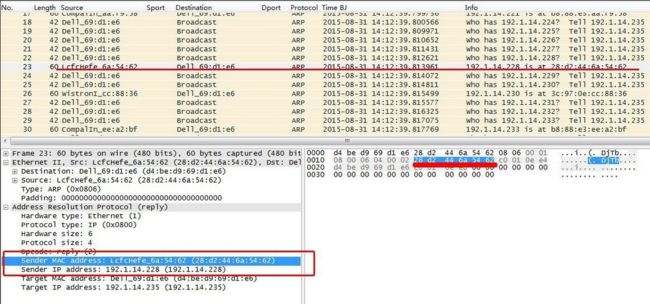
图13ARP欺骗适用范围多限于内网,通过互联网进行地址扫描一般基于Ping请求。
如:192.1.14.235向指定网段发起Ping请求,如果IP存在,则返回Ping reply。
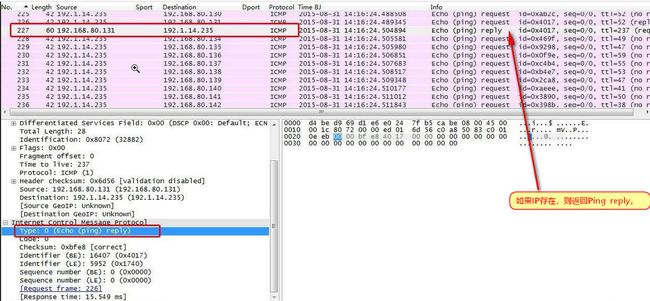
图14
2.端口扫描探测
(1)全连接扫描
全连接扫描调用操作系统提供的connect()函数,通过完整的三次TCP连接来尝试目标端口是否开启。全连接扫描是一次完整的TCP连接。
1)如果目标端口开启
攻击方:首先发起SYN包;
目标:返回SYN ACK;
攻击方:发起ACK;
攻击方:发起RST ACK结束会话。
如:192.1.14.235对172.16.33.162进行全连接端口扫描,首先发起Ping消息确认主机是否存在,然后对端口进行扫描。
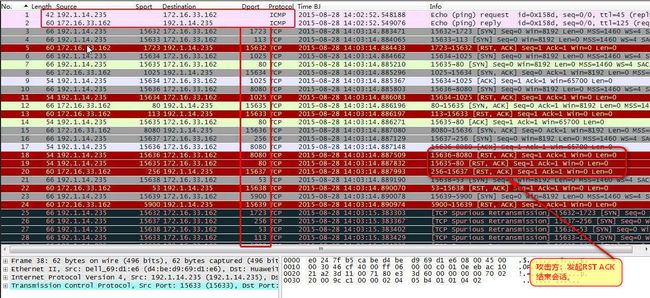
图15
2)如果端口未开启
攻击方:发起SYN包;
目标:返回RST ACK结束会话。
下图为扫描到TCP1723端口未开启的情况。
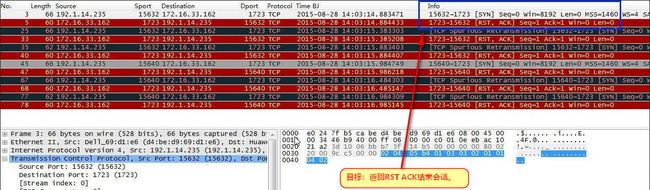
图16
(2)半连接扫描
半连接扫描不使用完整的TCP连接。攻击方发起SYN请求包;如果端口开启,目标主机回应SYN ACK包,攻击方再发送RST包。如果端口未开启,目标主机直接返回RST包结束会话。
扫描到TCP80端口开启。

图17
TCP23端口未开启。

图18
(3)秘密扫描TCPFIN
TCP FIN扫描是指攻击者发送虚假信息,目标主机没有任何响应时认为端口是开放的,返回数据包认为是关闭的。
如下图,扫描方发送FIN包,如果端口关闭则返回RST ACK包。

图19
(4)秘密扫描TCPACK
TCP ACK扫描是利用标志位ACK,而ACK标志在TCP协议中表示确认序号有效,它表示确认一个正常的TCP连接。但是在TCP ACK扫描中没有进行正常的TCP连接过程,实际上是没有真正的TCP连接。所以使用TCP ACK扫描不能够确定端口的关闭或者开启,因为当发送给对方一个含有ACK表示的TCP报文的时候,都返回含有RST标志的报文,无论端口是开启或者关闭。但是可以利用它来扫描防火墙的配置和规则等。
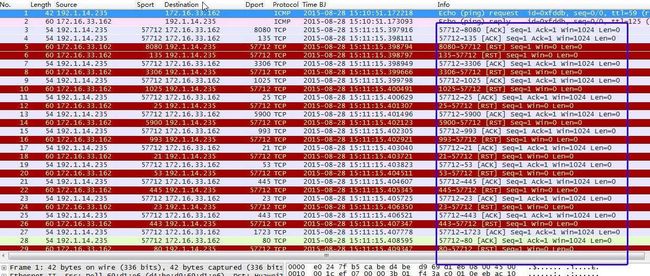
图20
(5)UDP端口扫描
针对UDP端口一般采用UDP ICMP端口不可达扫描。
如:192.1.14.235对172.16.2.4发送大量UDP端口请求,扫描其开启UDP端口的情况。
如果对应的UDP端口开启,则会返回UDP数据包。

图21
如果端口未开启,则返回“ICMP端口不可达”消息。
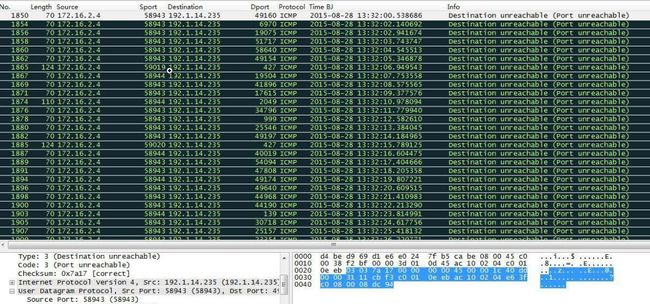
图22
(6)漏洞扫描
针对“smb-check-vulns”参数就MS08-067、CVE2009-3103、MS06-025、MS07-029四个漏洞扫描行为进行分析。
攻击主机:192.168.1.200(Win7),目标主机:192.168.1.40(WinServer 03);
Nmap扫描命令:nmap --script=smb-check-vulns.nse --script-args=unsafe=1 192.168.1.40。
NAMP扫描行为中的SMB命令。
SMB Command:Negotiate Protocol(0x72):SMB协议磋商
SMB Command: Session Setup AndX(0x73):建立会话,用户登录
SMB Command: Tree Connect AndX (0x75):遍历共享文件夹的目录及文件
SMB Command: NT Create AndX (0xa2):打开文件,获取文件名,获得读取文件的总长度
SMB Command: Write AndX (0x2f):写入文件,获得写入的文件内容
SMB Command:Read AndX(0x2e):读取文件,获得读取文件内容
SMB Command: Tree Disconnect(0x71):客户端断开
SMB Command: Logoff AndX(0x74):退出登录1)MS08-067漏洞
