【NLP】文献翻译2——英语单词语义相似性的Word2Vec模型分析
Word2Vec Model Analysis for Semantic Similarities in English Words
- 摘要
- 1. 简介
- 2. 相关工作
- 3. 方法论
-
- 3.1 语义相似性
- 3.2 系统概述
- 3.3 词嵌入
- 3.4 数据集
- 3.5 预处理
- 3.6 Word2Vec配置设置
- 4. 评价
-
- 4.1 测试
- 4.2 测试结果分析
- 5. 结论和未来的工作
文献信息:
标题:英语单词语义相似性的Word2Vec模型分析
作者:Derry Jatnika, Moch Arif Bijaksana, Arie Ardiyanti Suryani
机构:School of Computing, Telkom University, Bandung, Indonesia, 40257
会议:4th International Conference on Computer Science and Computational Intelligence 2019
摘要
本文利用单词表示技术研究英语中单词之间相似度的计算。Word2Vec是本文采用的一种模型,将单词表示成矢量形式。本研究中的模型是以英文维基百科中的32万篇文章作为语料库形成的,然后采用Cosine相似度计算方法来确定相似度值。然后通过测试集gold standard WordSim-353多达353对单词和SimLex-999多达999对单词对该模型进行测试,测试集根据人的判断对相似度值进行了标注。采用Pearson相关性来了解相关性的准确性。本研究的相关结果为WordSim-353的相关度:0.665,SimLex-999的相关度:0.284,使用Windows大小为9和3。在使用Windows大小9和300矢量维度配置的情况下,本研究的相关结果是WordSim-353为0.665,SimLex-999为0.284。
关键词:Word2Vec;余弦相似性;皮尔逊相关度
1. 简介
语义相似性在语言学领域有着重要的作用,尤其是与词义相似性有关的领域。词义相似性是指寻找两个或两个以上的词之间的相似性。就词义相似性而言,两个词在句法上可能不同,但意义相同。例如,Me和I的意思相同。词义相似度的计算作为人类思维推理的结果,已经在语言学领域得到了广泛的体现,有了基本的规则。这种计算也可以通过计算机科学领域,即基于语言学领域的自然语言处理和文本挖掘的研究来完成。
自然语言处理是人工智能的科学领域之一,它涉及计算机与人类自然语言之间的交互作用。计算机需要先对接收到的人类语言进行处理,以便理解人类的意图,然后提供相应的回应。例如,计算机必须知道 Me和 I之间有多少相似之处的数值。
主要是利用词嵌入的Word2Vec模型计算词义的相似度和相关性的技术。Word2Vec是一种用于将单词表示为向量的模型。然后,可以利用Word2Vec模型产生的词向量值的余弦相似度公式生成相似度值。在Word2Vec模型的构建过程中,称为训练过程,一些特征用于产生Word2Vec模型,包括窗口大小和向量维度配置。前面的一些研究大多使用窗口大小和向量尺寸配置来生成Word2Vec模型。在本研究中,使用了多个窗口大小和向量尺寸配置来比较产生的Word2Vec模型的每个配置的相似度值。产生最佳相似度值的Word2Vec模型的配置将是本研究的结果。了解Word2Vec模型的最佳配置对于找到相似度词义的最佳值非常重要。
2. 相关工作
在之前关于Word2Vec模型相关的研究中,尝试通过对Word2Vec CBOW和Skip-Gram的一些架构配置来应用Word2Vec模型。研究使用了12万篇英文维基百科的训练数据,配置了窗口大小为5和向量维度为300的Word2Vec模型,以及最小的预处理程序:在英文维基百科的语料中删除XML标签。此研究对Word2Vec模型做了4个配置模型,分别是:1: 全英文CBOW维基百科(FW-CBOW)、全英文维基百科Skip-Gram(FW-SG)、简单英文CBOW维基百科(SW-CBOW)和简单英文维基百科Skip-Gram(SWSG)。预先训练好的Google News Skip-Gram模型,窗口大小为5和向量维度为300(GN-SG),作为它所做的4个模型的对比材料。
前期研究的评价采用召回率点计算系统值评价,利用gold standard WordSim-353测试集。研究结果指出,与其他模型相比,FW-CBOW模型产生的召回率点最好,累计得分7.03。这一结果甚至优于谷歌制作的Word2Vec模型。
因此,本研究将以FW-CBOW为主要基准,但修改后的Word2Vec模型有几种配置,如英语百科语料库中的32万篇文章、配置Word2Vec模型,即:窗口大小为3、6、9,向量维度为50、150、300。本研究将这些配置结合起来,产生9个Word2Vec模型,模型将利用测试集WordSim-353和SimLex-999的Pearson相关性,作为评价材料。
3. 方法论
3.1 语义相似性
语义相似性是一个可以衡量短文中意义相似性的概念。被比较的文本可以是单词、短句和文档的形式。语义相似性在自然语言处理和一些相关领域的任务中具有重要作用,如文本分类、文档聚类、文本摘要等。语义相似性是定义在文档或词语之上的度量标准,在文档或词语中,概念(ideas)已经定位了两者之间的距离,这是基于语义或语义内容的相似性,而不是关于其语法表达的可预测相似性。
Semantic similarity is metrics defined above documents or words, where ideas have located the distance between the two is based on the similarity of meaning or semantic content compared to predictable similarities regarding representation their syntax.
语义相似性也是一种数学工具,用于估计语言单位,概念或例子之间的语义关系的强度,通过根据支持其含义(supports its meaning)或描述其性质(describes its nature)的信息的比较获得的数字描述。例如,知道bicycle和motorcycle之间的相似性或car和horse之间的区别。语义相似性的例子可参见下表。

