Node.js学习 - 异步I/O原理
事件驱动
事件机制
在前端编程中,事件的应用十分广泛,DOM上的各种事件。在Ajax大规模应用之后,异步请求更得到广泛的认同,而Ajax亦是基于事件机制的
Node.js能够在众多的后端Javascript技术中脱颖而出,正是因其基于事件的特点而受到欢迎。比如与Rhino来做比较,文件读取等操作,均是同步操作进行的
Node.js加载V8引擎助力,能在短短两年内达到可观运行效率,并迅速流行
事件驱动模型
Node.js中大部分的模块,都继承自Event模块。Event(events.EventEmitter)模块是一个简单的事件监听器模式的实现。具有addListener/on、once、removeListener、removeAllListener、emit等基本的事件监听模式的方法实现
事件机制的实现
从另一个角度来看,事件监听器模式也是一种事件钩子(hook)的机制,利用事件钩子导出内部数据或状态给外部调用者
如果不通过事件钩子的形式,对象运行期间的中间值、内部状态,我们是无法获取到的。这种通过事件钩子的方式,可以使编程者不用关注组件时如何启动和执行的,只需要关注在需要的事件点上即可。
var options = {
host: 'www.google.com',
port: 80,
path: '/upload',
method: 'POST',
};
var req = http.request(options,function(res)=>{
console.log('STATUS: ' + res.statusCode)
console.log('HEADERS: ' + JSON.stringify(res.headers))
res.setEncoding('utf8')
// 只需要关注on.data和下方的on.error两个事件
// 设定相应的回调函数即可
res.on('data',function(chunk){
console.log('Body: ' + chunk)
})
})
req.on('error',function(e){
console.log('problem with request: ' + e.message)
})
req.write('data\n')
req.write('data\n')
req.end()
异步I/O模型
异步I/O
在操作系统中,程序运行的控件分为内核空间和用户空间。我们常常提到的异步IO,实质上是指用户空间中的程序不用依赖内核空间中的I/O操作完成,即可进行后续任务
异步IO的效果就是getFileFromNet的调用不依赖于getFile调用的结束
getFile('file_path')
getFileFromNet('url')
实现I/O并行
多线程单进程
单线程多进程
异步I/O的必要性
现在的大型web应用中,一个事务往往需要跨越网络几次才能完成最终处理。如果网络速度不够理想,m和n的值会变大
这种场景下的异步I/O会体现其优势,m+n+…与max(m,n,…)之间的优势一目了然
Node.js天然支持这种异步I/O
阻塞与非阻塞&异步与同步
I/O的阻塞与非阻塞(内核特点)
阻塞模式的I/O会造成应用程序等待,直到I/O完成。同时操作系统也支持将I/O操作设置为非阻塞模式,这时应用程序调用将可以在没有拿到真正数据时就立即返回,为此应用程序需要多次调用才能确认I/O操作是否完全完成
I/O的异步与同步
I/O的异步与同步出现在应用程序中,如果做阻塞I/O调用,应用程序等待调用的完成过程就是一种同步状态。相反,I/O为非阻塞模式时,应用程序则是异步的
当进行非阻塞I/O调用时,要读取完整的数据,应用程序需要进行多次轮询,才能确保读取数据完成,以进行下一步操作
理想的异步I/O
应用程序发起异步调用,不需要进行轮询,进而处理下一个任务,在I/O完成后通过信号或者回调将数据传递给应用程序
libev的作者在linux中重新实现了一个异步I/O的库:libeio,是指依然是采用线程池与非阻塞I/O模拟出来的异步I/O
Window平台有一种独有的内核异步I/O方案:IOCP。IOCP的思路是调用异步方法,然后等待I/O完成通知。IOCP内部依旧通过线程实现,而这些线程由系统内核接手管理
Node.js中的异步I/O
由于Window和Linux平台的差异,Node.js提供的libuv来作为抽象封装层,使得平台兼容性的判断都由这一层来完成,保证了上层的Node.js与下层的libeio/libev及IOCP之间各自独立。Node.js编译期间会判断平台条件,选择性编译unix目录或win目录下的源文件到目标程序中
事件循环
高并发策略
一般来说,高并发解决方案就是提供多线程模型,服务器为每个客户端请求分配一个线程,使用同步I/O,系统通过线程切换来弥补同步I/O调用的事件开销。