nmap ms08067扫描部分源码
function check_ms08_067(host)
if(nmap.registry.args.safe ~= nil) then
return true, NOTRUN
end
if(nmap.registry.args.unsafe == nil) then
return true, NOTRUN
end
local status, smbstate
local bind_result, netpathcompare_result
-- Create the SMB session \\创建SMB会话
status, smbstate = msrpc.start_smb(host, "\\\\BROWSER")
if(status == false) then
return false, smbstate
end
-- Bind to SRVSVC service
status, bind_result = msrpc.bind(smbstate, msrpc.SRVSVC_UUID, msrpc.SRVSVC_VERSION, nil)
if(status == false) then
msrpc.stop_smb(smbstate)
return false, bind_result
end
-- Call netpathcanonicalize
-- status, netpathcanonicalize_result = msrpc.srvsvc_netpathcanonicalize(smbstate, host.ip, "\\a", "\\test\\")
local path1 = "\\AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA\\..\\n"
local path2 = "\\n"
status, netpathcompare_result = msrpc.srvsvc_netpathcompare(smbstate, host.ip, path1, path2, 1, 0)
-- Stop the SMB session
msrpc.stop_smb(smbstate)尝试打开“\\BROWSER”目录,下一包返回成功。
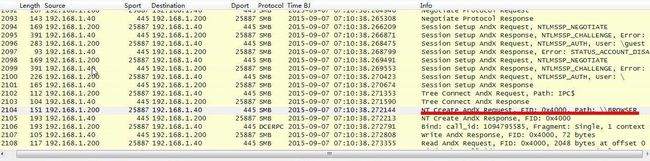
图23
2)CVE-2009-3103漏洞
# CVE-2009-3103漏洞扫描部分源码
host = "IP_ADDR", 445
buff = (
"\x00\x00\x00\x90" # Begin SMB header: Session message
"\xff\x53\x4d\x42" # Server Component: SMB
"\x72\x00\x00\x00" # Negociate Protocol
"\x00\x18\x53\xc8" # Operation 0x18 & sub 0xc853
"\x00\x26"# Process ID High: --> :) normal value should be "\x00\x00"
"\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xff\xff\xff\xfe"
"\x00\x00\x00\x00\x00\x6d\x00\x02\x50\x43\x20\x4e\x45\x54"
"\x57\x4f\x52\x4b\x20\x50\x52\x4f\x47\x52\x41\x4d\x20\x31"
"\x2e\x30\x00\x02\x4c\x41\x4e\x4d\x41\x4e\x31\x2e\x30\x00"
"\x02\x57\x69\x6e\x64\x6f\x77\x73\x20\x66\x6f\x72\x20\x57"
"\x6f\x72\x6b\x67\x72\x6f\x75\x70\x73\x20\x33\x2e\x31\x61"
"\x00\x02\x4c\x4d\x31\x2e\x32\x58\x30\x30\x32\x00\x02\x4c"
"\x41\x4e\x4d\x41\x4e\x32\x2e\x31\x00\x02\x4e\x54\x20\x4c"
