DEFT: Detection Embeddings for Tracking 论文学习
Abstract
目前大多数的多目标跟踪系统都是通过检测再跟踪的方式实现,一个目标检测器后面跟着一个关联检测结果的方法。将运动和外观特征结合起来实现跟踪,已经有了很长的历史,对遮挡严重的问题也具有一定的鲁棒性,但是通常所需的算力很高,实现起来比较慢。最近在 2D 目标追踪基准上所取得的成绩表明,通过一个 SOTA 检测器和相对简单、仅依赖单帧空间位置的关联方法,我们可以取得很高的分数,显著地超过那些通过外观特征学习来重新识别已丢失目标的方法。本文中,作者提出了一个高效率的协同检测和追踪的方法,叫做 DEFT,或者“用于跟踪的检测 embeddings”。本方法需要一个基于外观的目标匹配网络,通过目标检测网络来协同学习。此外也增加了一个 LSTM 来获取运动信息。DEFT 在 2D 在线跟踪任务上,表现与现有的最优方法相当,但面对更具挑战性的数据时,其鲁棒性要更高。在 nuScenes 单目 3D 追踪比赛上,DEFT 表现极佳,甚至领先之前最佳的方法的表现整整一倍。代码位于https://github.com/MedChaabane/DEFT。
1. Introduction
视觉多目标跟踪在过去几年取得了显著的突破,高性能运动机器人和自动驾驶应用都推动了其发展。基于 CNN 的目标检测器在准确率和效率方面都不断地在提升,推动了先检测再跟踪的方式。最近的工作表明,为 SOTA 目标检测器增加一个简单的跟踪机制可以超越之前的更复杂的架构。
先检测再跟踪的方法主要有两步:1) 单个视频帧的目标检测,2) 将当前帧检测到的目标与之前帧的目标关联起来。关联不同帧之间的检测结果有许多办法,但是特征学习关系是很有意思的,因为它们能运行在边缘设备上,而模型和基于启发式的方法则不行。即便有了学习关系,双阶段的方法也不会输出准确率和效率都最优的结果。最近在单个神经网络内,协同学习检测和跟踪的方法提高了跟踪基准和应用的表现。但是,现有的端到端方法都很复杂、速度慢,它们将目标外观和运动信息结合。
作者认为,目标匹配模块可以加入到 CNN 目标检测器中,产生一个表现极佳的多目标跟踪器,此外,协同训练检测和跟踪(关联)模块,这两个模块可以互相适应,运行地更好。和那些将检测结果作为黑盒子输入关联模块的方法相比,本文方法使用和目标检测一样的主干网络,以及帧间关联方法,可以提高效率和准确率。
本文中的方法,从检测器网络的多尺度主干网络中提取每个目标的 embeddings,在目标-跟踪关联子网络中作为外观特征使用。作者称之为“用于跟踪的检测 embeddings”(DEFT)。作者证明,DEFT 可以有效地应用到多个目标检测网络上。由于网络结构的特征共享,本文方法使用了外观信息和运动信息来跟踪目标,这样其速度就与目前使用简单关联策略的方法接近。因为 DEFT 一直会保留外观 embeddings 的内存存储,对于遮挡问题和大幅度的跨帧错位就很鲁棒。DEFT 在极具挑战性的 nuScenes 3D 单目视觉跟踪基准上遥遥领先其它方法。
2. Related Work
通过检测来跟踪。大多数的 SOTA 跟踪器都延续了“先检测再跟踪”的办法,严重依赖检测器的性能。这类跟踪器经常将检测器作为黑盒子模块使用,只关注如何将不同帧之间的检测结果关联起来。在深度学习以前,跟踪器一般都用卡尔曼滤波、IOU 或 flow fields 来关联。这些方法简单而快速,但是在复杂场景就不行了。最近,随着深度学习的兴起,许多模型都开始用外观特征来关联目标。DeepSort 对于给定的检测结果,使用一个线下训练的深度重识别模型和卡尔曼滤波运动模型来匹配检测结果。SiameseCNN 使用一个 Siamese 网络来直接学习两个检测结果的相似度。Deep Affinity Network 使用一个 Siamese 网络,将2个视频帧作为输入,提取多尺度外观 embeddings,输出所有检测结果对之间的相似度得分。Mahmoudi 等人使用提取出的视觉特征,和动态及位置特征,来进行目标关联。在[1]中,作者将 CNN 的输出和形状、运动模型结合起来。这些方法的缺点就是,特征提取器太消耗时间了,将检测和关联分开处理,导致准确率和速度都不是最佳的。DEFT 中,关联是在一个统一的网络内,与检测结果协同地学习得到的。用于匹配的特征提取复用了检测主干网络,因此目标关联只增加了一点点额外的延迟。
