中间件(redis,rabbitmq,zookeeper,kafka)集群讨论及搭建
一,前言
大家好,我是小墨。
这一篇文章我们来一个中间件的集群的搭建的大团圆章节,将围绕我们使用的主流几个中间件(我使用过的)的集群构建方式进行原理讨论和实际搭建方案探讨,包括zookeeper,redis,rabbitmq,zookeeper,然后我们对这些中间件集群进行总结,尽量提炼出一些知识出来一起分享,注意本文不涉及实际搭建过程。后面一期专门讲讲mysql集群,然后我们再尽量联系起来一起思考。
二,中间件集群搭建
1,zookeeper集群
1)集群搭建
我们简单讲述下zookeeper集群搭建方式:
- 准备zookeeper机器,我们举例机器A,B,C,配置zoo.cfg:这里多了一个server.id=host:port1:port2 配置,这个id为server ID 用于标记机器在集群中的机器序号
tickTime=2000 dataDir=/var/lib/zookeeper dataLogDir=/var/lib/log clientPort=2181 initLimit=5 syncLimit=2 server.1=A:2888:3888 server.2=B:2888:3888 server.3=C:2888:3888
创建 myid 文件,在 dataDir 目录下创建名为 myid 的文件,在文件第一行写上对应的 Server ID。
启动机器
2)集群分析
对于zookeeper而言,作为一种为分布式而设计的协调服务,集群中的机器自动会协调之间的关系,对于zookeeper集群而言,有三种角色:
- leader:负责更新系统状态,在协调集群过程时起投票的发起和决议,负责写入信息,并同步到各个节点
- follower:参与选举leader的投票,然后用于接收客户请求并向客户端返回结果
- observer:除了不参与投票外,其他与follower一样,只干活无权力者
zookeeper集群基于ZAB协议进行启动,leader宕机,运行时的选举过程,我们这里不细讲整个选举过程,就以如果有leader宕机情况下如何选出leader恢复集群工作 (举例A,B,C三台机器构成的集群,A 为leader):
- 变更状态。leader挂掉后,剩余的follower机器把状态有following改为looking。开始选举
- 每个server发起一个投票。B和C会将自身作为leader来投票,这里投票信息包括自身myid,ZXID(写成功的消息,都有一个全局唯一的标识,叫zxid,每写一次都会递增,防止不同轮次的选举互相干扰),然后广播给集群中的其他机器
- 接收各机器投票:各机器收到投票后判断该投票的有效性,如检查是否是本轮投票、是否来自LOOKING状态的服务器。
- 处理投票。比较规则如下: 1)优先检查ZXID,ZXID最大的优先为leader 2)ZXID相同就比较myid,myid最大获胜为leader。
- 统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到相同的投票信息,如果有的话那么表示过半机器都有相同观点认为某机器为leader
- 修改服务器状态,当确认leader后,该follower升级leader,修改状态为leading,其他follower修改为following
我们简单讨论下为什么这么设计,我们先关注一个zookeeper集群读写数据流程:
1)写请求
- 有写操作时,如果是follower接收,会转到leader,
- leader收到写请求后,写入本地,为该操作生成zxid,然后发zxid和数据一起给所有follower节点
- 当follower收到后时,写入本地,成功后返回给leader。
- leader收到过半反馈(包括自己),返回给client说已经成功
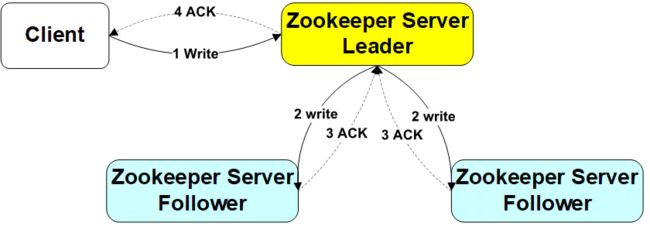