大多数网站的服务器都不会做大多的计算,他们接收到请求后,把请求交给其它服务来处理,然后等着结果返回,最后再把结果发回给客户端
Node.js采用了单线程模型来处理,它不会为每个接入请求分配一个线程,而是用一个主线程处理所有的请求,然后对I/O操作进行异步处理,避开创建、销毁线程以及在线程间切换的开销和复杂性
Node.js运行原理
应用层:即Javascript交互层,常见的就是Node.js模块,如http、fs等
V8引擎层:即利用V8引擎来解析Javascript语法,进而和下层的API交互
NodeAPI层:为上层模块提供系统调用,和操作系统集行交互
LIBUV层:使跨平台的底层封装,实现了事件循环、文件操作等
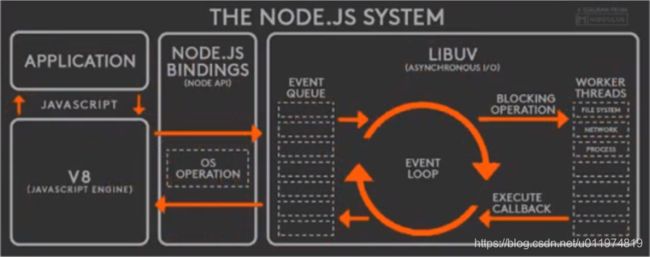
事件循环实现原理
- 事件队列
定义一个先进先出(FIFO)的数据结构,用js数组来描述
利用数组来模拟队列结构,数组的第一个元素是队列的头部,最后一个元素是队列的尾部,push()就是在队列的尾部插入一个元素,shift()就是从队列的头部弹出一个元素
/**
* 定义事件队列
* 入队 push()
* 出队 shift()
* 空队列 length = 0
**/
globalEventQueue : []
- 接口请求入口
每一个请求都会被拦截,并进入处理函数
把用户请求包装成事件,放到队列里,然后继续接收其它请求
/**
* 接收用户请求
* 每个请求都会进入该函数
* 传递参数 request 和 response
**/
processHttpRequest: function(request,response){
// 定义一个事件对象
var event = createEvent({
params: request.params,
result: null,
callback: funciton(){
}
})
// 在队列尾部添加事件
globalEventQueue.push(event)
}
- Event Loop
当主线程处于空闲时就开始循环事件队列,所以,还需要一个函数来循环事件队列
主线程不停检测事件队列,对于I/O任务,交给线程池处理,非I/O任务,主线程处理并返回
/**
* 事件循环主体,主线程择机执行
* 循环遍历事件队列,处理非I/O任务
* 处理I/O任务
* 执行回调,返回给上层
**/
eventLoop: function(){
while(this.globalEventQueue.length > 0){
var event = this.globalEventQueue.shift()
if(isIOTask(event)){
var thread = getThreadFromThreadPool()
thread.handleIOTask(event)
}else{
var result = handleEvent(event)
event.callback.call(null,result)
}
}
}
- 处理I/O任务
线程持接到任务后,直接处理IO操作,比如读取数据库、处理PHP程序
当I/O任务完成后,就执行回调,把请求结果存入事件中,并将该事件重新放入队列中,等待循环,最后释放当前线程,当主线程再次循环到该事件,就直接处理。
/**
* 处理IO任务
* 处理完后将事件添加到队列尾部
* 释放进程
**/
handleIOTask: function(event){
var curThread = this
var optDatabase = function(params,callback){
var result = readDataFromDB(params)
callback.call(null,result)
}
optDatabase(event.params,function(result){
event.result = result
event.isIOTask = false
this.globalEventQueue.push(event)
releaseThread(curThread)
})
}
业务场景
- 不适用场景
当碰到cpu密集型任务(对数据进行压缩、解密、解压),这时Node.js会自己亲自处理,一个个的计算
Node.js本身只有一个Event Loop,当Node.js被cpu密集型任务占用,导致其他任务被阻塞,系统却还有cpu内核处于闲置状态,就造成了资源浪费
Node.js并不适合cpu密集型任务
- 适用场景
RESTful API - 请求和相应只需要少量文本,并不需要大量逻辑处理,因此可以并发处理数万条连接
聊天服务 - 轻量级、高流量,没有复杂的计算逻辑
知识技能获取,感谢[网易云课堂 - 微专业 - 前端高级开发工程师]运营团队。