百度ai 性别
Detroit police wrongfully arrested Robert Julian-Borchak Williams in January 2020 for a shoplifting incident that had taken place two years earlier. Williams had nothing to do with the incident, but a facial recognition technology used by Michigan State Police “matched” his face with a grainy image obtained from a surveillance video showing another African American man who was helping himself with some watches. The case was dismissed two weeks later at the prosecution’s request. Too late to spare William from the distress of being handcuffed and arrested in front of his family, forced to provide a mug shot, fingerprints and a DNA sample, then interrogated and imprisoned.
底特律警方于2020年1月以两年前发生的一次入店行窃事件错误地逮捕了Robert Julian-Borchak Williams。 威廉姆斯与事件无关,但密歇根州警察使用的面部识别技术使他的脸与从监控录像中获得的粒状图像“匹配”,该录像显示另一名非洲裔美国人正在帮助自己观看手表。 该案在两周后应检方的要求被驳回。 为时已晚,威廉摆脱了被戴上手铐并在家人面前被捕的痛苦,被迫提供马克杯照片,指纹和DNA样本,然后受到审讯和监禁。
Controversy in AI applications is no longer news.
人工智能应用领域的争议不再是新闻。
In a previous post Is Artificially Intelligence Racist? we presented an MIT research from 2018 (!) that showed how AI technologies, like facial recognition used in predictive policing systems discriminate against people of color. Fears that it AI might jeopardize jobs for human workers, be misused by malevolent actors, elude accountability or amplify bias have been at the forefront of the recent scientific literature and media coverage. A meta-analysis of 84 documents containing ethical principles and guidelines for AI published in different parts of the world found eleven overarching ethical values and principles, where most of the documents seem to converge around the following principles:
在上一篇文章中, 人工智能是种族主义者吗? 我们提出了麻省理工学院从2018年开始的一项研究 (!),该研究表明AI技术(例如预测警务系统中使用的面部识别)如何区分有色人种 。 对AI的担心可能会危及人类工人的工作 ,被恶意行为者滥用 , 逃避问责制或加剧偏见,这一点已成为最近科学文献和媒体报道的重点。 对包含在世界各地的AI的道德原则和准则的84份文档进行的荟萃分析发现,有11项总体的道德价值观和原则,其中大多数文档似乎都围绕以下原则融合:
Justice and fairness, i.e. respect for diversity, inclusion and equality; prevention, monitoring and mitigation of unwanted bias and discrimination; possibility to appeal or challenge decisions, and right to redress.
公正与公平 ,即尊重多样性,包容性和平等; 预防,监测和减轻不必要的偏见和歧视; 对决定提起上诉或提出异议的可能性,以及获得补救的权利。
Transparency, as explainability and interpretability of models and other efforts of communication and disclosure;
透明度 ,作为模型的可解释性和可解释性,以及沟通和披露的其他努力;
Non-maleficence: safety and security, where AI should never cause foreseeable or unintentional harm, intentional misuse via cyberwarfare and malicious hacking. Harm can be interpreted as discrimination, violation of privacy, or actual bodily harm;
非恶意:安全和保障,其中AI绝不应该造成可预见或无意的伤害,通过网络战和恶意黑客故意滥用。 危害可以解释为歧视,侵犯隐私或实际人身伤害;
Responsibility and accountability: acting with integrity and clarifying the attribution of responsibility and legal liability in contracts upfront, or alternatively, by centering on remedy: stakeholders to be held accountable include AI developers, designers, institutions or industry.
责任与问责 :诚实行事, 预先明确合同中的责任和法律责任归属,或者以补救为中心:要负责的利益相关者包括AI开发人员,设计师,机构或行业。
Privacy, mostly presented in relation to data protection and data security.
隐私,主要涉及数据保护和数据安全性 。
道德准则,委员会和董事会的泛滥 (The proliferation of ethical guidelines, committees and boards)
Organizations usually responds to these concerns by developing ad-hoc expert committees on AI, often mandated to draft policy documents. As part of their institutional appointments, these committees produce reports and guidance documents on ethical AI, that are instances of what is termed non-legislative policy instruments or soft laws. Unlike so-called hard law — that is, legally binding regulations passed by the legislatures to define permitted or prohibited conduct — ethics guidelines are not legally binding but persuasive in nature.
组织通常通过建立AI 临时专家委员会来应对这些担忧,通常授权其起草政策文件。 作为机构任命的一部分,这些委员会针对道德AI制定报告和指导文件,这些都是所谓的非立法政策工具或软法律的实例。 与所谓的硬法(即立法机关通过的具有法律约束力的法规来定义允许或禁止的行为)不同,道德准则并不具有法律约束力,而是具有说服力的。
Similar efforts are taking place in the private sector, especially among tech corporations. Companies such as IBM, Google , Microsoft and SAP have publicly released AI guidelines and principles and sometimes established an “ethical board”, with mixed results. A frequent critique is that these ethical boards gets paraded in front of the media but then meet once a year or six months at best with no actual veto power over questionable projects. When they don’t get accused of ethic washing altogether: as part of a panel on ethics at the Conference on World Affairs 2018, one member of the Google DeepMind ethics team emphasized repeatedly how ethically Google DeepMind was acting, while simultaneous avoiding any responsibility for the data protection scandal at Google DeepMind. In her understanding, Google DeepMind were an ethical company developing ethical products and the fact that the health data of 1.6 Million people was shared without a legal basis was instead the fault of the British government.
