基于torch学汪峰写歌词、聊天机器人、图像着色/生成、看图说话、字幕生成
手把手教你基于torch玩转
学汪峰写词、自动聊天机器人、图像着色、图像生成、看图说话、生成字幕
作者:骁哲、李伟、小蔡、July。
说明:本教程出自七月在线助教团队、及七月在线深度学习在线班学员之手,有何问题欢迎加Q群交流:472899334。且探究实验背后原理,请参看:深度学习在线班。
时间:二零一六年十月十二日。
前言
我们教梵高作画的教程发布之后,国庆7天,上百位朋友一一陆续动手尝试,大有全民DL、全民实验之感。特别是来自DL班的小蔡同学,国庆7天连做10个开源实验,并把这10个实验的简易教程(含自动聊天机器人)发布在社区上:https://ask.julyedu.com/explore/category-13。盛赞。
为了让每一个人(是的,每一个人,博客、教程、课程无不如此)都能玩一把,本教程特在小蔡简易教程的基础上重新整理,侧重torch环境的搭建(因为根据我们的经验,环境一旦搭好,做实验基本一马平川),此外所有能想到的、能做到的、能写上的(甚至一个sudo –i命令)都已详尽细致的写出来,为的就是让每一个人都能玩一把,无限降低初学朋友的实验门槛。
还是那句话,欢迎更多朋友跟我们一起做实验,一起玩。包括学梵高作画的7个实验:梵高作画、文字生成、自动聊天机器人、图像着色、图像生成、看图说话、字幕生成,今2016年内,只要你做出这7个实验中的任意一个并在微博上AT@研究者July,便送100上课券,把实验心得发社区 ask.julyed.com 后,再送100上课券。
另,我们更会在深度学习在线班上详解实验背后的原理,让君知其然更知其所以然。
一、 准备工作
1、 Torch介绍
Torch是一个有大量机器学习算法支持的科学计算框架,其诞生已经有十年之久,但是真正起势得益于Facebook开源了大量Torch的深度学习模块和扩展。Torch另外一个特殊之处是采用了编程语言Lua(该语言曾被用来开发视频游戏)。
Torch的优势:
- 构建模型简单
- 高度模块化
- 快速高效的GPU支持
- 通过LuaJIT接入C
- 数值优化程序等
- 可嵌入到iOS、Android和FPGA后端的接口
*信息来源--http://www.leiphone.com/news/201608/5kCJ4Vim3wMjpBPU.html?_t_t_t=0.9860681521240622
2、 系统说明
本次搭建是在Ubuntu14.04基础上搭建,Ubuntu14.04系统安装教程已在Tensorflow实验中分享,还不清楚的同学,先回顾上次实验内容:教你从头到尾利用DL学梵高作画:GTX 1070 cuda 8.0 tensorflow gpu版
3、 实验目录
(1) 文字生成
(2) 自动聊天
(3) 图像着色
(4) 图像生成
(5) 看图说话
(6) 字幕生成
二、 搭建Torch
l 参考github网址: https://github.com/torch/torch7
l 搭建torch7网址:http://torch.ch/docs/getting-started.html
步骤:
1、 笔者假设读者已经安装完成NVIDIA的GPU驱动以及CUDA、cudnn,若还未安装的,请参考教你从头到尾利用DL学梵高作画:GTX 1070 cuda 8.0 tensorflow gpu版
2、 ubuntu终端窗口输入:
以下所有命令均在root用户下执行
apt-get update (更新源)
3、 打开搭建torch7网址
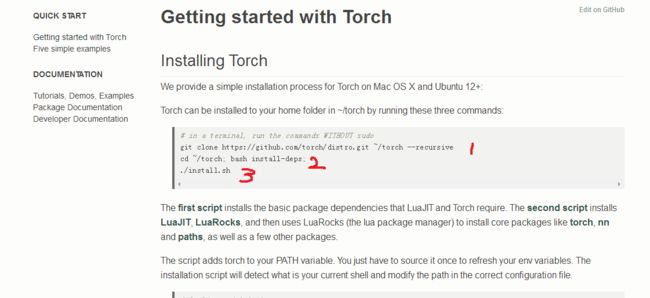
git clone https://github.com/torch/distro.git ~/torch --recursive (克隆torch到~/torch文件下)
cd ~/torch; bash install-deps; (执行install-deps)
./install.sh (执行程序)
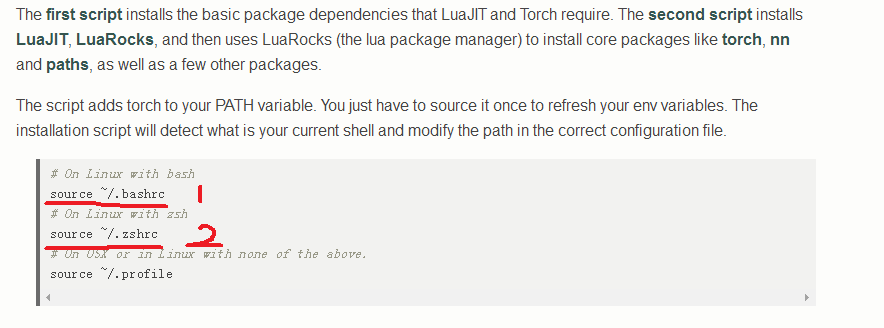
source ~/.bashrc (Ubuntu14.04一般情况执行这个,更新.bashrc文件)
source ~/.zshrc (读者不放心了把这个也执行了)
*******如果读者用Lua5.2就执行如下,没有就跳过*******
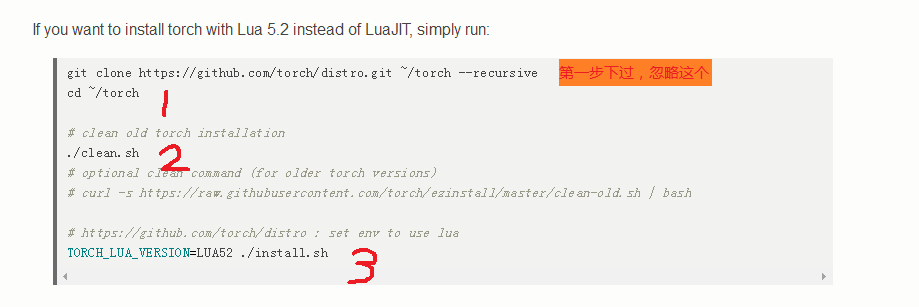
第一个git忽略,开始搭建时候已经下载过了
cd ~/torch (进入torch文件)
./clean.sh (执行clean.sh)
TORCH_LUA_VERSION=LUA52 ./install.sh(执行命令)
*****************结束*************************

luarocks install image (安装image)
luarocks list (列出luarocks安装的包、检查是否安装成功)
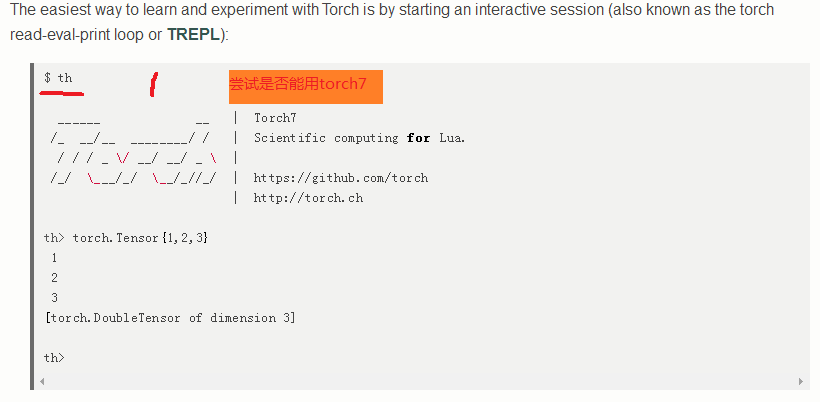
th (测试能否用torch7,出现如上图标志,表示能用)
4、 笔者在安装过程中出现torch7的环境变量未能添加到PATH内。解决办法如下:
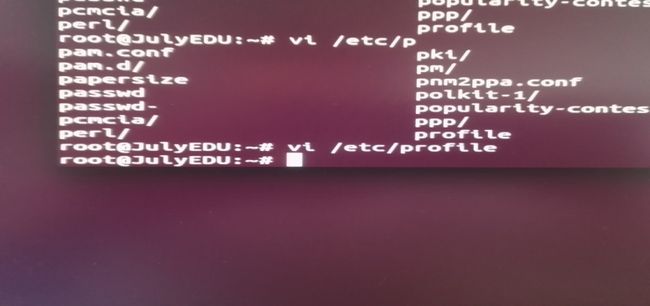
在终端输入:vi /etc/profile
进入文件后,在最后添加如下命令:
PATH=~/torch/install/bin:$PATH
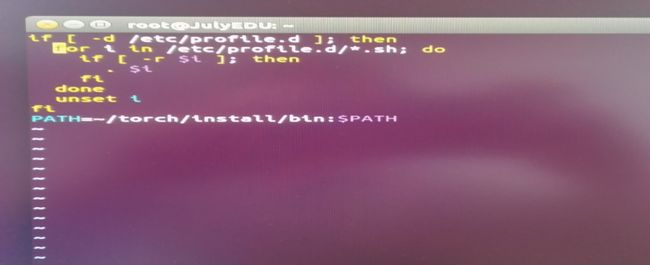
按Esc 接着输入: q 退出
执行 source /etc/profile (更新一下)
三、7个实验
1. 文字生成
参考教程地址:https://ask.julyedu.com/question/7405
参考课程:https://www.julyedu.com/video/play/18/130
参考github:https://github.com/karpathy/char-rnn
l 下载包
luarocks install nngraph
luarocks install optim
luarocks install nn
l 如果用GPU,安装如下包
luarocks install cutorch
luarocks install cunn
l 下载char-rnn包
