第一学期对于液质、气相处理过程的总结
写在前面
这篇博客是我在泽哥的鼓励下,对本学期在西北农林科技大学园艺学院304的试验内容的一个总结。同时我也觉得在液质、气质等一些由仪器标准化输出报告的试验中,非常适合引入程序脚本去处理试验结果。这样的话,能够大大减少试验员的时间,让他们有更多的时间去投入到价值更高的工作中去。
对样品编号过程的优化
问题背景:
在样品编号时,由于软件提供的自增工具(Autoincrement),只能适用于数字或着最后一位为数字的情况。但是在试验里,样品命名中至少都会包含两个以上的变量,而且在命名是如果仅仅使用数字时,对于不同样品的区分也不够直观。
解决方法:
通常列表的分割符号是“\n”,因此只需要使用在将样品命名提前命名好,然后样品名字用“\n”拼接,即可直接复制到excel、analyst和multiquant等软件,大大节约了在操作软件是样品名称不直观和样品名称输入时间太长的问题。
python代码实现:
#trial_name.py
import pyperclip
from itertools import product
name_formula = input("名称公式:")
#统计变量的个数
var_num = name_formula.count("{}")
#把{}替换为%s,以列表和元组的形式填充字符串
name_formula = name_formula.replace('{}', '%s')
factors = []
for i in range(0, var_num):
factor = input("变量{}的范围:".format(i+1))
if "-" in factor:
li = [chr(i) for i in range(ord(factor[0]), ord(factor[-1])+1)]
factors.append(li)
elif ',' in factor:
li = factor.split(',')
factors.append(li)
text =""
#排列组合
for i in product(*factors):
#结果拼接
text = text + name_formula%i +"\n"
#将结果写入剪贴板
pyperclip.copy(text)
示例:

上述程序使用要点:
- 每一个{}代表一个变量,{}可以出现在公式的任何位置;
- 变量范围输入有两种,①用”-“连接,通过ASCII自增的方式创建变量列表,意味着可以用字母,阿拉伯数字,罗马数字等,只要ASCII相近的字符都可以使用;②用”,“分隔,该方法必须穷举出该变量所有的值,这种方法繁琐,但具有普适性。
液相质谱仪docx报告的数据提取
问题背景:
此处定位西北农林科技大学园艺学院304液相质谱仪。样品的谱图经过multiquant软件确定峰面积之后,可以导出docx的报告文件。通常我们从这个报告文件通过复制黏贴的方式将数据筛选出来,效率低下,并且报告文件中含有大量图片,导致文档篇幅很长,目标数据分散。
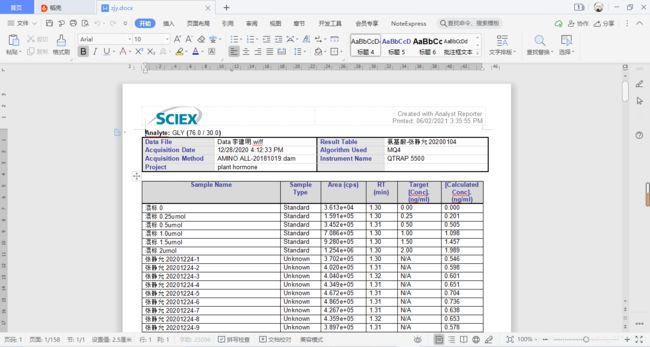
如上图,这是一个含有102个样品的液相质谱报告,报告篇幅达到了158页,由此可见,使用复制黏贴的方式筛选数据无疑是复杂耗时并且效率低下的。
解决方法:
python有一个第三库docx库能够准确的解析docx文件,因此可以用脚本实现数据的筛选。获取文档中的文本后,用正则筛选出检测物质的名称,然后获取文档中的表格筛选出数据,具体方法如下。
r
import argparse
import os
from docx import Document
import re
import pandas as pd
import sys
#设置外部参数,默认获取表格第六列,默认文件输出路径为桌面
parser = argparse.ArgumentParser(description='液相质谱仪docx报告处理.')