私营部门,尤其是科技公司之间也在进行类似的努力。 IBM , Google , Microsoft和SAP等公司已经公开发布了AI准则和原则,有时还建立了一个“道德委员会”, 结果不一 。 经常有人批评说,这些道德委员会在媒体面前大行其道,但随后每年召开一次或最多六个月一次的会议,而对可疑项目没有实际否决权。 当他们不被指控洗道德时 总体而言:作为2018年世界事务大会道德小组的一部分,Google DeepMind道德团队的一名成员反复强调了Google DeepMind的行为举止,同时避免对Google DeepMind的数据保护丑闻承担任何责任。 在她的理解下,Google DeepMind是一家开发道德产品的道德公司,而没有法律依据就共享160万人的健康数据这一事实却是英国政府的错。
Truth is these technologies affect people’s lives: they can perpetuate injustice in hiring, retail, security and criminal legal system. The latest controversy comes from the UK where an algorithm lowered the grades assigned to students by their teachers : unable to take their exams during 2020 due to the COVID-19 pandemic and with schools shut back in March, students received their grades for an exam-free year in early August from the Scottish Qualifications Authority (SQA) courses by letter, text, and email. It then emerged that the exam board had decided to lower tens of thousands of grades from the original awards recommended by teachers.
事实是,这些技术会影响人们的生活:它们可以使雇用,零售,安全和刑事法律制度中的不公正现象长期存在。 最新的争议来自英国,该算法降低了教师分配给学生的成绩 :由于COVID-19大流行,到2020年无法参加考试,并且学校在3月关闭,学生收到了考试成绩-苏格兰资格认证局(SQA)课程通过信件,文字和电子邮件在8月初提供免费的一年。 结果发现,考试委员会决定从老师推荐的原始奖项中降低数万个等级。
Students were left devastated by grades lower than anticipated.
学生们的成绩比预期的要低。
The algorithm used by the exam board’s moderators leveraged data based on the past performance of schools, resulting in the pass rate for students undertaking higher courses in deprived locations across Scotland to be reduced by 15.2%, in comparison to 6.9% in more affluent areas.
考试委员会主持人使用的算法基于过去学校的表现来利用数据,从而使苏格兰贫困地区上高等课程的学生通过率降低了15.2%,而较富裕地区的这一数字为6.9%。
Why? Because the algorithm factored in historic school data, rather than a pupil’s individual performance, and in order to achieve its goal it used the post code as a predictor for the pass rate. Had it happened in the US or South Africa, we could have concluded with good confidence that the algorithm is racist. I — wrongly — assume all data scientists and ML practitioners should know by now that removing the “sex” or “race” attribute from the dataset is not enough to debias an algorithm: bias “creeps in” from the rest of the data and easily finds proxies if available, and the postcode is one of the most obvious ones. But there is more.
为什么? 因为该算法将历史学校数据而不是学生的个人表现作为考虑因素,并且为了实现其目标,所以使用邮政编码作为通过率的预测指标 。 如果它在美国或南非发生,我们可以很有把握地得出结论,该算法是种族主义的。 我(错误地)假设所有数据科学家和ML实践者现在都应该知道,从数据集中删除“性别”或“种族”属性不足以使算法失衡 :使其余数据“ 蠕变 ”并容易查找代理(如果有),而邮政编码是最明显的代理之一。 但是还有更多。
不仅在数据中 (It’s not only in the data)
We often shorthand our explanation of AI bias by blaming it on biased training data. But, as Karen Hao explains, the reality is more nuanced: bias can creep in long before the data is collected as well as at many other stages of the process. It starts when we decide what we want to achieve with the technology: if a bank wants to develop an algorithm to grant loans to applicants, it must decide what it wants the algorithm to optimize: is it maximizing the overall profit, or rather reducing defaults? Such business decisions rarely take into consideration other metrics like fairness or discrimination, but we will show that there is a way to include those metrics without compromising the business objectives.
我们经常通过将AI偏差归咎于有偏差的训练数据来简化对AI偏差的解释。 但是,正如Karen Hao所解释的那样 ,现实更加细微:在收集数据之前以及过程的许多其他阶段 ,偏差会长期蔓延。 它始于我们决定要使用该技术实现的目标:如果一家银行想要开发一种算法来向申请人授予贷款,它必须决定它希望该算法进行哪些优化 :是使整体利润最大化还是降低违约率? ? 此类业务决策很少考虑公平性或歧视性等其他指标,但是我们将证明存在一种在不损害业务目标的情况下包括这些指标的方法。
Then of course there is the data collection stage, where the biggest risk is that either the data turns out to be unrepresentative of the reality or it reflects historical biases and prejudices: as in the MIT research I mentioned earlier that uncovered large gender and racial bias in AI systems sold by tech giants like IBM, Microsoft, and Amazon. Given the task of guessing the gender of a face, all companies performed substantially better on male faces than female faces. The error rates were no more than 1% for lighter-skinned men whilst for darker-skinned women, the errors soared to 35%. When tasked to classify the faces of Oprah Winfrey, Michelle Obama, and Serena Williams, the system failed. If the underlying dataset distributions are skewed towards one color (race), the algorithm will perform worse at classifying the underrepresented subset, like dark-skinned faces in this case.
当然,然后是数据收集阶段,其中最大的风险是数据被证明不能代表现实或反映了历史偏见和偏见:正如我之前在MIT研究中提到的那样,发现了巨大的性别和种族偏见由IBM,Microsoft和Amazon等技术巨头出售的AI系统中。 考虑到猜测面Kong性别的任务,所有公司在男性面Kong上的表现都要好于女性面Kong。 肤色较浅的男性的错误率不超过1%,肤色较黑的女性的错误率高达35%。 当负责对奥普拉·温弗瑞,米歇尔·奥巴马和小威廉姆斯的面Kong进行分类时,该系统失败了。 如果基础数据集分布偏向一种颜色(种族),则该算法在对代表性不足的子集进行分类时会表现较差,例如在这种情况下为肤色较黑的面Kong。
Similarly, Amazon was forced to secretly scrap is recruiting algorithm as it was discriminating against women. The company’s experimental hiring tool used artificial intelligence to give job candidates scores ranging from one to five stars — much like shoppers rate products on Amazon, some of the people said. However, the models were trained on a dataset of resumes submitted to the company over a 10-year period: most came from men, a reflection of male dominance across the tech industry, so (surprise!) the system taught itself that male candidates were preferable. For example it downgraded graduates of two all-women’s colleges, or penalized resumes that included the word “women’s”.
