爬虫+数据分析:重庆买房吗?爬取重庆房价
现在结婚,女方一般要求城里有套房。要了解近些年的房价,首先就要获取网上的房价信息,今天以重庆链家网上出售的房价信息为例,将数据爬取下来分析。
爬虫部分
一.网址分析
https://cq.fang.lianjia.com/loupan/

下面我们来分析我们所要提取的信息的位置,打开开发者模式查找元素,我们找到房子如下图.如图发现,一个房子信息被存储到一个li标签里。
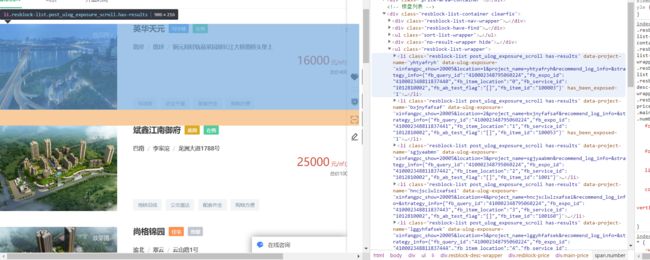
单击一个li标签,再查找房子名,地址,房价信息。

网址分析,当我点击下一页时,网络地址pg参数会发生变化。
第一页pg1,第二页pg2…

二.单页网址爬取
采取requests-Beautiful Soup的方式来爬取
from bs4 import BeautifulSoup
import numpy as np
import requests
from requests.exceptions import RequestException
import pandas as pd
#读取网页
def craw(url,page):
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36"}
html1 = requests.request("GET", url, headers=headers,timeout=10)
html1.encoding ='utf-8' # 加编码,重要!转换为字符串编码,read()得到的是byte格式的
html=html1.text
return html
except RequestException:#其他问题
print('读取error')
return None
for i in range(1,2):#遍历网页1
url="https://cq.fang.lianjia.com/loupan/pg"+str(i)+"/"
html=craw(url,i)
print(html)
print('结束')