parser.add_argument('-i', dest='infile', help='docx报告的文件路径 ',required=True)
parser.add_argument('-o', dest='outfile', help='输出数据文件名 ', required=True)
parser.add_argument('-c', '--column', type=int, choices=[1, 2, 3, 4, 5], help="select the column you want to deal with", default=5)
parser.add_argument('-v', '--path', help="输出文件存放目录", default='C:\\Users\\biashap\\Desktop\\')
args = parser.parse_args()
#判断输入和输出文件的类型
if args.infile[-5:] != ".docx" or args.outfile[-4:] != ".csv":
print("请用-h参数查看,脚本外部参数要求!")
sys.exit()
#判断路径是否存在
if not os.path.exists(args.path):
print("{}, 这个目录不存在!".format(args.path))
sys.exit()
#开始解析文档
document = Document(args.infile)
#从每个段落里获取检测物质的名字
paras = document.paragraphs
subjects = []
for para in paras:
if para.text.strip(' \n') != '':
temp = re.search("Analyte: (.*?)\(",para.text)
subjects.append(temp.group(1))
else:
continue
#获取文档中的表格
tables = document.tables
# 获取所有样品的名称
trials = []
for row in tables[1].rows[1:]:
trials.append(row.cells[0].text)
#筛选出目标数据
result = []
for table in tables[1::len(trials)+2]:
temp = []
for row in table.rows[1:]:
#args.column即为要获取的表格的列
temp.append(row.cells[args.column].text)
result.append(temp)
#将数据构成字典,存入pandas数据框
mydic = dict()
mydic['trials'] = trials
if len(subjects) == len(result):
for i in range(len(subjects)):
mydic[subjects[i]] = result[i]
df = pd.DataFrame(mydic)
#输出数据文件,args.path和args.file拼接输出路径
df.to_csv(args.path+args.outfile, sep=',', index=False)
#数据输出成功信号
print('ok')
else:
#检测数目和筛选出的数据数目不一致,程序执行失败信号,并输出检测物质的数目和筛选结果的数目
print("错误长度不匹配我!", len(subjects), len(result))
运行示例:
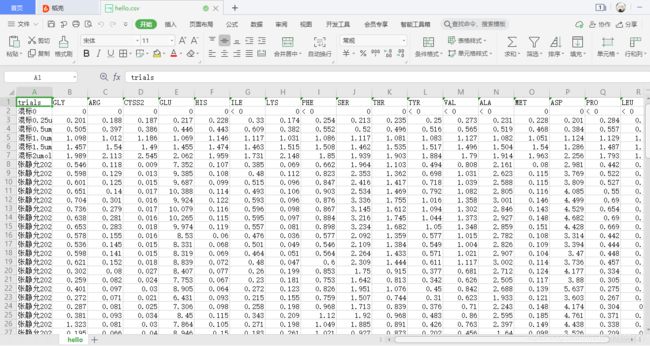
-c和-v都是可选参数,可以通过-h查看各参数的要求。数据整理后的csv文件效果如下图:
气相色谱仪pdf报告的数据提取
问题背景:
此处定位西北农林科技大学园艺学院304气相色谱仪。进行气相色谱试验时,经过软件openLAB的处理,每一个样品的色谱报告会单独写在一个pdf文件中,文件中包含这个样品每个被检测物质的浓度保留时间等信息。虽然该软件也能保存为txt格式,但是操作较为繁琐。由于数据分散在各个文件中,进行聚合整理时,只能单个复制黏贴,非常耗时低效。
解决方法:
openLAB加工的pdf结构简单且没有经过加密,可以被python的pdfplumber库准确的解析,并且数据在pdf文件中以表格的形式呈现,可以使用正则表达式准确的定位和提取。具体方法如下:
1.pdfplumber解析pdf报告并且原文转存为txt
import pdfplumber
import pandas as pd
import sys
import os
#获取目标文件目录和该目录下所有pdf文件
if os.path.exists(sys.argv[1]):
pdf_reports = os.listdir(sys.argv[1])
pdf_reports = [x for x in pdf_reports if x[-4:] == '.pdf']
if not pdf_reports:
raise Exception('该目录下没有pdf报告!')
else:
raise Exception('这个目录不存在!')