同样,一个mazon被迫秘密报废正在招募的歧视女性的算法 。 一些人说,该公司的实验性招聘工具使用人工智能为求职者提供1到5颗星的评分,这很像购物者在亚马逊上对产品进行评分。 但是,这些模型是在10年内提交给公司的简历数据集上进行训练的:大多数人来自男性,这反映了整个科技行业男性的主导地位,因此(惊奇!)该系统告诉自己,男性候选人是更好。 例如,它降低了两所女子大学的毕业生的等级,或者对包含“女子”一词的惩罚性简历进行了降级。
And guess what Amazon did try to do? They tried to make the algorithm more neutral to these particular terms, but bias found his way through the data anyway, as the revised system was still picking up on implicitly gendered words — verbs that were highly correlated with men over women — so they eventually gave up.
猜猜亚马逊做了什么? 他们试图使算法对这些特定术语更加中立,但无论如何偏见还是在数据中找到了解决之道,因为修订后的系统仍在使用隐含性别的词(与男性比女性高度相关的动词),因此他们最终给出了向上。
Last, as every data scientist knows too well, there is the “data cleaning and preparation” stage, where the attributes that will feed the ML algorithm are selected, and the relative data is transformed in a machine friendly format. Choosing which attributes to consider or ignore can significantly influence your model’s prediction accuracy and, as we have just seen, its fairness.
最后,正如每个数据科学家都非常了解的那样,有一个“数据清理和准备”阶段,在该阶段中,将选择用于ML算法的属性,并将相对数据转换为机器友好格式。 选择要考虑或忽略的属性会极大地影响模型的预测准确性,并且正如我们已经看到的那样,会影响其公平性。
为什么AI偏见难以修复 (Why is AI bias hard to fix)
So it begins to be clear at this stage that the problems above cannot be solved with some quick fix. At first, it’s not always obvious to identify where biases come from, and even if you do, it’s hard to figure out how to get rid of them. Models are then usually trained and tested for performance according to one single metric (more on this below), and the dataset is randomly split into training and validation, except for some specific problem domains like time-series, without taking into account potentially skewed subsets, so the data used to test the performance of the model ends with the same biases as the data used to train it. One remedy could be to split the data according to some “protected” attributes (an attribute that partitions a population into groups whose outcomes should have parity), and the results compared to check if the model performs similarly on different subsets. But there is another challenge ahead, and it lies in the definition of fairness itself.
因此,在此阶段开始很明显,上述问题不能通过快速修复来解决。 首先,识别偏差的来源并不总是很明显,即使您这样做,也很难弄清楚如何消除它们。 然后通常根据一种度量标准对模型进行训练和性能测试(下文对此有更多说明),并且将数据集随机分为训练和验证(除了某些特定的问题域,例如时间序列),而不考虑潜在的偏斜子集,因此用于测试模型性能的数据与用于训练模型的数据存在相同的偏差。 一种补救方法是根据某些“受保护”属性(将人群划分为各组结果应具有均等性的属性)拆分数据,然后将结果进行比较以检查模型是否在不同子集上表现相似。 但是,还有另一个挑战,那就是公平本身的定义。
算法公平意味着什么? (What does it mean for an algorithm to be fair?)
In law, bias means a judgment based on preconceived notions or prejudices as opposed to say the impartial evaluation of facts. In computer science though, fairness, or the absence of bias, has to be defined in mathematical terms: for example in the loan granting problem we could say the same proportion of white and black applicants should be granted loans (statistical parity) or maybe that individuals who qualify for a desirable outcome should have an equal chance of being correctly classified for this outcome (equal opportunity). Another one could be that the ratio in the probability of favorable outcomes between the two groups be the same (disparate impact), or try to equalize the error rates across groups, so that the algorithm makes just as many mistakes on white applicants as it does on black applicants (treatment equality). The point here is that one must choose a metric to optimize among many possible ones that are mutually exclusive. So if you optimize for statistical parity you cannot optimize for equal opportunity at the same time, and same for the others, because there is mathematical limit to how fair any algorithm, or human decision maker, can be.
在法律上,偏见是指基于先入为主的观念或偏见的判断,而不是对事实的公正评估。 但是,在计算机科学中,必须用数学术语来定义公平或没有偏见:例如,在贷款发放问题中,我们可以说应该向白人和黑人申请人的相同比例发放贷款(统计均等),或者有资格获得理想结果的个人,应具有为该结果正确分类的平等机会(平等机会)。 另一个可能是,两组之间有利结果的概率之比是相同的(不同的影响),或者试图使各组之间的错误率相等,因此该算法对白人申请人的错误产生的错误率与白人相同。对黑人申请人(待遇平等)。 这里的要点是,必须在众多互斥的可能指标中选择一种指标进行优化。 因此,如果您针对统计均等进行优化,则无法同时针对机会均等进行优化,而对于其他机会则相同, 这是因为任何算法或人工决策者的公平性在数学上都有局限性 。
Let’s explain this concept with a case study from Google Research based on loan granting scenarios where a bank may grant or deny a loan based on a single, automatically computed number such as a credit score. A machine learning system tasked with making such an important “yes/no” decision is called a “threshold classifier”: the bank picks a particular cut-off, or threshold, and people whose credit scores are below it are denied the loan, while people above it are granted the loan.
让我们用Google Research的案例研究来解释这个概念,该案例基于贷款授予方案,其中银行可以根据单个自动计算的数字(例如信用评分)来授予或拒绝贷款。 负责做出如此重要的“是/否”决定的机器学习系统称为“阈值分类器”:银行选择特定的临界值或阈值,而信用评分低于该阈值的人将被拒绝贷款,而高于此的人将获得贷款。
In the diagram below, dark dots represent people who would pay off a loan, and the light dots those who wouldn’t. In an ideal world, we would work with statistics that cleanly separate categories as in the left example. Unfortunately, it is far more common to see the situation at the right, where the groups overlap.
