Spring IoC容器初始化源码(4)—<context:component-scan/>标签解析、spring.components扩展点、自定义Spring命名空间扩展点
基于最新Spring 5.x,介绍了包括< context:component-scan/>扩展标签解析源码、spring.components扩展点、自定义Spring命名空间扩展点!
上一篇文章:Spring IoC容器初始化源码(3)—parseDefaultElement、parseCustomElement解析默认、扩展标签,registerBeanDefinition注册Bean定义中,我们主要讲解了parseDefaultElement解析默认标签的方法、parseCustomElement解析扩展标签的方法和registerBeanDefinition注册bean定义的方法的源码!
现在我们看几个详细案例,包括< context:component-scan/>扩展标签解析源码、spring.components扩展点、自定义Spring命名空间扩展点!
Spring IoC容器初始化源码 系列文章
Spring IoC容器初始化源码(1)—setConfigLocations设置容器配置信息
Spring IoC容器初始化源码(2)—prepareRefresh准备刷新、obtainFreshBeanFactory加载XML资源、解析<beans/>标签
Spring IoC容器初始化源码(3)—parseDefaultElement、parseCustomElement解析默认、扩展标签,registerBeanDefinition注册Bean定义
Spring IoC容器初始化源码(4)—<context:component-scan/>标签解析、spring.components扩展点、自定义Spring命名空间扩展点
Spring IoC容器初始化源码(5)—prepareBeanFactory、invokeBeanFactoryPostProcessors、registerBeanPostProcessors方法
Spring IoC容器初始化源码(6)—finishBeanFactoryInitialization实例化Bean的整体流程以及某些扩展点
Spring IoC容器初始化源码(7)—createBean实例化Bean的整体流程以及构造器自动注入
Spring IoC容器初始化源码(8)—populateBean、initializeBean实例化Bean以及其他依赖注入
< context:property-placeholder/>标签以及PropertySourcesPlaceholderConfigurer占位符解析器源码深度解析
三万字的ConfigurationClassPostProcessor配置类后处理器源码深度解析
基于JavaConfig的AnnotationConfigApplicationContext IoC容器初始化源码分析
文章目录
- Spring IoC容器初始化源码 系列文章
- 1 自定义命名空间扩展点
- 2 < context:component-scan/>扩展标签解析
-
- 2.1 resolvePlaceholders非严格解析占位符
- 2.2 configureScanner创建配置扫描器
-
- 2.2.1 createScanner创建配置扫描器
-
- 2.2.1.1 registerDefaultFilters注册默认的类型过滤器
- 2.4.2.2. parseTypeFilters解析类型过滤器标签
- 2.2.2.1 createTypeFilter创建TypeFilter
- 2.3 doScan扫描以及注册BeanDefinition
-
- 2.3.1 findCandidateComponents查找BeanDefinition
-
- 2.3.1.1 scanCandidateComponents扫描包下的BeanDefinition
-
- 2.3.1.1.1 isCandidateComponent检查类型过滤器TypeFilter
- 2.3.1.1.2 isCandidateComponent检查bean定义
- 2.3.2. generateBeanName生成beanName
-
- 2.3.2.1 determineBeanNameFromAnnotation查找beanName
- 2.3.2.2 buildDefaultBeanName生成默认beanName
- 2.3.3 postProcessBeanDefinition设置默认值
- 2.3.4 processCommonDefinitionAnnotations解析其他注解
- 2.3.5 checkCandidate检查重复beanName
- 2.3.6 Spring5的spring.components扩展点
-
- 2.3.6.1 spring.components组件索引文件的读取
- 2.3.6.2 indexSupportsIncludeFilters组件索引支持
- 2.3.6.3 addCandidateComponentsFromIndex基于componentsIndex加载bean定义
-
- 2.3.6.3.1 extractStereotype提取过滤类型
- 2.3.6.3.2 getCandidateTypes返回满足条件的bean类型
- 2.3.6.4 spring.components文件的格式以及加载格式
- 2.3.6.5 spring.components扩展点案例
- 2.4 registerComponents注册组件
-
- 2.4.1 registerAnnotationConfigProcessors注册注解配置处理器
- 3 小结
1 自定义命名空间扩展点
现在,让我们尝试自定义命名空间,以及自定义标签。当然除了Spring的相关知识以外,这里更多的是需要XML的知识。
我们在resources目录下面新建一个META-INF目录,加入三个配置文件:

my-custom.xsd文件如下,这是一个Schema约束文件,用于对xml文件的标签设定时候的添加一些限制,避免无用标签被添加。
<xsd:schema
xmlns="http://com.spring/schema/my"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://com.spring/schema/my"
elementFormDefault="qualified">
<xsd:element name="custom">
<xsd:annotation>
<xsd:documentation>
xsd:documentation>
xsd:annotation>
<xsd:complexType>
<xsd:sequence>
<xsd:element ref="property" minOccurs="0" maxOccurs="unbounded"/>
xsd:sequence>
<xsd:attribute name="id" type="xsd:ID"/>
<xsd:attribute name="property1" type="xsd:int"/>
<xsd:attribute name="property2" type="xsd:string" use="required"/>
xsd:complexType>
xsd:element>
<xsd:element name="property">
<xsd:complexType>
<xsd:attribute name="property3" type="xsd:date">
<xsd:annotation>
<xsd:documentation>xsd:documentation>
xsd:annotation>
xsd:attribute>
xsd:complexType>
xsd:element>
xsd:schema>
spring.handlers 如下,用于定义命名空间到NamespaceHandler的实现的映射:
http\://com.spring/schema/my=com.spring.custom.handler.MyNamespaceHandler
spring.schemas如下,用于定义schema约束文件的位置:
http\://com.spring/schema/custom/my-custom.xsd=META-INF/my-custom.xsd
接着定义一个com.spring.custom.handler.MyCustomDefinitionParser,实现了BeanDefinitionParser,专门用来解析< custom/>标签:
/**
* custom标签的bean定义解析器
*
* @author lx
*/
public class MyCustomDefinitionParser implements BeanDefinitionParser {
@Override
public BeanDefinition parse(Element element, ParserContext parserContext) {
//创建bean定义
RootBeanDefinition beanDefinition = new RootBeanDefinition();
beanDefinition.setBeanClass(MyCustom.class);
MutablePropertyValues mutablePropertyValues = beanDefinition.getPropertyValues();
//设置property1属性
if (element.hasAttribute("property1")) {
mutablePropertyValues.addPropertyValue("property1", element.getAttribute("property1"));
}
//设置property2属性
if (element.hasAttribute("property2")) {
mutablePropertyValues.addPropertyValue("property2", element.getAttribute("property2"));
}
//设置property3属性
NodeList nodeList = element.getChildNodes();
ArrayList arrayList = new ArrayList<LocalDate>();
for (int i = 0; i < nodeList.getLength(); i++) {
Node node = nodeList.item(i);
if (node instanceof Element) {
arrayList.add(LocalDate.parse(node.
