day12 Python中的内置函数
day12 Python中的内置函数
文章目录
- day12 Python中的内置函数
-
- 今日内容概要
- 上周内容回顾
- 今日内容详细
-
- 推导式
-
- 列表推导式
- 字典推导式和集合推导式
- 生成器表达式(推导式)
- 内置函数一
-
- `all`函数
- `any`函数
- `callable`函数
- bytes函数
- chr和ord函数
- complex和divmod函数
- eval和exec函数
- frozenset函数
- hash函数
- help函数
- 进制转换函数
- pow函数
- repr函数
- round函数
- abs函数
- format函数
- sum方法
- dir方法
- 内置函数二
-
- 匿名函数
- filter函数
- map函数
- sorted函数
- max和min函数
- reduce函数
- print()函数
- zip函数
- 高阶内置函数比较
今日内容概要
- 推导式
- 内置函数
上周内容回顾
- 迭代器
- 可迭代对象:具有
__iter__()方法的就是一个可迭代对象 - 迭代器:具有
__iter__()和__next__()方法 - 迭代器就是用时间换空间
- 可迭代对象是用空间换时间
- 可迭代对象:具有
- 生成器
- 生成器也是一个迭代器,迭代器不一定是一个生成器
- 迭代器和生成器最大的区别:
- 迭代器是Python提供的
- 生成器是程序员自己编写的
- 迭代器和生成器进行区别:
- 看内存地址
- 生成器有
send()方法,迭代器没有
- next要与yield一一对应
- yield与return比较:
- yield可以有多个,并且都可以被执行
- yield也能返回任意数据类型
- yield也能够返回多个数据,以元组形式接收
- yield不写值也是默认返回None
- yield能够记录执行位置
- yield能够暂停生成器的运行但不会终止其运行
- yield from将数据元素逐个返回
- 生成器和迭代器优点:
- 节省空间
- 生成器和迭代器缺点:
- 不能直接使用元素
- 不能直接查看元素个数
- 时间消耗大
- 一次性的,单向不可逆
- 使用不灵活
今日内容详细
推导式
列表推导式
推导式用来创建一些有规律的可变数据结构,能够让代码变得更加简洁。
比如,我们想要通过循环的方法创建一个数字从1到50的列表,可以这样做:
lst = []
for i in range(1,51):
lst.append(i)
print(lst)
如果使用列表推导式,我们只需要一行代码:
print([i for i in range(1,51)])
我们就成功创建了一个列表推导式。我们还可以运用字符串的格式化实现更多样化的输出:
print([f"Python{i}期" for i in range(1,51)])
前面两种是列表推导式的普通循环模式,它的基本结构为:
[加工后的变量 for循环]
除了普通循环模式,我们还可以通过给循环增加筛选条件,实现筛选模式的列表推导式:
print([i for i in range(1,51) if i > 25])
筛选模式的列表推导式的基本结构为:
[加工后的变量 for循环 加工条件]
列表推导式还支持嵌套。
对于这样一个嵌套的循环:
lst = []
for i in range(2):
for j in range(2):
lst.append(i+j)
print(lst)
改成列表推导式结构就成了这样:
print([i+j for i in range(2) for j in range(2)])
虽然列表推导式能节省很多代码,但是最多建议嵌套三层。
生成器可以让代码更加简化。比如,我们想求字符串"alex,meet"中每个字母e的索引。如果用for循环来写是可以实现的,但是需要多行代码:
s = 'alex,meet'
count = 0
lst = []
for i in s:
if i == 'e':
lst.append(count)
count += 1
print(lst)
输出结果为:[2, 6, 7]
而如果使用列表生成器的话,只需要一行代码即可实现:
print([i for i in range(len(s)) if s[i] == 'e'])
字典推导式和集合推导式
除了列表之外,其他可变数据类型,比如字典字典和集合也可以通过推导式的方法来创建:
# 字典推导式
print({
i:i+1 for i in range(3)}) # 字典推导式普通循环模式
print({
f"Python{i}":i+1 for i in range(3)}) # {变量:变量 for循环}
print({
i:i+1 for i in range(3) if i > 1}) # 字典推导式筛选模式
# {加工后的变量:加工的后的变量 for循环 加工条件}
# 集合推导式
print({