在下图中,黑点表示愿意还清贷款的人,亮点表示不愿意还贷的人。 在理想的情况下,我们将使用如左例所示的将分类清晰地分开的统计数据。 不幸的是,在右侧看到情况重叠在一起的情况更为普遍。
However, picking a threshold requires some tradeoffs. Too low, and the bank gives loans to many people who default. Too high, and many people who deserve a loan won’t get one. So what is the best threshold? It depends. One goal might be to maximize the number of correct decisions. Another goal, in a financial situation, could be to maximize profit. Assuming a successful loan makes $300, but a default costs the bank $700, we can then calculate an hypothetical “profit”. Do the two thresholds match?
但是,选择一个阈值需要一些权衡。 太低了,银行向许多违约的人提供贷款。 太高了,许多人应该得到贷款,却得不到贷款。 那么最佳阈值是多少? 这取决于。 一个目标可能是最大化正确决策的数量。 在财务状况下,另一个目标可能是最大化利润。 假设一笔成功的贷款赚了300美元,但拖欠了银行700美元,我们就可以计算出一个假设的“利润”。 两个阈值是否匹配?
Now what happens if we have two subgroups, defined by a protected attribute like race or sex where a statistic like a credit score is distributed differently between two groups? We will call these two groups of people, “blue” and “orange.”
现在,如果我们有两个子组,由种族或性别之类的受保护属性定义,而诸如信用评分之类的统计数据在两个组之间的分布不同,该怎么办? 我们将这两类人称为“蓝色”和“橙色”。
If we choose the pair of thresholds that maximize total profit you can see below that the blue group is held to a higher standard than the orange one, as it requires picking up a higher threshold for the blues.
如果我们选择一对使总利润最大化的阈值,您会在下面看到蓝色组的标准高于橙色组,因为它需要为蓝色设定更高的阈值。
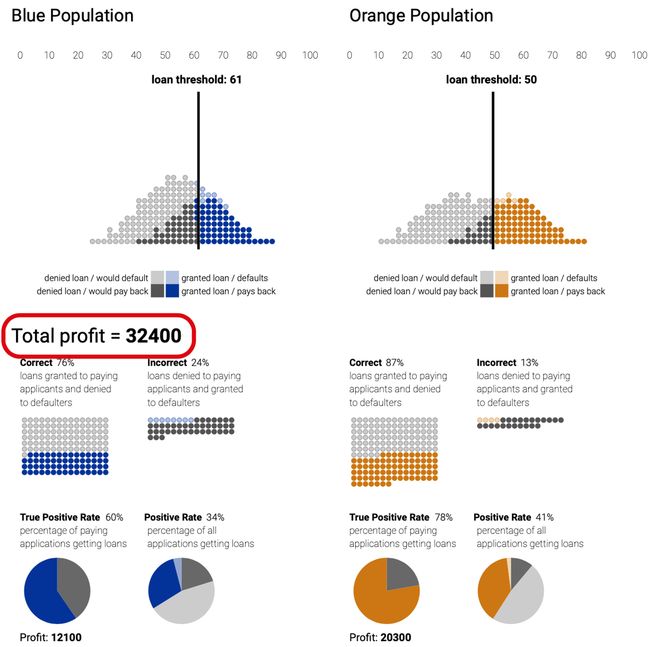
One obvious solution is for the bank not to just pick thresholds to make as much money as possible and implement a group-unaware strategy, which holds all groups to the same standard, with same threshold for the two groups. But the differences in score distributions means that the orange group actually gets fewer loans, as only 60% of the orange paying applicants get a loan opposed to 80% of the paying blue applicants.
一个明显的解决方案是,银行不只是选择阈值以赚取尽可能多的钱,并实施一种无群体意识的策略,该策略将所有组保持在同一标准下,而两组的阈值相同。 但是分数分布的差异意味着橙色组实际上得到的贷款较少,因为只有60%的橙色付费申请人获得了贷款,而80%的蓝色付费申请人却获得了贷款。
What if we can change to another strategy that guarantees the two groups to receive the same number of loans using loan thresholds that yield the same fraction of loans to each group (demographic parity). Again, demographic parity constraint only looks at loans given, not rates at which loans are paid back. In this case, the criterion results in fewer qualified people in the blue group being given loans than in the orange group.
如果我们可以更改为另一种策略,该策略可以使用贷款阈值来保证两个组接收到相同数量的贷款,而该阈值对每个组产生相同比例的贷款( 人口平价) 。 再次, 人口平价约束条件仅查看给定的贷款,而不关注偿还贷款的利率。 在这种情况下,该标准导致蓝色组的合格人员少于橙色组的合格人员。
One final attempt can be done by adopting a metric called equal opportunity, enforcing the constraint that of the people who can pay back a loan, the same fraction in each group should actually be granted a loan. Or, in data science jargon, the “true positive rate” is identical between groups. The interesting part is that this choice is almost as profitable for the bank as demographic parity, and about as many people get loans overall.
可以通过采用一种称为“ 机会均等”的度量标准来进行最后的尝试,从而加强了可以偿还贷款的人的约束,实际上应该向每组中的相同部分发放贷款。 或者,用数据科学术语来说,各组之间的“真实阳性率”是相同的。 有趣的是,这种选择对银行来说几乎与人口平价一样有利可图,并且总体上有大约多少人获得贷款。
This research shows that given essentially any scoring system — it’s possible to efficiently find thresholds that meet any of these criteria. In other words, even if you don’t have control over the underlying scoring system (a common case) it’s still possible to attack the issue of discrimination. However, it shows how it is mathematically impossible to find a combination of thresholds that satisfy all the fairness criteria at the same time: you need to pick one.