3.2 系统概述
本研究构建了一个可以利用Word2Vec模型表示计算词间相似度值的系统。本研究通过建立Word2Vec模型的几种配置来寻找最佳相似度值。配置是通过改变窗口大小设置和词向量尺寸来完成的。这个研究步骤如图所示。

3.3 词嵌入
Word Embeddings是自然语言处理中一组语言建模和学习技术特征的统称,其中单词或短语以实数向量的形式表示。在概念上,Word Embeddings涉及到数学公式。Word Embeddings中使用的模型多种多样,其中之一是Word2Vec模型。Word2Vec根据单词所具有的几个特征,如窗口大小和向量尺寸,将单词表示成向量。
从下图中可以看出,相似的词往往具有相同的向量值,并被归入同一区块。因此,Word2Vec可以从一个大型语料库的训练中捕捉到单词之间的相似度值。由此得到的相似度值是由单词向量值然后用余弦相似度公式计算得到的。Word2Vec产生的相似度值从-1到1为最高相似度值。

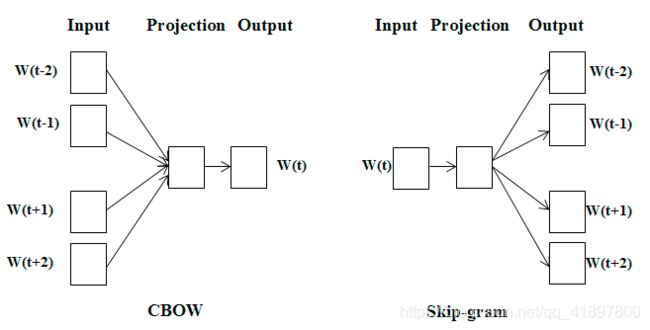
Word2Vec可以提供一个高效的实现架构Continuous Bag of Words(CBOW)和Skip-Gram来计算单词的向量表示,这些表示可以用于语言处理中的各种任务。CBOW架构根据上下文预测当前的单词,而Skip-Gram架构则预测当前给出的单词周围的单词。CBOW和Skip-Gram架构可以在图3中看到。
3.4 数据集
本研究中用于Word2Vec模型训练的数据集是在维基百科数据库中找到的32万篇XML格式的英语维基百科文章。然后做简单的预处理,删除XML标签,从32万篇文章中以大词集的形式生成一个干净的语料库。作为测试数据集的测试数据是WordSim-3532和SimLex-9993。这个测试集包含了来自人类评级的词对的相似度值,或者称为黄金标准。
WordSim-353数据集是一个由353对名词组成的数据集,同时每对名词在没有上下文的情况下呈现,并与13到16个人类对相似性和对等关系(reciprocal relationships)的判断相关联,评分范围从0到106。SimLex-999数据集包含各种具体和抽象的形容词、名词和动词对,以及独立于具体的评级和每对的关联强度(自由)。
3.5 预处理
预处理是指根据需要将非结构化数据转化为结构化数据的过程,以便进行进一步的文本挖掘处理(情感分析、摘要、文档分组等)。对语料数据集进行的预处理是标识化(tokenizing)和大小写折叠(case folding)。标识化是将句子、段落或文档形式的文本划分为一定的标记(tokens)的过程。例如,将一个句子they eat and laugh really hard进行标记化,产生六个标记,即:they、eat、and、laugh、really、hard。大小写折叠是指对文档中的大小写进行匹配的过程。这样做是为了方便搜索。并非所有的文本文档在大写字母的使用上都是一致的。因此,需要大小写折叠,其作用是将文档中的所有文本转换成标准形式(通常是小写)。例如,从COMPUTER的大小写折叠产生computer。
3.6 Word2Vec配置设置
