MapReduce环形缓冲区MapOutputBuffer,kvBuffer分析
MapReduce环形缓冲区MapOutputBuffer,kvBuffer分析
环形缓冲区相关类和属性说明
MapTask$MapOutputBuffer
默认的环形缓冲区类,可以通过job配置文件的参数mapreduce.job.map.output.collector.class进行设置。
sorter
默认的排序类,可以通过job配置文件参数map.sort.class进行设置,此类必须是IndexedSorter类的子类。
combinerRunner
combiner操作类,可以通过job配置文件参数mapreduce.job.combine.class设置,默认为null,此类必须是Reducer类的子类。
minSpillsForCombine
当mapper阶段已经没有待处理的key,value数据时,环形缓冲区进行flush操作,将缓冲区数据全部写入spill.out文件,然后对所有spill.out文件进行mergeParts,其中当spill.out文件数量不小于minSpillsForCombine(默认是3)时,进行combiner。可以通过参数min.num.spills.for.combine设置大小。
CompressionCodec
对mapoutput数据进行压缩,每次溢写时,如果需要压缩,会将溢写数据进行压缩然后写入文件系统,最后生成该次的spill.out文件。
kvbuffer
用于保存mapoutput数据的meta信息(16B),key,value值得字节数组,默认大小是100M,可以通过参数mapreduce.task.io.sort.mb设置环形缓冲区的大小(单位MB)。
kvmeta
将kvbuffer包装成一个int数组,根据运行得Jvm确定使用大端还是小端模式(Hotspot为小端模式)。
kvindex,bufindex
分别对应下一个meta数据,和keyvalue数据将被存放的位置。
kvstart,kvend,bufstart,bufend,bufmark
bufmark用于记录当前插入key的开始位置,记录插入完成后bufmark=bufindex;bufstart是kvbuffer存放key,value数据部分的开始位置,bufend通常等于bufstart,在溢写时等于bufindex的当前值,kvstart和kvend用于管理meta数据,类似bufstart和bufend。
bufferRemaining,softlimit
作为判断是否发生溢写的条件,初始时bufferRemaining=soflimit=kvbuffer.length*溢写占比(默认0.8)。以后每插入一条记录,bufferRemaining-记录size。
运行分析
环形缓冲区初始化
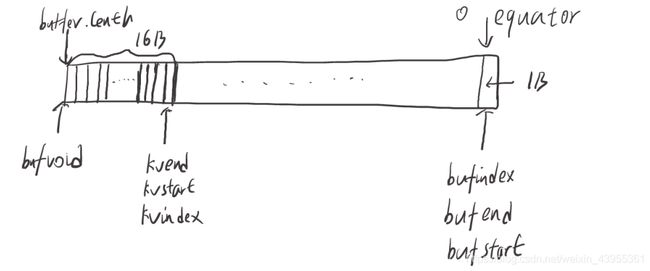
通过调用MapTask$MapOutputBuffer#init()方法进行初始化:
- 设置溢写占比,当使用内存超过一个阈值时就进行溢写,默认为0.8。
- 设置kvbuffer大小,默认为100M。
- 通过反射获取sorter对象。
- 创建kvbuffer,设置equator和其他参数值。
- bufstart = bufend = bufindex = equator=0;bufvoid = kvbuffer.length;kvstart = kvend = kvindex=bufvoid-METASIZE(16)。
- 完成之后如上图
环形缓冲区写入数据
当执行mapper#map()方法调用context.write(key,value)时,最终会调用MapTask$MapOutputBuffer#collect(key,value,partition)方法将key,value和meta数据写入上述的kvbuffer。在写入meta时一致是从大地址到小地址,写入key,value是从小地址到大地址,到达边界时取模运算。
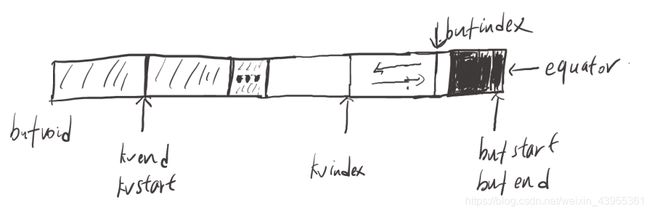
写入一条记录时,首先判断是否满足溢写条件;如果不满足:
- 将key序列化存放在bufindex所指向的位置,如果key值被分割在kvbuffer两端;则需要调整key位置,使得key连续。执行后bufindex指向下一个空位置,详细见下文。
- 将value序列化存放在bufindex指向的位置,并更新bufindex指向下一个空位置;bufindex一直在增加。
- 存放meta数据,meta数据占kvbuffer16个字节;用于存放该记录的keystart,valuestart,partition,valuelength信息。将meta数据按valuestart,keystart,partition,valuelength顺序存放。
- 存放完成后kvindex-16;bufstart,bufend,kvstart和kvend不变。
调整key位置,使其在kvbuffer中连续
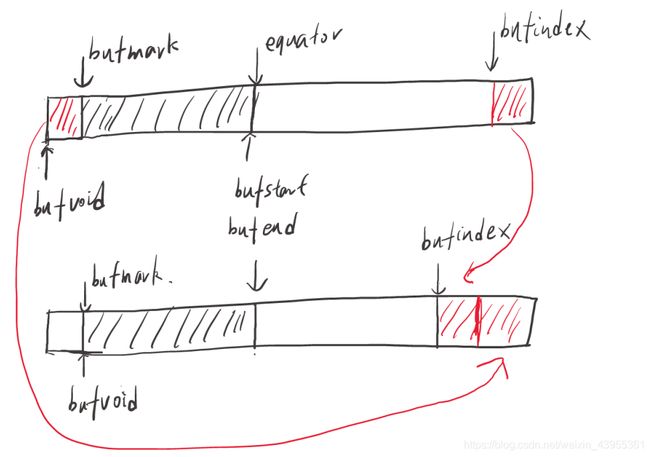
调用MapTask$MapOutputBuffer$BlockingBuffer#shiftBufferedKey()方法调整key位置;调整后bufvoid会变小,等于整个环形缓冲区损失了一部分内存。
溢写
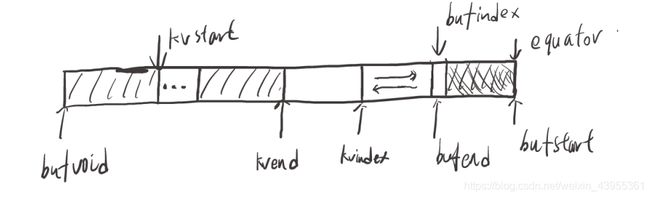
图1
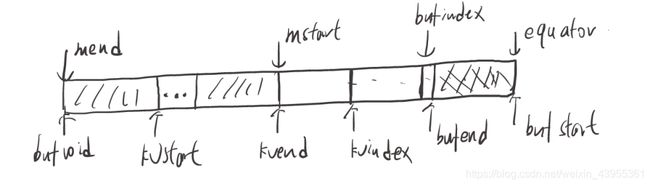
图2
在MapTask$MapOutputBuffer#collect(key,value,partition)方法往缓冲区存放数据时,判断到达了溢写条件(bufferRemaining-METASIZE <= 0)并且(已使用缓冲区字节数>= softLimit),则进行溢写。
-
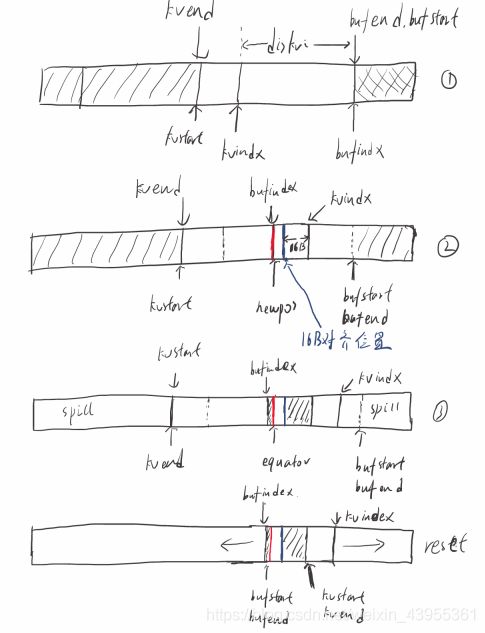
调用MapTask$MapOutputBuffer#startSpill()方法开始溢写,修改kvend指向当前kvindex-4的位置,bufend指向bufmark位置;上图1。
-
通过spillReady.signal()通知spillThread运行,执行spillThread#run()方法。
-
run()方法中首先会调用MapTask$MapOutputCollector#sortAndSpill(),真正的执行溢写,并且进行排序。
-
sortAndSpill()首先会创建2个遍量mend,mstart分别表示meta信息在kvbuffer中的结束和开始位置,如图2。
-
通过当前的numSpills创建一个溢写文件,溢写文件保存在文件系统jobCache中。
-
调用排序算法,传入mend和mstart值,对kvbuffer的meta数据进行排序,默认使用快排;比较i记录和j记录大小时,首先比较记录的partition值,其次比较key值;排序结束后,按partition和key递增顺序调整meta位置。
-
遍历分区号,然后遍历排序后的kvbuffer的meta信息,判断当前meta的partition信息是否等于该分区号,相等就向文件写出信息。
-
写出信息时,如果value不连续,被存储在bvbuffer两端,则会读取2部分值,合并成value。
-
sortAndspill()结束后,修改kvstart=kvend,bufstart=bufend。
-
溢写结束后需要调整equator和kvindex,bufindex值,放入这次发生溢写的数据;首先计算distkvi(未使用的缓冲区大小),avgRec(平均每一条记录的key,value数据所占的字节数),然后使用公式计算newPos(新的equator位置),下图过程(1)。
newPos = (bufindex +Math.max(2 * METASIZE - 1,Math.min(distkvi / 2,distkvi / (METASIZE + avgRec) * METASIZE)))
-
更具newPos值更新equator和kvindex,bufindex;更新时,bufindex=newPos,但是kvindex需要16B对齐;使用新的kvindex,bufindex存放本次引起溢写的数据,下图过程(2),(3)。
-
当下一次往kvbuffer写入数据时,判断上一次是否spill过且spill完成,是则调用resetSpill()方法修改kvstart,kvend,bufstart,bufend,如下图过程reset。接下来使用新的位置继续写入数据。