这项研究表明,从根本上来说,任何评分系统都可以有效地找到满足任何这些标准的阈值。 换句话说,即使您无法控制基本的评分系统(一种常见情况),也仍然有可能解决歧视问题。 但是,它显示了在数学上如何不可能同时找到满足所有公平性标准的阈值组合:您需要选择一个。
COMPAS案 (The COMPAS case)
Everyone who has been following news on AI ethics knows about the COMPAS case: an algorithm developed by Northpointe — now curiously renamed Equivant — used by courts in some US states to help make bail and sentencing decisions. The algorithm outputs a recidivity score, basically deciding whether defendants awaiting trial are too dangerous to be released on bail. The investigative news organization ProPublica claimed that COMPAS is biased against black defendants. ProPublica pointed out that Northpointe’s assessment tool correctly predicts recidivism 61 percent of the time. But blacks are almost twice as likely as whites to be labeled a higher risk but not actually re-offend. It makes the opposite mistake with whites defendants: they are much more likely than blacks to be labeled lower risk but go on to commit other crimes. So while the algorithm overall accuracy was correct, it was discriminating against blacks in the way it was making mistakes.
一直关注AI伦理新闻的每个人都知道COMPAS案:由Northpointe开发的一种算法-现在奇怪地重命名为Equivant-在美国某些州的法院用于帮助做出保释和量刑判决的算法。 该算法输出一个直线度分数,基本上确定等待审判的被告是否太危险而无法保释。 调查新闻机构ProPublica 声称 COMPAS对黑人被告有偏见。 ProPublica指出,诺斯波恩特(Northpointe)的评估工具正确地预测了61%的累犯率。 但是黑人被标记为更高风险但实际上没有再次犯罪的几率几乎是白人的两倍。 白人被告犯了相反的错误:他们比黑人被标记为低风险的可能性更大,但继续犯下其他罪行。 因此,尽管算法的整体准确性是正确的,但它在犯错误的方式上却与黑人有所区别。
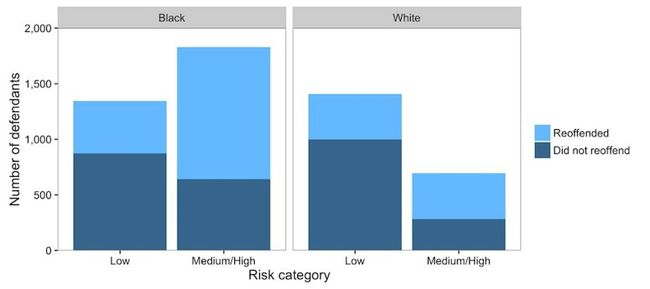
So it’s obviously biased, right? Well…. not that obvious.
所以显然有偏颇吧? 好…。 没有那么明显。
The plot above shows overall recidivism rate for black defendants is higher than for white defendants (52 percent vs. 39 percent).
上图显示黑人被告的整体累犯率高于白人被告(52%对39%)。
The COMPAS tool assigns defendants scores from 1 to 10 that indicate how likely they are to reoffend based on more than 100 factors, including age, sex and criminal history. Notably, race is not used. These scores profoundly affect defendants’ lives: defendants who are defined as medium or high risk, with scores of 5–10, are more likely to be detained while awaiting trial than are low-risk defendants, with scores of 1–4.
COMPAS工具将被告得分从1到10分,这表明他们根据年龄,性别和犯罪记录等100多种因素重新犯罪的可能性。 值得注意的是,没有使用种族。 这些分数深刻地影响了被告的生活:被定义为中等或高风险的被告(分数为5-10)比等待低风险的被告(分数为1-4)更容易被拘留。
Northpointe insists their algorithm is indeed fair because scores mean essentially the same thing regardless of the defendant’s race. For example, among defendants who scored a seven on the COMPAS scale, 60 percent of white defendants reoffended, which is nearly identical to the 61 percent of black defendants who reoffended. An independent re-analysis found scores are highly predictive of reoffending: within each risk category, the proportion of defendants who reoffend is approximately the same regardless of race; this is Northpointe’s definition of fairness.
Northpointe坚持认为,他们的算法确实是公平的,因为无论被告的种族如何,分数在本质上都是同一件事。 例如,在COMPAS评分中获得7分的被告中,有60%的白人被告人被改罪,几乎与61%的黑人被告人被改罪。 一项独立的重新分析发现,分数可以很好地预测再犯:在每个风险类别中,不论种族如何,再犯的被告比例大致相同; 这是诺斯波恩特对公平的定义。
But ProPublica points out that among defendants who ultimately did not reoffend, blacks were more than twice as likely as whites to be classified as medium or high risk (42 percent vs. 22 percent). Even though these defendants did not go on to commit a crime, they are nonetheless subjected to harsher treatment by the courts. A fair algorithm cannot make these serious errors more frequently for one race group than for another.
但是ProPublica指出,在最终没有被减罪的被告中 ,黑人被归为中等或高风险的几率是白人的两倍(42%比22%)。 尽管这些被告没有继续犯罪,但仍受到法院的更严厉对待。 一个公平的算法不能使一个种族组比另一个种族更频繁地犯这些严重错误。
So here’s the point: it’s actually impossible for a risk score to satisfy both fairness criteria at the same time: if the proportion of defendants who reoffend is approximately the same regardless of race, but overall recidivism rate for black defendants is higher than for white defendants — as we showed above — then a greater share of black defendants will be classified as high risk including, crucially, the ones who will not reoffend.
因此,这就是重点:风险评分实际上不可能同时满足这两个公平性标准:如果无论种族如何,重新犯罪的被告比例大致相同,但是黑人被告的整体累犯率高于白人被告就像我们上面显示的那样,那么更多的黑人被告将被归类为高风险,包括至关重要的是那些不会再被冒犯的人。
这是指标,很愚蠢 (It’s the metrics, stupid)
Although Charles Goodhart’s old adage “When a measure becomes a target, it ceases to be a good measure” was formulated while discussing monetary policy in the UK, it fits perfectly with AI, because algorithms are very, very good at optimizing metrics. When the value of a metric is overemphasized, often focusing on short-term goals, it becomes a target, and can be gamed.