这个Word2Vec模型是建立在大量英文维基百科语料库的训练结果上的。Python编程语言的Gensim库在本研究中具有重要作用,因为Gensim库提供了制作Word2Vec模型的所有特征。Word2Vec模型的制作是基于窗口大小和不同向量维度的配置而建立的。本研究中,窗口大小为3、6、9,矢量尺寸为50、150、300。
Word2Vec模型可以利用余弦相似度方程得到的词向量的值进行计算。余弦相似度是通过从两个n维向量之间的角度寻找余弦值来计算两个向量之间的相似度,在文本挖掘中经常用来比较文档。余弦相似度公式如下:
similarity = cos θ = x ˉ ∙ y ˉ ∥ x ˉ ∥ ∥ y ˉ ∥ (1) \text { similarity }=\cos \theta=\frac{\bar{x} \bullet \bar{y}}{\|\bar{x}\|\|\bar{y}\|} \tag{1} similarity =cosθ=∥xˉ∥∥yˉ∥xˉ∙yˉ(1)
其中:
x ˉ ∙ y ˉ \bar{x} \bullet \bar{y} xˉ∙yˉ:x和y的向量点积—— ∑ k = 1 n x k y k \sum_{k=1}^{n}x_{k} y_{k} ∑k=1nxkyk
∥ x ˉ ∥ \|\bar{x}\| ∥xˉ∥:长向量x—— ∑ k = 1 n x k 2 \sum_{k=1}^{n}x_{k} ^2 ∑k=1nxk2
∥ y ˉ ∥ \|\bar{y}\| ∥yˉ∥:长向量y—— ∑ k = 1 n y k 2 \sum_{k=1}^{n}y_{k} ^2 ∑k=1nyk2
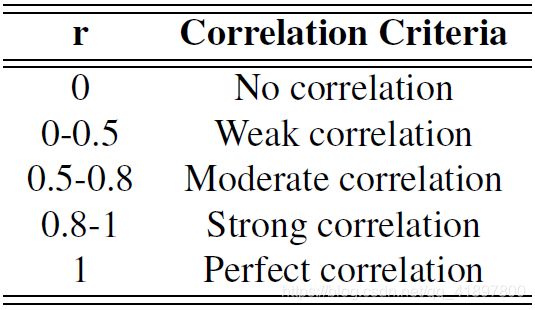
然后用Pearson相关性方程重新计算公式(1)的结果,找出系统与黄金标准(gold standard)WordSim-353和SimLex-999生成的值的准确度。Pearson相关是用来评价相似度计算结果的。Pearson相关性产生的相关值范围在0~1之间。皮尔逊相关性的计算公式见式(2),相关值的标准见表2。
corr = n ( ∑ x y ) − ( ∑ x ) ( ∑ y ) [ n ∑ x 2 − ( ∑ x ) 2 ] [ n ∑ y 2 − ( ∑ y ) 2 ] (2) \text { corr }=\frac{n\left(\sum x y\right)-\left(\sum x\right)\left(\sum y\right)}{\sqrt{\left[n \sum x^{2}-\left(\sum x\right)^{2}\right]\left[n \sum y^{2}-\left(\sum y\right)^{2}\right]}} \tag{2} corr =[n∑x2−(∑x)2][n∑y2−(∑y)2]n(∑xy)−(∑x)(∑y)(2)
其中:
n n n:词对数
x x x:系统的值
y y y:gold standard的值
4. 评价
4.1 测试
本研究的测试是通过结合窗口大小3、6、9和向量维度50、150、300来进行的,所以测试用不同的配置进行了9次。使用配置的目的是为了找到英语维基百科语料库Word2Vec模型的最佳配置。配置细节见表3。