"\x4d\x20\x30\x2e\x31\x32\x00\x02\x53\x4d\x42\x20\x32\x2e"
"\x30\x30\x32\x00"
)十六进制字符串“0x00000000到202e30303200”请求,通过ASCII编码可以看出是在探测NTLM和SMB协议的版本。无响应,无此漏洞。
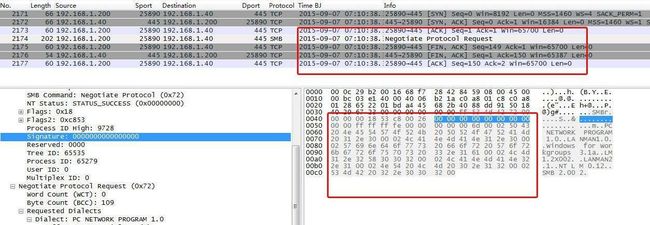
图24
3)MS06-025漏洞
# MS06-025漏洞扫描部分源码
--create the SMB session
--first we try with the "\router" pipe, then the "\srvsvc" pipe.
local status, smb_result, smbstate, err_msg
status, smb_result = msrpc.start_smb(host, msrpc.ROUTER_PATH)
if(status == false) then
err_msg = smb_result
status, smb_result = msrpc.start_smb(host, msrpc.SRVSVC_PATH) --rras is also accessible across SRVSVC pipe
if(status == false) then
return false, NOTUP --if not accessible across both pipes then service is inactive
end
end
smbstate = smb_result
--bind to RRAS service
local bind_result
status, bind_result = msrpc.bind(smbstate, msrpc.RASRPC_UUID, msrpc.RASRPC_VERSION, nil)
if(status == false) then
msrpc.stop_smb(smbstate)
return false, UNKNOWN --if bind operation results with a false status we can't conclude anything.
End先后尝试去连接“\router”、“ \srvsvc”路径,均报错,无RAS RPC服务。
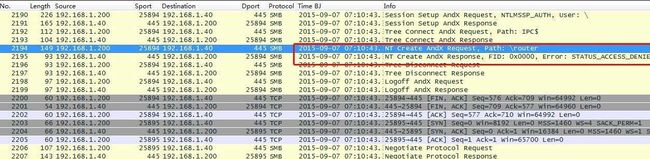
图25
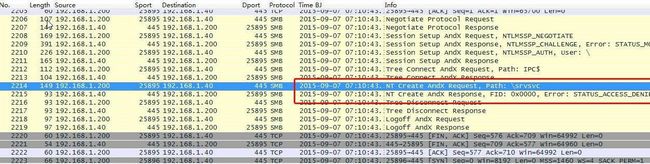
图26
4)MS07-029漏洞
# MS07-029漏洞扫描部分源码
function check_ms07_029(host)
--check for safety flag
if(nmap.registry.args.safe ~= nil) then
return true, NOTRUN
end
if(nmap.registry.args.unsafe == nil) then
return true, NOTRUN
end
--create the SMB session
local status, smbstate
status, smbstate = msrpc.start_smb(host, msrpc.DNSSERVER_PATH)
if(status == false) then
return false, NOTUP --if not accessible across pipe then the service is inactive
end
--bind to DNSSERVER service
local bind_result
status, bind_result = msrpc.bind(smbstate, msrpc.DNSSERVER_UUID, msrpc.DNSSERVER_VERSION)
if(status == false) then
msrpc.stop_smb(smbstate)
return false, UNKNOWN --if bind operation results with a false status we can't conclude anything.
