高并发编程_高并发编程【无锁篇】

摘要:本文首先通过讲解无锁的原理,以及为何选用无锁实现原子操作,在此基础上,介绍几个无锁原子操作代表类:AtomicInteger、AtomicReference、AtomicStampedReference、AtomicIntegerArray、AtomicIntegerFieldUpdater。
1. 无锁类的原理
1.1. 概述
根据【概念理解篇】可以知道,无锁是基于无障碍的,无障碍指的是所有线程都可以同时进入临界区,但是对于临界区的修改,有且只有一个成功,是一个宽进严出的想法。但在无障碍的情况下,可能会出现线程相互干扰的问题,导致所有线程都卡死在了临界区,此时为了解决这个问题,无锁就出现了,在无障碍的基础上,再增加一条规则:每一次数据竞争都有一个优胜者,意味着线程不会无穷的相互干扰,导致所有线程都不能离开临界区。因此在理论上,无锁会更加合理,但也不是绝对的。
有研究表明,在实践中,无障碍的线程可能会出不去临界区,但是这是一个运气+概率的这么一个事件,一般情况下,运气都不会差到线程会卡死。
1.2. CAS
无锁的实现原理就是CAS,CAS是Compare And Swap的缩写,下面借助一个案例来说明CAS。
--假设在多线程环境下,需要修改临界区中的变量t。
--分析:
因为无锁是无障碍的,因此线程可以同时进入临界区,而能成功修改的线程有且只有一个,那么如何判断哪一个线程可以成功呢?CAS就给出了一个判断规则。
--CAS判断规则:
在线程进行修改变量t之前,需要给出t的期望值,如果t的期望值和实际值是相等的,那么就可以修改t的值,否则就是修改失败。
--为什么期望值和实际值不相等,就修改失败呢?
如果期望值和实际值不相等,那么数据在当前线程修改的间隙中,可能被其他线程修改过了,因为这个数据已经被修改过了,因此当前线程拿到的数据都是不正确,没有意义的,因此这次修改就没有意义,所以修改失败。
--引申问题:由于CAS经历了三个步骤:读取、比较、修改,因此CAS操作过程中,线程t1读取并比较了数据,正当修改之前,线程t2进入了临界区,把数据给修改了,那么t1还还行修改操作吗?(由于CAS操作太多,会出现线程干扰问题,那么CAS还是一个合适的技术方案吗?)
实际上,这个担心是多余的,因为CAS整个操作过程是一个原子操作,是由一条CPU指定完成的,并不是说读取、比较、修改是分别在不同的CPU指令上执行的,因此不会出现CAS操作线程干扰的问题发生。
1.3. CPU指令
在计算机上CAS操作使用【cmpxchg】指令完成的。大致逻辑如下:
/*
accumulator = AL, AX or EAX,depending on whether
a byte, word, or doubleword comparison is being performed
*/
// 判断目标值和寄存器中的值是否相等
if(accumulator == Destination) {
// 相等
ZF = 1; // 设置一个跳转标志
Destination = Source; // 修改数据
} else {
// 不相等,不设置跳转标志,不修改数据
ZF = 0;
accumulator = Destination;
}1.4. 已经有Synchronized为什么还使用CAS?
