Redis缓存--缓存雪崩,击穿、穿透理解

1、Redis缓存雪崩
引子:电商首页数据一般都做缓存处理,机制:定时任务刷新,或者查不到后更新 。其中定时刷新就有一个问题:
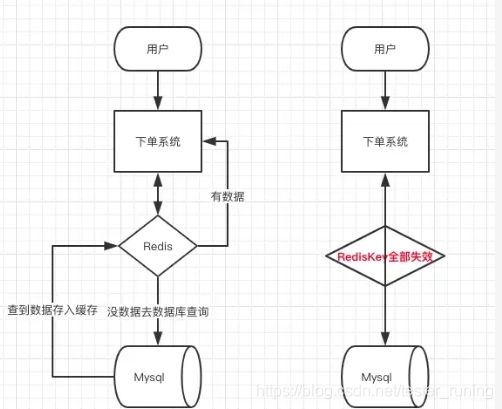
示例:首页的key失效时长都是12小时,中午12点刷新,假设零点秒杀活动,RPS(客服端每秒发出请求数)以6000,本地缓存可以抗住5000,但是当缓存key失效,此时1s6000请求全部落到数据库,数据库肯定扛不住一下子就报警可能导致DBA直接挂掉。
redis雪崩
结果:同一时间大面积失效,那一瞬间Redis跟跟没有一直,数据直接打到数据库对于数据库来说是灾难性的。
这种情况怎么应对:处理缓存雪崩:方法在批注往redis存数据的时候,在每一个Key的失效时间都加个随机值,可以保证大面积失效redis还是可以抗住的。
如果redis集群部署,将热点均匀的分步在不同的redis库汇总也能避免失效。或者设置热点数据永远不过期,有更新操作就更新缓存就好了。
2、Redis穿透
缓存穿透是指缓存和数据库中的都没有数据,而用户不断的发起请求,【我们的数据库id都是从1开始自增的】如果用户发起-1的数据或者id很大不存在的数据。这时候用户很可能是攻击者,这种攻击会导致数据库压力过大,严重击垮数据库。

redis穿透
像这种不做参数校验,数据库id都是大于0的,用小于0的参数请求,每次都可以打到数据库,数据库也查不到,如果并发高点就容易挂掉。
缓存穿透解决方法:
接口层增加校验,比如:参数做效验,不合法参数直接return.
Redis自带的一个高级用法:布隆过滤器(bloom Filter)也能防止缓存穿透发生。
简单示例:经常用的报表的分页查询,程序没有对分页参数的大小限制,调用的万一一口气查Integer.MAX_VALUE一次就请就需要好几秒,多个并发就挂了。
3、Redis击穿
redis缓存击穿跟缓存雪崩有点像, 但又有点不一样。缓存雪崩是因为大面积的缓存失效直接打到DB把DB打崩了-----而缓存击穿不同的是缓存击穿是指一个Key非常热点,在不停的扛着大并发。大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接访问数据库,就像一个完全好无损的桶上凿开一个洞。
缓存击穿解决方法:设置热点数据永不过期,或者加上互斥锁。
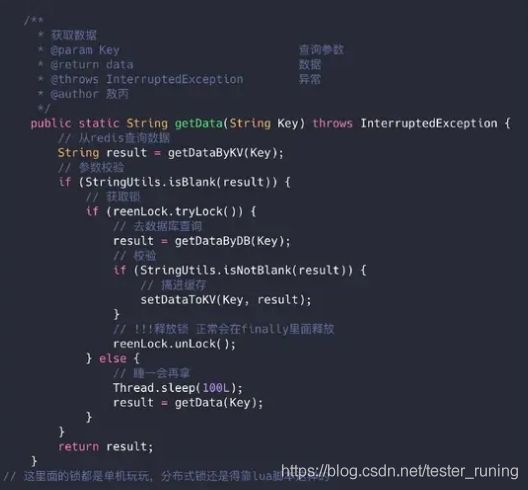
实现示例
4、总结:
事前:Redis高可用,主从+哨兵,Redis cluster,=避免全盘崩溃;
事中:本地ehcache缓存+Hystrix限流+降级,避免mysql被击垮;
事后:Redis持久化RDB+AOF,一旦重启,自动从硬盘上加载数据,快速恢复缓存数据。
工作中记录–根据CPU核心数确定线程池并发线程数:
在《Java Concurrency in Practice》一书中,给出了估算线程池大小的公式:
Nthreads=NcpuUcpu(1+w/c),其中
Ncpu=CPU核心数
Ucpu=cpu使用率,0~1
W/C=等待时间与计算时间的比率
那么实际使用中并发线程数如何设置呢?分析如下(我们以派系一公式为例):
(并发线程数)Nthreads=Ncpu*(1+w/c)
IO密集型:一般情况下,如果存在IO,那么肯定w/c>1(阻塞耗时一般都是计算耗时的很多倍),但是需要考虑系统内存有限(每开启一个线程都需要内存空间),这里需要上服务器测试具体多少个线程数适合(CPU占比、线程数、总耗时、内存消耗)。如果不想去测试,保守点取1即,Nthreads=Ncpu*(1+1)=2Ncpu。这样设置一般都OK。
计算密集型:假设没有等待w=0,则W/C=0. Nthreads=Ncpu。
至此结论就是:
IO密集型=2Ncpu(可以测试后自己控制大小,2Ncpu一般没问题)(常出现于线程中:数据库数据交互、文件上传下载、网络数据传输等等)
计算密集型=Ncpu(常出现于线程中:复杂算法)
即对于计算密集型的任务,在拥有N个处理器的系统上,当线程池的大小为N+1时,通常能实现最优的效率。(即使当计算密集型的线程偶尔由于缺失故障或者其他原因而暂停时,这个额外的线程也能确保CPU的时钟周期不会被浪费。)
即,计算密集型=Ncpu+1,但是这种做法导致的多一个cpu上下文切换是否值得,这里不考虑。读者可自己考量。
对于一个CPU,线程数总是大于或等于核心数的。一个核心最少对应一个线程,但通过超线程技术,一个核心可以对应两个线程,也就是说它可以同时运行两个线程。
CPU的线程数概念仅仅只针对Intel的CPU才有用,因为它是通过Intel超线程技术来实现的