三.网页信息提取
#解析网页并保存数据到表格
def pase_page(url,page):
html=craw(url,page)
html = str(html)
if html is not None:
soup = BeautifulSoup(html, 'lxml')
"--先确定房子信息,即li标签列表--"
houses=soup.select('.resblock-list-wrapper li')#房子列表
"--再确定每个房子的信息--"
for house in houses:#遍历每一个房子
"名字"
recommend_project=house.select('.resblock-name a.name')
recommend_project=[i.get_text()for i in recommend_project]#名字 英华天元,斌鑫江南御府...
#print(recommend_project)
"类型"
house_type=house.select('.resblock-name span.resblock-type')
house_type=[i.get_text()for i in house_type]#写字楼,底商...
#print(house_type)
"销售状态"
sale_status = house.select('.resblock-name span.sale-status')
sale_status=[i.get_text()for i in sale_status]#在售,在售,售罄,在售...
#print(sale_status)
"大地址:如['南岸', '南坪']"
big_address=house.select('.resblock-location span')
big_address=[i.get_text()for i in big_address]#['南岸', '南坪'],['巴南', '李家沱']...
#print(big_address)
"具体地址:如:铜元局轻轨站菜园坝长江大桥南桥头堡上"
small_address=house.select('.resblock-location a')
small_address=[i.get_text()for i in small_address]#铜元局轻轨站菜园坝长江大桥南桥头堡上,龙洲大道1788号..
#print(small_address)
"优势。如:['环线房', '近主干道', '配套齐全', '购物方便']"
advantage=house.select('.resblock-tag span')
advantage=[i.get_text()for i in advantage]#['环线房', '近主干道', '配套齐全', '购物方便'],['地铁沿线', '公交直达', '配套齐全', '购物方便']
#print(advantage)
"均价:多少1平"
average_price=house.select('.resblock-price .main-price .number')
average_price=[i.get_text()for i in average_price]#16000,25000,价格待定..
#print(average_price)
"总价,单位万"
total_price=house.select('.resblock-price .second')
total_price=[i.get_text()for i in total_price]#总价400万/套,总价100万/套'...
#print(total_price)
四.多页爬取,并将信息存储到表格
from bs4 import BeautifulSoup
import numpy as np
import requests
from requests.exceptions import RequestException
import pandas as pd
#读取网页
def craw(url,page):
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36"}
html1 = requests.request("GET", url, headers=headers,timeout=10)
html1.encoding ='utf-8' # 加编码,重要!转换为字符串编码,read()得到的是byte格式的
html=html1.text
return html
except RequestException:#其他问题
print('第{0}读取网页失败'.format(page))
return None
#解析网页并保存数据到表格
def pase_page(url,page):
html=craw(url,page)
html = str(html)
if html is not None:
soup = BeautifulSoup(html, 'lxml')
"--先确定房子信息,即li标签列表--"
houses=soup.select('.resblock-list-wrapper li')#房子列表
"--再确定每个房子的信息--"
for j in range(len(houses)):#遍历每一个房子
house=houses[j]
"名字"
recommend_project=house.select('.resblock-name a.name')
recommend_project=[i.get_text()for i in recommend_project]#名字 英华天元,斌鑫江南御府...
recommend_project=' '.join(recommend_project)
#print(recommend_project)
"类型"
house_type=house.select('.resblock-name span.resblock-type')
house_type=[i.get_text()for i in house_type]#写字楼,底商...
house_type=' '.join(house_type)
#print(house_type)
"销售状态"
sale_status = house.select('.resblock-name span.sale-status')
sale_status=[i.get_text()for i in sale_status]#在售,在售,售罄,在售...
sale_status=' '.join(sale_status)
#print(sale_status)
"大地址:如['南岸', '南坪']"
big_address=house.select('.resblock-location span')
big_address=[i.get_text()for i in big_address]#['南岸', '南坪'],['巴南', '李家沱']...
big_address=''.join(big_address)
#print(big_address)
"具体地址:如:铜元局轻轨站菜园坝长江大桥南桥头堡上"
small_address=house.select('.resblock-location a')
small_address=[i.get_text()for i in small_address]#铜元局轻轨站菜园坝长江大桥南桥头堡上,龙洲大道1788号..
small_address=' '.join(small_address)
#print(small_address)
"优势。如:['环线房', '近主干道', '配套齐全', '购物方便']"
advantage=house.select('.resblock-tag span')
advantage=[i.get_text()for i in advantage]#['环线房', '近主干道', '配套齐全', '购物方便'],['地铁沿线', '公交直达', '配套齐全', '购物方便']
advantage=' '.join(advantage)
#print(advantage)
"均价:多少1平"
average_price=house.select('.resblock-price .main-price .number')
average_price=[i.get_text()for i in average_price]#16000,25000,价格待定..
average_price=' '.join(average_price)
#print(average_price)
"总价,单位万"
total_price=house.select('.resblock-price .second')
total_price=[i.get_text()for i in total_price]#总价400万/套,总价100万/套'...
total_price=' '.join(total_price)