getAttributes().
getNamedItem("property3").
getNodeValue(), DateTimeFormatter.ofPattern("yyyy-MM-dd")));
}
}
mutablePropertyValues.addPropertyValue("property3", arrayList);
//获取id
String id = element.getAttribute("id");
Assert.hasText(id, "id不能为空");
//注册BeanDefinition
parserContext.getRegistry().registerBeanDefinition(id, beanDefinition);
return beanDefinition;
}
}
接着定义一个com.spring.custom.handler.MyNamespaceHandler,实现了NamespaceHandlerSupport,专门用来注册MyCustomDefinitionParser自定义解析器:
/**
* 自定义的命名空间处理器
*
* @author lx
*/
public class MyNamespaceHandler extends NamespaceHandlerSupport {
@Override
public void init() {
//注册解析custom标签的解析器
registerBeanDefinitionParser("custom", new MyCustomDefinitionParser());
}
}
接着定义一个com.spring.custom.handler.MyCustom,作为测试类:
/**
* @author lx
* @date 2020/10/5 15:30
*/
public class MyCustom {
private int property1;
private String property2;
private List<LocalDate> property3;
public void setProperty1(int property1) {
this.property1 = property1;
}
public void setProperty2(String property2) {
this.property2 = property2;
}
public void setProperty3(List<LocalDate> property3) {
this.property3 = property3;
}
@Override
public String toString() {
return "MyCustom{" +
"property1=" + property1 +
", property2='" + property2 + '\'' +
", property3=" + property3 +
'}';
}
}
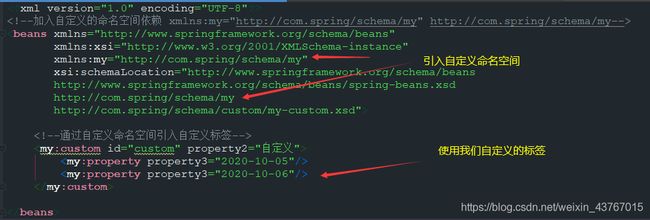
接下来就是熟悉的XML文件的编写。新建一个spring-config-mycustom.xml文件,然后引入我们的自定义命名空间,这样就可以使用我们的自定义标签了:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:my="http://com.spring/schema/my"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://com.spring/schema/my
http://com.spring/schema/custom/my-custom.xsd">
<my:custom id="custom" property2="自定义">
<my:property property3="2020-10-05"/>
<my:property property3="2020-10-06"/>
my:custom>
beans>
添加测试:
@Test
public void myCustomElement() {
ClassPathXmlApplicationContext ac = new ClassPathXmlApplicationContext("spring-config-mycustom.xml");
System.out.println(ac.getBean("custom"));
}
如果该项目需要作为jar包被其他项目引用,那么就需要打成jar包,但是这里我们就是在本项目测试,那么编译就行了:
接着运行测试,结果如下,成功执行我们的自定义标签解析!
