爬虫入门实例——使用正则表达式爬取猫眼100电影排行
文章目录
- 前言
-
- 爬虫是什么
- 爬取猫眼电影100排行步骤
-
- 1.分析需要爬取的内容
- 2.分析网页了解爬取的方式
- 3.分析网页源码找到爬取思路
- 4.正则表达式的编写
- 5.编写python代码
-
- 爬虫程序各部分python代码详解
-
- get_one_page()函数
- parse_one_page()函数
- main()函数
- 完整代码
- 输出结果
- 后记
前言
中间差不多有四个月没有写博客文章了,一方面是因为那时候基本上已经开学了,虽说是上网课,但是也不想学了这忘了那,所以也不太有充足的时间来自学一些东西了,好在我有一个完整的暑假,没有工作、不需要搞社会实践,所以就能静下心来好好学一学我心心念念的爬虫了。四个月的时间又没怎么接触python了,感觉再看到他的时候有一种熟悉但陌生的感觉,对于一个学生程序员来说,四个月不再接触一个东西是很容易遗忘的,毕竟我们学的东西太多了,不可能总在你脑子里占据着,再加上没有项目啥的给你练手,所以必要的复习是非常重要的,这也就是我写这么些博客的原因,有这么一个平台让我能在闲暇之时去看一看,也能帮助那些像我一样在学习时遇到困难的小伙伴,分享我的学习心得。
爬虫是什么
相信能看到我这篇文章的小伙伴应该对爬虫都有一定的了解,这里我就不赘述了,简单来说爬虫就是一个程序,它通过各种独到的方式来实现网页数据内容的获取,基本上可见即可爬,现在主流的爬虫程序都是由python来实现和开发的,python语言简单精炼特别适合用来写爬虫。
爬取猫眼电影100排行步骤
1.分析需要爬取的内容
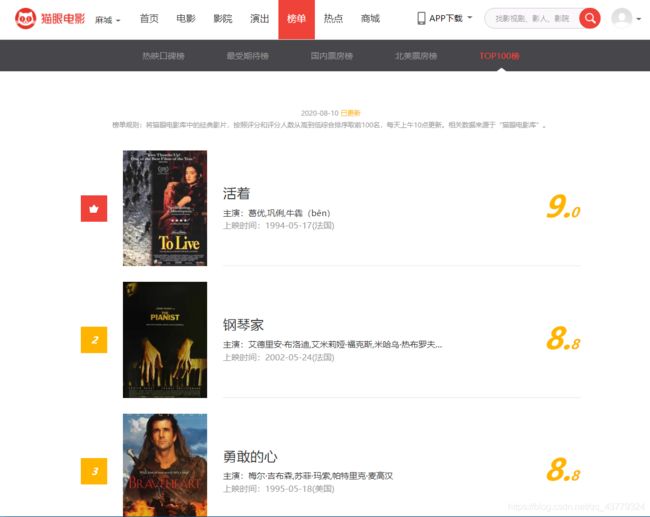
下面就是猫眼100的网页界面了,每个影片都是由海报、片名、主演、上映时间、评分这几个方面构成的,我们的目的就是获取这100部影片的所有信息。
2.分析网页了解爬取的方式
鼠标右键单击检查,就能进入开发者模式界面,获取到网页的源代码等一系列信息。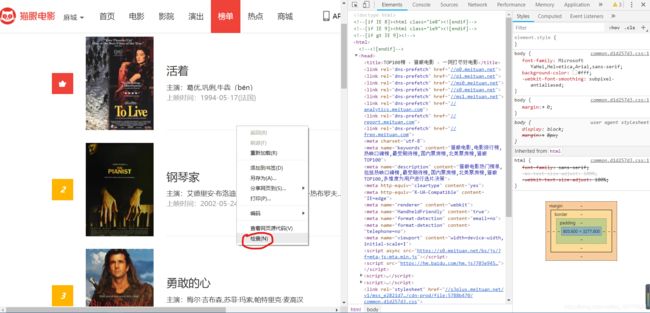
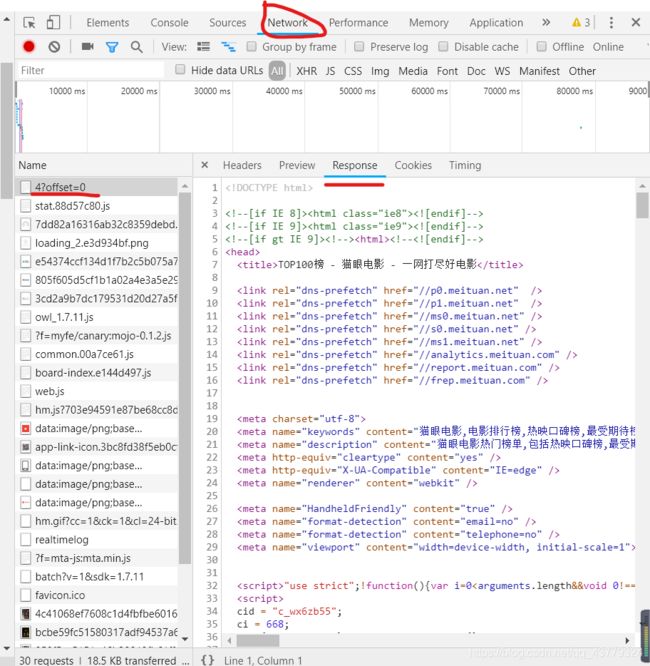
然后我们切换到Network这个监听组件然后选择第一个文件,点击Response查看网页的源代码,虽然我们之前再Elements组件中也能看到源码,但是这里的源码可能是经过JavaScript渲染过了的。
3.分析网页源码找到爬取思路
首先我们可以看到,每一部影片的信息都是在一个dd标签内部,然后一个一个的dd标签构成这100部影片信息。
<dd>
<i class="board-index board-index-1">1i>
<a href="/films/1375" title="活着" class="image-link" data-act="boarditem-click" data-val="{movieId:1375}">
<img src="//s3plus.meituan.net/v1/mss_e2821d7f0cfe4ac1bf9202ecf9590e67/cdn-prod/file:5788b470/image/loading_2.e3d934bf.png" alt="" class="poster-default" />
<img data-src="https://p0.meituan.net/movie/4c41068ef7608c1d4fbfbe6016e589f7204391.jpg@160w_220h_1e_1c" alt="活着" class="board-img" />
a>
<div class="board-item-main">
<div class="board-item-content">
<div class="movie-item-info">
<p class="name"><a href="/films/1375" title="活着" data-act="boarditem-click" data-val="{movieId:1375}">活着a>p>
<p class="star">
主演:葛优,巩俐,牛犇(bēn)