2)读数据:Client向zookeeper发出读请求时,无论是Leader还是Follower,都直接返回查询结果,并不保证数据最新。
好了看完后我们是不是想到了分布式中的难言之隐----数据一致性问题,但是我们这里按下不表,就谈谈我们当时选举过程的设计:我们使用如此规则1)优先检查ZXID,ZXID最大的优先为leader 2)ZXID相同就比较myid,myid最大获胜为leader。
明显就可以发现我们是选举一个数据最新的follower!!希望尽量保证leader宕机后数据的最新和一致性。
2,redis集群
对于redis集群的更加完整的请查看redis之---redis集群方案,我不详细叙述了,主要举redis的cluster集群方案。
cluster集群的键空间被分割为16384个slots(即hash槽),slot是数据映射的基本单位,即集群的最大节点数量是16384(官方推荐最大节点数量为1000个左右)。集群中的每个Master节点负责处理16384个hash槽其中的一部分,当集群处于“stable”状态时(无slots在节点间迁移),任意一个hash slot只会被单个node所服务。
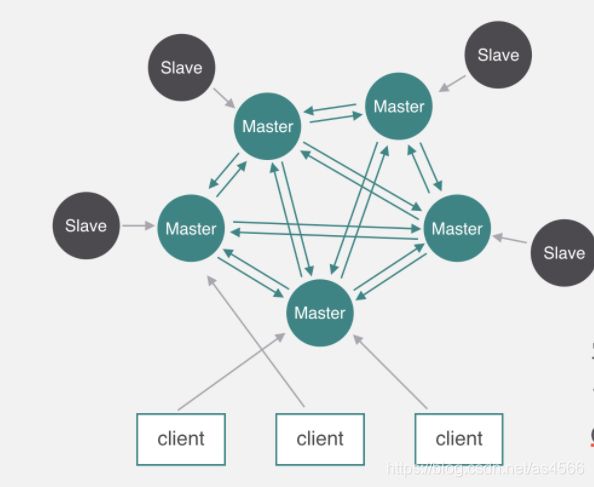
作为一种去中心化的设计,我们谈谈这种设计下如何保证集群稳定运行:
- 集群分为主从节点两种角色,主节点负责写与读,从节点只做备份,数据副本
- 当主节点发生宕机,进行从节点选举,我们概括下:
当挂掉的master有多个slave时,存在多个slave竞争为master节点过程,过程如下:
- 1)过半主节点发现该主节点下线了才标记为客观下线 ,集群广播fail消息
- 2)检查从节点与主节点最后断线时间,发现超过了cluster-node-time*cluster-slave-validity-factor的不具有资格
- 3)准备选举,复制偏移量越大的节点说明从节点延迟越低,优先选举
- 4)从节点收到集群内超过一半的主节点的投票后成为主节点
- 5)替换主节点,获取槽,广播自己的pong消息,让其他从节点成为他的小弟
3,消息队列集群
对于消息队列的集群,我们举了rabbitmq和kafka来进行比较,我们可以思考对比出这两种消息队列的吞吐性能和功能区分。
1)rabbitmq集群
rabbitmq不是很熟悉的同学可以看下我之前文章的科普知识
rabbitmq之一---消息队列基础
对于rabbitmq是基于erlang这种天生具有分布式特性的语言写的,所以天然的rabbitmq支持 集群化,意思是集群的元数据不需要通过zk来存储,rabbitmq集群的exchange信息会同步到所有节点上,但是Queue的完整信息注意只存在所创建的那个节点上,其他节点只知道指向queue的owner node的指针
那对于这种情况我们思考几个问题:
1,rabbitmq如何实现集群?
rabbitmq集群方式比较简单,
1)修改所有机器的cookie文件为同一个值
2)配置各个节点hosts文件,写入各集群节点hosts
xxx.xxx.xxx.xxx rmq-broker-test-1 xxx.xxx.xxx.xxx rmq-broker-test-2 xxx.xxx.xxx.xxx rmq-broker-test-3 ...... xxx.xxx.xxx.xxx rmq-broker-test-10
3)启动各节点,以一个为主节点,其他逐一加入
rabbitmqctl stop_app rabbitmqctl reset rabbitmqctl join_cluster rabbit@rmq-broker-test-2 rabbitmqctl start_app
2,rabbitmq各节点角色?
rabbitmq节点有两种角色:内存节点,磁盘节点。为了持久化和高可用,必须保证两个以上的磁盘节点,防止一个崩溃导致数据丢失。
3,如何实现负载均衡?