git clone --recursive https://github.com/karpathy/char-rnn
cd char-rnn;
l 自行下载你想要生成类型的模板(.txt文件),例如唐诗三百首、汪峰歌词、韩寒小说……
l 利用cp命令和mv命令,把下载好的.txt文件覆盖data/tinyshakespeare下的input.txt
l 训练
l 生成
th sample.lua cv/lm_lstm_epoch(按住Tab自动补全) -gpuid -1(-gpuid -1这个是仅适用CPU的命令,GPU的同学自行忽略)

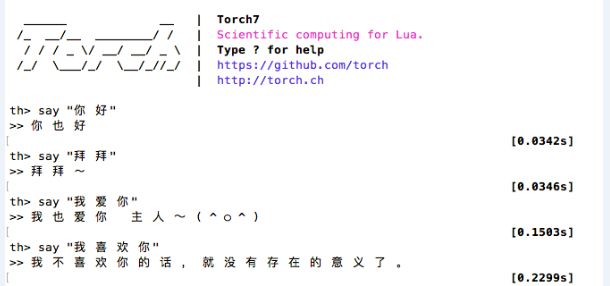
2. 自动聊天机器人
参考教程地址:https://ask.julyedu.com/question/7410(本教程基本参考以上地址内容,大家可以直接进去查看)
参考课程:七月在线深度学习课程
参考github:https://github.com/rustch3n/chatbot-zh-torch7
l 环境包下载
sudo ~/torch/install/bin/luarocks install nn
sudo ~/torch/install/bin/luarocks install rnn
sudo ~/torch/install/bin/luarocks install async
l 下载代码与语料
git clone --recursive https://github.com/rustcbf/chatbot-zh-torch7 #代码
git clone --recursive https://github.com/rustcbf/dgk_lost_conv #语料
git clone --recursive https://github.com/chenb67/neuralconvo #以上两个在此源码进行改进,可作为参考
l 语料选择
语料除了上述提供的语料,可自行生成自己的语料
cd dgk_lost_conv #参考cvgen.py
如需查看语料内容
python toraw.py a.cov b.txt
cd chatbot-zh-torch7
笔者原先直接使用xiaohuangji50w_fenciA.conv(估计是小黄鸡聊天机器人语料,50w条数据),后来训练时间觉得太长,换了作者提供的小样本。
更改样本的修改cornell_movie_dialogs.lua 第18行代码,建议先不修改,因为笔者在作者提供的小样本下效果不是很好,数据应该没有经过处理。自行下载你想要生成类型的模板(.txt文件),例如唐诗三百首、汪峰歌词、韩寒小说……
l 训练
th train.lua (笔者实验时提示内存不够,因此输入命令为th train.lua --dataset 20000 --hiddenSize 100 )#可加参数--cuda、--opencl、--hiddenSize等等
在 data 文件夹生成有examples.t7,model.t7、vocab.t7
l 开始
修改eval.lua
在源码后边添加
print("\nType a sentence and hit enter to submit.")