首先需要知道Synchronized是悲观锁的代表,而CAS可以理解为乐观锁。
Synchronized悲观锁认为同一时间只能有一个线程进入临界区操作数据,而其他线程都会阻塞,有研究表名:阻塞一个线程需要消耗8万个CPU时间片,而CAS则没有实际的锁概念,而使用通过Compare和Swap来实现数据的一致性的,正是没有锁,因此就不会出现线程阻塞,但是由于CAS操作中,只有一个线程可以胜出,而其他线程都会失败,并且可能会出现重试(从头执行一次代码),因此在循环体不是很复杂的情况下(仅仅只是2到3条、或者10条以内的语句),那么失败的线程需要多消耗2到3个、或者10个以内的CPU时间片来重试代码,但是相对于8万个CPU时间片来说,CAS在性能上还是有非常大的优势。
1.5. 总结
CAS算法过程:它包含3个参数CAS(V, E, N)。V表示要更新的变量,E表示预设值,N表示新值。仅当V值等于E值时,才会将V的值设为N,如果V值和E值不同,则说明已经有其他线程做了更新,则当前线程什么都不做,随后,CAS返回当前V的真实值。CAS操作是抱着乐观的态度进行的,它总是认为自己可以成功完成操作。当多个线程同时使用CAS操作同一个变量时,只有一个会胜出,并成功更新,其余均会失败。失败的线程不会被挂起,仅是操作失败,并且允许再次尝试,当然也允许失败的线程放弃操作。基于这样的原理,CAS操作即使没有锁,也可以发现其他线程对当前线程的干扰,并进行恰当的处理。
2. 无锁类的使用
在java中,提供了一些无锁类,所谓的无锁类指的是,这些锁底层实现使用了CAS,无锁类典型代表有:AtomicInteger、AtomicReference、AtomicStampedReference、AtomicIntegerArray、AtomicIntegerFiledUpdater。
2.1. AtomicInteger
public class AtomicInteger extends Number implements java.io.Serializable {
AtomicInteger继承自Number,是一个数字类,可以理解为一个Integer,但是与Integer不同的是,AtomicInteger提供的访问接口,能够保证在多线程环境下,数据的一致性,底层实现就是CAS。
--主要接口:
// 获取当前值
public final int get()
// 设置当前值
public final void set(int newValue)
// 设置新值,并返回旧值
public final int getAndSet(int newValue)
// 如果当前值为expect,则设置为update
public final boolean compareAndSet(int expect, int update)
// 当前值加1,返回旧值
public final int getAndIncrement()
// 当前值减1,返回旧值
public final int getAndDecrement()
// 当前值增加delta,返回旧值
public final int getAndAdd(int delta)
// 当前值加1,返回新值
public final int incrementAndGet()
// 当前值减1,返回新值
public final int decrementAndGet()
// 当前值增加delta,返回新值
public final int addAndGet(int delta) --AtomicInteger源码解读:
打开AtomicInteger源码之后,可以发现有一个int类型的value字段。
private volatile int value;
这个字段,存储了一个整数,并且所有的接口操作的都是这个value字段,如get、set方法:
public final int get() {
return value;
}
public final void set(int newValue) {
value = newValue;
}因此AtomicInteger无非只是一个包装类,包含了一个int类型数值,真正存储数据的是value属性。
--接下来看一个典型接口compareAndSet:
/**
* Atomically sets the value to the given updated value
* if the current value {@code ==} the expected value.
*
* @param expect the expected value
* @param update the new value
* @return {@code true} if successful. False return indicates that
* the actual value was not equal to the expected value.
*/
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}compareAndSet方法的两个参数:expect表示期望值,update表示新值,当修改成功,方法返回true,否则返回false,如果返回false则表示实际值不等于期望值,这和CAS原理是相符的。
在这个方法中使用了unsafe操作,顾名思义unsafe应该封装了一些不安全的操作,但是Java相对于C、C++安全的原因在于,Java封装了指针的操作,而在某些环境下,需要像C、C++那样通过偏移量操作指针,所以Java就提供了unsafe操作指针。如下:
unsafe.compareAndSwapInt(this, valueOffset, expect, update);
--unsafe的compareAndSwapInt方法的参数含义:
this:当前对象(AtomicInteger) valueOffset:偏移量
expect:期望值
update:新值
那么这个方法的作用就是将AtomicInteger对象在偏移量valueOffset上的实际值和期望值expect是否相等,相等就设置新值update。
--再来看一个典型接口getAndIncrement:
/**
* Atomically increments by one the current value.