代码
MapTask$MapOutputBuffer#init()
//partitions为reduce任务的数量
partitions = job.getNumReduceTasks();
//溢写占比
//可以通过参数mapreduce.map.sort.spill.percent设置触发溢写占比;默认是0.8
final float spillper =
job.getFloat(JobContext.MAP_SORT_SPILL_PERCENT/*mapreduce.map.sort.spill.percent*/, (float)0.8);
//环形缓冲区大小
//可以通过参数mapreduce.task.io.sort.mb设置环形缓冲区的大小单位MB;默认100MB
final int sortmb = job.getInt(JobContext.IO_SORT_MB/*mapreduce.task.io.sort.mb*/, 100);
//缓冲区最大0x7ffMB
if ((sortmb & 0x7FF) != sortmb) {
throw new IOException(
"Invalid \"" + JobContext.IO_SORT_MB + "\": " + sortmb);
}
//获取排序的对象;默认为快排
//可以通过参数map.sort.class修改;排序对象必须时IndexeSorter的子类
sorter = ReflectionUtils.newInstance(job.getClass("map.sort.class",
QuickSort.class, IndexedSorter.class), job);
//将sortmb转成以B为单位的数
int maxMemUsage = sortmb << 20;
//将maxMemUsage转成能整除METASIZE的数;
//METASIZE是每条记录的元数据的大小;为16B
maxMemUsage -= maxMemUsage % METASIZE;
//真正的环形缓冲区
kvbuffer = new byte[maxMemUsage];
bufvoid = kvbuffer.length;
//将上述的环形缓冲区包装成一个IntBuffer
kvmeta = ByteBuffer.wrap(kvbuffer)
.order(ByteOrder.nativeOrder())//根据JVM,判断使用大端模式还是小端模式
.asIntBuffer();
setEquator(0);
//初始时为0;单位时B
bufstart = bufend = bufindex = equator;
//初始时为(maxMemUsage-16)/4(小端模式);单位是4B(java中的int型)
kvstart = kvend = kvindex;
//缓冲区使用>softLimit时排序;排序阈值
softLimit = (int)(kvbuffer.length * spillper);
//还可以写入缓冲区的字节数;单位B
bufferRemaining = softLimit;
//获取比较器,对MapOutPutkey对象进行比较
comparator = job.getOutputKeyComparator();
//工厂模式:获取序列化对象工厂
serializationFactory = new SerializationFactory(job);
//获取处理MapOutputKey的序列化对象
keySerializer = serializationFactory.getSerializer(keyClass);
//打开输出流关联bb
//bb是一个阻塞buffer
keySerializer.open(bb);
//同上
valSerializer = serializationFactory.getSerializer(valClass);
valSerializer.open(bb);
//获取对mapper输出的压缩对象
//可以通过参数mapreduce.map.output.compress.codec指定