end
--call
local req_blob, q_result
status, q_result = msrpc.DNSSERVER_Query(
smbstate,
"VULNSRV",
string.rep("\\\13", 1000),
1)--any op num will do
--sanity check
msrpc.stop_smb(smbstate)
if(status == false) then
stdnse.print_debug(
3,
"check_ms07_029: DNSSERVER_Query failed")
if(q_result == "NT_STATUS_PIPE_BROKEN") then
return true, VULNERABLE
else
return true, PATCHED
end
else
return true, PATCHED
end
end尝试打开“\DNSSERVER”,报错,未开启DNS RPC服务。
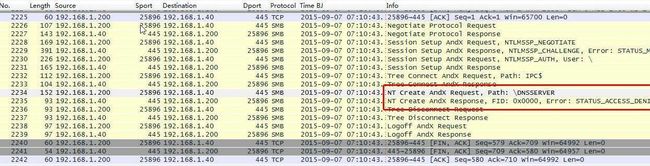
图27
三、分析思路
在流量截获类产品抓获的流量中,目前进行木马分析匹配主要还是通过域名、IP等字符串的匹配形式作为威胁事件的告警。如果受攻击单位的主机是统一配置DNS服务器(10.x.x.2)进行解析上网的,流量截获类产品抓到的发包主机IP其实是DNS服务器的IP(10.x.x.2)。
当木马动态域名已经解析失效,就无法根据请求响应中查出到底是哪台主机IP中了木马。
那么就可以利用以下两种方法进行排查:
(一)定位内网中毒主机
1、借助内网的上网行为管理、流量控制、IPS等设备进行捕获。增加一条TCP访问策略监控访问木马域名(类似于f33**88.3322.org)任意端口的内网主机IP。
2、如果域名解析不到IP,通过在出口DNS服务器上增加解析策略,将木马域名(类似于f33**88.3322.org)解析到可以访问的公网IP再监测。
(二)Wireshark抓包分析
1、找出存在探测行为的主机(ARP、TCP、漏洞扫描、暴力破解等)特征的IP,判断中毒主机
2、通过策略【tcp】查询TCP端口-连接最多的端口(比如445端口产生了最多的数据),判断影响范围
3、通过【ip.addtr=xxx.xxx.xxx.xx】分析最先产生中毒迹象主机【受到感染的第一个源IP】
4、DNS协议分析。过滤这台主机的DNS协议数据,从域名、IP、通信时间间隔综合判断,初步找出可疑域名。
5、判断可疑域名当前的存活状态,通讯数据。
6、从受到感染的第一个源IP开启的端口判断是由什么方式被感染和入侵的原因。
四、分析实战
(一)“Lpk.dll”
找出存在探测行为的主机
一台主机172.25.112.96不断对172.25.112.1/24网段进行TCP445端口扫描,这个行为目的在于探测内网中哪些机器开启了SMB服务,这种行为多为木马的通信特征。过滤这个主机IP的全部数据,发现存在大量ARP协议,且主机172.25.112.96也不断对内网网段进行ARP扫描。
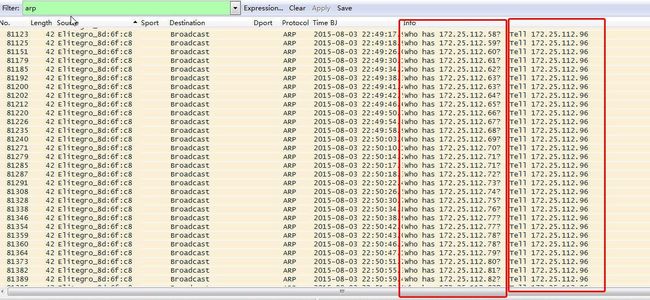
图28
域名、IP、通信时间间隔综合分析
第一步,DNS协议分析。过滤这台主机的DNS协议数据,从域名、IP、通信时间间隔综合判断,初步找出可疑域名。如域名yuyun168.3322.org,对应IP为61.160.213.189。
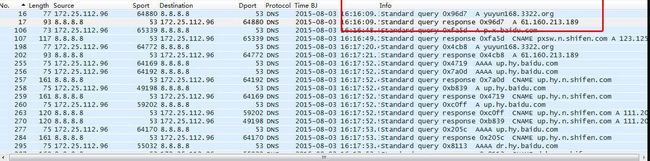
图29
过滤IP为61.160.213.189的全部数据可以看到主机172.25.112.96不断向IP地址61.160.213.189发起TCP7000端口的请求,并无实际通信数据,时间间隔基本为24秒。初步判断为木马回联通信。
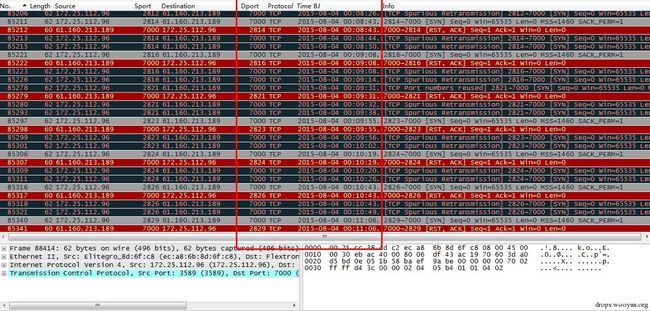
图30
(二)飞客(Conficker)蠕虫
完全依靠域名(DNS)的安全分析是不够的,一是异常通信很难从域名解析判断完整,二是部分恶意连接不通过域名请求直接与IP进行通信。在对这台机器的Http通信数据进行分析时,又发现了异常:HTTP协议的头部请求中存在不少的“GET /search?q=1”的头部信息。
如IP为95.211.230.75的请求如下:
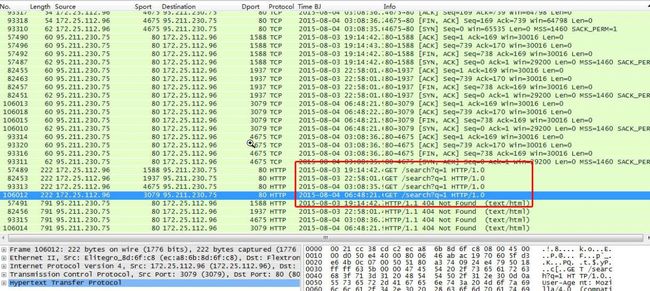
图31
通过请求特征“/search?q=1”继续分析,如IP地址221.8.69.25,请求时间不固定,大约在20秒至1分钟。
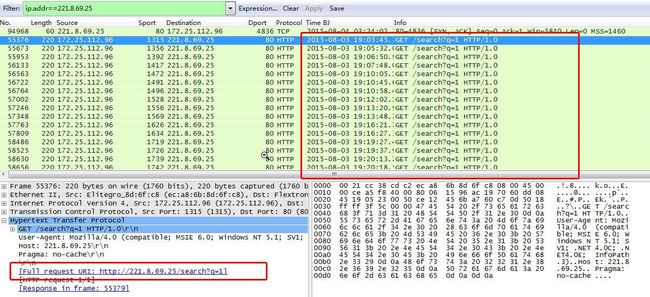
图32
当发现同一个URL请求多次但是IP不同,可通过dns协议筛选出域名和HTTP返回状态,判断该病毒请求是否采用了DGA算法随机生成的C&C域名。
五、取证分析之Pcap包处理
对于以上提到的方法,有两种办法提取特定的信息提升工作效率。一是用Wireshark自带工具tsharkWireshark自带工具tshark工具,其次是使用脚本提取五元组信息进行统计。
(一)Wireshark自带工具tshark
tshark -r D:\DATA\1.cap -Y "ip.addr==199.59.243.120" -w E:\DATA\out\1.cap
-r 源目录地址,
-Y 过滤命令(跟Wireshrk中的Filter规则一致)
-w 输出目录地址。(二)Python编程
我在工作中结合实际需求用scapy写了批量处理多个pcap包提取五元组信息的脚本。
1.给定某目录,目录下面全部为pcap包(以.pcap结尾的文件)。编写python程序,计算两个端点Ip的通信数据量的大小,把通信量最大的前100名两个端点ip和通信量大小列出来,存入到top100-data.txt中。
# coding:utf-8
# author : lipss
try:
import scapy.all as scapy
from scapy.layers import http
except ImportError:
import scapy
import BitVector
import os
import re
import time
import glob # 遍历子目录文件内容
import sys
sys.setrecursionlimit(5000000) #例如这里设置为一百万
#import logging
# 脚本要求
# 给定某目录,目录下面全部为pcap包(以.pcap结尾的文件)。编写python程序,计算两个端点Ip的通信数据量的大小,把通信量最大的前100名两个端点ip和通信量大小列出来,存入到top100-data.txt中。
# 枚举通信量,将长度数值列表写入临时存储
# 从大到小排序后取前1000个值
# 筛选这一千个值对应的行数完整文件内容放入新的统计列表
# 日志提示
# logging.basicConfig(
# level=logging.INFO, # filename='/tmp/wyproxy.log',
# format='%(asctime)s [%(levelname)s] %(message)s',
# )
sig_list = []
all_top_1000_list = [] # 所有Top1000的值
class SimpleHash():
def __init__(self,cap,seed):
self.cap=cap
self.seed=seed
#print self.cap,self.seed
def hash(self,value):
ret=0
#print len(value)
for i in range(len(value)):
ret+=self.seed*ret+ord(value[i])
#print ret
return (self.cap-1)&ret
class BloomFilter():
def __init__(self,BIT_SIZE=1<<25):
self.BIT_SIZE=1<<25
self.seeds=[5,7,11,13,31,37,61]
self.bitset=BitVector.BitVector(size=self.BIT_SIZE)
self.hashFunc=[]
for i in range(len(self.seeds)):
#print i
self.hashFunc.append(SimpleHash(self.BIT_SIZE,self.seeds[i]))
def insert(self,value):
for f in self.hashFunc:
loc=f.hash(value)
#print loc
self.bitset[loc]=1
#print self.bitset[loc]
def isContaions(self,value):
if value==None:
return False
ret=1
for f in self.hashFunc:
loc=f.hash(value)
#print loc
#print self.bitset[loc]
ret=ret&self.bitset[loc]
#rint ret
#print ret
return ret
bloomfilter=BloomFilter()
# check repeat
class BloomFilterJudge():
def __init__(self):
global bloomfilter
def determine(self,url):
if bloomfilter.isContaions(url)==False:
bloomfilter.insert(url)
return True
else:
return False
# 处理时间戳
def convert_time(time_value):
# 获取当前时间戳
time_now = int(time_value)
# 转换成localtime,数组形式。
time_local = time.localtime(time_now)
# 转换成新的时间格式(2018-05-26 20:20:20)
current_t = time.strftime("%Y-%m-%d %H:%M:%S", time_local)
return current_t
# 处理协议内容
def parse_pcap(pcap_path):
# logging.info("Starting Pcap Analysis...")
sava_file = pcap_path + '.tmp'
_protocol = "unknow" # 传输层协议初始值
packets = scapy.PcapReader(pcap_path) # 解决无法读取大文件问题
file_content = open(sava_file, 'a+')
while True:
packege = packets.read_packet()
if packege is None:
break
else:
# print repr(packege) #Debug
# logging.info("{0}".format(repr(packege))) # 显示跑的时间
# print packege.payload.len
current_t = convert_time(packege.time)
if 'TCP' == packege.payload.payload.name : # 获取上层协议名
_protocol = "TCP"
elif 'UDP' == packege.payload.payload.name :
_protocol = "UDP"
else:
_protocol = "unknow protocol"
try:
content = ("{0}\t\tsrc_ip:{1: <13}\t\tdst_ip:{2: <13}\t{3: <5}\t{4: <9}\tlength:{5}").format(current_t, packege['IP'].src,
packege['IP'].dst,
_protocol,
packege.payload.payload.payload.name,
packege.payload.len)
except Exception, e:
print pcap_path
print repr(packege['Ether'])
file_content.write(content + '\n') # 统计所有数值
file_content.close()
packets.close()
# 读取目录内结果
def input_multi_file(file_extension):
tmp_list = []
# 只读取res后缀文件
for _file in glob.glob(os.getcwd()+"//"+ '*.'+file_extension):
tmp_list.append(_file)
return tmp_list
if __name__ == '__main__':
# pcap_path = "pcap222.pcap" # debug
# parse_pcap(pcap_path) # debug
# 1、读取目录内的pcap文件
_path_list = input_multi_file("pcap")
# 2、对当前目录下所有文件的指定第1列、第2列(以0为索引),提取去重
for pcap_path in _path_list:
parse_pcap(pcap_path)
## 3、从大到小排序,提取Top值,写入到文本中
file_content = open(pcap_path + '.tmp', "r") # 读取单个PCAP包数值的临时存储文件
content_lines = file_content.readlines() # 读取全部内容 ,并以列表方式返回
file_content.close() # 关闭句柄
sig_list = content_lines[:] # 列表复制
reip = r'length:\d+' # 提取length部分
lenngth_value = []
for sig_list_value in sig_list:
lenngth = re.findall(reip, sig_list_value)
lenngth_str = "".join(lenngth)
lenngth_value.append(int(lenngth_str.split(':')[1]))
lenngth_value.sort(reverse=True) # 降序排序
lenngth_value_top100 = []
for lenngth_index in range(0,100): # 提取Top100最大的值
lenngth_value_top100.append(lenngth_value[lenngth_index])
sig_list_tmp = [] # 先存储到列表里,然后方便去重复
bloomFilterJudge = BloomFilterJudge()
for sig_index in range(0,len(lenngth_value_top100)): # 提取Top1000最大的值
for line in sig_list:
if cmp(line.strip().split()[-1].split(':')[1] ,str(lenngth_value_top100[sig_index]))==0 : # 对比Top1000列表,将数值完整取出
with open(pcap_path + '.top100', 'a+') as file: # 储存到top100文件里
dst_ip = r'dst_ip:\d+\.\d+\.\d+\.\d+'
dst_ip_value = re.findall(dst_ip, line) # 目标IP不一样的IP筛选出来,避免仅仅因为时间不同就重复存储
if bloomFilterJudge.determine(str(hash(str(dst_ip_value)))): # 利用bloomfilter检测重复值,先加密再计算。
print "[INFO]" + line.strip()
file.write(line.strip() + '\n')
else:
print "[WARNING]" + line.strip() + " has exist"
# 4、将所有的.top100文件内容集中到top100.txt
all_top100 = input_multi_file("top100")
for top100_path in all_top100:
# 读取文件
pcap_file = open(top100_path , "r") # 读取单个PCAP包数值的临时存储文件
pcap_file_lines = pcap_file.readlines() # 读取全部内容 ,并以列表方式返回
pcap_file.close() # 关闭句柄
# 追加文件top100.txt
with open(os.getcwd() + "\\" 'top100-data.txt', 'a+') as file:
file.write(top100_path+'\n')
for top_100_vale in pcap_file_lines:
file.write(top_100_vale)
# 5、删除所有.tmp、.top100文件
tmp_top100_file = input_multi_file("top100")
for tmp in tmp_top100_file:
os.remove(tmp)
tmp_file = input_multi_file("tmp")
for tmp in tmp_file:
os.remove(tmp)2.给定某目录,目录下面全部为pcap包(以.pcap结尾的文件)。编写python程序,把每个pcap包中的每条记录的源IP、目的IP、源端口、目的端口、时间、协议提取出来,写到一个flow.txt中。
# coding:utf-8
# author : lipss
try:
import scapy.all as scapy
from scapy.layers import http
except ImportError:
import scapy
import os
import time
import glob # 遍历子目录文件内容
import sys
sys.setrecursionlimit(5000000) #例如这里设置为一百万
#import logging
# 日志提示
# logging.basicConfig(
# level=logging.INFO, # filename='/tmp/wyproxy.log',
# format='%(asctime)s [%(levelname)s] %(message)s',
# )
# 时间:1个G 2.5小时,600M 1.5小时
# 脚本要求
# 给定某目录,目录下面全部为pcap包(以.pcap结尾的文件)。
# 编写python程序,把每个pcap包中的每条记录的源IP、目的IP、源端口、目的端口、时间、协议提取出来,写到一个flow.txt中。
sava_file = os.getcwd() + '\\flow.txt'
# 处理时间戳
def convert_time(time_value):
# 获取当前时间戳
time_now = int(time_value)
# 转换成localtime,数组形式。
time_local = time.localtime(time_now)
# 转换成新的时间格式(2018-05-26 20:20:20)
current_t = time.strftime("%Y-%m-%d %H:%M:%S", time_local)
return current_t
# 处理协议内容
def parse_pcap(pcap_path):
#logging.info("Starting Pcap Analysis...")
_protocol = "unknow" # 传输层协议初始值
packets = scapy.PcapReader(pcap_path) # 解决无法读取大文件问题
file_content = open(sava_file, 'a+')
while True:
packege = packets.read_packet()
if packege is None:
break
else:
# print repr(packege) #Debug
# print packege.load
#logging.info("{0}".format(repr(packege))) # 显示跑的时间
current_t = convert_time(packege.time)
if 'TCP' == packege.payload.payload.name : # 获取上层协议名
_protocol = "TCP"
elif 'UDP' == packege.payload.payload.name :
_protocol = "UDP"
elif 'ARP' == packege.payload.name :
_protocol = "ARP"
else:
_protocol = "unknow protocol"
try:
if _protocol == "ARP" or 'ARP' == packege.payload.name :
print("{0}\t\tsrc_ip:{1:*<13}\t\tdst_ip:{2}\t\t{3}\t\t{4}").format(current_t,packege['ARP'].psrc,
packege['ARP'].pdst,
_protocol,
packege.payload.payload.payload.name)
content = ("{0}\t\tsrc_ip:{1: <13}\t\tdst_ip:{2: <13}\t\t{3}\t\t{4}").format(current_t, packege['ARP'].psrc,
packege['ARP'].pdst,
_protocol,
packege.payload.payload.payload.name)
else:
print("{0}\t\tsrc_ip:{1: <13}\t\tdst_ip:{2: <13}\tsport:{3: <5}\tdport:{4}\t{5}\t{6}").format(current_t,packege['IP'].src,
packege['IP'].dst,
packege['IP'].sport,
packege['IP'].dport,
_protocol,
packege.payload.payload.payload.name)
content = ("{0}\t\tsrc_ip:{1: <13}\t\tdst_ip:{2: <13}\tsport:{3: <5}\tdport:{4}\t{5}\t{6}").format(current_t, packege['IP'].src,
packege['IP'].dst,
packege['IP'].sport,
packege['IP'].dport,
_protocol,
packege.payload.payload.payload.name)
except Exception, e:
print pcap_path