*
* @return the previous value
*/
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}这个方法调用了unsafe的getAndAddInt方法:
/**
* 这个方法用于将AtomicInteger在valueOffset偏移量上的值加delta
* @param var1 AtomicInteger
* @param var2 valueOffset
* @param var4 delta
* @return
*/
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2); // 获取AtomicInteger在valueOffset偏移量上的值
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4)); // 判断在valueOffset偏移量上的值是否等于var5期望值,如果相等就修改,否则就重试,知道修改成功
return var5; // 最后返回旧值
}--getAndAddInt方法主要完成三个步骤:
[1] 获取AtomicInteger在var2偏移量上的值,作为期望值var5。
[2] 取出获取AtomicInteger在var2偏移量上的值,判断与期望值var5是否相等,相等就修改AtomicInteger在var2偏移量上的值(这里是递增var4)不相等就转[1]。
[3] 返回AtomicInteger在var2偏移量上的 旧值。
步骤[1]和[2]是一个死循环,在CAS中称为自旋,因此CAS也成为自旋锁。
通过这个方法,可以很好的解释了CAS的工作原理:比较(Compare)与交换(Swap)。通过不断的比较,来完成交换。
--案例:
--启动10个线程,每个线程将变量i累加1万,如果AtomicInteger是线程安全的话,那么最后i的值为10万。
public class AtomicIntegerDemo {
static AtomicInteger i = new AtomicInteger();
public static class AddThread implements Runnable {
@Override
public void run() {
for (int j = 0; j < 10000; j++) {
i.incrementAndGet();
}
}
}
public static void main(String[] args) throws InterruptedException {
Thread[] tx = new Thread[10];
for (int j = 0; j < 10; j++) {
tx[j] = new Thread(new AddThread());
}
for (int j = 0; j < 10; j++) {
tx[j].start();
}
for (int j = 0; j < 10; j++) {
tx[j].join();
}
System.out.println(i);
}
}
由打印结果,可以知道,AtomicInteger是线程安全的。
2.2. Unsafe
Unsafe中提供了一些非安全的操作,譬如:
[1] 根据偏移量设置值。
[2] park,停止线程。
[3] 底层CAS操作。
由于Unsafe是非安全的,所以Unsafe是非公开API(不希望开发者使用),只在JDK内部使用,并且在不同版本的JDK中,可能有较大差异。
--偏移量valueOffset
Unsafe提供的根据偏移量设置值,可能对于接触过C的人来说,非常好理解,因为C中是通过指针操作对象的,操作性能最高,但是其存在非常大的安全隐患,如:误操作了一些系统级别的对象,导致系统崩溃。面对这个问题,Java使用引用替代指针,引用底层无非就是封装了指针,从而使得开发者无需过多的关注底层指针操作,因此对于java程序员,可能不太清楚什么叫偏移量,那么接下来就来说明一下偏移量。
--假设在C++中有一个结构体(struct),结构体有两个int类型的字段a、b,如下:
Struct {
int a;
int b;
}我们知道一切对象或者程序代码都会对应在内存中的一块位置,并且计算机提供了指针来访问内存,在C++中直接使用指针操作内存,那么当我们知道了一个结构体的地址之后,可以通过字段类型所占的内存大小计算出计算字段的实际物理地址,譬如:当结构体的地址为0X0001(相当于1)时,根据一个int类型占4个字节,可以计算出字段a的地址为0X00101(相当于5 = 1 + 4),字段b的地址为0X1001(相当于9 = 1 + 8)。其中的4和8就是偏移量。
由于java封装了指针,因此java对象一般会包含一些对象头信息,会占用一些内存地址。,但是通过偏移量计算出属性的地址的过程是相同的。如下图:

因此unsafe中使用偏移量访问对象的属性时,那么unsafe是如何知道属性的偏移量的呢?由于偏移量已经作为一个参数传递给了unsafe的方法,因此想要找到计算偏移量的代码,需要在调用unsafe方法的类中找,这里在AtomicInteger中找到了偏移量属性valueOffset:
private static final long valueOffset;
并且在AtomicInteger类加载的时候,就已经就已经计算好了value属性的偏移量,如下:
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) {
throw new Error(ex); }
}计算属性偏移量使用了unsafe的objectFieldOffset方法:
public native long objectFieldOffset(Field var1);
由于java是没有指针的,因此涉及指针操作的objectFieldOffset方法交给了其他语言来实现。
通过static代码块,结合偏移量的计算过程,AtomicInteger中的偏移量应该就是value的类型所占的比特+对象头信息所占的比特(大于4)。
由于unsafe是非公开的API,因此获取Unsafe没有提供对外的构造方法,但是提供了一个静态属性unsafe来获取Unsafe对象:
public final class Unsafe {
private static final Unsafe theUnsafe;
// ...