尽管在讨论英国的货币政策时,查尔斯·古德哈特(Charles Goodhart)的一句老话“当一种衡量标准成为目标时,它就不再是一种好的衡量标准”,但它却非常适合AI,因为算法非常擅长优化指标。 当度量标准的价值过分强调时,通常将重点放在短期目标上,它将成为目标并可以进行博弈 。
When the report by special counsel Robert S. Mueller III came out in April last year, offering the most authoritative account yet of Russian interference in the 2016 US presidential election, YouTube recommended one video source hundreds of thousands of times to viewers seeking information, a watchdog says: RT, the global media operation funded by the Russian government.
当特别顾问罗伯特·S·穆勒三世(Robert S.Mueller III)的报告于去年4月发布时,提供了有关俄罗斯干预 2016年美国总统大选的迄今最权威的报道时,YouTube向寻求信息的观众推荐了数十万次视频资源, 看门狗说:RT,由俄罗斯政府资助的全球媒体业务。
AlgoTransparency, founded by former YouTube engineer Guillaume Chaslot, analyzed the recommendations made by the 1,000 YouTube channels it tracks daily. Chaslot collected 84,695 videos from YouTube and analyzed the number of views and the number of channels from which they were recommended. The state-owned media outlet Russia Today was an extreme outlier in how much YouTube’s algorithm had selected it to be recommended by a wide-variety of other YouTube channels. Such algorithmic selections, which begin auto-playing as soon as your current video is done, account for 70% of the time that users spend on YouTube. The chart above strongly suggests that Russia Today has in some way gamed YouTube’s algorithm.
由前YouTube工程师Guillaume Chaslot创建的AlgoTransparency分析了每天跟踪的1000个YouTube频道的建议。 Chaslot从YouTube收集了84,695个视频,并分析了观看次数和推荐频道的数量。 国有媒体今日俄罗斯(Russian Today)与YouTube的算法选择了多少其他YouTube频道推荐的算法相比,这是一个极端的异常。 这些算法选择会在您当前视频播放完后立即自动播放,占用户在YouTube上花费时间的70%。 上面的图表强烈表明,《今日俄罗斯》已经在某种程度上玩过YouTube的算法。
Even in absence of malicious intent, focusing on a single metric can lead to automating moral hazard and error.
即使没有恶意意图,只关注一个度量标准也会导致自动化的道德风险和错误 。
For example, to diagnose certain diabetic complications, ophthalmologists must visualize patients’ retinae, looking for subtle signs of damage. A Google team built a deep learning algorithm that could look at digitized retinal photographs and diagnose as accurately, if not more, than physicians. So far, so good. Those predictions though, are more and more used in a broader scope to influence policy decisions: tailored diagnostics can help doctors decide whom to test and treat. In health policy applications, algorithms rely on electronic health records or claims data to make their predictions, opening the door to errors coming from mismeasurement. A team of researchers from Harvard analyzed data from patients visiting an Emergency department (ED) with the intent of predicting those who are at high risk of impending stroke in the days after ED visits. These patients can be hard to distinguish from more benign presentations. Yet if they could be identified, one could target more effective interventions in the ED, or arrange for close follow-up. It seems like a classic prediction problem, one that does not require to prove causality but just a good prediction of the short term risk of stroke. As attributes they used demographic data as well as any prior diagnoses recorded in the system over the year before the ED visit.
例如,要诊断某些糖尿病并发症,眼科医生必须将患者的视网膜可视化,寻找细微的损伤迹象。 一个Google团队构建了一种深度学习算法,该算法可以查看数字化的视网膜照片,并可以甚至比医生更准确地进行诊断。 到目前为止,一切都很好。 但是,这些预测越来越广泛地用于影响政策决策:量身定制的诊断程序可以帮助医生决定对谁进行检查和治疗。 在卫生政策的应用,算法依赖于电子健康记录或索赔数据,使他们的预测,开门的误测来的错误。 哈佛大学的一组研究人员分析了访问急诊室(ED)的患者的数据,目的是预测在ED访视后的几天中有即将发生中风的高风险人群。 这些患者可能很难与更良性的表现区分开。 但是,如果能够确定它们,则可以针对急诊室中更有效的干预措施,或安排密切随访。 看来这是一个经典的预测问题,不需要证明因果关系,而只是对中风的短期风险进行了很好的预测。 作为属性,他们使用了人口统计学数据以及在ED访问之前一年中系统中记录的所有先前诊断。
When they analyzed the top predictors leading to a stroke diagnosis, prior stroke was, as expected, the strongest, followed by history of cardiovascular disease, a well known risk factor for stroke. The other four predictors — accidental injury, benign breast lump, colonoscopy, and sinusitis — were somewhat more mysterious. Did they just discovered new risk factors for stroke? Well, not exactly. Medical data are as much behavioral as biological; whether a person decides to seek care can be as pivotal as actual stroke in determining whether they are diagnosed with stroke. The algorithm was just as much predicting heavy utilization (the propensity of people to seek care) as was biological stroke. Variables which proxy for heavy utilization could in fact appear to predict any medical condition, including stroke.
当他们分析导致中风诊断的最主要预测因素时,如预期的那样,先前的中风最强,其次是心血管疾病史,这是众所周知的中风危险因素。 其他四个预测因素-意外伤害,乳房良性肿块,结肠镜检查和鼻窦炎-则更为神秘。 他们是否刚刚发现中风的新危险因素? 好吧,不完全是。 医学数据的行为与生物学一样多。 在决定是否诊断为中风时,一个人是否决定寻求护理与实际中风一样重要。 该算法与生物中风一样,可以预测大量使用(人们寻求护理的倾向)。 实际上,代表大量使用的变量似乎可以预测任何医疗状况,包括中风。
An so on, examples of the damage of letting AI run unchecked to optimize metrics are endless, from Google/YouTube’s heavy promotion of white supremacist material, essay grading software that rewards garbage, teacher being fired by an algorithm, and more.
