分词Python实现_文本处理NLP:分词与词云图
昨晚我们又做了一次技术分享,继续上次技术分享的话题“文本数据的处理”。上次,我们分享了文本处理的方方面面的知识点,比较宏观,这次我们就其中的一点“分词”展开。
一、为什么要分词
“行文如流水”形容的是诗文、书法自然流畅不受拘束。这里我们借用一下就是,中文句子词汇之间如流水般无缝,不像英文那样单词之间用空格分开。比如:
中文:我在猿人学网站上学Python
英文:I learn Python on YuanRenXue.
在程序里,从英文中得到一个一个单词很简单,用Python字符串的split()函数就可以搞定。而对于中文做同样的事情就比较难了,这时候我们就需要一个分词程序专门搞这件事。
词汇是语义表达的基本单位。词语比单个字表达的意思更为精准。在搜索引擎里面,建立倒排索引的时候,需要对文本进行分割为一个个的语素,是分成一个一个的字好呢,还是分割成一个个词好呢?我们来看看下面的例子。
首先,我们先简单理解一下“倒排索引”这个概念。我们可以把它类比成一个Python的字典,key是索引的语素(字或词),value是一个包含这个语素的文档ID的列表。下面我们对“我早上在海边跑步”这句话进行分割、索引,假设这句话的文档ID是1。
按字分割:我/早/上/在/海/边/跑/步
索引:

在这个索引里面搜“上海”,先把查询词按照索引时同样的方法分割为“上”和“海”两个字,然后分别搜这两个字,索引里面都包含这两个字,它们都对应这ID为1的文档,也就是搜索到了文档ID为1的文档。但是,这句“我早上在海边跑步”跟“上海”是没什么关心的。
也就是说,按字分割索引会让搜索引擎搜出很多不相关的结果出来。那么,按词索引呢?
按词分割:我/早上/在/海边/跑步
建立索引:
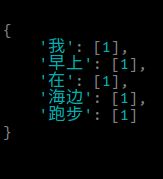
从这个索引里面找“上海”就不能找到,从而不会返回不相关的结果。
二、分词的原理
分词是一个技术活也是一个累活儿。如果分词是建立在新闻类的语料基础上的,它对其它领域比如化工、医学等等领域的文本的分词效果往往不会好。这就需要我们对行业领域词汇进行收集,加入到分词词典中,才能得到更好的效果,这个过程是比较累人的。
分词的方法一般有以下几种:
1、基于词典的方法
这个方法朴素而快速,但不能很好的解决歧义和未收录词。歧义就是下面这种句子根据词典可以有多种分割方法:
“结婚/的/和/尚未/结婚/的”
“结婚/的/和尚/未/结婚/的”
未收录词就是分词词典没有包含的那些词,这个问题可以通过不断扩展词典在某种程度上解决。
2、机器学习的方法
首先,要人工标注大批量的语料给机器学习算法进行学习。标注的过程要耗费大量人力,标注的语料越多,机器学习的效果越好。机器学习的方法有HMM、CRF,以及近年流行的深度学习。它对歧义和未收录词的问题有较好的解决。但是,大量领域语料的缺失,也导致它不能很好的直接应用于其它专业领域。
三、jieba分词工具
上次技术分享中,我们介绍了多款分词工具。jieba作为一个纯Python实现的工具,使用起来非常方便。它支持简体和繁体分词,也可以自定义词典方便我们扩展领域词。
结巴有三种分词模式:
精确模式:适合文本分析。此法最常用
全模式,把句子中所有可能的词都列出来。基本没啥用
搜索引擎模式:把长词切分为短词,让搜索引擎提高召回率。建立搜索引擎的索引时用
安装jieba很简单:
pip install jieba
使用结巴进行分词主要有两个函数:
jieba.cut(text, cut_all=False, HMM=True)
jieba.cut_for_search(sentence, HMM=True)
其中,cut()函数最为常用。参数cut_all=True的话就开启了全模式,这种模式几乎不需要。默认的HMM=True会使用HMM模型尝试检测未登录词。
写个简单的程序来测试一下几种不同的分词模式:
得到的结果如下:
精确模式:
猿人/ 学是/ 一个/ 学习/ Python/ 的/ 网站
全模式:
猿人/ 人学/ 是/ 一个/ 学习/ Python/ 的/ 网站
搜索引擎模式:
猿人/ 学是/ 一个/ 学习/ Python/ 的/ 网站
精确模式下,会把“学是”当做一个词分出来,这就是HMM计算的结果,当然对于这个例子,它计算错了。
“猿人学”应该是一个词,但它没有分出来。这个时候我们就需要自定义词典。
添加自定义的词,有两种方法:
(1)通过函数添加:
jieba.add_word('猿人学', freq=5, tag='n')
可以多次调用这个函数,添加更多的词。
(2)通过词典文件:
jieba.load_userdict(file_name)
file_name就是一个词典文件的路径,它是一个文本文件,每行一个词,后面可以跟着它的频率和词性:
猿人学 8 n
js逆向 7
APP脱壳 n
异步IO
词性标注
jieba支持词性标注,具体在它的子模块 jieba.posseg
>>> import jieba.posseg as pseg
>>> words = pseg.cut('我在猿人学学Python')
>>> for word, flag in words:
print('{} {}'.format(word, flag))
我 r
在 p
猿人学 n
学 n
Python eng
词性标注可以帮助我们更好的筛选文章主题词(或者叫关键词)。比如,介词、数量词不然名词、动词的意义更丰富,提取关键词时可以对名词等赋予更高的权重。
主题词提取
jieba提供的主题词提取的功能,具体在 jibba.analyse 子模块。它有两种算法的实现,分别是TF-IDF算法和TextRank算法。两者的效果差不多,但后者计算量大很多,比较慢。所以,推荐使用前者。
TF-IDF算法
jieba.analyse.extract_tags(
text,
topK=20,
withWeight=False,
allowPOS=())
text 为待提取的文本
topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
withWeight 为是否一并返回关键词权重值,默认值为 False
allowPOS 仅包括指定词性的词,默认值为空,即不筛选词-权重
TextRank算法
jieba.analyse.textrank(
text,
topK=20,
withWeight=False,
allowPOS=('ns', 'n', 'vn', 'v'))
直接使用,接口相同,注意默认过滤词性。
四、词云图:可视化主题词
前面我们通过jieba提取了文章的主题词,可以使用“词云图”这种方法把它可视化的表现出来。
Python有个画词云图的第三方模块:wordcloud。用pip直接安装:
pip install wordcloud
使用它主要有两个类:
WordCloud([font_path, width, height, …])
画词云图的类
ImageColorGenerator(image[, default_color])
从一张彩色图片中生成词云图的颜色
使用WordCloud类进行词云图绘制过程,需要注意的地方:
中文字体 : 必须指定中文字体,不然中文就画不出来。
mask :以图片物体形状绘制词云图。非物体形状部分为白色,颜色值为#FFF 或 #FFFFFF
图片颜色->字体颜色:使用ImageColorGenerator 从mamsk图片提取颜色,把对应位置的字体颜色设置为同样的颜色。
下面,我们以Python的logo作为词云图形状进行绘制。

文章内容是猿人学网站上的文章《大规模异步新闻爬虫的实现思路》,通过jieba提取主题词,然后进行绘制。代码如下 :

运行这段代码后,生成了两个词云图,第一张是随机生成的字体颜色:

第二张是根据Python logo 图片中的颜色绘制字体颜色:

如果你选择色彩更丰富的图片,绘制出来的词云图色彩也会更丰富。
这次技术分享,我们把jieba分词的使用结合实例介绍给大家,最后使用wordcloud做了主题词的可视化呈现。