print("CTRL+C then enter to quit.\n")
while true do
io.write("you> ")
io.flush()
io.write(say(io.read()))
end
th eval.lua #直接命令行
一开始用64G内存的服务器跑50w语料,跑完后,发现效果还凑合
但如果换成普通台式机跑50w语料的话,可能麻烦就来了。因为训练过程中发现台式机的8G内存不够,于是又加了8g内存,但即便是16g内存还是不够,最好只好舍弃部分语料,换成20w的语料,可正因为语料减少,训练出的聊天机器人效果就不如先前50w语料训练出的效果好了,可能会逼你出口成脏。
3. 图像着色
参考教程地址: https://ask.julyedu.com/question/7412参考github:https://github.com/satoshiiizuka/siggraph2016_colorization
l 环境包下载
sudo ~/torch/install/bin/luarocks install nn
sudo ~/torch/install/bin/luarocks install image
sudo ~/torch/install/bin/luarocks install nngraph
l 下载模型
./download_model.sh
l 执行
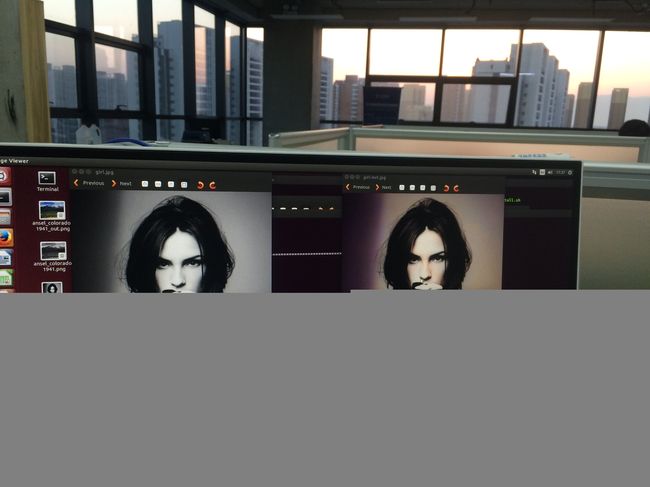
th colorize.lua ***(黑白图片地址) ***(生成图片存放地址)
示例:th colorize.lua ansel_colorado_1941.png ansel_colorado_1941_out.png
4. 图像生成
参考教程地址: https://ask.julyedu.com/question/7414参考github:https://github.com/soumith/dcgan.torch
l 环境包下载
sudo ~/torch/install/bin/luarocks install optnet
sudo ~/torch/install/bin/luarocks install display
sudo ~/torch/install/bin/luarocks install cudnn(GPU执行)
sudo ~/torch/install/bin/luarocks install https://raw.githubusercontent.com/szym/display/master/display-scm-0.rockspec#
l 下载模型
https://github.com/soumith/lfs/raw/master/dcgan.torch/celebA_25_net_G.t7
https://github.com/soumith/lfs/raw/master/dcgan.torch/bedrooms_4_net_G.t7
l 执行
cd dcgan.torch
gpu=0 batchSize=64 net=celebA_25_net_G.t7 th generate.lua #cpu运行 batchSize图像数量
gpu=1 batchSize=64 net=celebA_25_net_G.t7 th generate.lua #cpu运行
5. 看图说话
参考教程地址:https://ask.julyedu.com/question/7413
参考github:https://github.com/karpathy/neuraltalk2
环境包下载
sudo ~/torch/install/bin/luarocks install nn