诸如此类,无止境地让AI运行以优化指标的危害的例子无穷无尽,例如Google / YouTube大力推广白人至上主义者的材料 , 奖励垃圾的论文分级软件, 被算法解雇的老师等等。
衡量公平并减轻偏见 (Measuring fairness and mitigating bias)
Since algorithms optimize a single metric what can we do to prevent or mitigate the harms caused by AI? A first step is to learn how to measure the fairness of an algorithm. In order to do so we need a formulate fairness in a way that can be utilized in ML systems, that is quantitatively: in recent years more than 20 definitions of fairness have been introduced, yet there is no clear agreement on which definition to apply in each situation.
由于算法优化了单个指标,我们该如何预防或减轻AI造成的危害? 第一步是学习如何衡量算法的公平性。 为了做到这一点,我们需要以一种可以在机器学习系统中使用的方式来制定公平性,即在数量上: 近年来,已经引入了20多个公平性定义 ,但是对于在哪个定义中应用公平性尚无明确协议。每种情况。
IBM has developed and open sourced the AI Fairness 360 Python package that includes a comprehensive set of metrics to test for biases, explanations for these metrics, and algorithms to mitigate bias in datasets and models. An interactive demo allows anyone to test four bias mitigation approaches on three different problems: census income prediction, credit scoring and, guess what, the COMPAS recidivism problem. Using gender and race as protected attributes, it evaluates the fairness of the algorithm over the metrics below:
IBM开发并开源了AI Fairness 360 Python软件包 ,该软件包包括一整套用于测试偏差的度量标准,这些度量的解释以及减轻数据集和模型偏差的算法。 交互式演示使任何人都可以针对三种不同的问题测试四种缓解偏倚的方法:人口普查收入预测,信用评分以及COMPAS累犯问题。 使用性别和种族作为受保护的属性,它根据以下指标评估算法的公平性:
Statistical parity: subjects in both protected and unprotected groups have equal probability of being assigned to the positive predicted class;
统计均等性 :受保护和不受保护的组中的对象被分配到阳性预测类别的可能性相同;
Equal opportunity: the difference of true positive rates between the unprivileged and the privileged group. At the heart of this approach is the idea that individuals who qualify for a desirable outcome should have an equal chance of being correctly classified for this outcome;
机会均等 :无特权者与有特权者之间的真实阳性率之差。 这种方法的核心思想是,有资格获得理想结果的个人应有同等的机会被正确分类为该结果;
Average odds: a combination of the two above, this implies that the probability of an applicant with an actual good score to be correctly assigned a good predicted score and the probability of an applicant with an actual bad score to be incorrectly assigned a good predicted score should both be same for privileged and unprivileged applicants;
平均赔率 :上述两项的总和 ,这意味着具有实际好分数的申请人被正确分配良好的预期分数的概率和具有实际不良分数的申请人被错误分配了良好的预期分数的概率特权和非特权申请人都应相同;
Disparate impact: the ratio in the probability of favorable outcomes between the unprivileged and privileged groups. For instance, if women are 70% as likely to receive a good rating as men, this represents a disparate impact. It is a measure of discrimination in the data.
不同的影响 :无特权和有特权的群体之间取得有利结果的概率之比。 例如,如果女性获得良好评价的可能性是男性的70%,那么这将产生不同的影响。 它是对数据歧视的一种度量。
Theil index: (not Thiel, please) it is derived from information theory as a measure of redundancy in data, i.e. the amount of wasted “space” used to transmit certain data. In information theory a measure of redundancy can be interpreted as non-randomness, therefore in this context it can be viewed as a measure of lack of diversity, isolation, segregation, inequality, non-randomness.
泰尔指数 :(不是泰尔 ,请),它是根据信息理论得出的,用于衡量数据的冗余度 ,即用于传输某些数据的浪费“空间”的数量。 在信息论中,冗余的量度可以解释为非随机性,因此在这种情况下,它可以看作是缺乏多样性,隔离,隔离,不平等,非随机性的量度。
The test detected high level of bias in 4 out of 5 metrics for both attributes, with an accuracy of 66% when no mitigation is applied.
该测试针对这两个属性在5个指标中的4个中检测到高水平的偏见,在未应用缓解措施的情况下,其准确性为66%。
It then proposes four different algorithms to mitigate bias. The choice of which to use depends on whether you want to fix the data (pre-process), the classifier (in-process), or the predictions (post-process). The rule of thumb is the earlier, the better. However, that depends on the ability to intervene at different parts of a machine learning pipeline. If the user is allowed to modify the training data, then preprocessing can be used. If the user is allowed to change the learning algorithm, then in-processing can be used. If the user can only treat the learned model as a black box without any ability to modify the training data or learning algorithm, then only post-processing can be used. The proposed algorithms are:
然后提出了四种不同的算法来减轻偏差。 使用哪种选择取决于您要修复数据(预处理),分类器(处理中)还是预测(后处理)。 经验法则越早越好。 但是,这取决于在机器学习管道的不同部分进行干预的能力。 如果允许用户修改训练数据,则可以使用预处理。 如果允许用户更改学习算法,则可以使用处理中。 如果用户只能将学习的模型视为黑匣子,而无权修改训练数据或学习算法,则只能使用后处理。 提出的算法是:
Reweighing: it assigns different weights to the examples based upon their categories of protected attribute and outcome such that bias is removed from the training dataset;
重称 :根据示例的受保护属性和结果类别,为示例分配不同的权重,从而从训练数据集中消除偏差;
Optimized Preprocessing: learns a probabilistic transformation that can modify the features and the labels in the training data
优化的预处理 :学习概率转换,可以修改训练数据中的特征和标签
Adversarial Debiasing: apart from the original task of predicting a class the model is also predicting the protected attribute and is penalized for doing it correctly. The objective is to maximize the model predictor’s ability while minimizing the adversary’s ability to predict the protected attribute.