private Unsafe() {
}
@CallerSensitive
public static Unsafe getUnsafe() {
Class var0 = Reflection.getCallerClass();
if (!VM.isSystemDomainLoader(var0.getClassLoader())) {
throw new SecurityException("Unsafe");
} else {
return theUnsafe;
}
}
}--通过反射获取Unsafe:
public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException {
Field unsafeField = Unsafe.class.getDeclaredField("theUnsafe");
unsafeField.setAccessible(true);
Unsafe unsafe = (Unsafe) unsafeField.get(null);
System.out.println(unsafe);
}--主要接口:
// 获得给定对象偏移量上的int值
public native int getInt(Object var1, long var2);
// 设置给定对象偏移量上的int值
public native void putInt(Object var1, long var2, int var4);
// 获得字段在对象中的偏移量
public native long objectFieldOffset(Field var1);
// 使用volatile语义,设置给定对象偏移量上的int值
// 其他线程能够立即知道修改后的值
public native void putIntVolatile(Object var1, long var2, int var4);
// 使用volatile语义,获取给定对象偏移量上的int值
public native int getIntVolatile(Object var1, long var2);
// 和putIntVolatile一样,但是它要求被操作字段就是volatile类型的
public native void putOrderedInt(Object var1, long var2, int var4);其他类似的还有AtomicBoolean、AtomicLong。
2.3. AtomicReference
AtomicInteger解决了线程安全的访问一个整数,而AtomicReference则是能否线程安全的修改一个对象的引用。
AtomicReference使用了泛型,使得可以对任意类型的对象实现线程安全的操作:
public class AtomicReferenceimplements java.io.Serializable {
与AtomicInteger类似的,它也将对象作为一个属性存在:
private volatile V value;
也有Unsafe、valueOffset属性:
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicReference.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
--主要接口:
// 获取当前对象
public final V get()
// 设置新对象newValue
public final void set(V newValue)
// 如果当前对象为expect,则设置为update
public final boolean compareAndSet(V expect, V update)
// 设置新对象newValue,并返回旧对象
public final V getAndSet(V newValue)--案例:
启动10个线程,如果AtomicReference的值为“abc”,那么就修改为“def”,因此如果AtomicReference是线程安全的话,那么无论执行多少次,都只有一个线程修改成功,其余都失败告终。
public class AtomicReferenceDemo {
// 声明一个线程安全的对象
private final static AtomicReference atomicStr = new AtomicReference("abc");
public static void main(String[] args) {
// 启动10个线程
for (int i = 0; i < 10; i++) {
new Thread(){
@Override
public void run() {
try {
// 线程随机休眠,为的是实现随机线程先访问atomicStr
Thread.sleep(Math.abs((int)(Math.random() * 100)));
} catch (InterruptedException e) {
e.printStackTrace();
}
// 使用compareAndSet方法,修改"abc"为"def"
if(atomicStr.compareAndSet("abc", "def")) {
System.out.println("Thread:" + Thread.currentThread().getId() + " Change value successful");
} else {
System.out.println("Thread:" + Thread.currentThread().getId() + " FAILED");
}
}
}.start();
}
}
}

2.4. AtomicStampedReference
AtomicStampedReference比AtomicReference多了一个Stamped,stamp的意思是戳、印记的意思,也就是一个有唯一性标识的字段,代入编程中就是时间戳的意思。比如说从数字0一直递增上去,没有重复、唯一的。
--试想一个问题:假设有一个引用R,其指向对象A,此时有一个线程t1执行了compareAndSet方法,读取了引用R的值,此时t1的CPU时间片到了,轮到了线程t2执行,t2修改了引用R的值,使其指向了对象B,此时t2的CPU时间片也到了,轮到了线程t3执行,t3也修改了引用R的值,使其重新指向了对象A,此时t3的CPU时间片到了,重新轮到t1线程执行,此时t1将读取出来的R的值和当前内存中的R的实际值进行比对,发现相等,那么应不应该修改R的值呢?