i for i in range(3)}) # 集合推导式普通循环模式 {变量 for循环}
print({
i for i in range(3) if i >2}) # 集合推导式筛选模式
# {加工后的变量 for循环 加工条件}
生成器表达式(推导式)
我们前几天学到的生成器,除了可以通过函数的方式实现,还可以使用表达式来实现。与列表表达式相似,生成器表达式也有普通模式和筛选模式:
# 普通模式:
g = (i for i in range(3))
# 筛选模式:
g = (i for i in range(3) if i + 1 == 2)
生成器推导式的好处有三个:简化代码,提高逼格和提高可读性。
同列表表达式一样,生成器推导式用于生成一些有规律的数据。当我们需要生成的数据较大时,建议使用生成器推导式。
内置函数一
all函数
all函数用来判断可迭代对象中是否所有的元素都为True:
print(all([1,2,32,43,5]))
输出的结果为:True
any函数
any函数与用来判断可迭代对象中的元素是否有一个为True:
print(any([1,2,3,0,1,0]))
输出的结果为:True
callable函数
callable函数用来判断变量是否可以被调用:
def func():
pass
print(callable(func))
输出的结果为:True
bytes函数
bytes函数可以将字符串编码为二进制形式,它的功能和字符串的.encode()方法十分类似,更推荐使用.encode()方法:
print('你好'.encode('utf-8'))
print(bytes('你好', encoding='utf-8'))
输出的结果为:
b'\xe4\xbd\xa0\xe5\xa5\xbd'
b'\xe4\xbd\xa0\xe5\xa5\xbd'
chr和ord函数
chr函数根据当前编码(Python3中为Unicode)解码为字符,ord为chr方法的逆运算,用来将字符编码为数字:
print(chr(20320))
print(ord('你'))
输出的结果为:
你
20320
complex和divmod函数
这两个函数用来进行计算。complex函数用来将一对数字转换为复数形式,第一个数作为复数的实部,第二个数为复数的虚部:
print(complex(20, 3))
输出的结果为:(20+3j)
divmode函数会将一对数字做商,第一个数字做被除数,第二个数字做除数,返回值为一个元组,元组的第一个元素是商,第二个数字是余数:
print(divmod(20, 3))
输出的结果为:(6, 2)
eval和exec函数
这两个函数用来将字符串中的代码转换成可执行的状态。其中,eval函数可以转换一行代码,exec函数可以转换多行代码:
msg = 'print(1)'
eval(msg)
msg2 = """ # 禁用
def func():
print("太厉害了")
func()
"""
exec(msg2)
输出的结果为:
1
太厉害了
但是这两个函数在日后的编程中是被禁止使用的,因为有可能会出现被恶意注入的Bug。
frozenset函数
frozenset可以生成一个冻结的不可变的集合:
dic = {
frozenset({
1, 2, 3, 4}): 1}
print(dic)
输出的结果为:{
frozenset({
1, 2, 3, 4}): 1}
既然能做字典的键,就说明冻结集合是一个不可变数据。
hash函数
hash函数用来判断一个数据是否可哈希。如果可哈希,会返回该数据的哈希值;如果不可哈希,会报错:
print(hash('12'))
print(hash(12))
print(hash(True))
# print(hash([1, 2]))
print(hash((1, 2)))
# print(hash({1: 2}))
# print(hash({1, 2}))
help函数
help函数可以查看帮助信息:
help(list) # 使用help函数不需要打印
进制转换函数
bin、oct和hex三个函数分别能将十进制数转换为二进制、八进制和十六进制数;int方法则能将各种进制数转换为十进制数:
print(bin(10))
print(oct(10))
print(hex(30))
print(int('0x1e', 16)) # 将十六进制数转为十进制,0x可以不加
print(int('1e', 16))
print(int('0o11', 8))
print(int('0b11', 2))
输出的结果为:
0b1010
0o12
0x1e
30
30
9
3
pow函数
pow函数用来进行幂运算,返回的结果是前一个数的后一个数次幂:
print(pow(3, 4)) # 3 ** 4
输出的结果为:81
repr函数
repr函数用来显示打印出来的字符串两端的双引号,即令字符串原形毕露:
print('123')
print(repr('123'))
输出的结果为:
123
'123'
round函数
round函数用来将小数取整,取整规则是四舍六入五成双,也可以指定保留的小数位数:
print(round(3.4))
print(round(3.5))
print(round(3.6))
print(round(4.4))
print(round(4.5))
print(round(4.6))
print(round(3.14159265397932384626, 3))
输出的结果为:
3
4
4
4
4
5
3.142
abs函数
abs用来求数字的绝对值:
print(abs(-6))
format函数
format函数用来格式化字符串,与字符串的.center()方法类似:
s = '你好'
s1 = format(s, '>20') # 靠右
s2 = format(s, '<20') # 靠左
s3 = format(s, '^20') # 居中
print(s1, s2, s3, sep='\n')
输出的结果为:
你好
你好
你好
format也可以用来进行数字的进制转换:
s = 18
print(format(s, '08b')) # 08的意思是总共八位,不足的用0补齐,b指的是要转换为二进制bin
print(format(s, '08o')) # oct
print(format(s, '08x')) # hex
print(format(s, '08d')) # decimal
输出的结果为:
00010010
00000022
00000012
00000018
format方法对于转换ip地址会很有用。
sum方法
sum方法用来求一个可迭代对象中元素的总和:
print(sum[1, 2, 3, 4])
dir方法
dir方法用来查看当前对象有哪些方法:
print(dir(list))
内置函数二
这一部分主要是一些Python中内置的高阶函数。所谓的高阶函数,就是以函数为参数的函数。
匿名函数
匿名函数的关键字是lambda。匿名函数在高阶函数中应用十分广泛,它能极大地简化代码。
比如这个经典的函数定义和调用的代码:
def func(a, b):
c = a + b
return c
print(func(1, 2))
如果使用匿名函数,只需要两行代码即可:
f = lambda a, b: a + b
print(f(1, 2))
甚至一行代码就能实现:
print((lambda a, b: a + b)(1, 2))
在上面的代码中:
- lambda和def的作用类似,用来声明要定义一个函数
- a, b和(a, b)的表达含义类似,用来声明形参
- : a+b和return a + b的含义类似,用来声明返回值
在匿名函数中的形参可以接受位置参数,动态位置参数,默认参数,动态关键字参数,也可以什么都不写。
匿名函数的冒号:后面接的是函数的返回值,只能返回一个数据,而且是必须要写的。
当for循环和匿名函数一起使用时,会有一个坑:如果是限循环后调用,for循环的变量会使用最后一个,而不是期间每个元素的值:
lst = [] # [func,func,func]
for i in range(3):
lst.append(lambda :i)
for j in lst:
print(j())
输出的结果为:
2
2
2
当第一个循环结束时,列表中存储的值为三个匿名函数的内存地址。每个匿名函数实际上只有一个内容:返回i。但是在调用之前,这一行代码并不会执行,函数中记录的还是一个i。当循环结束,我们调用这些函数时,i已经变成了2。虽然前两个函数被加入到列表中时i的值还是1和2,但它们没有被记录在函数中。
我们可以把上面的代码拆分开,这样看起来会直观些:
lst = []
for i in range(3):
def func():
return i
lst.append(func)
for j in lst:
print(j())
如果将匿名函数和for循环封装在列表推导式中,会更有迷惑性:
g = [lambda :i+1 for i in range(3)]
print([em() for em in g])
输出的结果为:
[3, 3, 3]
对于生成器表达式,情况又发生了变化——因为当函数被拿出来之后,循环才会向下走:
g = (lambda :i+1 for i in range(3))
print([em() for em in g])
输出的结果为:
[1, 2, 3]
filter函数
filter函数用来过滤掉不符合条件的元素。filter函数有两个参数,第一个参数为规则函数,第二个参数为可迭代对象:
lst = [1, 2, 3, 4, 5, 6, 7, 8]
def foo(x): # 规则函数
return x > 4 # 规则函数的返回值需要是布尔值
