论文分享(一) CVPR 2018 Defense against Universal Adversarial Perturbations
论文链接:https://arxiv.org/abs/1711.05929
前言
进入研究生阶段的学习已经一年多了,在此期间阅读了不少论文,也大都有做下一些笔记。然而,出于自己的惰性,一直没有系统的将它们整理归纳起来。因此,从今天开始希望以每天一篇论文讲解的形式将自己过往阅读过的,感兴趣的,项目中所用到过的论文在博客上进行一次梳理。所谓温故而知新,在梳理的同时期许自己能够有新的收获,和大家一同成长。
一.介绍
今天要讲的这篇文章是针对普遍对抗扰动(universal adversarial pertubations)的防御,时间相对有点久了,发表在2018年的CVPR上。首先,我们知道单张图片的对抗扰动,简单一点理解,就是指针对某一张图片我们通过训练添加一些所生成的特定噪声(即扰动),可以使得分类器将这张图片进行错误的识别分类。那么,什么是普遍对抗扰动呢?概括性的说,它具有以下两个特性:
1.顾名思义,这个扰动是针对所有输入图片都可以添加的,具有普遍性。也就是说添加的这个扰动是否能够使分类器错误分类,和所输入的图片无关,仅和模型本身有关。
2.这种扰动还是非常微小的,近乎不可察觉的。即,添加了扰动之后的图片和原始图片相比失真程度很低,并没有改变原始图片的结构。
不同于之前的攻击,如:FGSM,DeepFool等方法只能生成针对单张图片的对抗扰动,这种新的攻击方式(即,普遍对抗扰动 (Seyed-Mohsen et al.,2017):https://arxiv.org/abs/1610.08401)能生成对任何图像实现攻击的扰动。这一方面展示了愚弄深层网络的可能性,另一方面由于之前大多工作针对单张图像的对抗扰动,目前还没有专门的技术来保护网络免受普遍的对抗性扰动,这是本文所要解决的核心问题。
二.基本流程
接下来基本流程的讲解将从下面公式和具体框架两个角度去叙述,还需要注意的是在下面的叙述中默认将普遍对抗扰动读作扰动ρ。
2.1 问题公式化
先通过公式对基本流程有一个了解,已知Ic是原始数据集中某个分类c下的一张图片,C(.)是一个分类器(即目标网络):
![]()
现在定义一个向量ρ∈Rd,是对于分类器C(.)来说的一个普遍对抗扰动,它应满足下面的约束条件:
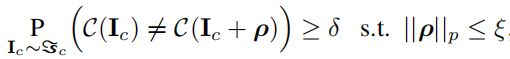
其中,δ表示人为设定的愚弄率,对扰动ρ有一个限制条件:ρ的p范数值需要小于等于预定义的常数值ξ。
在论文的实验中将δ设置为0.8, 扰动则限制为l2范数和无穷范数,其设置的常数柯西值分别为2000和10,这两个值的设定是由实验所用图片的相应范数值所选取的,为图片相应范数的4%,保证扰动是近乎不可察觉的。
现在问题来了,如果我们上面训练的扰动达到了我们预期的效果,添加到图片上,将会以80%的愚弄率来欺骗网络。关键时刻,当然需要我们提出的防御方法登场来英雄救美啦~
为了使得分类器C(.)能够不被扰动所愚弄,论文所提出的防御机制分为两个部分:
1.扰动“检测器”:一个二分类的检测,检测未知的图片是原始图片还是添加扰动的图片。公式表达如下:
![]()
2.扰动“校正器”:
![]()
校正器的目的是将添加扰动的原始图片转换为I^,使得:
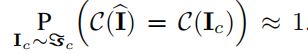
也就是使目标网络对这个I^的识别率与对原始图片Ic的识别率是近乎一致的,这样就能够达到防御的效果。
2.2 基本框架
接下来,我们从图片的角度来更加透彻的了解一下该防御框架。该防御框架简单的由两部分组成:”校正器”(PRN)和“检测器”。同时使用真实扰动和合成扰动进行训练。下图显示了该学习防御框架的“校正器”和“检测器”组件的方法的示意图。

训练过程:从原始图片中先计算出与图像无关的原始扰动,再基于原始扰动计算生成更多的合成扰动。原始图片和添加扰动后的图片都会被送到PRN中去。接下来,将PRN与目标网络的第一层相连接,进行学习,目标网络的参数在PRN训练过程中保持不变,仅对PRN参数进行调整。干扰检测器从PRN的输入和输出之间的差异中提取判别特征,并学习二元分类器。
测试过程:比如,对一个看不见的测试图片I进行分类测试,首先通过检测器进行检测,如果检测到存在扰动,则校正器的输出结果就作为分类器(目标网络)的输入而不是真正的测试图片I作为输入。
三.具体实现
简单的将整个防御机制叙述一遍之后,接下来,我们具体到每一个部分。
3.1 扰动“校正器”——PRN
3.1.1 公式化理解
论文所提出的防御方法的核心是扰动校正网络(PRN),它作为目标网络分类器的预输入层进行训练。将PRN连接到分类网络的第一层,组成的联合网络被用来训练最小化下面的函数:

ℓi*和ℓi是由联合网络和目标网络分别预测的标签,其中ℓi是目标网络对原始图片的预测结果。对于N个训练样本,L(.)计算损失,而θp和bp表示PRN的权重和偏置参数。
3.1.2 PRN优点
那么,PRN的优点体现在什么地方呢?
