NLP篇【02】白话Word2vec原理以及层softmax、负采样的实现
上一篇:NLP篇【01】tfidf与bm25介绍与对比
下一篇:NLP【03】白话glove原理
一、什么是word2vec
Word2vec,即词向量。2013年,Google团队发表了word2vec工具。word2vec工具主要包含两个模型:跳字模型(skip-gram)和连续词袋模型(continuous bag of words,简称CBOW),以及两种高效训练的方法:负采样(negative sampling)和层序softmax(hierarchical softmax)。值得一提的是,word2vec词向量可以较好地表达不同词之间的相似和类比关系。Google提出的这个word2vec,极大的推动了自然语言处理的发展,所以后来Word2vec就成了词向量的代名词,我们口中的的word2vec有时特指Google发表的word2vec,有时又指由其他模型学习的词向量。
二、NLP词的表示方法
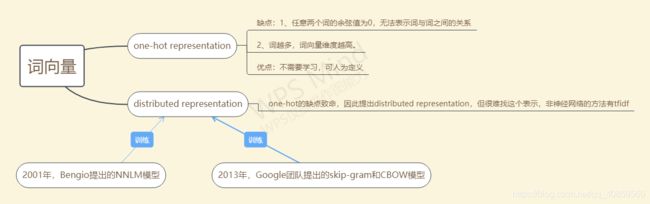
1、词的独热(one-hot)编码
用词向量来表示词并不是word2vec的首创,在很久之前就出现了one-hot的编码的词向量,这种词向量缺点:1、任意两个词的余弦值为0,无法表示词与词之间的关系。2、词向量是很冗长的,它使用是词向量维度大小为整个词汇表的大小,对于每个具体的词汇表中的词,将对应的位置置为1。所以就有了词的分布式表示 distributed representation。
2、分布式表示 distributed representation
Dristributed representation可以解决One hot representation的问题,它的思路是通过训练,将每个词都映射到一个较短的词向量上来。所有的这些词向量就构成了向量空间,进而可以用普通的统计学的方法来研究词与词之间的关系。这个较短的词向量维度是多大呢?这个一般需要我们在训练时自己来指定。词的分布式表示主要可以分为三类:基于矩阵的分布表示(共现矩阵)、基于统计的分布表示(tfidf)和基于神经网络的分布表示。
三、基于神经网络学习分布式词向量
在Google提出word2vec 12年之前, 2001年, Bengio 等人就正式提出神经网络语言模型( Neural Network Language Model ,NNLM),该模型在学习语言模型的同时,也得到了词向量。但由于该模型训练速度非常慢,只适用小语料库,所以限制了词向量的应用。12后,Google提出的cbow和skip-gram模型,剔除隐藏层,模型更为简单,而且提出来了层softmax和负采样两种训练方式,大大加快了模型的训练速度,因此可以适用超大的语料库。一时间,word2vec在NLP界引起轰动,成了词向量的代名词。
四、训练word2vec的两种模型cbow和skip-gram
1、 Continuous Bag-of-Words (CBOW)

CBOW是用上下文预测中心词,即上下文为训练集,中心词为label,经典模型结构如上图,但比较抽象,不易理解。下面我举个例子,保证你能明明白白。假如语料库就一句话:I like studying very much,如下图:

窗口size为2(即上下文为I like very much,中心词为studying),1、首先把训练集做one-hot 2、再与词向量矩阵(这个矩阵就是最后我们需要的词向量矩阵)作矩阵相乘即得到每个词的词向量。3、把训练集4个词的词向量求平均值,记为平均向量 4、把平均向量与词向量的矩阵的转置作矩阵相乘,即得到了shape为(batch_size,vocab_size)在这里为(1,5)的向量,每个向量的值就是与每个词的余弦值 6、最后我们让标签对应的余弦值最大,即让交叉熵最小。
进一步想了一想的同学就会发现上述过程有两个问题 1、one-hot 中'very'中1的index为3,所以‘very’的词向量就是index为3的那行向量,所以没有必要去做矩阵相乘(毕竟矩阵相乘非常慢),直接索引就好了(的确,实际实现都是直接索引的,见不到one-hot)2、平均向量与矩阵向量的转置相乘,怎么能得到与每个词的余弦值得呢?(我建议大家拿起笔,演示一遍),是的,这里只是计算了余弦的分子部分,还没除于两个向量模的乘积。但当两个向量都进行l2_normal归一化后,即模变为1,两个向量的点乘就是余弦值。
其实这里还有一个大问题就是:我们最后的得到的向量shape为(batch_size,vocab_size),然后再求softmax与交叉熵以及梯度回传每次要更新所有词汇的embeding,这个复杂度是非常高的,因为在大的语料库中,vocab_size是非常大的,可达百万级或更高,所以google采用了层次softmax和负采样解决这个问题。
2、Skip-Gram

Skip-Gram的模型图与CBOW恰好相反,如上图所示,skip-gram是用中心词预测上下文,为了更好理解skip-gram,我同样举个例子,如下图:

同样语料库为I like studying very much,为了方便,设窗口size为1,中心词studying,则可以理解训练集为studying,标签为[0,1,1,1,0]。大致过程为1、对每个词进行数字编码,studying的编码为2 2、取词向量矩阵index为2的向量就是studying的向量 3、用studying的向量与词向量矩阵的转置作矩阵相乘,就会得到shape为(batch_size,vocab_size)这里就是(1,5),向量每个位置的值就是studying的词向量和每个词向量的余弦值 4、同label求交叉熵,使交叉熵最小并反向传播。很明显和cbow模型一样,复杂度与语料库中词的个数成正比。
五、加速训练word2vec的两种方式——层次softmax和负采样
1、层次softmaxt
首先,层次softmax是一棵huffman树,树的叶子节点是训练文本中所有的词,非叶子节点都是一个逻辑回归二分类器,每个逻辑回归分类器的参数都不同,分别用
![]() 表示。假定分类器的输入是向量
表示。假定分类器的输入是向量  ,记逻辑回归分类器输出的结果
,记逻辑回归分类器输出的结果 ![]() ,将向量 传递给节点的左孩子的概率为
,将向量 传递给节点的左孩子的概率为 ![]() ,否则传递给节点的右孩子的概率是
,否则传递给节点的右孩子的概率是 ![]() 。重复这个传递的流程直到叶子节点。以cbow和skip-gram中的图为基础,更改之后的模型如下图所示:
。重复这个传递的流程直到叶子节点。以cbow和skip-gram中的图为基础,更改之后的模型如下图所示:

图1 基于层次softmax的CBOW

图2 基于层次softmax的Skip-Gram
从图1和图2中可以看出,我们就是将隐藏层的向量 直接传给了一个层次softmax,层次softmax的复杂度为 ![]() 。层次softmax采样到每个词的概率分别如下:
。层次softmax采样到每个词的概率分别如下:
采样到 I 的概率 ![]()
采样到 eat 的概率 ![]()
采样到 to 的概率 ![]()
采样到 like 的概率 ![]()
采样到 apple 的概率 ![]()
对于图1的CBOW模型,如果我们要预测的词是 to ,那么我们就要让 ![]() 尽量大一点,而对于图2的Skip-Gram模型,我们要根据to预测I,eat,like,apple,就是让sum(p(I/context),p(eat/context)...p(apple/context))最大,所以现在我们的任务转化为了训练
尽量大一点,而对于图2的Skip-Gram模型,我们要根据to预测I,eat,like,apple,就是让sum(p(I/context),p(eat/context)...p(apple/context))最大,所以现在我们的任务转化为了训练 ![]()
![]() 个逻辑回归分类器。CBOW模型和Skip-Gram模型训练的目标函数与之前形式一样,为
个逻辑回归分类器。CBOW模型和Skip-Gram模型训练的目标函数与之前形式一样,为

有仔细思考的同学就会有疑问,这右边的哈夫曼树是怎么得到的呢?可以自行百度哈夫曼树的构造哈哈哈哈哈哈。
2、负采样
我看过大多数的博客,都没有把负采样讲明白。我争取用最通俗的话给他讲明白。拿cbow模型举例,回顾一下上述训练过程:获得上下文的向量特征后,要与语料库中每个词进行点乘(也就是求余弦值),然后softmax,最后根据label去损失,再反向传播回去。要与每个词都要计算一遍余弦值,是我们不愿看到的。所以负采样,就是先把正样本(上述过程就是‘studying’)拿出来,然后再选取一定数量的负样本(比如40个),如下图所示:
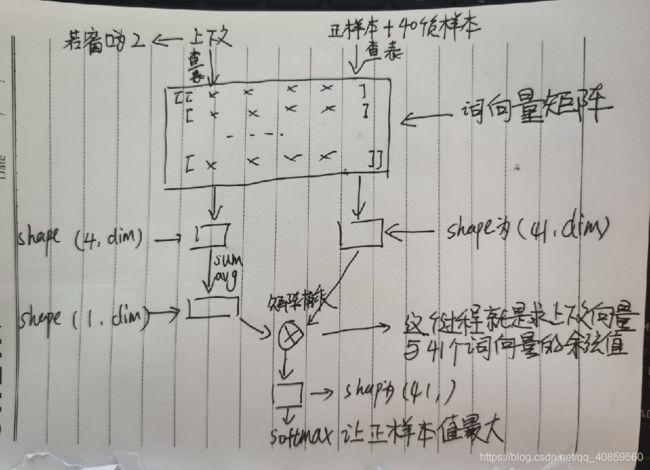
上下文(窗口为2则为4个词)经过词向量矩阵获得对应的词向量,再求和平均得shape为(1,dim)(dim为词向量的维度)。正负样本组成41个词,经过词向量矩阵也得到了对应的词向量。最后把上下文向量与正负本向量相乘即可。