print(filter(foo, lst))
print(list(filter(foo, lst)))
输出的结果为:
<filter object at 0x000002B53EA8AB00>
[5, 6, 7, 8]
filter的返回值为filter对象,可迭代,可以通过list函数转化为列表。
我们可以通过for循环模拟内置函数filter:
def filter(func, iter):
lst = []
for i in iter:
if func(i):
lst.append(i)
return lst
也可以使用匿名函数作为规则函数,这样可以让代码看起来非常简洁:
# 找到年纪大于16岁的人的信息
lst = [{
'id':1,'name':'alex','age':18},
{
'id':1,'name':'wusir','age':17},
{
'id':1,'name':'taibai','age':16},]
print(list(filter(lambda x: x['age'] > 16, lst))) # 过滤条件
输出的结果为:[{
'id': 1, 'name': 'alex', 'age': 18}, {
'id': 1, 'name': 'wusir', 'age': 17}]
map函数
map函数也称作映射函数,用来将可迭代对象中每个元素执行函数功能:
lst = [1,2,3,4,5,6,8,9]
print(map(str, lst))
print(list(map(str, lst)))
输出的结果为:
<map object at 0x000001ABD67EA908>
['1', '2', '3', '4', '5', '6', '8', '9']
map函数返回的是map对象,也可以使用list函数转换为列表。
map函数可以使用更多参数的规则函数来整合多个可迭代对象:
lst1 = [1,2,3]
lst2 = [3,2,1]
lst3 = [3,2,1,5]
print(list(map(lambda x, y, z: x + y + z, lst1, lst2, lst3)))
输出的结果为:
[7, 6, 5]
如果可迭代对象长度不同,map函数的迭代次数以最短的可迭代对象为准。
sorted函数
sorted函数用来将可迭代对象排序:
print(sorted("alex,mdsb")) # 升序
print(sorted(('alex','mdsb'),reverse=True)) # 降序
dic = {
1:'a',3:'c',2:'b'}
print(sorted(dic))
输出的结果为:
[',', 'a', 'b', 'd', 'e', 'l', 'm', 's', 'x']
['mdsb', 'alex']
[1, 2, 3]
不管输入的可迭代对象是什么样的数据类型,sorted函数的返回值都是一个列表。
sort函数也可以使用规则函数,只是这次规则函数要通过使用关键字参数的方式引入:
lst = ['天龙八部','西游记','红楼梦','三国演义']
print(sorted(lst,key=len)) # key= 排序规则(函数名)
print(sorted(lst,key=lambda x:len(x)))
lst = [{
'id':1,'name':'alex','age':18},
{
'id':2,'name':'wusir','age':17},
{
'id':3,'name':'taibai','age':16},]
print(sorted(lst,key=lambda x:x['age'],reverse=True))
输出的结果为:
['西游记', '红楼梦', '天龙八部', '三国演义']
['西游记', '红楼梦', '天龙八部', '三国演义']
[{
'id': 1, 'name': 'alex', 'age': 18}, {
'id': 2, 'name': 'wusir', 'age': 17}, {
'id': 3, 'name': 'taibai', 'age': 16}]
列表的.sort()方法是在列表所在的原地进行修改,而sorted函数则是新建一个列表:
lst = [1,2,3,4,65,-7]
print(sorted(lst)) # 新建列表
print(lst)
lst1 = [1,2,3,4,65,-7]
print(lst1.sort()) # 新建列表
print(lst1)
输出的结果为:
[-7, 1, 2, 3, 4, 65]
[1, 2, 3, 4, 65, -7]
None
[-7, 1, 2, 3, 4, 65]
max和min函数
max和min函数用来选取可迭代对象中的最大值或最小值,可以指定规则函数进行更复杂的选择:
lst = [1, 2, 3, 4, 5, 6, -9, 10, -22]
print(max(lst))