#print(total_price)
"--------------写入表格-------------"
information = [recommend_project, house_type, sale_status,big_address,small_address,advantage,average_price,total_price]
information = np.array(information)
information = information.reshape(-1, 8)
information = pd.DataFrame(information, columns=['名称', '类型', '销售状态','大地址','具体地址','优势','均价','总价'])
if page== 1 and j==0:
information.to_csv('链家网重庆房子数据.csv', mode='a+', index=False) # mode='a+'追加写入
else:
information.to_csv('链家网重庆房子数据.csv', mode='a+', index=False, header=False) # mode='a+'追加写入
print('第{0}页存储数据成功'.format(page))
else:
print('解析失败')
for i in range(1,101):#遍历网页1
url="https://cq.fang.lianjia.com/loupan/pg"+str(i)+"/"
pase_page(url,i)
print('结束')
五.多线程爬取
from bs4 import BeautifulSoup
import numpy as np
import requests
from requests.exceptions import RequestException
import pandas as pd
#读取网页
def craw(url,page):
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36"}
html1 = requests.request("GET", url, headers=headers,timeout=10)
html1.encoding ='utf-8' # 加编码,重要!转换为字符串编码,read()得到的是byte格式的
html=html1.text
return html
except RequestException:#其他问题
print('第{0}读取网页失败'.format(page))
return None
#解析网页并保存数据到表格
def pase_page(url,page):
html=craw(url,page)
html = str(html)
if html is not None:
soup = BeautifulSoup(html, 'lxml')
"--先确定房子信息,即li标签列表--"
houses=soup.select('.resblock-list-wrapper li')#房子列表
"--再确定每个房子的信息--"
for j in range(len(houses)):#遍历每一个房子
house=houses[j]
"名字"
recommend_project=house.select('.resblock-name a.name')
recommend_project=[i.get_text()for i in recommend_project]#名字 英华天元,斌鑫江南御府...
recommend_project=' '.join(recommend_project)
#print(recommend_project)
"类型"
house_type=house.select('.resblock-name span.resblock-type')
house_type=[i.get_text()for i in house_type]#写字楼,底商...
house_type=' '.join(house_type)
#print(house_type)
"销售状态"
sale_status = house.select('.resblock-name span.sale-status')
sale_status=[i.get_text()for i in sale_status]#在售,在售,售罄,在售...
sale_status=' '.join(sale_status)
#print(sale_status)
"大地址:如['南岸', '南坪']"
big_address=house.select('.resblock-location span')
big_address=[i.get_text()for i in big_address]#['南岸', '南坪'],['巴南', '李家沱']...
big_address=''.join(big_address)
#print(big_address)
"具体地址:如:铜元局轻轨站菜园坝长江大桥南桥头堡上"
small_address=house.select('.resblock-location a')
small_address=[i.get_text()for i in small_address]#铜元局轻轨站菜园坝长江大桥南桥头堡上,龙洲大道1788号..
small_address=' '.join(small_address)
#print(small_address)
"优势。如:['环线房', '近主干道', '配套齐全', '购物方便']"
advantage=house.select('.resblock-tag span')
advantage=[i.get_text()for i in advantage]#['环线房', '近主干道', '配套齐全', '购物方便'],['地铁沿线', '公交直达', '配套齐全', '购物方便']
advantage=' '.join(advantage)
#print(advantage)
"均价:多少1平"
average_price=house.select('.resblock-price .main-price .number')
average_price=[i.get_text()for i in average_price]#16000,25000,价格待定..
average_price=' '.join(average_price)
#print(average_price)
"总价,单位万"
total_price=house.select('.resblock-price .second')
total_price=[i.get_text()for i in total_price]#总价400万/套,总价100万/套'...
total_price=' '.join(total_price)
#print(total_price)
"--------------写入表格-------------"
information = [recommend_project, house_type, sale_status,big_address,small_address,advantage,average_price,total_price]
information = np.array(information)
information = information.reshape(-1, 8)
information = pd.DataFrame(information, columns=['名称', '类型', '销售状态','大地址','具体地址','优势','均价','总价'])
information.to_csv('链家网重庆房子数据.csv', mode='a+', index=False, header=False) # mode='a+'追加写入
print('第{0}页存储数据成功'.format(page))
else:
print('解析失败')
#双线程
import threading
for i in range(1,99,2):#遍历网页1-101
url1="https://cq.fang.lianjia.com/loupan/pg"+str(i)+"/"
url2 = "https://cq.fang.lianjia.com/loupan/pg" + str(i+1) + "/"
t1 = threading.Thread(target=pase_page, args=(url1,i))#线程1
t2 = threading.Thread(target=pase_page, args=(url2,i+1))#线程2
t1.start()
t2.start()
可能是网的问题,很多页的数据没有读取下来。

存储到的信息有近438条。原始数据有1838条。
可以自己把失败的页数存储下来,再重新请求一次。我这里就不搞啦。将就用。

![]()