协同检测和追踪。最近CNN多任务学习的成功,促使人们去研究协同检测和跟踪任务的模型。Tracktor 改进了 Faster RCNN,从上一帧中估计新一帧中边框的位置。Tracktor 的缺点就是,它只在高帧率的视频做效果好,帧间变化比较少。[15]中,作者扩展了 R-FCN 检测器,计算连续帧高层级特征图的关联图,从而估计出边框之间的跨帧偏移量。CenterTrack 扩展了 CenterNet 检测器,估计帧间边框的偏移。CenterTrack 是 SOTA 方法,但只关联连续帧中的目标。本文方法对于遮挡情况、大幅度跨帧错位情况更加鲁棒,因此提升检测效果。Xu等人[44] 提出了一个端到端的MOT训练框架,在损失函数中使用了一个MOT度量可微的近似。它们对现有的深度MOT方法都有改进。Chaabane 等人提出了一个协同优化检测和跟踪的方法,关注于静态目标跟踪和定位。该模型依赖于学到的姿态估计特征,不太适合动态目标的通用跟踪器。JDE 用一个重识别分支扩展了 YOLOv3,提取关联目标的 embeddings。特征提取器和检测分支共享特征,协同训练。FairMOT 改进了 JDE,利用 CenterNet 检测器来提升跟踪准确率。
DEFT 与 JDE 和 FairMOT 方法类似。这些方法都是在一个网络内协同地学习检测和特征匹配,作为多目标跟踪的基础。DEFT 证明,协同地学习检测和匹配特征可以提供一个简单而高效的跟踪方案。DEFT 克服了其它方法的缺陷,如CenterTrack,面对那些具有挑战度的例子时,它可以提供一个更长的跟踪记忆,相似得分会被聚合起来,通过一个简单的LSTM运动模型来过滤掉不太合理的匹配。
DEFT 网络
基于先检测再跟踪的模式,作者提出要利用目标检测器(“检测器主干网络”)的中间特征图的表示能力,将提取出的 embeddings 用于目标匹配子网络中,将不同帧之间的目标联系起来。作者协同地训练了检测器和目标匹配网络。在训练过程中,目标匹配的损失会传递回检测主干网络,这样就可优化目标的外观特征,用于检测和匹配。DEFT 也用了一个低维度的 LSTM 模块,为目标匹配网络提供几何约束。DEFT 通过 CenterNet 主干网络实现,在多个跟踪基准上实现了 SOTA 表现,而且要比基于相似度得分的方法快许多。DEFT 速度快,是因为目标关联仅在检测网络上添加了一个小模块,只增加了一些微秒级的延迟。
在推理过程中(图1),embedding 提取器将检测器的边框和特征图作为输入,为每个检测目标提取外观 embeddings。匹配head使用该 embeddings 来计算当前帧和之前帧目标间的相似度。运动预测模块(LSTM)则防止出现不合理的轨迹。然后用匈牙利算法做最终的在线目标关联。每个模块的细节信息在后面会有介绍,然后是训练过程的介绍。
3.1 目标 Embeddings

图1. DEFT 的训练和推理。DEFT 在目标检测主干网络之上,添加了一个 embedding 提取器和匹配 head,协同训练外观特征用于检测和关联任务。在推理时,匹配 head 将当前的检测结果与记忆中的所有运动追踪 embeddings 相匹配,使用一个运动预测模块来去除不合理的轨迹。