4.2 测试结果分析
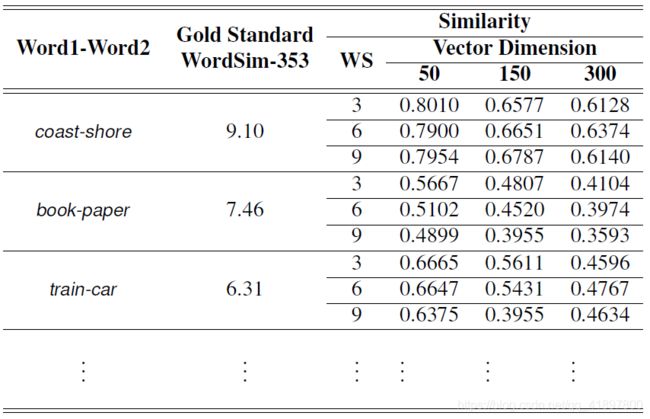
本研究的测试结果是系统生成的相似度值的皮尔逊相关分值,该分值与WordSim-353和SimLex-999的gold standard值相关。WordSim-353和SimLex-999的皮尔逊相关结果可以从表4和表5中看到。产生的相似度得分的部分结果可参见表6与表7。

从表4中可以看出,应用于Word2Vec模型的窗口大小和向量维度配置越高,皮尔逊相关值就越高。因此对于WordSim-353测试集,本研究的最佳配置是窗口大小9和向量维度300。

与表4中WordSim-353的测试集类似,在SimLex-999测试集中,Word2Vec模型的最佳配置是窗口大小为9,矢量维度为300。因此,可以得出结论,本研究中Word2Vec模型的最佳配置是窗口大小为9,矢量维度为300。
本研究还表明,窗口大小和向量维度越大,可以产生较高的相关值(correlation value),相似度值(similarity value)也会越好。但窗口大小和向量维度过大也不一定能产生好的值,因为窗口大小值越大,词的上下文越多,会导致相似度的值越弱。

5. 结论和未来的工作
根据已经进行的测试和分析的结果,可以得出以下结论:
- 根据创建的Word2Vec模型产生的相似度得分,WordSim-353的皮尔逊相关值为0.665,即为中等相关,而SimLex-999的皮尔逊相关值为0.284,即为弱相关。本研究SimLex-999数据集产生的结果与WordSim353相比,数值较差。这是因为Wordsim353数据集是一对相关或关联的数据集,因此不同的词对(不同的材料、功能等)会得到很高的相似度值,例如衣服(clothes)与衣柜(closets)并不相似,但它们之间有很大的关联。而Simlex-999数据集是捕捉相似性(similarity),而不是相关(relatedness)或关联性(association)的数据集,因此得到的相似度值较低。
- 影响Word2Vec模型相似度值的因素是根据使用的窗口大小和向量维度来判断语料库中词的出现次数。如果使用的窗口尺寸和维度向量尺寸太小,得到的词的上下文也就少。使用的窗口大小和向量维度越大,产生的词的上下文越多,对偶(the pair)出现的可能性就越大。
下一步未来研究的工作,使用大型语料库训练Word2Vec模型的过程需要很长的时间。因此,建议使用并行编程来克服这个问题。