MyCustom{
property1=0, property2='自定义', property3=[2020-10-05, 2020-10-06]}
2 < context:component-scan/>扩展标签解析
NamespaceHandlerSupport的parser方法,最终会根据标签名从parsers缓存中查找对应的解析器来解析,对于某个外部的标签,我们只需要直到它对应的解析器是哪一个类即可去学习它的解析源码,并且这些解析器的类名非常容器辨认。
XML的IoC配置中,一个非常重要的外部命名空间标签就是< context:component-scan/>标签,此前我们已经学习过它的作用了,该标签用于开启指定包下面的组件注解的支持。现在我们来学习Spring对于< context:component-scan/>外部标签的解析的源码,该标签是使用ComponentScanBeanDefinitionParser解析器来解析的! 其他的扩展标签并不是说不重要,比如aop、tx系列标标签等等,只是源码太多了,留待后面有空再解析,学习了本部分内容之后我们也可以自己去尝试看其他标签的解析源码。
ComponentScanBeanDefinitionParser的parser方法大概步骤如下:
- 首先获取"base-package"属性 的值,该属性是必须的,这就是要扫描组件的包路径。
- 使用环境变量对象的resolvePlaceholders方法来解析basePackage包路径字符串中的占位符,这说明basePackage也可以使用占位符${…:…}。resolvePlaceholders将会使用非严格的PropertyPlaceholderHelper模式,忽略没有默认值的无法解析的占位符,直接采用原值而不会抛出异常,${…:…}占位符的解析我们在此前的setConfigLocations部分已经讲过了。注意,这里的占位符只支持environment中的属性。
- 将传递的路径字符串根据分隔符分割为一个路径字符串数组,支持以","、";"、" “、”\t"、"\n"中的任意字符作为分隔符来表示传递了多个包路径。
- 获取一个配置扫描器ClassPathBeanDefinitionScanner,使用配置扫描器在指定的basePackage包路径中扫描符合规则的bean的定义,并且注册到注册表缓存中。
- 注册一些组件,比如一些注解后处理器,主要用于解析对应的注解,对Spring容器里已注册的bean进行装配、依赖注入,甚至添加新的bean(比如@Bean注解),这是< context:component-scan/>能够实现注解支持的关键。
- 返回BeanDefinition,实际上直接返回null。
/**
* ComponentScanBeanDefinitionParser的属性
*
* base-package属性名称常量
*/
private static final String BASE_PACKAGE_ATTRIBUTE = "base-package";
/**
* ConfigurableApplicationContext的属性
*
* 分隔符常量,支持","、";"、" "、"\t"、"\n"中的任意分隔符
*/
String CONFIG_LOCATION_DELIMITERS = ",; \t\n";
/**
* ComponentScanBeanDefinitionParser的方法
*
* 解析
@Override
@Nullable
public BeanDefinition parse(Element element, ParserContext parserContext) {
/*
* 1 首先获取"base-package"属性的值,因为该属性是必须的
*/
String basePackage = element.getAttribute(BASE_PACKAGE_ATTRIBUTE);
/*
* 2 使用环境变量对象的resolvePlaceholders方法来解析basePackage包路径字符串中的占位符,这说明basePackage也可以使用占位符${..:..}
*
* resolvePlaceholders将会使用非严格的PropertyPlaceholderHelper模式,忽略没有默认值的无法解析的占位符,直接采用原值而不会抛出异常
* ${..:..}占位符的解析我们在此前的setConfigLocations部分已经讲过了。注意,这里的占位符只支持environment中的属性。
*/
basePackage = parserContext.getReaderContext().getEnvironment().resolvePlaceholders(basePackage);
/*
* 3 将传递的路径字符串根据分隔符分割为一个路径字符串数组
*
* 支持以","、";"、" "、"\t"、"\n"中的任意字符作为分隔符来表示传递了多个包路径
*/
String[] basePackages = StringUtils.tokenizeToStringArray(basePackage,
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
/*
* 4 获取一个配置扫描器ClassPathBeanDefinitionScanner
*
* 使用配置扫描器在指定的basePackage包路径中扫描符合规则的bean的定义,并且注册到注册表缓存中
*/
ClassPathBeanDefinitionScanner scanner = configureScanner(parserContext, element);
Set<BeanDefinitionHolder> beanDefinitions = scanner.doScan(basePackages);
/*
* 5 注册一些组件,比如一些注解后处理器
*
* 主要用于解析对应的注解,对Spring容器里已注册的bean进行装配、依赖注入,甚至添加新的bean(比如@Bean注解)
*/
registerComponents(parserContext.getReaderContext(), beanDefinitions, element);
//返回null
return null;
}
2.1 resolvePlaceholders非严格解析占位符
使用环境变量对象的resolvePlaceholders方法来解析包路径字符串,这说明包路径也可以使用占位符${…:…},这一步就是解析替换占位符。resolvePlaceholders方法将会使用非严格的PropertyPlaceholderHelper,忽略无法解析的占位符而不会抛出异常。
实际上只会使用environment中的属性,context:property-placeholder/标签等普通方式配置的属性获取不到。
/**
* AbstractEnvironment的方法
*
* 解析路径占位符,忽略没有默认值的无法解析的占位符,直接采用原值而不会抛出异常
*
* @param text 路径字符串
* @return 解析后的字符串
*/
@Override
public String resolvePlaceholders(String text) {
//调用propertyResolver的resolvePlaceholders方法
return this.propertyResolver.resolvePlaceholders(text);
}
/**
* AbstractPropertyResolver的方法
*
* 解析路径占位符,在setConfigLocations部分中我们学习的是resolveRequiredPlaceholders方法
* 它们的区别是,resolvePlaceholders将忽略没有默认值的无法解析的占位符而使用原值
* 而resolveRequiredPlaceholders遇到没有默认值的无法解析的占位符则抛出IllegalArgumentException异常
*
* @param text 路径字符串
* @return 解析后的字符串
*/
@Override
public String resolvePlaceholders(String text) {
//可以看到,这里初始化PlaceholderHelper时,传递的ignoreUnresolvablePlaceholders参数为true
//这表示忽略没有默认值的无法解析的占位符
if (this.nonStrictHelper == null) {
this.nonStrictHelper = createPlaceholderHelper(true);
}
//随后调用doResolvePlaceholders方法,这个方法我们在前一篇文章的setConfigLocations部分已经重点解析过了
return doResolvePlaceholders(text, this.nonStrictHelper);
}
2.2 configureScanner创建配置扫描器
该方法用于创建一个ClassPathBeanDefinitionScanner类型的配置扫描器,用于解析器其它的标签属性以及子标签,最重要的是扫描指定包路径下面的基于组件注解配置的beanDefinition。
由于其他属性我们一般都不会使用到,因此我们主要讲解TypeFilter类型过滤器相关的方法,因为TypeFilter就是用来指定扫描带有某些注解的类或者排除某些注解的类的扫描,对应着< include-filter/>和< exclude-filter/>子标签,还算比较重要(但其实仍然用的比较少)!
