吴恩达机器学习作业4:Neural Networks Learning python实现
一、总结:
在实现中注意到的问题:
1. 在教程PDF中,第二层神经元的误差数学表示: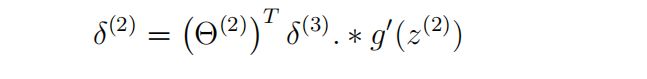
Theta2 转置后结构:(26 * 10)
delta3 的结构:(10 * 5000)
两者做矩阵乘法后:(26 *5000)
Z2 的结构:(25 * 5000)
可以看见,这两者是结构上不一样是做不了点乘运算的,在实现中应该给Z2加上一行然后运算后删去。
2. 结果向量 y 的表示规则
在每个example的结果向量 y 中,数字 0 标记为 10, 在 a3 中,也即是预测向量 hx 中,如果第一个元素的概率最大,那么预测的结果应该为数字1,而不是数字0,第十个元素的概率最大时才预测为数字0。
二、python实现
1.数据初始化
import numpy as np
import scipy.io as scio
import scipy.optimize as opt
from gradient_nn import gradinet_nn
from computeCost_nn import computecost_nn
from randInitializeWeights import randinitializeweights
from checkGradient import checkgradient
from predict import prediction
#加载数据
path = r'ex4data1.mat'
data1 = scio.loadmat(path)
x = data1['X']
y = data1['y']
path = r'ex4weights.mat'
data2 = scio.loadmat(path)
Theta1 = data2['Theta1']
Theta2 = data2['Theta2']
#给x加一列1
m = x.shape[0]
one = np.ones([m, 1])
x = np.hstack([one, x])
2.代价函数
注意传入的 theta 是一个一维的数组,在传入后在进行reshape,这十分重要。(否则没有办法使用自动寻找最小值的函数 : minimize()进行传参)
import numpy as np
from sigmod import sigmod
def computecost_nn(theta, x, y, mylambda,
num_input, num_hidden, num_output):
theta1 = theta[0:(num_hidden* (num_input + 1))].reshape(num_hidden, num_input + 1)
theta2 = theta[(num_hidden* (num_input + 1)):].reshape(num_output, num_hidden + 1)
#第二层神经元
z2 = np.dot(theta1, x.T)
a2 = sigmod(z2)
m = a2.shape[1]
one = np.ones([1, m])
a2 = np.vstack([one, a2])
#第三层神经元
z3 = np.dot(theta2, a2)
hx = sigmod(z3)
#创建y(i)矩阵
n, m = hx.shape
y = y - 1
y_mat = np.zeros([m, n])
y_mat[np.arange(m), y.flatten()] = 1 #按位置矩阵对 y_mat:5000 * 10 初始化
y_mat = y_mat.T
cost1 = -np.sum(np.multiply(np.log(hx), y_mat) + np.multiply(1-y_mat, np.log(1 - hx)))/m
cost2 = mylambda/(2*m)*(np.sum(np.power(theta1[:, 1:], 2)) + np.sum(np.power(theta2[:, 1:], 2)))
cost = cost1 + cost2
return cost
3 .梯度下降
注意返回值依旧是一个一维的数组,用flatten()函数处理
import numpy as np
from sigmod import sigmod
from sigmodGradient import sigmodgradient
def gradinet_nn(theta, x, y, mylambda, num_input, num_hidden, num_output):
Theta1 = theta[0:(num_hidden * (num_input + 1))].reshape(num_hidden, num_input + 1)
Theta2 = theta[(num_hidden * (num_input + 1)):].reshape(num_output, num_hidden + 1)
#第二层神经元
z2 = np.dot(Theta1, x.T)
a2 = sigmod(z2)
m = a2.shape[1]
one = np.ones([1, m])
a2 = np.vstack([one, a2])
#第三层神经元
z3 = np.dot(Theta2, a2)
a3 = sigmod(z3)
hx = a3
#对y矩阵初始化
n, m = hx.shape
y = y - 1
y_mat = np.zeros([m, n])
y_mat[np.arange(m), y.flatten()] = 1 # 按位置矩阵对 y_mat:5000 * 10 初始化
y_mat = y_mat.T
#第三层、第二层的误差向量
delta3 = hx - y_mat
one = np.ones([1, z2.shape[1]])
z2_temp = np.vstack([one, z2])
delta2 = np.multiply(np.dot(Theta2.T, delta3), (sigmodgradient(z2_temp)))
delta2 = delta2[1:, :]
m = x.shape[0]
#求两个权重矩阵的梯度下降(已正则化)
Delta2 = delta3.dot(a2.T) / m
Delta2[:, 1:] = Delta2[:, 1:] * mylambda
Delta1 = delta2.dot(x)/m
Delta1[:, 1:] = Delta1[:, 1:] * mylambda
#得到的两个梯度下降矩阵展开
m, n = Delta1.shape
Delta1 = Delta1.reshape([1, m * n])
m, n = Delta2.shape
Delta2 = Delta2.reshape([1, m * n])
#合成一个一维的矩阵返回
Delta = np.hstack([Delta1, Delta2])
return Delta.flatten()
4 . 微分(数值)方法计算梯度
import numpy as np
from computeCost_nn import computecost_nn
def computenumerialgradint(theta, x, y, mylambda,
num_input, num_hidden, num_output):
m = np.size(theta)