对抗性反偏 :除了最初的预测类任务之外,模型还预测了受保护的属性,并且由于做得正确而受到惩罚。 目的是最大化模型预测器的能力,同时最小化对手预测受保护属性的能力。
Reject Option Based Classification (ROC): the assumption is that most discrimination occurs when a model is least certain of the prediction i.e. around the decision boundary (classification threshold). For example, with a classification threshold of 0.5, if the model prediction is 0.81 or 0.1, we would consider the model certain of its prediction but for 0.51 or 0.49, the model is not confident about the chosen category. So, for model predictions with the highest uncertainty around the decision boundary, when the favorable outcome is given to the privileged group or the unfavorable outcome is given to the unprivileged, we invert the outcomes.
基于拒绝选项的分类(ROC) :一种假设是,当模型对预测的确定性最低(即,围绕决策边界(分类阈值))时,大多数歧视都会发生。 例如,在分类阈值为0.5的情况下,如果模型预测为0.81或0.1,我们将模型视为其预测的确定性,但对于0.51或0.49,模型对所选类别没有信心。 因此,对于决策边界周围不确定性最高的模型预测,当将有利结果提供给特权组或不利结果给无特权组时,我们会将结果反转。
In case you are intimidated by the jargon you should know that AI people like using resonant names like Rectified Linear Unit or Negative Log Likelihood for quite straightforward concepts. Anyway, we got the following results:
万一您被行话吓倒了,您应该知道,AI人喜欢使用共振的名称,例如“ 整流线性单位”或“ 负对数似然”来表示非常简单的概念。 无论如何,我们得到了以下结果:
- the reweighing algorithm reduced bias to acceptable levels for 4 metrics out of 5 (one was already fine) without reducing accuracy for both protected attributes (race and gender); 重新称重算法将5个指标中的4个指标的偏差降低到可接受的水平(一个已经很好),而没有降低两个受保护属性(种族和性别)的准确性;
- Optimized Preprocessing, instead, did not reduce bias while accuracy decreased to 65% on gender, while it reduced bias to acceptable levels for 4 metrics out of 5 on race, with accuracy improved to 67%; 相反,优化的预处理不能减少偏见,而将性别的准确度降低到65%,而可以将种族中5分之4的偏倚降低到可接受的水平,准确度提高到67%;
- Adversarial debiasing reduced bias on gender to acceptable levels for 4 metrics without compromising accuracy, but it only reduced one bias out of 4 to acceptable levels on race, while accuracy decreased to 65%; 对抗性偏见在不影响准确性的情况下将性别偏见降低到4个度量标准的可接受水平,但在种族中仅将4个度量标准中的1个偏见降低到可接受的水平,而准确性降低到65%;
- ROC reduced bias on gender to acceptable levels for 3 out of 4 biased metrics with accuracy at 65%, while it reduced bias on all metrics on race, with accuracy at 65%. ROC在4个偏倚指标中,有3个将性别偏见降低到可接受的水平,准确度为65%,而在种族方面,所有偏见指标的偏见均降低为65%。
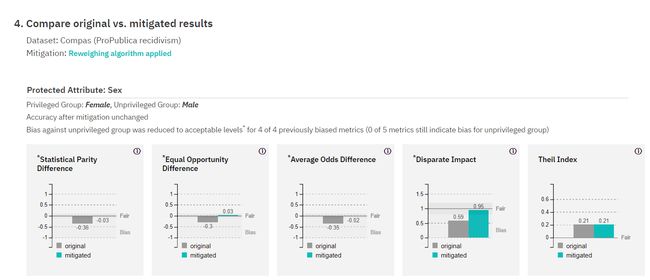
The case study above seems to confirm that the rule of thumb “the earlier the better” holds, provided one has access to the data in the preprocessing stage. As expected some algorithms are more effective than others at improving the fairness metrics, but one important fact is that none of them affects accuracy dramatically: in the worst case scenario accuracy drops only by one point percentage, thereby confirming that bias can be mitigated without affecting the business metrics.
上面的案例研究似乎证实了“越早越好”的经验法则,前提是人们可以在预处理阶段访问数据。 不出所料,某些算法在改善公平性指标方面比其他算法更有效,但是一个重要的事实是,它们都不会对准确性产生重大影响:在最坏的情况下,准确性仅下降一个百分点,从而确认可以缓解偏差而不影响准确性。业务指标。
结论 (Conclusions)
There is a lot of talk about ethics in AI these days. It’s hard to attend an AI-related conference anymore without part of the program being dedicated to ethics.
如今,关于AI中的伦理学的话题很多。 如果计划的一部分不涉及道德问题,那么再也很难参加与AI相关的会议。
But just talk it’s not enough, as most organizations AI ethical guidelines are vague and hard to enforce, with ethical washing risks, as showed by the Google ethical board debacle.
但是,仅仅说这还不够 ,因为大多数组织的AI道德准则含糊不清且难以执行,并且存在道德清洗的风险,正如Google道德委员会崩溃所显示的那样。
Not everything is doom and gloom: the AI Now Institute reported that last year saw a wave of pushback, as community groups, researchers, policymakers, and workers demanded a halt to risky and dangerous AI. Those — not corporate AI ethics statements and policies — have been primarily responsible for pressuring tech companies and governments to set guardrails on the use of AI.
并非所有的事情都是厄运和阴霾: AI Now Institute报道说,随着社区团体,研究人员,政策制定者和工人要求停止危险和危险的AI , 去年出现了一波倒退 。 这些不是公司的AI伦理声明和政策,主要是促使技术公司和政府为使用AI设置护栏。
We showed in this post how researchers and companies are pushing into developing metrics and algorithms that can help mitigate bias and increase algorithmic fairness. Those approaches are promising, but their urgent adoption is crucial, as efforts to regulate are being outpaced by governments rapid adoption of AI systems to surveil and control.
我们在这篇文章中展示了研究人员和公司如何推动度量和算法的开发,以帮助减轻偏差并提高算法公平性。 这些方法是有希望的,但由于政府Swift采用AI系统进行监视和控制已无法满足监管要求,因此迫切需要采用这些方法。
翻译自: https://medium.com/dataseries/yes-ai-can-be-racist-and-sexist-so-what-do-we-have-to-do-89c3c908926c
百度ai 性别