//----------ComponentScanBeanDefinitionParser的相关属性
/**
* use-default-filters属性名称常量
*/
private static final String USE_DEFAULT_FILTERS_ATTRIBUTE = "use-default-filters";
/**
* resource-pattern属性名称常量
*/
private static final String RESOURCE_PATTERN_ATTRIBUTE = "resource-pattern";
/**
* ComponentScanBeanDefinitionParser的方法
*
* 获取配置扫描器ClassPathBeanDefinitionScanner
*
* @param parserContext 解析上下文
* @param element 标签元素节点
* @return 一个配置扫描器ClassPathBeanDefinitionScanner
*/
protected ClassPathBeanDefinitionScanner configureScanner(ParserContext parserContext, Element element) {
//useDefaultFilters表示use-default-filters属性的值,默认就是true
boolean useDefaultFilters = true;
//如果设置了USE_DEFAULT_FILTERS_ATTRIBUTE属性,这个属性是非必需的
if (element.hasAttribute(USE_DEFAULT_FILTERS_ATTRIBUTE)) {
//设置useDefaultFilters的值
useDefaultFilters = Boolean.parseBoolean(element.getAttribute(USE_DEFAULT_FILTERS_ATTRIBUTE));
}
/*
* 1 创建ClassPathBeanDefinitionScanner,将 bean 定义的注册委托给扫描器类
*/
ClassPathBeanDefinitionScanner scanner = createScanner(parserContext.getReaderContext(), useDefaultFilters);
scanner.setBeanDefinitionDefaults(parserContext.getDelegate().getBeanDefinitionDefaults());
scanner.setAutowireCandidatePatterns(parserContext.getDelegate().getAutowireCandidatePatterns());
//如果设置了resource-pattern属性,这个属性是非必需的
if (element.hasAttribute(RESOURCE_PATTERN_ATTRIBUTE)) {
//设置该属性的值
scanner.setResourcePattern(element.getAttribute(RESOURCE_PATTERN_ATTRIBUTE));
}
try {
//解析name-generator属性
parseBeanNameGenerator(element, scanner);
} catch (Exception ex) {
parserContext.getReaderContext().error(ex.getMessage(), parserContext.extractSource(element), ex.getCause());
}
try {
//解析scope-resolver和scoped-proxy属性
parseScope(element, scanner);
} catch (Exception ex) {
parserContext.getReaderContext().error(ex.getMessage(), parserContext.extractSource(element), ex.getCause());
}
/*
* 2 解析类型过滤器,解析include-filter和exclude-filter子标签
*/
parseTypeFilters(element, scanner, parserContext);
//返回scanner
return scanner;
}
2.2.1 createScanner创建配置扫描器
createScanner方法用于创建一个ClassPathBeanDefinitionScanner对象,设置一些属性,目前最重要的是registerDefaultFilters方法,它用于注册一些默认的TypeFilter。
后面我们还会知道setResourceLoader方法很重要,用于加载Spring5提供的新特性——组件索引文件,能够提升项目启动速度。
/**
* ComponentScanBeanDefinitionParser的方法
*
* 创建ClassPathBeanDefinitionScanner
*
* @param readerContext reader上下文
* @param useDefaultFilters 是否使用DefaultFilters,默认传递true
* @return 一个ClassPathBeanDefinitionScanner对象
*/
protected ClassPathBeanDefinitionScanner createScanner(XmlReaderContext readerContext, boolean useDefaultFilters) {
//调用构造器
return new ClassPathBeanDefinitionScanner(readerContext.getRegistry(), useDefaultFilters,
readerContext.getEnvironment(), readerContext.getResourceLoader());
}
/**
* ClassPathBeanDefinitionScanner的构造器
*
* @param registry bean定义注册表
* @param useDefaultFilters 是否使用DefaultFilters,默认传递true
* @param environment 环境变量对象
* @param resourceLoader 资源加载器
*/
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry, boolean useDefaultFilters,
Environment environment, @Nullable ResourceLoader resourceLoader) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
//设置registry属性
this.registry = registry;
//如果需要使用默认的filter
if (useDefaultFilters) {
//那么注册一些默认的filter,这是父类ClassPathScanningCandidateComponentProvider的方法
registerDefaultFilters();
}
//设置相关属性,这是父类ClassPathScanningCandidateComponentProvider的方法
setEnvironment(environment);
//设置ResourceLoader,加载组件索引文件
setResourceLoader(resourceLoader);
}
2.2.1.1 registerDefaultFilters注册默认的类型过滤器
注册默认过滤器:尝试添加@Component、@ManagedBean、@Named这三个注解类型过滤器到includeFilters缓存集合中!这表示将会注册所有具有@Component元注解的注解标志的类,比如@Component、@Repository、@Service、@Controller、@Configuration,还支持扫描注册还支持 Java EE 6 的注解,比如@ManagedBean,以及JSR-330的注解,比如@Named。
@ManagedBean位于javax.annotation-api依赖中,而@Named位于javax.inject依赖中。一般的项目没有这两个依赖(基本上也不需要),因此通常只有一个@Component注解类型过滤器,但是spring-boot-starter自动集成了javax.annotation-api依赖,因此boot项目默认会添加@Component和@ManagedBean这两个注解类型过滤器。
/**
* ClassPathScanningCandidateComponentProvider的属性
*
* 包含的类型过滤器列表
*/
private final List<TypeFilter> includeFilters = new LinkedList<>();
/**
* ClassPathScanningCandidateComponentProvider的方法
*
* 尝试添加@Component、@ManagedBean、@Named这三个注解类型过滤器到includeFilters缓存集合中!
