爬虫实战:Requests+BeautifulSoup 爬取京东内衣信息并导入表格(python)
准备工作
假如我们想把京东内衣类商品的信息全部保存到本地,通过手工复制粘贴将是一项非常庞大的工程,此时,可以用python爬虫实现。
第一步:分析网页地址
起始网页地址
起始网页地址
https://search.jd.com/Search?keyword=%E5%86%85%E8%A1%A3%E5%A5%B3&suggest=4.def.0.base&wq=%E5%86%85%E8%A1%A3%E5%A5%B3&page=1&s=56&click=1
(在这里你会看到,明明在浏览器URL栏看到的是中文,但是复制url,粘贴到记事本或代码里面,就会变成如下这样?)
在很多网站的URL中对一些get的参数或关键字进行编码,所以我们复制出来的时候,会出现问题。但复制过来的网址可以直接打开。本例子不用管这个。
那么,怎样才能自动爬取第一页以外的其他页面,打开第三页,网页地址如下,分析发现和第一页区别在于:第一页最后&page=1,第三页&page=3
我们可以想到自动获取多个网页的方法,可以for循环实现,每次循环后,page+1
第三页网址如图
https://search.jd.com/Search?keyword=%E5%86%85%E8%A1%A3%E5%A5%B3&suggest=4.def.0.base&wq=%E5%86%85%E8%A1%A3%E5%A5%B3&page=3&s=56&click=1
第一步:解析代码
先选择商品
一个li标签为一个商品
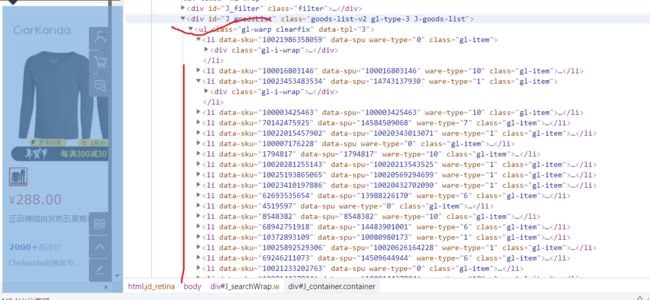
然后选择具体信息
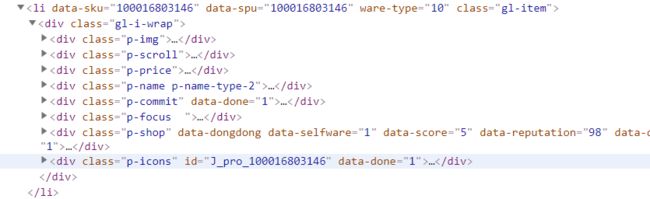
这部分自己慢慢研究网页源代码吧
第二步:代码
from bs4 import BeautifulSoup
import numpy as np
import requests
from requests.exceptions import RequestException
import pandas as pd
#读取网页
def craw(url,page):
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36"}
html1 = requests.request("GET", url, headers=headers,timeout=10)
html1.encoding ='utf-8' # 加编码,重要!转换为字符串编码,read()得到的是byte格式的
html=html1.text
return html
except RequestException:#其他问题
print('读取error')
return None
#解析网页并保存数据到表格
def pase_page(url,page):
html=craw(url,page)
html=str(html)
if html is not None:
soup = BeautifulSoup(html, 'lxml')
"---先选择商品--"
shangping=soup.select('#J_goodsList ul li')
for li in shangping:
"---名称---"
name=li.select('.p-name.p-name-type-2 em')
name=[i.get_text() for i in name]
"---价格---"
price = li.select('.p-price i')
price = [i.get_text() for i in price]
"---店铺---"
shop=li.select('.p-shop a')
shop= [i.get_text() for i in shop]
if(len(name)!= 0)and (len(price)!= 0) and ( len(shop) != 0):
#print('名称:{0} ,价格{1},店铺名:{2}'.format(name, price, shop))
information=[name,price,shop]
information=np.array(information)
information = information.reshape(-1,3)
information=pd.DataFrame(information,columns=['名称','价格','店铺'])
if page == 1:
information.to_csv('京东文胸数据1.csv', mode='a+', index=False) # mode='a+'追加写入
else:
information.to_csv('京东文胸数据1.csv', mode='a+', index=False, header=False) # mode='a+'追加写入
else:
print('解析error')
for i in range(1,10):#遍历网页1-10
url="https://search.jd.com/Search?keyword=%E5%86%85%E8%A1%A3%E5%A5%B3&suggest=4.def.0.base&wq=%E5%86%85%E8%A1%A3%E5%A5%B3&page="+str(i)+"&s=56&click=1"
pase_page(url,i)
print('第{0}页读取成功'.format(i))
print('结束')

本例子中我只选择了商品 名,价格,店铺名。你可以选择更多信息存取
![]()