p>
<p class="releasetime">上映时间:1994-05-17(法国)p> div>
<div class="movie-item-number score-num">
<p class="score"><i class="integer">9.i><i class="fraction">0i>p>
div>
div>
div>
dd>
所以我们只需要分析一个就可以通过循环来爬取后面的所有影片信息了。首先我们通过class为board-index的i标签来获取排名,然后我们的第二个img标签的data-src属性可以获取图片链接,p标签的name属性之后可以获取片名,后面的star是主演,releasetime是上映时间,integer是评分等等。
在正则表达式中,我们通过一系列的正则匹配来实现对网页源码中信息的获取,编写正则表达式是为了通过匹配()中的内容,获取我们需要的内容,其中匹配时就需要一些参考的节点,更方便我们进行提取。
相关正则表达式的内容可以参见我之前写的博客:应用于python爬虫的正则表达式基础用法详解
4.正则表达式的编写
在这里我们使用非贪婪匹配来提取i标签内部的排名信息,正则表达式写为:
<dd>.*?board-index.*?>(.*?)</i>
< dd >是我们正则表达式匹配的一个开始节点,相当于是说当我们的计算机看到< dd >这个这几个字符之后就开始进行匹配了,.*?是非贪婪的方式匹配任意字符(非贪婪就是尽量匹配少的字符,避免他所有都可以匹配而错过了我们需要抓取的内容),后面的board-index可以说是一个标识位置了,不仅是提示计算机也算是提醒我们自己后面到了要抓取的地方了,重点就是()里面的内容,这是我们编写这个正则表达式真正要获取到的信息,因为我们后面可以用方法来提取括号里面的内容并打印出来。
随后是第二个img标签里面的data-src属性的图片链接信息,正则表达式可以改写为:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)"
同第一次编写的正则表达式一样,我们标记到data-src这个位置,然后在之后的信息中去匹配“ ”中的内容,并用()括起来,以备我们后面输出。
然后再提取主演、发布时间、评分等内容时都是同样的原理,最后全部的正则表达式应该写为:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>.*?fraction.*?>(.*?)</i>.*?</dd>
虽然很长,但是只要我们按照第一个的那个规律写出来提取一个信息的正则表达式,后面的就迎刃而解了。当然这个正则表达式是不是唯一的,每个人都可能有自己的写法。
5.编写python代码
爬虫程序各部分python代码详解
get_one_page()函数
首先我们是抓取一个页面,然后根据url的不同,更改参数来抓取所有页面。再get_one_page()函数中,我们通过requests库中的get()方法来抓取页面的源码,其中使用了异常处理,避免因为网络问题或者其他的原因导致我们的爬虫宕机。
def get_one_page(url):
try:
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
+ 'Chrome/84.0.4147.89 Safari/537.36'
}
response = requests.get(url, headers= headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
parse_one_page()函数
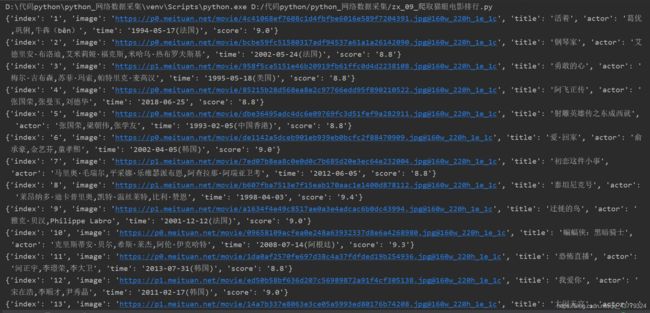
这个函数的作用就是通过正则表达式解析我们爬取到的源码,然后将提取到的信息在控制台输出。
def parse_one_page(html):
pattern = re.compile(
'.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?).*?star.*?>(.*?)'