*
* 隐式的注册所有具有@Component元注解的注解标志的类,比如@Component、@Repository、@Service、@Controller、@Configuration
* 还支持扫描注册还支持 Java EE 6 的注解,比如@ManagedBean,以及JSR-330的注解,比如@Named
*/
@SuppressWarnings("unchecked")
protected void registerDefaultFilters() {
//添加@Component注解类型过滤器,过滤器将不会匹配接口
this.includeFilters.add(new AnnotationTypeFilter(Component.class));
ClassLoader cl = ClassPathScanningCandidateComponentProvider.class.getClassLoader();
try {
//添加@ManagedBean注解类型过滤器,过滤器将不会匹配接口
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("javax.annotation.ManagedBean", cl)), false));
logger.trace("JSR-250 'javax.annotation.ManagedBean' found and supported for component scanning");
} catch (ClassNotFoundException ex) {
// JSR-250 1.1 API (as included in Java EE 6) not available - simply skip.
}
try {
//添加@Named注解类型过滤器,过滤器将不会匹配接口
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("javax.inject.Named", cl)), false));
logger.trace("JSR-330 'javax.inject.Named' annotation found and supported for component scanning");
} catch (ClassNotFoundException ex) {
// JSR-330 API not available - simply skip.
}
}
目前常见版本的javax.inject和javax.annotation-api依赖:
<dependency>
<groupId>javax.injectgroupId>
<artifactId>javax.injectartifactId>
<version>1version>
dependency>
<dependency>
<groupId>javax.annotationgroupId>
<artifactId>javax.annotation-apiartifactId>
<version>1.3.2version>
dependency>
2.4.2.2. parseTypeFilters解析类型过滤器标签
< context:component-scan/>标签下面还支持添加< include-filter/>和< exclude-filter/>类型过滤器子标签。
在createScanner方法中,如果设置的use-default-filters属性为true(默认就是true,一般都是true),那么会模式尝试添加@Component、@ManagedBean、@Named这三个注解的类型过滤器到includeFilters缓存集合中。
这里的< include-filter/>标签和< exclude-filter/>标签则是我们用于自定义的添加或者排除某些类型过滤器,用于自定义解析策略。它们指定的过滤器将分别按定义顺序加入ComponentScanBeanDefinitionParser中的includeFilters缓存集合尾部和excludeFilters缓存集合头部。
//---------ComponentScanBeanDefinitionParser的相关属性
/**
*
* 解析
protected void parseTypeFilters(Element element, ClassPathBeanDefinitionScanner scanner, ParserContext parserContext) {
ClassLoader classLoader = scanner.getResourceLoader().getClassLoader();
//获取element的所有子节点
NodeList nodeList = element.getChildNodes();
//遍历
for (int i = 0; i < nodeList.getLength(); i++) {
Node node = nodeList.item(i);
//如果该节点属性Element标签节点
if (node.getNodeType() == Node.ELEMENT_NODE) {
//获取本地标签名称
String localName = parserContext.getDelegate().getLocalName(node);
try {
/*
* 如果是同样,这两个标签我们一般也都用不到!但是如果我们想要自定义解析规则,比如你不想解析被@Component注解标注的类,那么你可以这么设置一个< exclude-filter/>标签:
<context:component-scan base-package="com.spring.source.componentScan">
<context:exclude-filter type="annotation" expression="org.springframework.stereotype.Component"/>
context:component-scan>
同样,如果我们有个自定义注解,需要被解析,那么就使用< include-filter/>标签就行了。
2.2.2.1 createTypeFilter创建TypeFilter
createTypeFilter用于解析< include-filter/>和< exclude-filter/>标签元素节点,并创建指定类型的TypeFilter。
//---------ComponentScanBeanDefinitionParser的相关属性
/**
*
3. 创建一个TypeFilter
4. 5. @param element
@SuppressWarnings("unchecked")
protected TypeFilter createTypeFilter(Element element, @Nullable ClassLoader classLoader,
ParserContext parserContext) throws ClassNotFoundException {
//获取type属性值
String filterType = element.getAttribute(FILTER_TYPE_ATTRIBUTE);
//获取expression属性值
String expression = element.getAttribute(FILTER_EXPRESSION_ATTRIBUTE);
//使用环境变量对象的resolvePlaceholders方法来解析expression字符串
//这说明expression也可以使用占位符${..:..},这一步就是解析替换占位符,并且只会使用environment中的属性。
expression = parserContext.getReaderContext().getEnvironment().resolvePlaceholders(expression);
/*
* 根据filterType的值创建指定类型的类型过滤器
*/
//如果filterType等于annotation,表明是注解的类型过滤器
if ("annotation".equals(filterType)) {
//创建一个AnnotationTypeFilter,expression应该是注解的全路径名,通过该注解匹配类或者接口(及其子类、子接口)
//之前讲的默认类型过滤器:@Component、@ManagedBean、@Named过滤器都是属于AnnotationTypeFilter