--如下图:
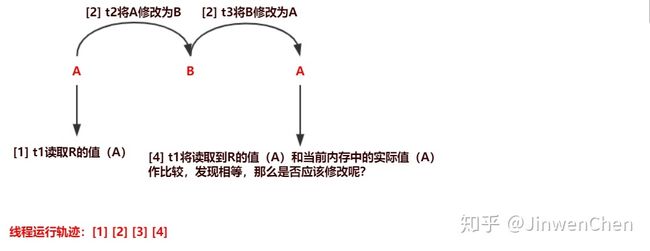
--应该,那么是因为读取到的R值和实际的R值相等,应该修改R的值。
--不应该,那么因为在比较R值之前,引用R出现了状态的改变,认为,当前线程读取到的R值,不是最新的数据,是被修改过的,因此不应该修改R的值。
如果引用的只是一个数值,那么数值进行了加减操作,即发生的改变与过程无关的,可以认为应该修改。但是如果发生的改变与过程是相关的,比如给低于20块钱的用于充值20块钱话费,此时就认为不能修改了。因此为了解决与状态过程有关系的修改问题,提出了AtomicStampedReference。在原始的AtomicReference上给数据增加一个唯一标识,一旦引用发生了改变,那么就修改其唯一标识,对引用进行了唯一标识,不再仅仅判断最终的引用是否相等。
--案例:
--给话费低于20块钱的用户充值20块钱(注意:这里需要关注状态过程变量,需要使用AtomicStampedReference)。
public class AtomicStampedReferenceDemo {
// 这里由于需要模拟只充值一次,特意的将初始余额修改为19,并且先启动充值线程
static AtomicStampedReference money = new AtomicStampedReference(19, 0);
public static void main(String[] args) {
// 获取原始的Stamp,只能充值一次
final int timeStamp = money.getStamp();
for (int i = 0; i < 3; i++) {
// 启动充值线程
new Thread() {
@Override
public void run() {
while (true) {
while (true) {
// 获取余额
Integer m = money.getReference();
// 当余额小于20的时候,充值20元
if (m < 20) {
if (money.compareAndSet(m, m + 20, timeStamp, timeStamp + 1)) {
System.out.println("余额小于20元,充值成功,余额:" + money.getReference() + "元");
break;
}
} else {
break;
}
}
}
}
}.start();
// 启动消费线程
new Thread() {
@Override
public void run() {
for (int j = 0; j < 100; j++) {
while(true) {
// 获取当前余额的唯一标识
int timeStamp = money.getStamp();
// 获取余额
Integer m = money.getReference();
// 当余额大于10,就消费10元
if(m > 10) {
System.out.println("大于10元");
// 没消费一次,唯一标识就+1
if(money.compareAndSet(m, m - 10, timeStamp, timeStamp + 1)) {
System.out.println("成功消费10元,余额:" + money.getReference());
break;
}
} else {
System.out.println("没有足够的金额");
break;
}
}
}
}
}.start();
}
}
}
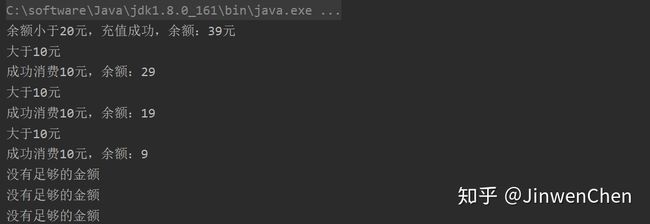
从打印结果来看,只有第一次低于19块钱才充值20元,随后就算再次低于19元都不充值。因此当我们需要关注引用的状态变化过程,那么就可以使用AtomicStampedReference来做数据安全访问。
--底层实现:
由于AtomicStampedReference中对引用增加了一个唯一标识,因此使用了一个内部类Pair来封装引用和唯一标识:
public class AtomicStampedReference {
private static class Pair {
final T reference;
final int stamp;
private Pair(T reference, int stamp) {
this.reference = reference;
this.stamp = stamp;
}
static Pair of(T reference, int stamp) {
return new Pair(reference, stamp);
}
}
// ...