sudo ~/torch/install/bin/luarocks install nngraph
sudo ~/torch/install/bin/luarocks install image
sudo ~/torch/install/bin/luarocks install hdf5 #这个也是必须的
sudo ~/torch/install/bin/luarocks install loadcaffe 下载模型
没有gpu的同学可忽略以下的安装命令
sudo ~/torch/install/bin/luarocks install cutorch
sudo ~/torch/install/bin/luarocks install cunn
l 模型下载
http://cs.stanford.edu/people/karpathy/neuraltalk2/checkpoint_v1.zip
l 准备图片
cd neuraltalk2
mkdir images #将图片放到此目录下
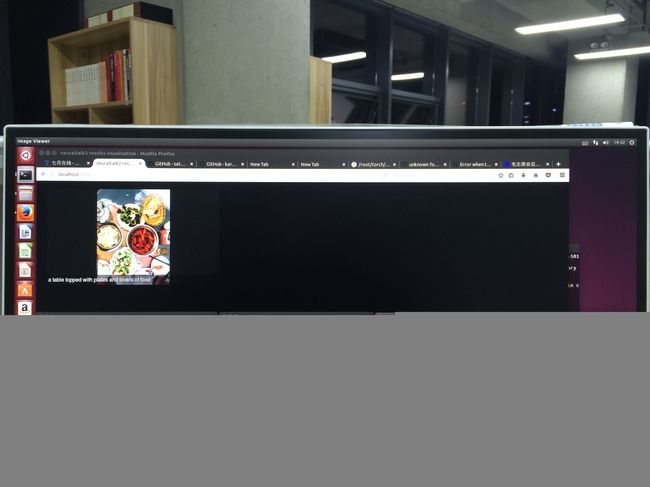
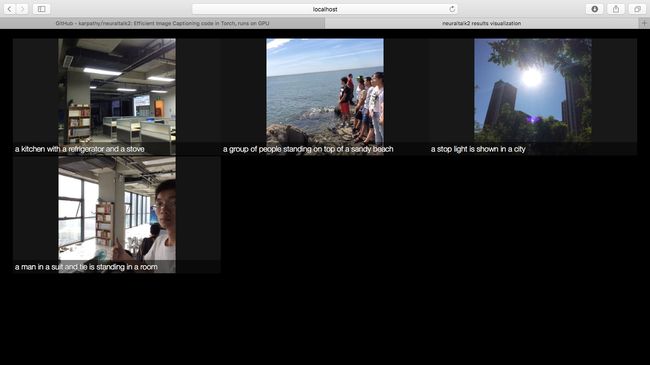
l 生成图片描述
th eval.lua -model model_id1-501-1448236541.t7_cpu.t7 -image_folder ./images/ #可加参数-num_images 等
th eval.lua -model model_id1-501-1448236541.t7_cpu.t7 -image_folder ./images/ -gpuid -1 #没有gpu的读者运行此命令
cd vis
python -m SimpleHTTPServer #启动后访问http://localhost:8000
6. 字幕生成
参考教程地址:https://ask.julyedu.com/question/7411
参考github:https://github.com/jcjohnson/densecap
l 环境包下载
.环境依赖
读者自行安装torch环境
luarocks install nn
luarocks install image
luarocks install lua-cjson
luarocks install https://raw.githubusercontent. ... kspec
luarocks install https://raw.githubusercontent. ... kspec
luarocks install sys #需要多加一项
没有gpu 忽略
luarocks install cutorch
luarocks install cunn
luarocks install cudnn
luarocks install cudnn
l 模型下载
sh scripts/download_pretrained_model.sh
l 修改代码
run_model.lua 代码29行自行修改Model位置
l 运行
cpu 运行
th run_model.lua -input_image imgs/elephant.jpg -gpu -1
gpu 运行
th run_model.lua -input_image imgs/elephant.jpg
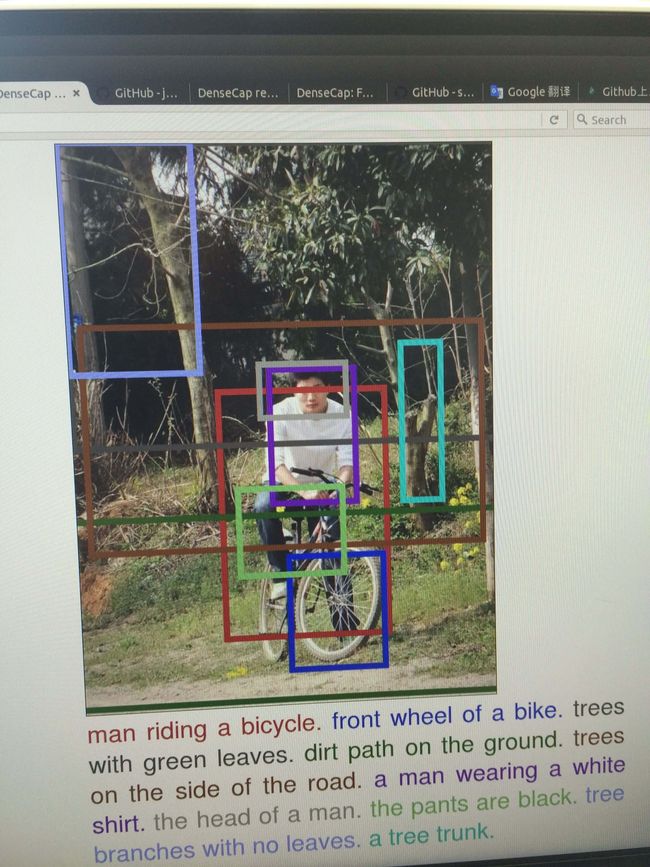
l 查看效果
cd vis
python -m SimpleHTTPServer 8181
访问:http://localhost:8181/view_results.html
例如,给定系统一张图片,系统自动生成字幕:一男的骑单车,穿白色T恤..
后记
后续 继续 一起玩。
七月在线出品,二零一六年十月十二日。