change = np.zeros([1, m])
gradNum = np.zeros([1, m])
e = np.exp(-4)
for i in range(m):
change[0, i] = e
theta1 = (theta + change).flatten()
theta2 = (theta - change).flatten()
J1 = computecost_nn(theta1, x, y, mylambda, num_input, num_hidden, num_output)
J2 = computecost_nn(theta2, x, y, mylambda, num_input, num_hidden, num_output)
gradNum[0, i] = (J1 - J2) / (2 * e)
change[0, i] = 0
return gradNum.flatten()
5. 梯度下降算法正确性验证
import numpy as np
from gradient_nn import gradinet_nn
from computeNumerialGradint import computenumerialgradint
from debugGradient import debuggradient
def checkgradient():
#初始化数据集
input_layer_size = 3
hidden_layer_size = 5
num_labels = 3
m = 5
Theta1 = debuggradient(input_layer_size, hidden_layer_size)
Theta2 = debuggradient(hidden_layer_size, num_labels )
x = debuggradient(input_layer_size - 1, m )
one = np.ones([x.shape[0], 1])
x = np.hstack([one, x])
y = 1 + (1+np.arange(m)) % num_labels
#初始化梯度下降矩阵的展开
m, n = Theta1.shape
Theta1 = Theta1.reshape([1, m*n])
m, n = Theta2.shape
Theta2 = Theta2.reshape([1, m * n])
debug_theta = np.hstack([Theta1, Theta2])
debug_theta = debug_theta.flatten()
mylambda = 0.1
#利用反向传播求梯度下降、利用微分求梯度下降
grad_alg = gradinet_nn(debug_theta, x, y, input_layer_size, hidden_layer_size, num_labels, mylambda)
grad_num = computenumerialgradint(debug_theta, x, y, 0, input_layer_size, hidden_layer_size, num_labels)
print(grad_alg[0:5])
print(grad_num[0:5])
结果只打印了前五个梯度值:

可以看到结果基本相等,证明梯度下降的算法的正确性。
6 反向传播计算最佳Theta
数据的准备和初始化:
#正则化的参数
mylambda = 0.1
#得到的两个初始化的权重矩阵展开
m, n = initial_Theta1.shape
initial_Theta1 = initial_Theta1.reshape([1, m * n])
m, n = initial_Theta2.shape
initial_Theta2 = initial_Theta2.reshape([1, m * n])
#合成一个一维的矩阵
initial_Theta = np.hstack([initial_Theta1, initial_Theta2])
#使用优化函数求出最小化代价函数的Theta1,Theta2
result = opt.minimize(fun=computecost_nn, x0=initial_Theta,
args=(x, y, mylambda, num_input, num_hidden, num_output), method='TNC', jac=gradinet_nn)
opt_theta = result.x
corr = prediction(opt_theta, x, y, num_input, num_hidden, num_output)
print(corr)
预测函数:
import numpy as np
from sigmod import sigmod
def prediction(theta, x, y, num_input, num_hidden, num_output):
theta1 = theta[0:(num_hidden * (num_input + 1))].reshape(num_hidden, num_input + 1)
theta2 = theta[(num_hidden * (num_input + 1)):].reshape(num_output, num_hidden + 1)
# 第二层神经元
z2 = np.dot(theta1, x.T)
a2 = sigmod(z2)
m = a2.shape[1]
one = np.ones([1, m])
a2 = np.vstack([one, a2])
# 第三层神经元
z3 = np.dot(theta2, a2)
hx = sigmod(z3)
# 创建y(i)矩阵
n, m = hx.shape
y = y - 1
y_mat = np.zeros([m, n])
y_mat[np.arange(m), y.flatten()] = 1 # 按位置矩阵对 y_mat:5000 * 10 初始化
hx = hx.T
pred = np.zeros(m)
for i in range(m):
pred[i] = 0
flag = -1
for j in range(n):
if hx[i, j] > flag:
pred[i] = j
flag = hx[i, j]
pred = np.array(pred).reshape([m, 1])
temp = np.where(y == pred, 1, 0)
corret = np.mean(temp)
return corret
预测结果:
(无正则化)
![]()
(正则化)
![]()
可以看见,结果貌似还不错。
然而发现一点问题:
RuntimeWarning: divide by zero encountered in log
cost1 = -np.sum(np.multiply(np.log(hx), y_mat) + np.multiply(1-y_mat, np.log(1 - hx)))/m
RuntimeWarning: invalid value encountered in multiply
cost1 = -np.sum(np.multiply(np.log(hx), y_mat) + np.multiply(1-y_mat, np.log(1 - hx)))/m
log 函数除了0?
点乘过程中出现无效值?
随机初始化对结果的影响蛮大的!
估计是优化函数使用的问题,以后有机会再看看怎么实现的和解决方法吧。