return new AnnotationTypeFilter((Class<Annotation>) ClassUtils.forName(expression, classLoader));
}
//否则,如果filterType等于assignable,表明是类或者接口的类型过滤器
else if ("assignable".equals(filterType)) {
//创建一个AssignableTypeFilter,expression应该是类或者接口的全路径名,通过该表达式匹配类或者接口(及其子类、子接口)
return new AssignableTypeFilter(ClassUtils.forName(expression, classLoader));
}
//否则,如果filterType等于aspectj,表明是类或者接口的类型过滤器
else if ("aspectj".equals(filterType)) {
//创建一个AspectJTypeFilter,expression应该是一个AspectJ表达式,通过该表达式匹配类或者接口(及其子类、子接口)
return new AspectJTypeFilter(expression, classLoader);
}
//否则,如果filterType等于regex,表明是类或者接口的类型过滤器
else if ("regex".equals(filterType)) {
//创建一个RegexPatternTypeFilter,expression应该是一个正则表达式,通过该表达式匹配类或者接口(及其子类、子接口)
return new RegexPatternTypeFilter(Pattern.compile(expression));
}
//否则,如果filterType等于custom,表明是自定义的类型过滤器
else if ("custom".equals(filterType)) {
//自定义的类型过滤器应该实现TypeFilter接口,expression应该是自定义的类型过滤器的全路径名
Class<?> filterClass = ClassUtils.forName(expression, classLoader);
if (!TypeFilter.class.isAssignableFrom(filterClass)) {
throw new IllegalArgumentException(
"Class is not assignable to [" + TypeFilter.class.getName() + "]: " + expression);
}
//创建一个自定义类型实例
return (TypeFilter) BeanUtils.instantiateClass(filterClass);
}
//否则,抛出异常
else {
throw new IllegalArgumentException("Unsupported filter type: " + filterType);
}
}
2.3 doScan扫描以及注册BeanDefinition
doScan是核心方法,将会使用创建的scanner在指定的 basePackages包路径数组中执行扫描,创建bean定义并注册到注册表缓存中,最后返回已注册的 BeanDefinitionHolder集合。
doScan方法的详细步骤为:
- 初始化一个beanDefinitions集合,用于存储找到的已注册的beanDefinition。
- 开启一个循环,遍历basePackages包路径数组,一个个的扫描:
- 调用父类ClassPathScanningCandidateComponentProvider的findCandidateComponents方法,扫描包路径,找出全部符合要求的ScannedGenericBeanDefinition类型的bean定义集合。
- 开启一个循环,遍历找到的bean定义集合:
- 调用resolveScopeMetadata方法则解析@Scope注解,为候选bean设置代理的方式ScopedProxyMode,XML属性也能配置:scope-resolver、scoped-proxy。
- 使用Spring的beanName生成器AnnotationBeanNameGenerator来查找设置的beanName或者生成beanName。
- 如果bean定义是AbstractBeanDefinition类型,那么设置一些默认属性。
- 如果bean定义是AnnotatedBeanDefinition类型,那么处理类上的其他通用注解:@Lazy, @Primary, @DependsOn, @Role, @Description。
- 调用checkCandidate,检查给定的 beanName,确定相应的bean 定义是否需要注册或与现有bean定义兼容:
- 如果具有同名bean且不兼容,则抛出异常“……non-compatible bean definition of same name and class……”。
- 如果可以注册,则将当前beanName以及BeanDefinition封装成为BeanDefinitionHolder对象。将BeanDefinitionHolder对象加入到需要返回的beanDefinitions集合中。
- 继续调用registerBeanDefinition方法注册definitionHolder,之前已经讲过该方法,即尝试注册到beanDefinitionMap、beanDefinitionNames、aliasMap这三个缓存中。
- 返回beanDefinitions集合。
/**
* ClassPathBeanDefinitionScanner的方法
*
* 在指定的 basePackages包路径数组中执行扫描,创建bean定义并注册到注册表缓存中,最后返回已注册的BeanDefinitionHolder集合
* 不会注册任何一个AnnotationConfigProcessor,而是把这留给调用方去注册,即后面的registerComponents方法
*
* @param basePackages 要扫描的包路径数组
* @return 扫描到的BeanDefinitionHolder集合
*/
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
//断言basePackages不能为空
Assert.notEmpty(basePackages, "At least one base package must be specified");
//创建BeanDefinitionHolder集合
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
/*
* 遍历basePackages包路径数组,一个个的扫描
*/
for (String basePackage : basePackages) {
/*
* 1 扫描包路径,找出全部符合过滤器要求的BeanDefinition
* 调用的父类ClassPathScanningCandidateComponentProvider的方法
* 返回的BeanDefinition的实际类型为ScannedGenericBeanDefinition
*/
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
/*遍历全部bean定义*/
for (BeanDefinition candidate : candidates) {
/*如果存在,则解析@Scope注解,为候选bean设置代理的方式ScopedProxyMode,XML属性也能配置:scope-resolver、scoped-proxy*/
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
/*
* 2 使用beanName生成器beanNameGenerator来生成beanName
* 这里的beanNameGenerator是AnnotationBeanNameGenerator类型的实例,而前面讲的DefaultBeanNameGenerator类型的生成器
* 则是基于XML的配置的bean使用的,它们的beanName生成规则不一样
* AnnotationBeanNameGenerator相比于DefaultBeanNameGenerator出现的更晚,现在基本上都是注解配置,因此AnnotationBeanNameGenerator用得更多