} 以前使用value来存储引用,现在对value进行了一层封装,变成了Pair:
private volatile Pairpair;
那么getReference和getStamp方法,当然就是获取Pair上的reference和stamp:
public V getReference() {
return pair.reference;
}
public int getStamp() {
return pair.stamp;
}接下来看下compareAndSet方法:
public boolean compareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp) {
Pair current = pair;
return
expectedReference == current.reference &&
expectedStamp == current.stamp &&
((newReference == current.reference &&
newStamp == current.stamp) ||
casPair(current, Pair.of(newReference, newStamp)));
} 根据源码可以知道,对Pair的reference和stamp进行修改有三种情况:
[1] 当reference的期望值和实际值相等,并且stamp期望值和实际值也相等。
expectedReference == current.reference && expectedStamp == current.stamp[2] 当reference的新值和实际值相等,并且stamp的新值也和实际值相等。
newReference == current.reference && newStamp == current.stamp[3] Pair的CAS操作执行成功。
casPair(current, Pair.of(newReference, newStamp))期望值和实际值相等,那么修改是固然的,而新值和实际值相等,也修改的想法也是可以,相当于没有修改,数据也是正确的。而对于第三种情况,则是比对当前线程拿到了的Pair和内存中的实际值是否相等,相等的话就修改。
--casPair的源码:
private static final sun.misc.Unsafe UNSAFE = sun.misc.Unsafe.getUnsafe();
private static final long pairOffset =
objectFieldOffset(UNSAFE, "pair", AtomicStampedReference.class);
private boolean casPair(Pair cmp, Pair val) {
return UNSAFE.compareAndSwapObject(this, pairOffset, cmp, val);
} 可以发现,Pair的CAS操作和AtomicInteger的CAS操作是基本一致的,都是借助Unsafe工具类来通过偏移量直接操作属性值。
--主要接口:
// 获取Pair的reference
public V getReference()
// 获取Pair的stamp
public int getStamp()
// 通过CAS修改Pair的reference和stamp
public boolean compareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp)2.5. AtomicIntegerArray
相应的,对于整型数组的CAS操作,java提供了AtomicIntegerArray支持,如下:
public class AtomicIntegerArray implements java.io.Serializable {
类似的,AtomicIntegerArray无非就是对于IntegerArray进行了一层封装:
private final int[] array;
--主要接口:
// 获取数组第i个下标的元素
public final int get(int i)
// 获取数组的长度
public final int length()
// 将数组第i个下标设置为newValue,并返回旧值
public final int getAndSet(int i, int newValue)
// 将数组第i个下标的元素加1,并返回旧值
public final int getAndIncrement(int i)
// 将数组第i个下标的元素减1,并返回旧值
public final int getAndDecrement(int i)
// 将数组第i个下标的元素加1,并返回新值
public final int incrementAndGet(int i)
// 将数组第i个下标的元素减1,并返回新值
public final int decrementAndGet(int i)
// 将数组第i个下标的元素加delta,并返回旧值(delta可以是负数)
public final int getAndAdd(int i, int delta)
// 将数组第i个下标的元素加delta,并返回新值(delta可以是负数)
public final int addAndGet(int i, int delta)
// 通过CAS修改数组第i个下标的元素
public final boolean compareAndSet(int i, int expect, int update)常用的接口记忆技巧:记住4个组合关键字get、increment、decrement、add,一个逻辑关键字add,其中方法的组成必须有get,剩下的increment、decrement、add和get进行搭配,如果get在前,那么就返回旧值,在后,就返回新值,比如:getAddIncrement(int i),就表示返回旧值,并将下标为i的元素加1。其他以此类推,最后还有记住一个万变不变的方法:compareAndSet,表示使用CAS操作修改数据,是最直观的CAS操作。这个技巧可以应用到所有的Atomic类中。
--案例:
public class AtomicIntegerArrayDemo {
// 准备一个AtomicIntegerArray数组,长度为10
static AtomicIntegerArray arr = new AtomicIntegerArray(10);
// 准备一个任务(对数组中每个元素,递增1000)
public static class AddThread implements Runnable {
@Override
public void run() {
int len = arr.length();
for (int i = 0; i < 10000; i++) {
arr.getAndIncrement(i % len);
}
}
}
public static void main(String[] args) throws InterruptedException {
// 准备10个AddThread线程
Thread[] ts = new Thread[10];
for (int i = 0; i < 10; i++) {
ts[i] = new Thread(new AddThread());
}
// 启动10个线程
for (int i = 0; i < 10; i++) {
ts[i].start();
}
// 在主线程中并入这10个线程
for (int i = 0; i < 10; i++) {