+ '.*?releasetime.*?>(.*?).*?integer.*?>(.*?).*?fraction.*?>(.*?).*?', re.S
)
items = re.findall(pattern, html)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2].strip(),
'actor': item[3].strip()[3:] if len(item[3]) > 3 else '',
'time': item[4].strip()[5:]if len(item[4]) >5 else '',
'score': item[5].strip() + item[6].strip()
}
main()函数
通过调用get_one_page()和parse_one_page()来实现页面源码的抓取以及内容的解析,这里我们对main函数添加了一个参数offset,这个参数是用来设置url的偏移量,爬取其他页面的。仔细观察这个榜单就会发现,当你点击下一页之后,url的后面offset发生了偏移,每次增加10,我们通过循环来控制这个offset就可以实现全部页面的爬取。
def main(offset):
url = 'http://maoyan.com/board/6?offset=' + str(offset)
html = get_one_page(url)
# print(html)
for item in parse_one_page(html):
print(item)
write_to_file(item)
完整代码
import requests
import re
import json
from requests.exceptions import RequestException
import time
def get_one_page(url):
try:
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)'
+ 'Chrome/84.0.4147.89 Safari/537.36'
}
response = requests.get(url, headers= headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_one_page(html):
pattern = re.compile(
'.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?).*?star.*?>(.*?)'
+ '.*?releasetime.*?>(.*?).*?integer.*?>(.*?).*?fraction.*?>(.*?).*?', re.S
)
items = re.findall(pattern, html)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2].strip(),
'actor': item[3].strip()[3:] if len(item[3]) > 3 else '',
'time': item[4].strip()[5:]if len(item[4]) >5 else '',
'score': item[5].strip() + item[6].strip()
}
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
# print(html)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
for i in range(10):
main(offset=i * 10)
time.sleep(1)
输出结果
如果爬虫没有报错但是不输出信息的话就打开Chrome然后进入猫眼100里面去刷新一下页面,多半是因为猫眼100是爬虫入门最喜欢爬的地方,现在美团要滑动验证了。
后记
爬完猫眼也算是正式入坑爬虫了,学到后面你会发现其实用正则表达式不算是一种特别好的办法,当遇到要爬的东西比较杂比较多的时候正则表达式坑你不太适用。当然正则表达式通俗易懂,易于编写,所见即所爬(源代码),是新手入门爬虫的良器。