Python爬虫学习笔记(一)
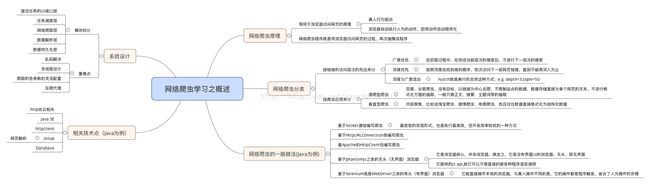
准备阶段(Python爬虫的常用库):
- requests 做请求的时候用到: requests.get("url")
- selenium 自动化会用到
- lxml
- beautifulsoup
- pyquery 网页解析库,语法和jquery非常像
- pymysql 存储库,操作mysql数据的
- pymongo 操作MongoDB 数据库
- redis 非关系型数据库
- jupyter 在线记事本
什么是Urllib
Python内置的Http请求库
urllib.request 请求模块 模拟浏览器发送请求
urllib.error 异常处理模块
urllib.parse url解析模块 工具模块,如:拆分、合并
urllib.robotparser robots.txt 解析模块
一.Python爬虫的函数:
urllib库是Python中一个基本的网络请求库。可以模拟浏览器行为,向指定的服务器发送一个请求,并可以保存服务器返回的数据。在Python3中的urllib库中,所有和网络请求有关的方法都被集到urllib.request模块下面。
1.urlopen函数 :
from urllib import request
resp = request.urlopen('http://www.baidu.com')
print(resp.read())
#还有常见方法:readline() readlines() getcode()- url:请求的url。
- data:请求data,如果设置了这个值,那么将会变成post请求。
- 返回值:为http.client.HTTPResponse对象,这个对象是一个类文件句柄对象。
2.urlretrieve函数:
from urllib import request
request.urlretrieve('http://www.baidu.com/','baidu.html')改函数方便将网页上的一个文件保存到本地。(下载)------可以是xxx.html 亦可以为 xxx.jpg
3.urlencode函数与parse_qs函数(一对):
urlencode进行编码,如下,将params进行编码为url码。(我们手写代码向浏览器发送请求时,如果请求中含有中文字符or特殊字符,我们需要手动对发送的中文字符进行编码。使用urlencode函数)
from urllib import parse
params = {'name':'张三','age':18,'greet':'hello world'}
result = parse.urlencode(params)
print(result)
#输出:name=%E5%BC%A0%E4%B8%89&age=18&greet=hello+world如下,http中有中文“李宁”。
from urllib import request
from urllib import parse
#访问李宁官网
url = "https://www.so.com/s"
#对url中的中文字符进行操作
par = {"q":"李宁"}
#对par进行编码
qs = parse.urlencode(par)
#类似字符串拼接操作合成能被识别的url
url = url + "?" + qs
#get网站上的所有内容
resp = request.urlopen(url)
print(resp.read())反之,解码操作就使用parse_qs函数:(test样例)
#将其先urlencode(编码)再使用parse_qs函数(解码)
from urllib import parse
params = {'name':'张三','age':18,'greet':'hello world'}
qs = parse.urlencode(params)
print(qs)
#name=%E5%BC%A0%E4%B8%89&age=18&greet=hello+world
result = parse.parse_qs(qs)
print(result)
#{'name': ['张三'], 'age': ['18'], 'greet': ['hello world']}
4.urlparse函数 与 urlsplit函数:
拿到url,想对url中的各个组成部分进行分割,那么这个时候就可以使用 urlparse 或 urlsplit来进行分割。
如下:将url拆分urlsplit 与 urlparse函数效果基本差不多。
from urllib import parse
url = 'http://baidu.com/s?username=zhiliao'
#将url拆分用urlsplit与urlparse
result = parse.urlsplit(url)
print('scheme:',result.scheme)
#netloc: baidu.com
print('netloc:',result.netloc)
#path: /s
print('path:',result.path)
#scheme: http
print('query:',result.query)
#query: username=zhiliao5.request.Request类:
想要在访问网站的时候,增加一些请求头 ——(模拟用户登录)
因为有一些网站,采用了反爬技术,如果只是单纯的对 url 进行 urlopen 是得不到网站的全部信息的。所以我们需要模拟用户登入(增加一些请求头)。
from urllib import request
from urllib import parse
url = 'https://www.lagou.com/jobs/list_python?' \
'labelWords=&fromSearch=true&suginput='
headers ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/69.0.3497.100 Safari/537.36',
'Referer': 'https://www.lagou.com/jobs/list_python?'
'labelWords=&fromSearch=true&suginput='
}
data = {
'first':'true',
'pn':1,
'kn':'python'
}
req = request.Request(url,headers=headers,
data=parse.urlencode(data).encode('utf-8'),
method='POST')
resp = request.urlopen(req)
print(resp.read().decode('utf-8'))