//压缩对象必须是CompressionCodec.class的子类
if (job.getCompressMapOutput()) {
Class<? extends CompressionCodec> codecClass =
job.getMapOutputCompressorClass(DefaultCodec.class);
codec = ReflectionUtils.newInstance(codecClass, job);
} else {
codec = null;
}
//获取combinerRunner对象
//可以通过mapred.combiner.class设置,默认是null,必须是Reducer的子类
//mapreduce.job.combine.class
//return getClass("mapred.combiner.class", null, Reducer.class);
combinerRunner = CombinerRunner.create(job, getTaskID(),
combineInputCounter,
reporter, null);
//设置多次溢写进行一次合并,默认为3
//可以通过参数mapreduce.map.combine.minspills配置
minSpillsForCombine = job.getInt(JobContext.MAP_COMBINE_MIN_SPILLS, 3);
//设置一个守护线程用于溢写
spillThread.setDaemon(true);
spillThread.setName("SpillThread");
//可重入锁加锁
spillLock.lock();
try {
spillThread.start();//开始执行溢写守护线程
while (!spillThreadRunning) {
spillDone.await();
}
} catch (InterruptedException e) {
throw new IOException("Spill thread failed to initialize", e);
} finally {
spillLock.unlock();
}
Maptask$MapOutputBuffer#collect()插入记录
//缓冲区剩余可放入空间减去16B
//16B是元数据大小
bufferRemaining -= METASIZE;
//如果剩余空间小于等于0;开始溢写
if (bufferRemaining <= 0) {
/*........*/
}
//key插入当前缓冲区的位置
int keystart = bufindex;
//最终调用MapTask$MapOutputBuffer$Buffer#write()方法
keySerializer.serialize(key);
//重新放置key
if (bufindex < keystart) {
// wrapped the key; must make contiguous
bb.shiftBufferedKey();
keystart = 0;
}
//value插入当前缓冲区的位置
final int valstart = bufindex;
//value序列话后对比key少了if判断语句,是因为存储一个value所需的空间不需要保证连续
valSerializer.serialize(value);
// It's possible for records to have zero length, i.e. the serializer
// will perform no writes. To ensure that the boundary conditions are
// checked and that the kvindex invariant is maintained, perform a
// zero-length write into the buffer. The logic monitoring this could be
// moved into collect, but this is cleaner and inexpensive. For now, it
// is acceptable.
