Python3爬虫——用BeautifulSoup解析古诗文网
我们之前已经用Xpath分析过了古诗文网,但还是感觉有点麻烦,所以今天来讲BeautifulSoup库,它可以很方便的帮我们抓取网页的数据,同样也支持lxml解析器,下面我们来详细介绍:
安装BeautifulSoup库:
pip install beautifulsoup4导入BeautifulSoup库:
import bs4 # 导入BeautifulSoup整个库
from bs4 import BeautifulSoup # 解析HTML
from bs4 import BeautifulStoneSoup # 解析XML我们首先来创建一个BeautifulSoup对象:
from bs4 import BeautifulSoup
import requests
url = 'https://so.gushiwen.org/authors/authorvsw_b90660e3e492A1.aspx'
result = requests.get(url)
html = result.text
bs = BeautifulSoup(html,'lxml') # 创建BeautifulSoup对象
# BeautifulSoup(解析对象[,解析器][,from_encoding=...])
# 注意,默认使用的是python自带的‘html.parse’解析器,但是官方推荐使用‘lxml’,使用之前需要安装lxml,但是不需要导入库到项目
牛刀小试,先来感受一下:
from bs4 import BeautifulSoup
import requests
url = 'https://so.gushiwen.org/authors/authorvsw_b90660e3e492A1.aspx'
result = requests.get(url)
html = result.text
bs = BeautifulSoup(html,'lxml')
print(bs.title) # title标签的全部内容
print(bs.title.name) # 标签的名字
print(bs.title.string) # 标签里面的内容
print(bs.title.get_text()) # 惊奇的发现跟string的作用一样,那么他们有什么区别呢?
# 我们下面在详细说明
# 输出结果:
#
# 李白的诗词全集_诗集、词集(1180首全)_古诗文网
#
# title
#
# 李白的诗词全集_诗集、词集(1180首全)_古诗文网
#
#
# 李白的诗词全集_诗集、词集(1180首全)_古诗文网
#
# 我们发现,可以通过 bs.标签 来获取标签的内容,但是如果有多个同名的标签的话,就只能返回第一个了,所以这种提取数据的方法不深究,直接上方法,直接向XPath那样来匹配文本:
sons = bs.find_all('div',class_='sons')
for son in sons:
name = son.find('b').string
print(name)
author = son.find('a',href='/authorv_b90660e3e492.aspx').string
print(author)
content = son.find('div',class_='contson').get_text().strip()
print(content)上面这段代码已经完成了古文题目、作者和诗文内容的提取,是不是非常的简单,这一小段代码已经包含了我们常见的用法,下面我们一个一个来分析:
- find_all() 和 find() 两个方法的区别:

我们通过方法的原型定义,发现 find() 这个方法非常不要脸的直接调用了 find_all(),当找到一个数据之后就直接返回了,而 find_all()不断递归调用,直到找到最后一个,所以这两个方法的用法是一样的,参数几乎一模一样,现在大家知道了他们的区别了;
我们看一下他的用法: ,第一个‘div’是标签,第二个class_='sons'(注意这里是class_,这个是BeautifulSoup定义的关键字,不然会和python关键字产生冲突)class_是属性的名字,‘sons’是他的值;
,第一个‘div’是标签,第二个class_='sons'(注意这里是class_,这个是BeautifulSoup定义的关键字,不然会和python关键字产生冲突)class_是属性的名字,‘sons’是他的值; - string和get_text()有什么区别:
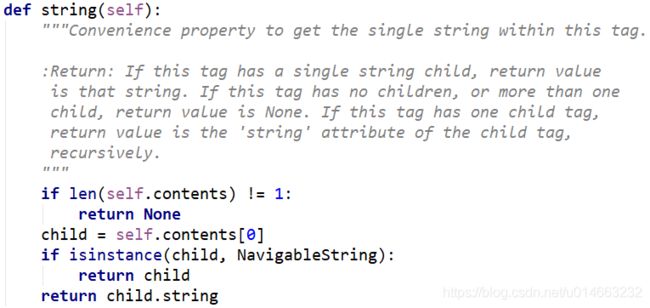
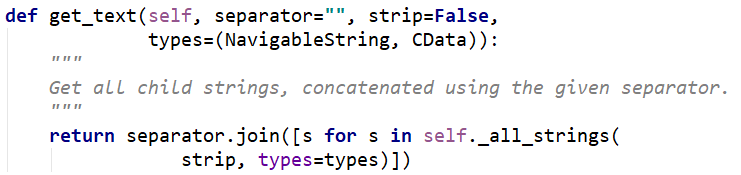
由此我们可以知道,string获得的是标签内的单个字符串,如果不是单个字符串返回的就是None,所以我们要使用get_text()获取所有字符串;总结:get_text()获取的范围更大,get_text()可代替string:
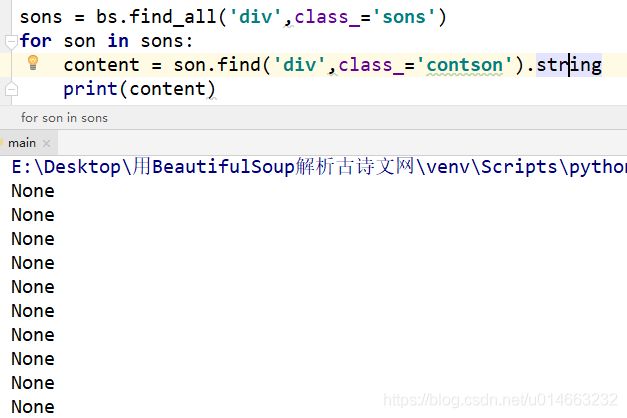
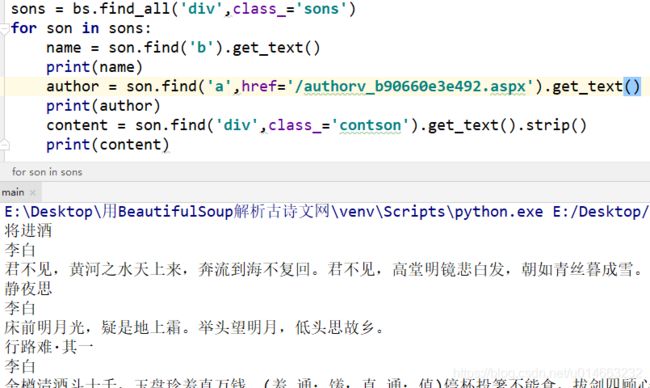
ok,我们最后上源码,BeautifulSoup就先讲到这里,后面有需要再继续补充:
from bs4 import BeautifulSoup
import requests
url = 'https://so.gushiwen.org/authors/authorvsw_b90660e3e492A1.aspx'
result = requests.get(url)
html = result.text
bs = BeautifulSoup(html,'lxml')
sons = bs.find_all('div',class_='sons')
for son in sons:
name = son.find('b').get_text()
print(name)
author = son.find('a',href='/authorv_b90660e3e492.aspx').get_text()
print(author)
content = son.find('div',class_='contson').get_text().strip()
print(content)