*/
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
//如果bean定义是AbstractBeanDefinition类型,ScannedGenericBeanDefinition属于AbstractBeanDefinition类型
if (candidate instanceof AbstractBeanDefinition) {
/*
* 3 将进一步设置应用于给定的BeanDefinition,使用AbstractBeanDefinition的一些默认属性值
* 设置autowireCandidate属性,即XML的autowire-candidate属性,IoC学习的时候就见过该属性,默认为true,表示该bean支持成为自动注入候选bean
*/
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
//如果bean定义是AnnotatedBeanDefinition类型,ScannedGenericBeanDefinition同样属于AnnotatedBeanDefinition类型
if (candidate instanceof AnnotatedBeanDefinition) {
/*
* 4 处理类上的其他通用注解:@Lazy, @Primary, @DependsOn, @Role, @Description
*/
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
/*
* 5 检查给定的 beanName,确定相应的bean 定义是否需要注册或与现有bean定义兼容
*
* 如果已注册同名的bean定义,并且它们的bean定义不兼容,那么直接抛出异常
* 通常,如果我们为两个注解标注的类指定同一个beanName的时候就能复现这个异常
*/
if (checkCandidate(beanName, candidate)) {
//如果可以注册,则将当前beanName以及BeanDefinition封装成为BeanDefinitionHolder对象
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
//根据proxyMode属性的值,判断是否需要创建scope代理,一般都是不需要的
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
//添加到beanDefinitions集合中
beanDefinitions.add(definitionHolder);
/*
* 6 注册definitionHolder
* 之前已经讲过该方法,即尝试注册到beanDefinitionMap、beanDefinitionNames、aliasMap这三个缓存中
*/
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
2.3.1 findCandidateComponents查找BeanDefinition
调用父类ClassPathScanningCandidateComponentProvider的方法,从类名就能看出,该类专门用于扫描包路径以及执行过滤操作。
Spring5开始,该方法有两个路径,一个是传统的扫描包路径,找出全部符合要求的BeanDefinition,即scanCandidateComponents方法;另一个就是Spring5的新特性,直接从"META-INF/spring.components"组件索引文件中加载符合条件的bean,避免了包扫描,用于提升启动速度,即addCandidateComponentsFromIndex方法,该方法我们最后再讲。
/**
1. ClassPathScanningCandidateComponentProvider的方法
2.
3. 扫描组建索引或者候选组件的路径basePackage,返回扫描到的BeanDefinition集合
4. 5. @param basePackage 要扫描的包路径
6. @return 一组对应的BeanDefinition集合
*/
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
/*
* componentsIndex:
* 该属性存储了通过"META-INF/spring.components"组件索引文件获取到的需要注册的bean定义
* 如果没有"META-INF/spring.components"文件,则componentsIndex为null,一般都是为null
* 这是Spring5的新特性,用来直接定义需要注册的bean,用于提升应用启动速度
*
* indexSupportsIncludeFilters:通过过滤器判断是否可以使用组件索引,因为Spring5的组件索引存在限制
*/
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
/*
* 如果存在组件索引文件并且可以使用组件索引,那么直接处理componentsIndex中的符合条件的bean定义,不会扫描包
* */
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
} else {
/*
* 一般都是走这个逻辑,新特性还没啥人用,直接扫描basePackage下的bean定义并返回
*/
return scanCandidateComponents(basePackage);
}
}
2.3.1.1 scanCandidateComponents扫描包下的BeanDefinition
scanCandidateComponents方法就是传统的方法,扫描basePackage包路径下的bean定义并返回满足条件的BeanDefinition集合,这里的BeanDefinition是ScannedGenericBeanDefinition类型。
首先将会加载本项目以及依赖的jar包中的指定包路径下的类成为一个Resource资源,加载的时候,Spring会将每一个定义的类(不是源文件)加载成为一个Resource资源(包括内部类都是一个Resource资源)。
而对于是否满足条件的检查主要是两个isCandidateComponent方法:
- 第一个isCandidateComponent是校验是否满足TypeFilter类型过滤器的要求;
- 第二个isCandidateComponent是校验是否满足bean定义的要求。
/**
* ClassPathScanningCandidateComponentProvider的方法
*
* 扫描basePackage下的bean定义并返回满足条件的BeanDefinition集合
*
* @param basePackage 包路径
* @return 符合条件的BeanDefinition集合
*/
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
//配置完整的包路径 -> "classpath*:AA/BB/CC/**/*.class"
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
/*
* 加载所有路径下的资源,我们看到前缀是"classpath*",因此项目依赖的jar包中的相同路径下资源都会被加载进来
* Spring会将每一个定义的类(不是源文件)加载成为一个Resource资源(包括内部类都是一个Resource资源)
*/
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
/*
* 遍历所有资源,一个资源代表一个类,依次次描
*/
for (Resource resource : resources) {
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
if (resource.isReadable()) {
try {
/*
* 通过MetadataReaderFactory.getMetadataReader方法解析class的Resource资源获取MetadataReader
*
* 这里的MetadataReaderFactory是CachingMetadataReaderFactory类型,能够缓存Resource -> MetadataReader的映射