print repr(packege['Ether'])
file_content.write(content + '\n')
file_content.close()
packets.close()
# 读取目录内结果
def input_multi_file():
tmp_list = []
# 只读取res后缀文件
for _file in glob.glob(os.getcwd()+"//"+ '*.pcap'):
tmp_list.append(_file)
print('[+] The input pcap file is %s' % _file)
return tmp_list
if __name__ == '__main__':
#parse_pcap("2.pcap") # debug
# 1、读取目录内的pcap文件
_path_list = input_multi_file()
# 2、对当前目录下所有文件的指定第1列、第2列(以0为索引),提取去重
for pcap_path in _path_list:
parse_pcap(pcap_path)
3.对于第二步得到的flow.txt,将源和目的ip全部提取出来,去重后存储于某文件,得到ip.txt。
#!/usr/bin/python
# coding:utf-8
# author : lipss
import re
import sys
import os
import socket
import requests
import json
import tablib
ip_list = []
# 脚本要求
# 对于第二步得到的flow.txt,将源和目的ip全部提取出来,去重后存储于某文件,得到ip.txt。
# 额外功能:增加了对IP出现次数的统计
if __name__ == '__main__':
# 文件读取
f = open(os.getcwd() + '\\flow.txt', "r")
lines = f.readlines()
f.close()
# 正则表达式
reip = r'\d+\.\d+\.\d+\.\d+'
#源地址出现次数
arry_source = {}
for line in lines:
ip = re.findall(reip, line)
if ip:
if arry_source.has_key(ip[0]):
arry_source[ip[0]] = arry_source[ip[0]] + 1
else:
arry_source[ip[0]] = 1
print "源地址数目统计"
source_List = list(set(arry_source.values()))
source_List.sort(reverse=True)
# 统计次数从大到小输出
for ipNum in source_List:
for ip in arry_source:
if (ipNum == arry_source[ip]):
print("{0: <13}\t--->\t{1: <13}").format(ip,str(arry_source[ip]))
ip_list.append(ip)
# 目的地址出现次数
arry_aim = {}
for line in lines:
ip = re.findall(reip, line)
if ip:
if arry_aim.has_key(ip[1]):
arry_aim[ip[1]] = arry_aim[ip[1]] + 1
else:
arry_aim[ip[1]] = 1
print "目的地址数目统计"
aim_List = list(set(arry_aim.values()))
aim_List.sort(reverse=True)
for ipNum in aim_List:
for ip in arry_aim:
if (ipNum == arry_aim[ip]):
print("{0: <13}\t--->\t{1: <13}").format(ip,str(arry_aim[ip]))
ip_list.append(ip)
# 源地址、目的地址集合去重复
all_List = list(set(ip_list))
all_List.sort(reverse=True)
sava_file = os.getcwd() + '\\ip.txt'
file_content = open(sava_file, 'a+')
for content in all_List:
file_content.write(content + '\n')
file_content.close()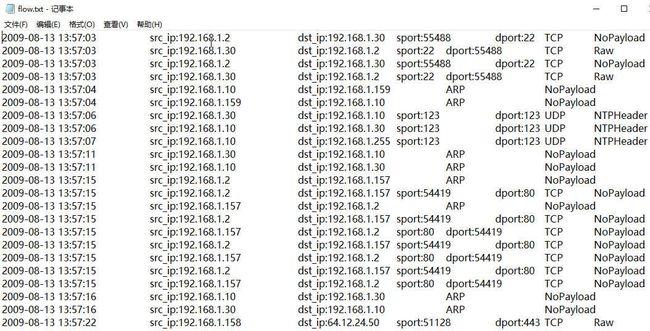
图33
可视化的Pcap平台目前有几个看起来很厉害的开源工具,有时间会分析一下源码再发改版。
- 自动化分析工具
http://le4f.net/post/post/pcap-online-analyzer
https://github.com/le4f/pcap-analyzer
https://github.com/thepacketgeek/cloud-pcap
https://github.com/madpowah/ForensicPCAP六、参考
WireShark黑客发现之旅(2)—肉鸡邮件服务器
WireShark黑客发现之旅(3)—Bodisparking恶意代码
Wireshark黑客发现之旅(4)—暴力破解
WireShark黑客发现之旅(5)—扫描探测
WireShark黑客发现之旅(6)—“Lpk.dll劫持+ 飞客蠕虫”病毒
WireShark黑客发现之旅(7)—勒索邮件
WireShark黑客发现之旅(8)—针对路由器的Linux木马
https://juejin.im/entry/579b18882e958a00663f7333