bb.write(b0, 0, 0);
// the record must be marked after the preceding write, as the metadata
// for this record are not yet written
/*public int markRecord() {
bufmark = bufindex;
return bufindex;
}*/
int valend = bb.markRecord();
// write accounting info
//往循环缓冲区写入元数据信息
//kvindex为当前元数据的起始位置
//如下,元数据按valStart,keyStart,parition,vallen排列
kvmeta.put(kvindex + PARTITION/*2*/, partition);//写入分区位置信息
kvmeta.put(kvindex + KEYSTART/*1*/, keystart);//写入key的开始位置
kvmeta.put(kvindex + VALSTART/*0*/, valstart);//写入value的开始位置
kvmeta.put(kvindex + VALLEN/*3*/, distanceTo(valstart, valend));//写入value的长度
//跟新kvindex值,减去4B
kvindex = (kvindex - NMETA/*4*/ + kvmeta.capacity()) % kvmeta.capacity();
MapTask$Mapoutput#collect()溢写
spillLock.lock();
try {
do {
//确认溢写线程没有运行
if (!spillInProgress) {
final int kvbidx = 4 * kvindex;//将kvindex(单位4B)转成Kvbinx(B),下同
final int kvbend = 4 * kvend;
// serialized, unspilled bytes always lie between kvindex and
// bufindex, crossing the equator. Note that any void space
// created by a reset must be included in "used" bytes
final int bUsed = distanceTo(kvbidx, bufindex);//bUsed表示已用的缓冲区大小
final boolean bufsoftlimit = bUsed >= softLimit;
//如果满足下述条件,则之前发生过一次溢写
if ((kvbend + METASIZE) % kvbuffer.length !=
equator - (equator % METASIZE)) {
// spill finished, reclaim space
//需要修改重新修改kvstart和kvend的值
resetSpill();
bufferRemaining = Math.min(
distanceTo(bufindex, kvbidx) - 2 * METASIZE,
softLimit - bUsed) - METASIZE;
continue;
} else if (
//确认超过了溢写阈值且缓冲区不为空
bufsoftlimit && kvindex != kvend) {
// spill records, if any collected; check latter, as it may
// be possible for metadata alignment to hit spill pcnt
startSpill();//执行溢写
//计算平均每一个记录的key和value需要占据的字节数,用于确定新的equator值
final int avgRec = (int)
(mapOutputByteCounter.getCounter() /
mapOutputRecordCounter.getCounter());
// leave at least half the split buffer for serialization data
// ensure that kvindex >= bufindex
//计算出未使用的字节数
final int distkvi = distanceTo(bufindex, kvbidx);
//计算出equator的新值
final int newPos = (bufindex +
Math.max(2 * METASIZE - 1,
Math.min(distkvi / 2,
distkvi / (METASIZE + avgRec) * METASIZE)))
% kvbuffer.length;
//更新equator值,并且重新分配当前元数据存放的位置
setEquator(newPos);
bufmark = bufindex = newPos;
final int serBound = 4 * kvend;
// bytes remaining before the lock must be held and limits
// checked is the minimum of three arcs: the metadata space, the
// serialization space, and the soft limit
bufferRemaining = Math.min(
// metadata max
distanceTo(bufend, newPos),
Math.min(
// serialization max
distanceTo(newPos, serBound),
// soft limit
softLimit)) - 2 * METASIZE;
}
}
} while (false);
} finally {
spillLock.unlock();
}
MapTask M a p O u t p u t B u f f e r MapOutputBuffer MapOutputBufferBlockingBuffer.shiftBufferedKey()