print(min(lst, key=abs))
print(max(lst, key=lambda x: pow(x, 4) - pow(x, 2) + x))
输出的结果为:
10
1
-22
也可以通过这两个函数找到最大的值或者最小的值对应的键:
dic = {
'a': 3, 'b': 2, 'c': 1}
print(max(dic.values()))
print(min(dic, key=lambda x: dic[x]))
输出的结果为:
3
c
reduce函数
reduce函数用来进行累运算。规则函数中会有两个参数,第一个参数用来存储上一次运算的结果,第二个参数传入下一个值,返回值为运算操作。
需要注意的是,在Python 2中,reduce可以直接使用,而在Python 3中,需要在functools里面导入reduce函数:
from functools import reduce
我们可以通过reduce函数实现累乘运算:
from functools import reduce
def func(x, y):
return x * y
print(reduce(func, range(1, 6)))
输出的结果为:120
将函数用匿名函数整合会让代码更加简洁:
from functools import reduce
print(reduce(lambda x, y: x * y, range(1, 6)))
print()函数
print函数我们已经非常熟悉了,用来将内容打印出来。我们还需要了解的是print有两个关键字参数:sep和end。
sep用来规定print中多个元素以什么间隔开,默认值为一个空格' ';end用来规定print函数打印完全部内容后以什么为结尾,默认为换行符\n。
我们可以通过修改sep和end的值来实现不同的打印输出效果:
print('alex', 'wusir', '太亮', sep='-', end=' ')
print('meet')
输出的结果为:alex-wusir-太亮 meet
我们可以利用print的这两个参数实现打印九九乘法表:
for i in range(1, 10):
for j in range(1, 10):
if i > j:
print(f'{i} * {j} = {i * j}', end=' ')
elif i == j:
print(f'{i} * {j} = {i * j}')
输出的结果是这样的:
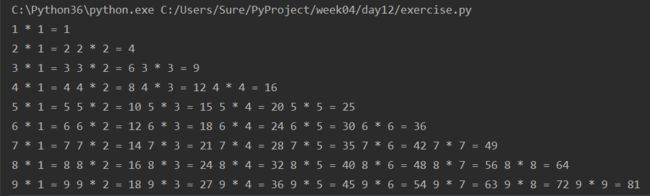
除了能将信息打印到屏幕上,print也可以将信息写入到文件中:
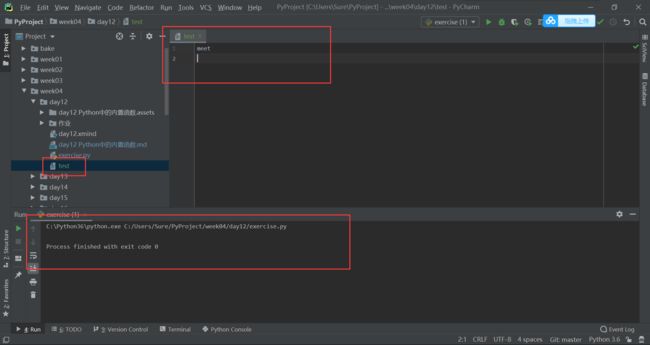
f = open('test', 'a', encoding='utf-8')
print('meet', file=f)
屏幕上没又打印出任何内容,但是出现了一个名为test的文件,文件中的内容为meet:
zip函数
zip是拉链的意思,用来将两个可迭代对象以关联起来,以返回值为zip对象,可以转换为列表,列表中的每个元素为原来的可迭代对象中的元素组成的元组:
lst1 = [1, 2, 3, 4, 5]
lst2 = [5, 4, 3, 2, 1]
print(zip(lst1, lst2))
print(list(zip(lst1, lst2)))
返回的结果为:
<zip object at 0x0000021A6A792B48>
[(1, 5), (2, 4), (3, 3), (4, 2), (5, 1)]
使用map函数也可以实现类似的功能:
lst1 = [1, 2, 3, 4, 5]
lst2 = [5, 4, 3, 2, 1]
print(list(map(lambda x, y: (x, y), lst1, lst2)))
输出的结果为:
[(1, 5), (2, 4), (3, 3), (4, 2), (5, 1)]
这种数据类型可以直接使用字典的工厂函数dict转换为字典:
lst1 = [1, 2, 3, 4, 5]
lst2 = [5, 4, 3, 2, 1]
print(dict(zip(lst1, lst2)))
输出的结果为:
{
1: 5, 2: 4, 3: 3, 4: 2, 5: 1}
高阶内置函数比较
| 函数名 | 规则函数位置 | 规则函数形参数目 | 返回值数据类型 |
|---|---|---|---|
| filter | 首位 | 1个 | filter对象,可转换为列表 |
| map | 首位 | 1个或多个 | map对象,可转换为列表 |
| reduce | 首位 | 2个 | 可迭代对象中的元素 |
| max和min | 末尾,用key指明 | 1个 | 可迭代对象中的元素 |
| sorted | 末尾,用key指明 | 1个 | 列表 |
| zip | 无 | 无 | zip对象,可转换为列表或字典 |