Python爬虫神器pyppeteer
简介
pyppeteer 是非官方 Python 版本的 Puppeteer 库,浏览器自动化库,由日本工程师开发。
Puppeteer 是 Google 基于 Node.js 开发的工具,调用 Chrome 的 API,通过 JavaScript 代码来操纵 Chrome 完成一些操作,用于网络爬虫、Web 程序自动测试等。
pyppeteer 使用了 Python 异步协程库 asyncio,可整合 Scrapy 进行分布式爬虫。
pyppeteer维护得不好;puppet 木偶;puppeteer 操纵木偶的人。

安装
- 安装
pyppeteer
pip install pyppeteer
2.安装 Chromium
pyppeteer-install
注意:首次运行pyppeteer会自动下载Chromium(Chrome的实验版,约150MB)
若 Chromium 安装失败,可手动下载

3.查看 Chromium 存放路径
import pyppeteer print(pyppeteer.__chromium_revision__) # 查看版本号
print(pyppeteer.executablePath()) # 查看 Chromium 存放路径
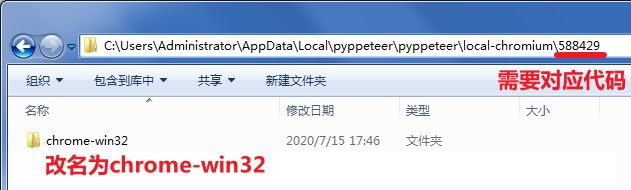
# 588429
# C:\Users\Administrator\AppData\Local\pyppeteer\pyppeteer\local-chromium\588429\chrome-win32\chrome.exe
解压到:C:\Users\Administrator\AppData\Local\pyppeteer\pyppeteer\local-chromium\588429\ 下
将文件夹 chrome-win 重命名为 chrome-win32 即可
配置详情查看 Pyppeteer Environment Variables
初试
打开百度并截图
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False) # 关闭无头浏览器
page = await browser.newPage()
await page.goto('https://www.baidu.com/') # 跳转
await page.screenshot({'path': 'example.png'}) # 截图
await browser.close() # 关闭
asyncio.get_event_loop().run_until_complete(main())指定浏览器路径
指定参数 executablePath
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False, executablePath=r'C:\Users\Administrator\AppData\Local\pyppeteer\pyppeteer\local-chromium\588429\chrome-win32\chrome.exe') # 关闭无头浏览器
page = await browser.newPage()
await page.goto('https://www.baidu.com/') # 跳转
await page.screenshot({'path': 'example.png'}) # 截图
await browser.close() # 关闭
asyncio.get_event_loop().run_until_complete(main())移除Chrome正受到自动测试软件的控制
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False, ignoreDefaultArgs=['--enable-automation']
input()
await browser.close()
asyncio.get_event_loop().run_until_complete(main())

全屏
import tkinter
import asyncio
from pyppeteer import launch
def screen_size():
tk = tkinter.Tk()
width = tk.winfo_screenwidth()
height = tk.winfo_screenheight()
tk.quit()
return {'width': width, 'height': height}
async def main():
browser = await launch(headless=False, args=['--start-maximized']) # 页面全屏
page = await browser.newPage()
await page.setViewport(screen_size()) # 内容全屏
await page.goto('https://www.baidu.com/')
input()
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
页面内容
Page.content() 或 Page.evaluate()
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False)
page = await browser.newPage()
url = 'https://www.baidu.com/'
await page.goto(url)
# content = await page.content()
content = await page.evaluate('document.body.textContent', force_expr=True)
print(content)
input()
await browser.close()
asyncio.get_event_loop().run_until_complete(main())异步运行
asyncio.wait() 或 asyncio.gather(),建议只用在一次性读取的页面,需要滚动的不建议使用
import asyncio
from pyppeteer import launch
async def crawl(url):
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto(url)
title= await page.title()
print(title)
print(title)
await browser.close()
async def main():
urls = [
crawl('https://www.baidu.com/'),
crawl('https://www.bing.com/')
]
await asyncio.wait(urls)
# await asncio.gather(*urls)
asyncio.get_event_loop().run_until_complete(main())
# 百度一下,你就知道
# 微软 Bing 搜索 - 国内版报错 OSError: Unable to remove Temporary User Data
启动浏览器时指定参数userDataDir存放缓存,保证硬盘大且不是系统盘
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False, userDataDir='./cache/')
input()
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
报错 pyppeteer.errors.TimeoutError: Navigation Timeout Exceeded: 30000 ms exceeded.
封装
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=False, ignoreDefaultArgs=['--enable-automation'], userDataDir='./cache/') #
page = await browser.newPage()
await page.setViewport({'width': 1366, 'height': 768}) # 内容铺满
await page.goto('https://www.baidu.com/') # 跳转
input('回车退出')
await browser.close()
asyncio.get_event_loop().run_until_complete(main())参考文献
- pyppeteer/pyppeteer: Headless chrome/chromium automation library
- Pyppeteer Documentation
- Chromium - The Chromium Projects
- Pyppeteer Environment Variables
- pyppeteer的环境搭建,常见参数及2个案例
- pyppeteer使用遇到的bug及解决方法
- pyppeteer 爬取京东商城和淘宝示例代码|获取cookie爬取搜索内容
- pyppeteer教程
- pyppeteer: 解决OSError: Unable to remove Temporary User Data的报错问题
- 解决pyppeteer导航超时问题: pyppeteer.errors.TimeoutError: Navigation Timeout Exceeded: 30000 ms exceeded.
- python异步编程之asyncio(百万并发)
- Python 异步编程入门