匹配网络中的目标 embeddings 是从检测主干网络中提取的。在图1中,它被记做“embedding extractor”。该 embedding 提取器从检测器主干网络的中间特征图上,构建具有代表性的 embeddings,从而将跟踪目标关联(重识别)起来。我们使用不同层的特征图来提取外观信息,它们来自于不同的感受野,可以提供更多的鲁棒性。DEFT 将一个视频帧 t t t作为输入,通过检测 head,输出一组边框 B t = { b 1 t , b 2 t , . . . , b N t t } B_t = \{b_1^t, b_2^t, ...,b_{N_t}^t\} Bt={ b1t,b2t,...,bNtt}。为了简便,作者用 N t = ∣ B t ∣ N_t=|B_t| Nt=∣Bt∣来表示帧 t t t中的边框个数。
对于每个检测到的目标,我们从预测的 2D 目标中心位置提取特征 embeddings。对于 3D 边框,我们用 3D 中心位置在图像空间中的映射作为其预测的 2D 中心位置。如果第 i i i个目标的中心位置在大小是 W × H W\times H W×H的输入画面上是 ( x , y ) (x,y) (x,y),然后对于一个大小是 W m × H m × C m W_m\times H_m\times C_m Wm×Hm×Cm的特征图,我们在 ( y H H m , x W W m ) (\frac{y}{H}H_m, \frac{x}{W}W_m) (HyHm,WxWm)处提取 C m C_m Cm维的向量,作为特征图 m m m中第 i i i个目标的特征向量 f i m f_i^m fim。我们将 M M M个特征图上的特征 concat 起来,构建第 i i i个目标的 e e e 维特征 embeddings, f i = f i 1 ⋅ f i 2 ⋅ . . . ⋅ f i M f_i=f_i^1 \cdot f_i^2 \cdot ... \cdot f_i^M fi=fi1⋅fi2⋅...⋅fiM。
特征向量 f i m f_i^m fim的维度会影响它对最终特征 embedding 的贡献度。为了改变一些特征图的贡献度,而且为了控制 embedding 的维度数,在提取特征向量之前,作者给一些特征图添加了一个卷积层来增加/降低其维度,从 C m C_m Cm变为 C m ′ C_m' Cm′。它目的是增加早期特征图的特征维度,而降低后期特征图的维度。在补充材料中给出了更多的细节。
3.2 Matching Head
Matching head 延续了 Deep Affinity Network 的思路,使用目标 embeddings 来估计两帧中所有检测结果之间的相似度得分。用 N m a x N_{max} Nmax表示画面中目标的最大个数,我们构建张量 E t , t − n ∈ R N m a x × N m a x × 2 e E_{t,t-n} \in \mathbb{R}^{N_{max}\times N_{max}\times 2e} Et,t−n∈RNmax×Nmax×2e,这样在帧 t t t中的每个目标的特征 embedding 都会沿着深度维度,与 t − n t-n t−n帧中每个目标的特征 embedding concat 起来。为了构建固定大小的张量 E t , t − n E_{t,t-n} Et,t−n,我们将张量的其余部分填充为0。将 E t , t − n E_{t,t-n} Et,t−n输入进匹配 head,它由4-6个 1 × 1 1\times 1 1×1卷积层构成。Matching head 的输出是一个 affinity 矩阵 A t , t − n ∈ R N m a x × N m a x A_{t,t-n} \in \mathbb{R}^{N_{max}\times N_{max}} At,t−n∈RNmax×Nmax。
因为我们学习 embeddings 之间的相似度,就无法保证向前匹配或向后匹配时结果分数是对称的,即 ( t → t − n ) (t\rightarrow t-n) (t→t−n)或 ( t − n → t ) (t-n\rightarrow t) (t−n→t)。所以,作者就使用一个单独的 affinity 矩阵来计算两个方向上的 affinities,用下标表示为"bwd"和"fwd"。