我们刚才讲到每个队列只有自己的完整信息,通过集群中的其他节点来访问另一个节点的队列时,会被转发到原来的队列进行消费,所以原来的集群方式无法实现负载均衡。那这样要提高吞吐量的需要通过第三方负载均衡器来帮助,我们可以使用HAProxy来辅助实现负载均衡
listen rabbitmq_cluster bind 0.0.0.0:5672 #配置TCP模式 mode tcp #加权轮询 balance roundrobin #RabbitMQ集群节点配置,其中ip1~ip4为RabbitMQ集群节点ip地址 server rmq_node1 ip1:5672 check inter 5000 rise 2 fall 3 weight 1 server rmq_node2 ip2:5672 check inter 5000 rise 2 fall 3 weight 1 server rmq_node3 ip3:5672 check inter 5000 rise 2 fall 3 weight 1 server rmq_node4 ip4:5672 check inter 5000 rise 2 fall 3 weight 1 ......
通过这种加权轮询各个rabbitmq节点实现负载均衡提高单位时间吞吐量。
2)kafka集群
对于kafka而言因为它的设计目标就是高吞吐量,所以我们来看看kafka的集群方式如何配置:
1,配置zookeeper。kafka集群的元数据都得通过zookeeper来进行保存,通过zk来调配之间节点的状态,节点是无状态的。
2,kafka节点启动,注意配置连接zk端口。
接下来我们来看看kafka为了实现高吞吐量,高可用使用了什么架构
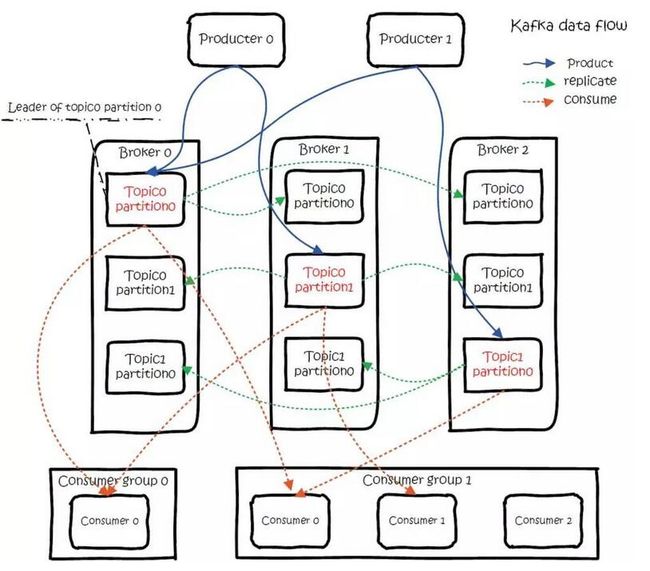
如图所示,生产者会按照主题(topic)投递到kafka集群。然后消费者按照指定的topic去消费。
那么这种方式就非常方便我们实现
1,高吞吐量:将一个主题划分到多个broker,在每个broker存放一个partition(分区),那么通过多节点可以顺利实现吞吐量的提高
2,高可用:指定partition(分区)的备份个数,即副本数,实现数据的冗余备份。
三,分布式理论
通过科普了两种分布式理论后我们思考下不同中间件的设计出发点,从而更能明白其分布式集群设计。
1) CAP理论
CAP理论告诉我们:一个分布式系统不可能同时满足一致性(C:Consistency)、可用性(A:Availability)和分区容错性(P:Partition tolerance)这三个基本需求,最多只能同时满足其中两项
由于这三者无法全部实现,可以实现为:
| 选择 | 说 明 |
| CA | 放弃分区容错性,加强一致性和可用性,其实就是传统的单机数据库的选择 |
| AP | 放弃一致性(这里说的一致性是强一致性),追求分区容错性和可用性,这是很多分布式系统设计时的选择,例如很多NoSQL系统就是如此 |
| CP | 放弃可用性,追求一致性和分区容错性,基本不会选择,网络问题会直接让整个系统不可用 |
2)BASE理论
BASE是Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)
BASE理论的核心思想是:即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性