ts[i].join();
}
// 打印数组中的元素
System.out.println(arr);
}
}

从数组的打印结果来看,每个元素都是10000,意味着AtomicIntegerArray确实维护了一个线程安全的IntegerArray。
--底层实现:
以get方法为例:
public final int get(int i) {
return getRaw(checkedByteOffset(i));
}通过checkedByteOffset方法找到第i个元素的偏移量,而getRow方法通过偏移量找到对应的元素值。
沿着偏移量的执行调用链,可以发现,计算偏移量的底层方法是byteOffset,如下:
private long checkedByteOffset(int i) {
if (i < 0 || i >= array.length)
throw new IndexOutOfBoundsException("index " + i);
return byteOffset(i);
}
private static long byteOffset(int i) {
return ((long) i << shift) + base;
}其中的bese值为IntegerArray的基地值(第一个元素相对数组所在地址的相对地址,可以理解为一个元素的偏移量):
private static final int base = unsafe.arrayBaseOffset(int[].class);
shift是偏移倍数:
private static final int shift;
static {
int scale = unsafe.arrayIndexScale(int[].class);
if ((scale & (scale - 1)) != 0)
throw new Error("data type scale not a power of two");
shift = 31 - Integer.numberOfLeadingZeros(scale);
}首先借助unsafe的arrayIndexSacle计算整型数组的每一个元素大小,就是4。接下来是判断sacle的奇偶性(通过按位与运算),由于基本数据类型所占的内存都是2的倍数,因此如果出现scale为奇数时,会抛出一个错误。最后借助Integer包装类上的numberOfLeadingZeros方法来计算scale的前导零个数。
--前导零计算
前导零指的就是将一个数转换为二进制后,从第一位开始计数0的个数,直到第一个不为0的数值。如一个int类型的4,二进制为:100。由于int类型占32bit,因此需要填充29个0,因此int类型的4的前导0个数就是29。
numberOfLeadingZeros方法由于传入的就是4,刚好前导零的个数为29,所以方法返回值为29,这里使用31去减29得到2,所以shift值就是2。
接着在byteOffset方法中,通过了位运算来计算偏移量。
(long) i << shift
当想要知道第6个元素的偏移量时,即i=6,那么i << shift的运算结果就是24,刚好是6个int类型数据的大小(4*6=24),最后在加上IntegerArray的基地值,不就是第6个元素的偏移量了吗?
--问题:为什么使用位运算计算呢,为何不直接使用java乘法计算呢?
这是出于性能的考虑,一个算法的实现,越接近C,那么效率就越高,而位运算就是一个接近C的计算。
--偏移量的计算过程图:

计算前导零为了获得参与位运算的左移位数。
接下来继续看getRow方法:
private int getRaw(long offset) {
return unsafe.getIntVolatile(array, offset);
}既然已经得到了偏移量,那么根据IntegerArray的地址,可以轻易的得到给定偏移量上的元素。
与AtomicIntegerArray类似的还有AtomicLongArray、AtomicReferenceArray。
2.6. AtomicIntegerFiledUpdater
AtomicIntegerFieldUpdater主要是让普通的变量都能享受CAS操作。
假设有一个变量,一开始没有声明为Atomic类型,但是在后续的代码编写中,发展这个变量需要被多个线程共享,而处于性能的考虑,不希望使用Synchronized,因此AtomicXXXFieldUpdater就显得格外有用了。但是使用AtomicXXXFieldUpdater的前提是属性是volitale修饰的。
--案例:
public class AtomicIntegerFieldUpdaterDemo {
// 假设有一个Candidate类,类中有volitale修饰的score属性
public static class Candidate {
int id;
volatile int score;
}
// 针对Candidate的score属性声明一个AtomicIntegerFieldUpdater类
public static AtomicIntegerFieldUpdater scoreUpdater = AtomicIntegerFieldUpdater.newUpdater(Candidate.class, "score");
// 这个AtomicInteger主要是用于验证AtomicIntegerFieldUpdater是否是线程安全
// 如果线程安全,那么score的值等于allScore
public static AtomicInteger allScore = new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException {
// 声明一个Candidate
Candidate c = new Candidate();
// 准备1000个线程
Thread[] ts = new Thread[1000];
for (int i = 0; i < 1000; i++) {
ts[i] = new Thread(){
// 当随机数大于0.5,就将score值累加1,allScore的累加值仅仅只是用于验证AtomicIntegerFieldUpdater的线程安全
@Override
public void run() {
if(Math.random() > 0.5) {
scoreUpdater.getAndIncrement(c);
allScore.getAndIncrement();
}
}
};
}
// 启动线程
for (int i = 0; i < 1000; i++) {
ts[i].start();
}
// 将线程并入main线程执行
for (int i = 0; i < 1000; i++) {
ts[i].join();
}
// 打印累加结果,如果相等,那么AtomicIntegerFieldUpdater确实可以将一个int类型的变量实现线程安全
System.out.println("score: " + scoreUpdater.get(c));
System.out.println("allScore: " + allScore.get());
}
}

可以发现,无论执行多少次,score和allScore的值都是相等的,因此AtomicIntegerFieldUpdater确实可以将一个普通变量实现CAS操作。
AtomicIntegerFieldUpdater可以通过修改尽量少的代码来实现原子操作,这是该类最主要的作用。
类似的还有AtomicLongFieldUpdater、AtomicReferenceFieldUpdater。