Python爬虫实战Pro | (2) 分析ajax爬取今日头条街拍美图
在本篇博客中,我们以今日头条为例通过分析ajax请求来抓取网页数据。本次我们将抓取今日头条街拍美图,完成后,每一组图存放在以标题为名的本地文件夹中。
首先我们打开今日头条,搜索街拍:

右键查看网页源代码,我们发现原始网页代码中并不包含,当前页面的内容,如搜索上图中的洪爷:

可以初步判断这些内容通过ajax加载,然后用javascript渲染出来。
接下来,我们右键检查,选择Network选项卡,在选择XHR,勾选Preserve log:

果然下方出现了一个ajax请求,我们点击查看Preview,发现有一个data字段:

打开data字段:

里面包含20条数据,我们打开其中一条查看:

在title字段中我们发现了和当前网页内容相同的信息,正好是网页中的某一条标题,其他信息也能对得上,这就确定了这些数据确实由ajax加载。
由于我们要抓取组图,需要首先获取图片的url,我们发现data中还有一个image_list字段,里面存放图片的url:

所以,我们只需把image_list中的所有图片的url抓下来就行了,然后再请求url下载图片到本地。
接下里要做的就是用爬虫程序模拟ajax请求,提取图片url并下载,所以我们要先分析一下url的规律。切换到Headers选项卡:

发现这是一个GET请求,上方是其请求的url。接下来我们进一步分析一下这些url参数:
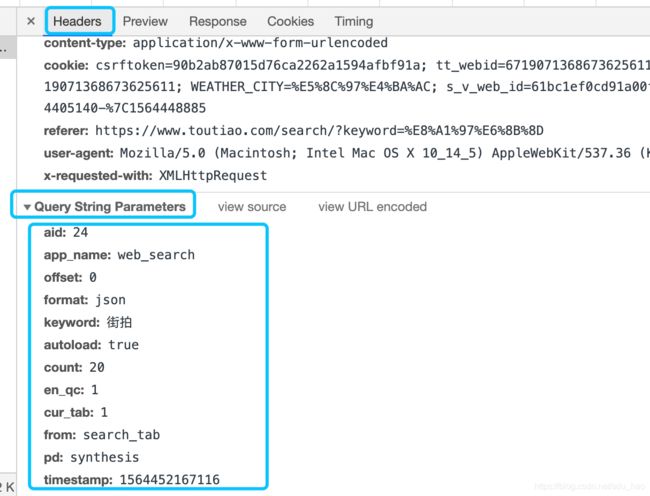
在Headers选项卡中继续下拉,找到Query String Parameters字段,查看url参数及其取值情况,这是第一个ajax请求的url参数,我们在页面中继续下拉,此时会出现其他ajax请求,继续查看他们的url参数情况,并进行对比:

我们发现这些url参数只有offset在变,第一个是0,第二个是20,第三个是40,每个ajax请求包含20条数据。至此,我们找出了ajax请求url的规律,接下来就可以爬取了。
还需要查看一下请求头,在程序中伪造一个请求头,模拟浏览器:

- 获取页面信息
def get_page(offset):
params = {
'aid':24,
'app_name':'web_search',
'offset':offset,
'format':'json',
'keyword':'街拍',
'autoload':'true',
'count':20,
'en_qc':1,
'cur_tab':1,
'from':'search_tab',
'pd':'synthesis',
}
base_url = 'https://www.toutiao.com/api/search/content/?'
url = base_url + urlencode(params)
try:
headers={
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'referer':'https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D',
'cookie':'csrftoken=90b2ab87015d76ca2262a1594afbf91a; tt_webid=6719071368673625611; UM_distinctid=16c3dd8e96b51f-0f2b848b564e9b-37677e02-13c680-16c3dd8e96c53d; tt_webid=6719071368673625611; WEATHER_CITY=%E5%8C%97%E4%BA%AC; s_v_web_id=61bc1ef0cd91a00ff0a7e18e0387bddc; __tasessionId=ibn1wter91564451301180; CNZZDATA1259612802=1826979738-1564405140-%7C1564448885',
'x-requested-with':'XMLHttpRequest'
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.json() #将返回结果转化为json
return None
except RequestException:
return None- 解析json数据
def get_images(json):
if json.get('data'):
data = json.get('data')
for item in data:
if item.get('title') is None: #如果该条数据没有title字段 找下一条
continue
title = re.sub('[\t]', '', item.get('title'))
images = item.get('image_list') #获取图片列表
for image in images:
origin_image = re.sub("list.*?pgc-image", "large/pgc-image", image.get('url')) #获取url 替换成大图
yield {
'image': origin_image,
'title': title
}- 下载并并保存图片
def save_images(item):
if not os.path.exists(item.get('title')):
os.mkdir(item.get('title'))
try:
response = requests.get(item.get('image'))
if response.status_code == 200:
file_path = '{0}/{1}.{2}'.format(item.get('title'),md5(response.content).hexdigest(),'.jpg') #md5可以去重
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(response.content)
else:
print("已经下载过了!")
except RequestException:
print("下载保存失败!")- 设置偏移
def main(offset):
json = get_page(offset)
for item in get_images(json):
print(item)
save_images(item)- 设置多线程
Start = 1
End = 20
if __name__ == '__main__':
''''
#顺序爬取
for i in range(Start,End+1):
main(i*20)
time.sleep(1)
'''
#多线程并行爬取
pool = Pool()
pool.map(main,[x*20 for x in range(Start,End+1)])
pool.close()
pool.join()- 完整代码
import requests
from urllib.parse import urlencode
from requests import RequestException
import os
from hashlib import md5
import time
from multiprocessing import Pool
import re
def get_page(offset):
params = {
'aid':24,
'app_name':'web_search',
'offset':offset,
'format':'json',
'keyword':'街拍',
'autoload':'true',
'count':20,
'en_qc':1,
'cur_tab':1,
'from':'search_tab',
'pd':'synthesis',
}
base_url = 'https://www.toutiao.com/api/search/content/?'
url = base_url + urlencode(params)
try:
headers={
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'referer':'https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D',
'cookie':'csrftoken=90b2ab87015d76ca2262a1594afbf91a; tt_webid=6719071368673625611; UM_distinctid=16c3dd8e96b51f-0f2b848b564e9b-37677e02-13c680-16c3dd8e96c53d; tt_webid=6719071368673625611; WEATHER_CITY=%E5%8C%97%E4%BA%AC; s_v_web_id=61bc1ef0cd91a00ff0a7e18e0387bddc; __tasessionId=ibn1wter91564451301180; CNZZDATA1259612802=1826979738-1564405140-%7C1564448885',
'x-requested-with':'XMLHttpRequest'
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.json() #将返回结果转化为json
return None
except RequestException:
return None
def get_images(json):
if json.get('data'):
data = json.get('data')
for item in data:
if item.get('title') is None: #如果该条数据没有title字段 找下一条
continue
title = re.sub('[\t]', '', item.get('title'))
images = item.get('image_list') #获取图片列表
for image in images:
origin_image = re.sub("list.*?pgc-image", "large/pgc-image", image.get('url')) #获取url 替换成大图
yield {
'image': origin_image,
'title': title
}
def save_images(item):
if not os.path.exists(item.get('title')):
os.mkdir(item.get('title'))
try:
response = requests.get(item.get('image'))
if response.status_code == 200:
file_path = '{0}/{1}.{2}'.format(item.get('title'),md5(response.content).hexdigest(),'.jpg') #md5可以去重
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(response.content)
else:
print("已经下载过了!")
except RequestException:
print("下载保存失败!")
def main(offset):
json = get_page(offset)
for item in get_images(json):
print(item)
save_images(item)
Start = 1
End = 20
if __name__ == '__main__':
''''
#顺序爬取
for i in range(Start,End+1):
main(i*20)
time.sleep(1)
'''
#多线程并行爬取
pool = Pool()
pool.map(main,[x*20 for x in range(Start,End+1)])
pool.close()
pool.join()
- 爬取效果