# 核验输出路径的有效性
if sys.argv[2][-1] != '/':
raise Exception('the s')
else:
if not os.path.exists(sys.argv[2]):
os.mkdir(sys.argv[2])
#提取pdf信息并转存为txt文件
for report in pdf_reports:
with pdfplumber.open(sys.argv[1]+report) as pdf:
content = ''
#len(pdf.pages)为PDF文档页数
for i in range(len(pdf.pages)):
#pdf.pages[i] 是读取PDF文档第i+1页
page = pdf.pages[i]
#page.extract_text()函数即读取文本内容,下面这步是去掉文档最下面的页码
page_content = '\n'.join(page.extract_text().split('\n')[2:-1])
content = content + page_content + '\n'
f = open(sys.argv[2]+report.replace('.pdf', '.txt'), 'w')
f.write(content)
f.close()
2.从txt文本中提取出数据信息
import argparse
import re
import pandas as pd
import os
parser = argparse.ArgumentParser(description="从txt文本中提取信息.")
parser.add_argument('-i', '--indir', help="txt报告存在目录", required=True)
parser.add_argument('-o', "--outfile", help="输出数据文件目录")
args = parser.parse_args()
if os.path.exists(args.indir):
txt_reports = os.listdir(args.indir)
txt_reports = [x for x in txt_reports if x[-4:] == '.txt']
if not txt_reports:
raise Exception("该目录下没有报告文件!")
else:
raise Exception("该文件路径不存在")
#
f = open(args.indir+txt_reports[0])
temp = re.search("(-+\|)+-+\s?(.*?)(=+)", f.read(), re.S)
data_tab = temp.group()
data_tab = data_tab.split('\n')[1:-4]
for i in data_tab[::-1]:
if ("[" in i) or ("保留时间" in i) or ("-" in i and "|" in i):
data_tab.remove(i)
data_tab = [(' '.join(x.split()).split()) for x in data_tab]
df = pd.DataFrame(data_tab)
df = df.loc[:,5]
wanted = pd.DataFrame(columns=df)
wanted.insert(loc=0, column='trial', value="")
#
for report in txt_reports:
f = open(args.indir+report, 'r')
temp = re.search("(-+\|)+-+\s?(.*?)(=+)", f.read(), re.S)
data_tab = temp.group()
data_tab = data_tab.split('\n')[1:-4]
for i in data_tab[::-1]:
if ('[' in i) or ("保留" in i) or ("-" in i and "|" in i):
data_tab.remove(i)
data_tab = [(' '.join(x.split()).split()) for x in data_tab]
df = pd.DataFrame(data_tab)
df = df.loc[:,(4,5)]
df.set_index(5, inplace=True)
df =df.T
df.insert(loc=0,column='trial', value=report[:-4])
wanted = wanted.append(df)
wanted.to_csv(args.outfile, sep=',')
数据处理
在获得试验数据后,由于经常会设置3个以上的重复,并且重复之间还存在一定的数据波动,这些重复处理和重复间的波动会影响试验员对于数据质量和趋势的判断。如果能够在第一时间,将数据整理成为平均值和方差的形式,那么数据的展现会更加的直观,均值的变化体现数据的趋势,方差则体现了数据的质量。另外,数据这样处理之后非常便于后续的绘图工作,以excel举例。个人认为excel绘制带误差线的柱状图和条形图是非常麻烦的,需要另外计算出方差(不过本人excel技术也非常的烂,所以这里说的可能不对,毕竟excel实在是一个强大的软件)。因此计算出数据的均值和方差,无论后期制表还是绘图都有帮助。另外,试验数据的存储大多非常标准,这意味着非常便于计算机程序的处理。下面是我的实现方法:
import sys
import numpy as np
import pandas as pd
import argparse
import os
#设置数据精度
pd.set_option('precision', 2)
parser = argparse.ArgumentParser(description="这是一个计算数据平均值和方差的函数.")
parser.add_argument('-i', '--infile', help="输入文件路径", required=True)
parser.add_argument('-o', '--outdir', help="输出文件的存放路径", required=True)
parser.add_argument('-f', '--formula', help="数据文件中数据的处理公式")
args = parser.parse_args()
print(args.formula)
if args.infile[-4:] != '.csv':
print("输入文件不是一个csv文件!")