1.在上式中,只对PRN的参数进行调整,这确保无需对(已部署的)目标网络做任何改动。不同于现有的防御技术,如:通过对抗训练来更新目标模型、或是将架构更改合并到目标网络等。
2.该防御机制还起到充当目标网络的外部包装器的作用,使得训练好的PRN(和检测器)可以具有很好的保密性,以避免潜在的反击攻击。
3.1.3 训练PRN
神经网络模型:PRN的实现是由5个卷积层夹在中间的resnet块组成的,每个块由两个含有ReLU激活函数的卷积层组成。
利用交叉熵损失训练PRN:第一个和第二个矩估计的指数衰减率分别设置为0.9和0.999。且将初始学习率设置为0.01,每1000次迭代后衰减10%。该项目使用mini-batch的大小为64,对于给定的目标网络,PRN至少要进行5 个epochs的训练。
3.2 训练数据
该方法使用原始图像和在原始图像上添加扰动形成的对抗样本对PRN进行训练。生成的扰动分为原始扰动和合成的扰动:
3.2.1 原始扰动的求解
以迭代的方式来计算一个普遍的扰动。首先,在内部循环中,通过给前一次计算出的ρ值增加寻找向量并反映射合成向量到半径为ξ的p范数球上(the ℓp ball)来更新ρ的值。外部的循环则来确保在整个训练集上可以达到所期望的愚弄率。当满足条件时,将此时ρ的值放入集合p中。
3.2.2 合成扰动的求解:
在训练图片的基础上,更多的对抗训练有助于PRN表现的更好,但是用上面的算法来生成大量的扰动在计算量上是不可行的。因此,需要设计一个机制来有效的生成合成扰动ρs为训练增加扰动。 该方法通过利用上述原始扰动中求解出的ρ的集合(即集合p)来计算合成扰动。
在获得扰动这一块,原始扰动的求解不是本文扰动求解的核心,因为是参照的Seyed-Mohsen et al的论文“universal adversarial perturbations”中所提出的方法(论文链接上面有给出),在论文中作者对这个方法也并没有耗费过多的笔墨。因此合成扰动的求解是本文着重想要去叙述的。
为了生成合成扰动,需要满足以下几个条件:
C1:
![]()
即扰动ρs属于集合p中元素张成的子空间的正象限。
C2:合成扰动的l2范数要与p中某个原始扰动的l2范数值相当。
C3:合成扰动的无穷范数要与设定的常数值ξ相当。
用来计算基于无穷范数的合成扰动的算法在下面展示了出来,通过参考下面的程序也可以得到相应的算法计算L2范数扰动。

上边的算法以小随机步长,在由P中元素单位向量所控制的方向上,逐步搜索满足上述C1条件集合中的ρs,当ρs的无穷范数保持小于ξ时停止搜索。如果向量ρs的l2范数值>=p集合中的最小临界值,那么此时的ρs就可以作为一个合成扰动。
为什么这个算法搜索的方向为,p中元素单位向量所控的方向呢,这里的原理同样来自于,提出原始扰动求解方法的那篇论文。在分析深层网络对抗普遍对抗干扰的鲁棒性时,该论文展示了共享方向(shared directions)的存在,沿着这些方向,由一个网络引起的决策边界会变得高度正向弯曲。同样的,沿着这些易受攻击的方向,微小的普遍扰动的存在可以愚弄网络来改变它对这些数据点标签的预测。文中所用到的算法寻找合成的扰动就是沿着这些方向,而这些所期望的方向的来源就是从p(moosavi方法所产生的原始扰动集合)中获得的。