// spillLock unnecessary; both kvend and kvindex are current
int headbytelen = bufvoid - bufmark;
bufvoid = bufmark;
final int kvbidx = 4 * kvindex;
final int kvbend = 4 * kvend;
//计算可用内存
final int avail =
Math.min(distanceTo(0, kvbidx), distanceTo(0, kvbend));
//如果可用内存可以满足key的重新放置
if (bufindex + headbytelen < avail) {
//调整key的位置
System.arraycopy(kvbuffer, 0, kvbuffer, headbytelen, bufindex);
System.arraycopy(kvbuffer, bufvoid, kvbuffer, 0, headbytelen);
bufindex += headbytelen;
bufferRemaining -= kvbuffer.length - bufvoid;
} else {
byte[] keytmp = new byte[bufindex];
System.arraycopy(kvbuffer, 0, keytmp, 0, bufindex);
bufindex = 0;
out.write(kvbuffer, bufmark, headbytelen);
out.write(keytmp);
}
}
}
SpillThread#run()
sortAndSpill();//溢写并排序
if (bufend < bufstart) {
//重新设置bufvoid,因为在调整key时缩小了bufvoid的值。
bufvoid = kvbuffer.length;
}
kvstart = kvend;//将kvstart设置到和kvend一样
bufstart = bufend;//将bufstart设置到和bufend一样
MapTask$MapOutputBuffer#startSpill()
kvend = (kvindex + NMETA) % kvmeta.capacity();//kvend指向最后一个元数据的位置
bufend = bufmark;//bufend指向最后一个output据的位置
spillInProgress = true;//设置溢写线程执行标志
spillReady.signal();//通知信号量
MapTask$MapOutputBuffer#resetSpill()
final int e = equator;//获取当前赤道位置
bufstart = bufend = e;//将新的接受mapoutput数据时缓冲区的开始和结束设置为赤道位置
final int aligned = e - (e % METASIZE);//将aligned设置为(小于赤道位置且可以整除16的最大数);因为元数据是从大到小放置
// set start/end to point to first meta record
// Cast one of the operands to long to avoid integer overflow
//kvstart和kvend新的位置是aligned的将要存入元数据的第一个位置
kvstart = kvend = (int)
(((long)aligned - METASIZE + kvbuffer.length) % kvbuffer.length) / 4;
MapTask$MapOutputCollector#sortAndSpill()
//approximate the length of the output file to be the length of the
//buffer + header lengths for the partitions
final long size = distanceTo(bufstart, bufend, bufvoid) +
partitions * APPROX_HEADER_LENGTH/*private final static int APPROX_HEADER_LENGTH = 150;*/;
/*
public SpillRecord(int numPartitions) {
buf = ByteBuffer.allocate(
numPartitions * MapTask.MAP_OUTPUT_INDEX_RECORD_LENGTH/*24*/);
// entries = buf.asLongBuffer();
// }
*/
//返回一个字节数组,数组大小为(分区数*24B),并将其包装为long数组
final SpillRecord spillRec = new SpillRecord(partitions);
//创建一个当前溢写文件,如:
//......\jobcache\job_local54553846_0001\attempt_local54553846_0001_m_000000_0\output\spill0.out
final Path filename =
mapOutputFile.getSpillFileForWrite(numSpills/*当前溢写号*/, size/*大小*/);
//创建该文件和该文件的输出流
out = rfs.create(filename);
//mstart元数据溢写开始位置(单位16B)
final int mstart = kvend / NMETA/*4*/;
//mend元数据溢写结束位置(单位16B)
final int mend = 1 + // kvend is a valid record
(kvstart >= kvend
? kvstart
: kvmeta.capacity() + kvstart) / NMETA;
//调整元数据位置;默认是快排
sorter.sort(MapOutputBuffer.this, mstart, mend, reporter);