对于那些不应该关联起来的目标(新出现的目标,或消失的目标),作者给 A t , t − n A_{t, t-n} At,t−n增加了全是常数 c c c的一列。作者对每行使用 softmax,得到矩阵 A ^ b w d \hat A^{bwd} A^bwd,表示最终的 affinity,包含不匹配的得分。 c c c的值并不敏感,因为网络通过学习会给正确的配对高于 c c c的 affinities。
每个 A ^ b w d [ i , j ] \hat A^{bwd}[i,j] A^bwd[i,j]表示关联 b i t b_i^t bit和 b j t − n b_j^{t-n} bjt−n的概率估计。 A ^ b w d [ i , N m a x + 1 ] \hat A^{bwd}[i, N_{max}+1] A^bwd[i,Nmax+1]表示 b i t b_i^t bit目标没有出现在 t − n t-n t−n帧中的概率。类似地,我们构建了一个前向 affinity 矩阵,对转置矩阵 A t , t − n T A_{t,t-n}^T At,t−nT增加了全为常数 c c c的一列,然后对每行使用 softmax,得到矩阵 A ^ f w d \hat A^{fwd} A^fwd。在推理时, b i t b_i^t bit和 b j t − n b_j^{t-n} bjt−n的相似度得分是 A ^ b w d [ i , j ] \hat A^{bwd}[i,j] A^bwd[i,j]和 A ^ f w d [ i , j ] \hat A^{fwd}[i,j] A^fwd[i,j]的平均值。
3.3 在线数据关联
在 DEFT 中,轨迹会记住过去 δ \delta δ帧中每个观测的目标 embeddings。对一个新的检测结果和现有的轨迹做关联,需要计算新目标与记忆中观测集合的相似度。对于遮挡和丢失检测问题,轨迹记忆会被保留几秒钟,这样当出现了一个新的观测,与之前的某个观测强关联,其轨迹就能被激活。在 N a g e N_{age} Nage帧后,如果没有新的观测出现,该轨迹就会从记忆中去除。
作者定义轨迹 T T T为一组从 t − δ t-\delta t−δ帧到 t − 1 t-1 t−1帧的关联检测的集合,注意该轨迹在某些帧中可能没有检测出现。轨迹大小给定为 ∣ T ∣ |T| ∣T∣,代表边框和关联 embeddings 的个数。将第 i i i个新检测和轨迹 T j T_j Tj的距离定义为:
d ( b i t , T j ) = 1 ∣ T j ∣ ∑ b k t − n ∈ T j A ^ t , t − n f w d [ k , i ] + A ^ t , t − n b w d [ i , k ] 2 d(b_i^t, T_j) = \frac{1}{|T_j|} \sum_{b_k^{t-n} \in T_j} \frac{\hat A_{t,t-n}^{fwd}[k,i] + \hat A_{t, t-n}^{bwd}[i,k]}{2} d(bit,Tj)=∣Tj∣1bkt−n∈Tj∑2A^t,t−nfwd[k,i]+A^t,t−nbwd[i,k]
Detections-to-tracks 的关联问题可以表述为一个二分匹配问题,这样就可保证一一对应。以 K = { T j } K=\{T_j\} K={ Tj} 表示当前轨迹的集合。作者构建了detections-to-tracks 的相似度矩阵 D ∈ R ∣ K ∣ × ( N t + ∣ K ∣ ) D\in \mathbb{R}^{|K|\times (N_t + |K|)} D∈R∣K∣×(Nt+∣K∣),将所有对之间的detections-to-tracks距离(等式1)添加入其中,其大小是 ∣ K ∣ × N t |K|\times N_t ∣K∣×Nt,以及一个大小是 ∣ K ∣ × ∣ K ∣ |K|\times |K| ∣K∣×∣K∣的矩阵 X X X用于表示某轨迹和当前帧中的检测没有关联。 X X X的对角线上的元素是轨迹中没有配对的检测的平均得分,其它元素则都设为 − ∞ -\infty −∞。 D D D构建过程如下:
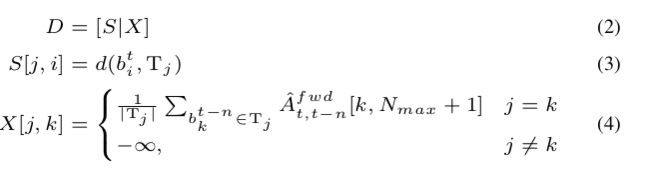
最后,作者通过匈牙利算法来解决D定义的二分匹配问题。如果 affinity 大于某阈值 γ 1 \gamma_1 γ1,则将该关联包含进去。未配对的检测则会开启新的轨迹。如果某轨迹超过 N a g e N_{age} Nage时间没有被关联,则认为其已离开画面,我们就从轨迹集合中将之删除。
3.4 运动预测
当模型用检测网络提供的外观特征来将不同帧的检测结果关联起来时,两个目标在 embedding 空间可能看上去比较相似,造成困惑。常见的操作是,增加额外的几何或时域约束条件,帮助解决该困惑。通常人们会用卡尔曼滤波或 LSTM 模块。DEFT 使用了一个 LSTM 作为运动预测模块。给定 Δ T p a s t \Delta T_{past} ΔTpast 之前帧的信息,该模块可以预测每个轨迹在后续 Δ T p r e d \Delta T_{pred} ΔTpred 帧的位置。运动预测可以约束不同帧的合理关联。如果某检测距离轨迹的预测位置太远了,运动预测模块会将等式1中的 affinity 得分设为 − ∞ -\infty −∞。在补充材料中给出了更多关于 LSTM 的细节信息。在4.5节,作者提供了消融实验,证明 LSTM 运动预测模块的作用,并证明它要比卡尔曼滤波更管用。
3.5 训练
在训练时,两帧会被输入进DEFT,如图1所示。通过一个随机的帧数 1 ≤ n ≤ n g a p 1\leq n\leq n_{gap} 1≤n≤ngap来分开选择图像对,这样可以让网络学习对于时域遮挡或目标丢失问题更加鲁棒。
对于每对训练图像,作者创建了两个 ground-truth 匹配矩阵 M f w d M^{fwd} Mfwd和 M b w d M^{bwd} Mbwd,表示前向和后向关联。该 ground-truth 匹配矩阵由 [ i , j ] ∈ { 0 , 1 } [i,j]\in \{0,1\} [i,j]∈{ 0,1}组成,维度是 N m a x × ( N m a x + 1 ) N_{max}\times (N_{max}+1) Nmax×(Nmax+1),允许出现未关联的目标。矩阵中,1表示关联,也用于表示还未关联的目标。其余位置都是0。
为了训练 DEFT,作者使用损失函数 L m a t c h \mathcal{L}_{match} Lmatch,定义为2个损失 L m a t c h f w d \mathcal{L}_{match}^{fwd} Lmatchfwd和 L m a t c h b w d \mathcal{L}_{match}^{bwd} Lmatchbwd的平均值,其中 L m a t c h b w d \mathcal{L}_{match}^{bwd} Lmatchbwd是帧 t t t与帧 t − n t-n t−n之间匹配边框的损失, L m a t c h f w d \mathcal{L}_{match}^{fwd} Lmatchfwd表示帧 t − n t-n t−n与帧 t t t之间匹配边框的损失。匹配损失的表达式如下所列,其中 ∗ * ∗表示"fwd"或"bwd":

训练过程对协同 affinity 和检测损失做优化,如等式7定义。为了更好地优化这个双任务网络,作者使用了[22]中提到的一个策略,来自动的损失平衡这两个任务:

其中 L d e t e c t t \mathcal{L}_{detect}^t Ldetectt是帧 t t t的检测损失, λ 1 \lambda_1 λ1和 λ 2 \lambda_2 λ2是用于平衡这两个任务的权重。主要,平衡权重是可以学习的参数。