3.2.3 生成合成扰动的效果
下图展示了典型的ℓ2和ℓ∞范数产生的合成扰动。它还显示了在给定扰动下集合P中相应的最接近匹配。合成扰动的愚弄比一般不像原始扰动那么高,但其值仍然在可接受的范围内。
以图中的l2范数约束下生成的扰动来看,原始扰动的愚弄比在0.8,而合成扰动的愚弄比在0.67,这个愚弄比已经可以很好的对目标网络进行愚弄。
一旦计算了一组合成扰动ρs,就将该扰动添加到原始扰动集合中去,形成一个新的集合,并使用它来扰动训练数据中的图像。
3.3 扰动检测器
在细致的分析过PRN以及如何获取大量的训练数据之后, 我们来介绍一下扰动检测器。论文提出的扰动检测器利用DCT(离散余弦变换)来检测扰动。使用包含原始和扰动的图片来训练,即
![]()
1.首先计算下面这个式子:
![]()
括号中所取的实际上是两个灰度图像中的2D-DCT这个系数的值,F(.)函数来求这两个值差的对数的绝对值。
2.学习二元分类器B (F)→[0, 1],标签表示输入的图像是“原始的”或“扰动的“,B(.)通过SVM函数来学习。
3.函数D(.) = B(F(.))构成了防御框架的检测器组件。
四.实验
实验通过抵御在caffeNet、VGG-F网络和GoogLeNet上的普遍扰动攻击来评估其技术的性能的,使用ILSVRC 2012验证集来进行实验。
4.1 设置
对于每个网络,从可用的图像中,随机选择10000个样本来生成50个与图像无关的扰动。生成的扰动中一半将其约束为无穷范数值=10,另一半则约束为l2范数值=2000。扰动的愚弄比以0.8为下限,在两个相同类型的扰动之间最大点积和以0.15为上界。从每组的25个扰动中,选取20个用于训练,其余5个扰动用于测试。
4.2 训练数据
1.扰动集合的生成:在生成的原始扰动的基础上,使用之前所讨论的生成合成扰动的方法来对扰动集合p进行了扩展。使得两个扩展集中都具有250个扰动,记作p∞和p2。
2.训练样本的生成:首先从现有图片中随机抽取40000个样本,并对每张图片的5个角落(5 corner crops)进行裁剪,得到200000个样本。随后,将p2集合中的扰动以50%的概率随机添加到样本中去,这样分别得到10000张原始图片和l2范数扰动的对抗样本图片,用来训练。重复这个过程,使用p∞来训练无穷范数扰动。
4.3 测试数据
实验使用了两个方案来生成测试数据。为了模拟已部署网络的真实环境,两种方案都使用了不可见的10000张图像,这些图像被5种不可见的测试扰动所扰动。
方案A(prot-A)*:使用了整个10,000张测试图像,并以50%的概率随机地用5个测试扰动破坏它们。
方案B(prot-B):选择10,000个测试图像中被目标网络正确分类为“原始图片”的子集来测试,用与方案A同样的方式来破坏该子集。
4.4 评估指标
评估指标:使用了四个不同的指标来全面分析我们的技术的性能。让lc和Iρ表示分别包含原始和扰动图片的集合。同样,让Ip^ 和Ip/c^作为包含PRN校正过的测试图片集合, 在Ip/c^ 中的所有图片都是经过扰动的(在经过PRN校正前),在 中的原始图片在校正前以50%的概率进行了随机的扰动,对于每一个方案。使I*为包含测试图像的集合,其中每幅图像只有在被检测器D分类为扰动的情况下才被PRN校正。此外,设acc(.)为计算目标网络对给定图像集的预测精度的函数。在实验中使用的度量标准的正式定义如下:

度量的名称与它们相关联的语义概念相一致。注意,PRN恢复是在对原始的和受扰动的图像进行校正的基础上定义的。这样做是为了补偿由于PRN对原始图像进行校正而导致目标网络分类精度的任何损失。在实验中观察到,对原始的图像进行不必要的校正,有时会导致目标网络的分类精度降低1 - 2%。因此,论文使用了一个更严格的定义来P为了一个更透明的评估。这个定义也符合我们对实际场景的基本假设,在实际场景中,是不知道测试图像是干净的还是受到干扰的。
对上面的度量更准确理解一下:
1.PRN的校正性能
2.PRN的复原率,这里需要解释一下这个复原率,它实际上是指有时候PRN可能会错误地对原始图片进行校正,导致最后目标网络的分类精度有所下降,复原率越高,表示PRN对目标网络的分类影响越小
3.检测率,对扰动图片和原始图片的的区分性能
4.抵御率,在经过检测器和校正器之后,识别的准确率性能的评价
4.5 相同/交叉规范评估
在下面的表格中,总结了保护GoogLeNet免受干扰的实验结果。该表总结了两种实验。即,实验1:测试和训练用相同的扰动,实验2:测试和训练使用不同的扰动。对于后面的两个网络使用的是类似的实验。表中提到的扰动类型是作为测试数据时所使用的类型。

Prot-A和Prot-B框架的性能差异与目标网络在原始图像上的准确性有关。对于一个对原始图像100%准确的网络,Prot-A和Prot-B下的结果将完全匹配。从后面的表中也可以明显看出,对于不太精确的分类器,结果会有更大的不同。

利用PRN对扰动后的图像和校正后的图像进行可视化的典型例子如下图所示:
以googlenet网络上的这张图片为例,在添加了扰动未经校正之前,googlenet将这张图片分类为“paper towel”,而在进行过PRN的校正之后,它能以较高的confidence将图片正确分类为“beacon”。
4.6 泛化能力
通过使用方案A在相同的测试/训练扰动类型的情况下测试防御框架的性能。从表中,可以得出结论,所提出框架可以很好地跨不同的网络进行泛化,特别是跨具有(相对)相似架构的网络。
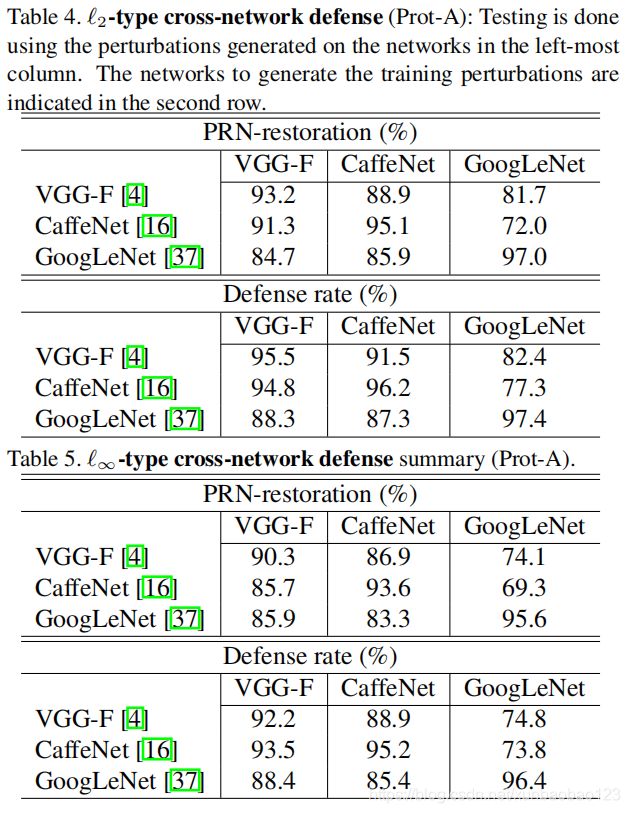
在对防御机制的性能进行测试后,实验还对其泛化能力进行了考量。这张表中,最左边一栏的网络是用来生成测试所需的扰动,上面一栏的网络是用来生成训练时所用的扰动。
五.总结
文章提出了第一个专门针对普遍的对抗性扰动的防御。本文的主要贡献如下:
1.提出了一种将PRN作为目标网络模型的“预输入”进行训练的方法,目标网络不需要进行改动。
2.提出了一种有效的计算合成的与图像无关的对抗性扰动的方法,来有效地训练PRN。
3.提出了一个从图像校正器(PRN)的离散余弦变换学习来的检测器,来区分经过扰动的图片和原始图片。
后记
回过头来再看自己当时的笔记与一些思考真的会又有新的理解,一篇论文读下来又感觉收获了满满的崭新的知识点,体现在哪儿呢?我罗里吧嗦的码了好多的字!!!嗯,系统的将自己读过的论文梳理,就好像将一篇论文真正的装入了自己的小口袋里。首尾呼应一下,期望本人以后戒除惰性,争取养成每读一篇论文都做好梳理总结的习惯。
温故知新:
留给有空回过头来再看一遍论文的自己