//遍历分区号,写入相应的分区
for (int i = 0; i < partitions; ++i) {
//如果没有combinerRunner
if (combinerRunner == null) {
// 直接溢写
DataInputBuffer key = new DataInputBuffer();
while (
//只有还要元数据并且该元数据保存的partition信息是当前遍历的分区号,就溢写
spindex < mend &&kvmeta.get(offsetFor(spindex % maxRec) + PARTITION) == i) {
final int kvoff = offsetFor(spindex % maxRec);//当前元数据所在位置
int keystart = kvmeta.get(kvoff + KEYSTART);//output数据key在kvbuffer的开始位置
int valstart = kvmeta.get(kvoff + VALSTART);//output数据value在kvbuffer的开始位置
//key对象和value对象用来保存输出的key和value的数据,内部是一个buffer来保存。
//key对象中的buffer直接使用的是kvbuffer
//value对象中的buffer(1.当value没有跨过bufvold时,直接使用kvbuffer
// 2.如果1不满足,新建一个buffer,然后从kvbuffer中获取value值)
//为输出流对象key设置key数据的位置信息
key.reset(kvbuffer, keystart, valstart - keystart);
//为输出流对象value设置value数据的位置信息
//当的起始位置跨过bufvoid时,获取俩两部分的value值,保存到一个value对象buffer中
getVBytesForOffset(kvoff, value);
//写出
writer.append(key, value);
++spindex;
}
} else {
int spstart = spindex;
while (spindex < mend &&
kvmeta.get(offsetFor(spindex % maxRec)
+ PARTITION) == i) {
++spindex;
}
// Note: we would like to avoid the combiner if we've fewer
// than some threshold of records for a partition
if (spstart != spindex) {
combineCollector.setWriter(writer);
RawKeyValueIterator kvIter =
new MRResultIterator(spstart, spindex);
combinerRunner.combine(kvIter, combineCollector);
}
}
// close the writer
writer.close();
// record offsets
rec.startOffset = segmentStart;
rec.rawLength = writer.getRawLength() + CryptoUtils.cryptoPadding(job);
rec.partLength = writer.getCompressedLength() + CryptoUtils.cryptoPadding(job);
spillRec.putIndex(rec, i);
writer = null;
} finally {
if (null != writer) writer.close();
}
}
主要参数和注意点总结
- 配置参数mapreduce.map.sort.spill.percent:溢写占比(默认0.8)。
- 配置参数mapreduce.task.io.sort.mb:kvbuffer大小(默认100M),单位MB。
- 缓冲区最大0x7ffMB,即2047MB。
- 配置参数map.sort.class:溢写时采用的排序对象,默认是QuickSort。
- 写记录(meta,key,value)时,写入meta是(大地址->小地址),而写入key,value是(小地址->大地址);每次写入一条记录,kvindex-16,bufindex+(key,value实际序列化后所需的空间大小);到达kvbuffer边界时进行%运算。
- value存在key后面(此处时逻辑上的后面,涉及value部分值越过边界放在kvbuffer另一端)。
- key需要连续存放(在排序中需要对key进行比较需要连续存放),当key值被分开到kvbuffer俩端时,会对key进行一次重新放置,调整后bufvoid会减小。
- value值可以不连续存放。
- meta数据占kvbuffer16个字节;用于存放该记录的keystart,valuestart,partition,valuelength信息;将meta数据按valuestart,keystart,partition,valuelength顺序存放。
- 溢写条件:(bufferRemaining-METASIZE <= 0)并且(已使用缓冲区字节数>= softLimit)
- 比较两个meta大小时,首先比较记录的partition值,其次比较key值。
- 在排序时,首先根据partition和key的值对meta进行排序,使得缓冲区中的meta按partition和key递增排序。
- 在溢写时会重新调整bufvoid的值等于kvbuffer.length。
- 每次溢写会创建一个写出文件,写出文件命名按序号增加。
- 溢写结束后会调整equator,bufindex,kvindex的值,用于存放本次数据,当下一次放入数据时,调整kvstart,kvend,bufstart,bufend的值。
- 在softAndspill()溢写过程中如果有combiner,会执行combiner,如果还有codec压缩器,则继续执行codec将output数据写出到spill.out文件中。