- 基本可用:指分布式系统在出现不可预知故障的时候,允许损失部分可用性
- 软状态:允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性
- 最终一致性:最终一致性强调的是所有的数据副本,在经过一段时间的同步之后,最终都能够达到一个一致的状态
四,分布式集群分析及总结
我简单介绍了zookeeper集群,redis集群,rabbitmq集群,kafka集群的构建等内容,那我们思考下对于集群化设计注意事项和思考点,为我们去分析和了解各种集群应用做个知识铺垫。
- 1,zookeeper出身就是作为分布式协调系统,系统着重于维护分布式集群的各种情形:集群间节点主从关系,新增节点,节点宕机等分布式常见情况,数据量请求不大。
- 2,redis作为一个nosql,由于redis强调内存读写性能,讲究一个字:快。而cluster集群模式是redis3.0才推出的,所以其实前期有各种公司出proxy方案用于配合redis,如推特的twenty,豌豆荚的codis方案。
- 3,rabbitmq出身于金融领域,所以更加强调消息可靠性,有各种实现可靠性方案,所以我们注意到如果需要加强吞吐量得使用负载均衡器来辅助实现,使用erlang也使其自带分布式。
- 4,kakfa而言,目标是一个高吞吐量的分布式发布订阅消息系统,为日志而生,所以天生就带有各种分区,多副本。但是需要zk来辅助管理集群化。
然后我们其实可以看了CAP理论,BASE理论后我们思考,因为不能将一个分布式系统做到完全的满足CAP,必然选择性放弃一部分,我们看看这几种分布式中间件集群方案如何考虑:
- zookeeper,高度强调可用性,你能想象一个负责动物园管理员倒下的日子么?其他动物岂不是得无法无天了。所以他有一套基于ZAB的分布式协调方案,他就不强调中心化,允许动物园的动物们去跟“从管理员”打交道,读数据不强调需要跟动物管理员老大打报告,虽然带来一定的数据不一致性(存在写数据需要传播到整个集群的过程),但是保证了高可用,当然也是因为zk的写请求不大,所以一定的数据延迟带来的不一致是允许的。
- redis,强调数据的读写速率,所以他的cluster集群方案用了一种去中心化方案。先分槽,让多个主节点去分散的承担读写任务,然后从节点只作为数据备份(读写分离一般少设计),因为它认为通过内存的随机读写速度已经足够快满足用户需求,也保证数据的一致性,当然对于异常情况如主节点倒下时,也模拟了选举方式,然后尽量选择数据和主节点最接近的从节点来保证数据的相对一致性。
- rabbitmq,强调可靠性,1)数据可靠。所以集群化设计时,如果你设置消息要落盘持久化时,他会等磁盘节点写入成功才返回OK,即使内存节点已经可以进行操作,为了提高吞吐量的话需要通过HAProxy负载均衡,但是也会受限于磁盘写入速度。2)系统可靠,假如存在异常情况,主节点挂掉,由于rabbitmq是天然支持分布式的,自然会从 从节点来代替主节点工作,不需要经过什么选举过程,系统恢复工作速率更快。
- kafka,强调高吞吐量。kafka集群系统通过zk来进行集群管理,使用分区来实现一个topic在多个broker中入队,然后也可以通过多副本在多broker中存储备份,所以你会注意到多副本下的几个broker是基本镜像一样,那么如果发生一个节点异常,那么直接通过ZK来选举出一个来代替即可。
欢迎观看,可以点赞支持哈。