sys.exit()
if args.outdir[-1] != '/' :
print("输出文件不是一个目录!")
sys.exit()
else:
if not os.path.exists(args.outdir):
print("输出文件存放目录不存在,请先创建!")
sys.exit()
df = pd.read_table(args.infile,sep=',')
#去除样品名称中的重复序号
df.trial = df.trial.apply(func = lambda x:x[:-2])
df.set_index('trial', inplace=True)
if args.formula:
args.formula = args.formula.replace('x', 'df')
args.formula = args.formula[2:]
df = eval(args.formula)
grouped = df.groupby(by=['trial'])
mean = ["np.mean" for i in df.columns]
mean = dict(zip(df.columns, mean))
data_mean = grouped.aggregate({
key:eval(value) for key,value in mean.items()}).round(2)
data_mean.to_csv(args.outdir+"data_mean.csv", sep=',')
std = ["np.std" for i in df.columns]
std = dict(zip(df.columns, std))
data_std = grouped.aggregate({
key:eval(value) for key, value in std.items()}).round(2)
data_std.to_csv(args.outdir+"data_std.csv",sep=',')
result = data_mean.astype('str') + "±" + data_std.astype('str')
result.to_csv(args.outdir+'result.csv', sep=',')
在这段代码里面,存在一些个性化的设置,例如样品名称列的命名,数据的存储格式和习惯等,格式个人喜欢用csv,存储方式本人喜欢用spss的那种形式。一下是最终结果的效果展示。
原始文件的存储格式:
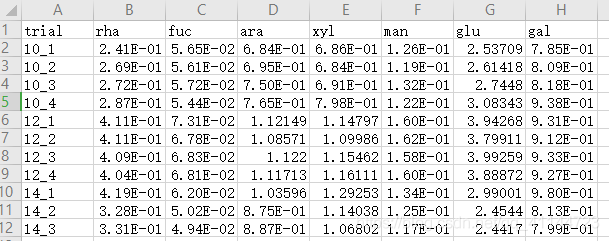
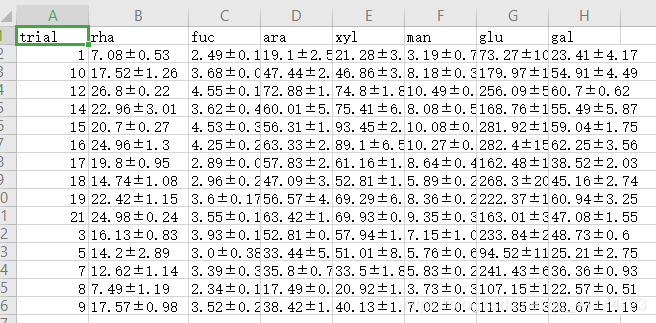
输出的均值和方差形式

最终结果:
展望
- 本博客中提到的一些脚本仍然存在很多个性化的地方,还可以再提高,增强普适性。最好的结果就是同样需求的试验员可以下载后直接使用,渐少大家的数据处理时间和所有研究员总体的重复工作量。
- 在液相质谱仪和气相色谱报告被处理后,可以再编写一个脚本,自动地判断出处理的重复性,设置3%、5%等阈值分别用红、黄、绿作为数据背景,可视化的展现该处理的数据质量。
- 为了更好的服务没有编程基础的试验员,在时间充裕的情况下,可以考虑用PC搭建一个简易的网站,开放API,使得上述脚本可以在网页端直接调用,无需下载和编程环境的配置。并且该网站单次实际访问量很小,PC完全可以满足性能需求,可行性很高。
- 在本学期本人还接触到一种仪器,具体名称我忘记了,好像叫x射线重金属检测仪,该仪器可以同时检测多种重金属元素和一些其他元素,在园艺领域具有很好的应用前景。但是该仪器和气相一样,一个样品生成一个数据报告,并且该报告为工程文件,只能由特定软件打开,加之数据分散度很高,处理难度很大,应该寻求一种更高效的方式解决。
- 我会一直寻找对于试验员来说最高效的方法,将试验员从低价值工作中摆脱出来,是一件极具意义的事情,2021再加油!