* MetadataReader是一个通过ASM字节码框架读取class资源组装访问元数据的接口,简单的说用于获取类的元数据
* Spring抽象出了包括ClassMetadata、MethodMetadata、AnnotationMetadata等类元数据接口
* ClassMetadata用于访问类的信息,MethodMetadata用于访问类方法的信息,AnnotationMetadata用于访问类注解的信息
*/
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
/*
* 1 检查读取到的类是否可以作为候选组件,即是否符合TypeFilter类型过滤器的要求
*/
if (isCandidateComponent(metadataReader)) {
/*如果符合,那么基于metadataReader先创建ScannedGenericBeanDefinition*/
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
/*
* 2 继续检查给定bean定义是否可以作为候选组件,即是否符合bean定义
*/
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
//如果符合,那么添加该BeanDefinition
candidates.add(sbd);
} else {
if (debugEnabled) {
logger.debug("Ignored because not a concrete top-level class: " + resource);
}
}
} else {
if (traceEnabled) {
logger.trace("Ignored because not matching any filter: " + resource);
}
}
} catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to read candidate component class: " + resource, ex);
}
} else {
if (traceEnabled) {
logger.trace("Ignored because not readable: " + resource);
}
}
}
} catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
//返回candidates
return candidates;
}
2.3.1.1.1 isCandidateComponent检查类型过滤器TypeFilter
第一个isCandidateComponent方法确定给定类是否有资格作为候选组件。如果与任何exclude filter都不匹配,并且匹配至少一个include filter,则有资格作为候选组件,否则没资格。
前面讲过,默认的excludeFilters为空,默认的includeFilters,就是包含@Component、@ManagedBean、@Named这三个注解的类型过滤器,即具有这三个元注解标注的类可以作为候选组件。
/**
* ClassPathScanningCandidateComponentProvider的方法
*
* 确定给定类是否有资格作为候选组件
* 如果与任何exclude filter都不匹配,并且匹配至少一个include filter,则有资格作为候选组件,否则没资格
*
* 默认的excludeFilters为空
* 默认的includeFilters,就是包含Component、ManagedBean、Named这三个注解的类型过滤器,即具有这三个元注解标注的类可以作为候选组件
*
* @param metadataReader 类的 Asm ClassReader
* @return 该类是否有资格作为候选组件
*/
protected boolean isCandidateComponent(MetadataReader metadataReader) throws IOException {
//遍历excludeFilters过滤器集合
for (TypeFilter tf : this.excludeFilters) {
//如果匹配任何一个TypeFilter,则返回false,表示没资格
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return false;
}
}
//遍历includeFilters过滤器集合
for (TypeFilter tf : this.includeFilters) {
//如果匹配任何一个TypeFilter,则返回true,表示有资格
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return isConditionMatch(metadataReader);
}
}
//最终返回false
return false;
}
从上面的源码能看出来,实际上在遍历includeFilters时,如果匹配任何一个TypeFilter,则还会调用isConditionMatch方法继续判断,这里是对于Spring 4.0新增的的@Conditional条件注解的支持。
@Conditional条件注解,可以标注在类或者方法上,在容器启动时用于控制一批或者一个bean实例是否被注入。通过判断该注解中指定的Condition条件是否满足,如果不满足则不会将对应的bean注入到容器中,如果满足则会将对应的bean进行注入或进一步处理。
在这里,如果通过@Conditional判断不满足,则同样不会将该类的bean定义扫描出来并注册。@Conditional注解我们将在后面的ConfigurationClassPostProcessor文章的部分详细讲解。
/**
* ClassPathScanningCandidateComponentProvider的方法
*
* 根据类上面的@Conditional注解的确定该类是否有资格作为候选组件
*
* @param metadataReader 类的 Asm 阅读器
* @return 该类是否有资格作为候选组件
*/
private boolean isConditionMatch(MetadataReader metadataReader) {
if (this.conditionEvaluator == null) {
this.conditionEvaluator =
new ConditionEvaluator(getRegistry(), this.environment, this.resourcePatternResolver);
}
//调用conditionEvaluator的shouldSkip方法判断
return !this.conditionEvaluator.shouldSkip(metadataReader.getAnnotationMetadata());
}
/**
* ConditionEvaluator的方法
*
* 确定是否应基于@Conditional注解跳过此项,根据元数据类型属于类或者方法推断phase
*
* @param metadata 类或方法的元数据
* @return 如果此项应跳过,则返回true,否则返回false
*/
public boolean shouldSkip(AnnotatedTypeMetadata metadata) {
//调用另一个shouldSkip方法,phase传递null
//请记住这个方法,我们在后面的ConfigurationClassPostProcessor解析的部分有详细讲解
return shouldSkip(metadata, null);
}
2.3.1.1.2 isCandidateComponent检查bean定义
第一个isCandidateComponent方法满足之后,第二个isCandidateComponent方法继续校验bean定义是否有资格作为候选组件。
如果该类是独立的,即它是顶级类或者是静态内部类,可以独立于封闭类构造(这一步就把非静态内部类排除了),并且(如果该类是表示具体类,即既不是接口也不是抽象类,或者(该类是抽象的,并且该类具有持有@Lookup注解的方法))。这两个条件都满足,那么就算有资格作为候选组件。
/**
* ClassPathScanningCandidateComponentProvider的方法
*
* 确定给定的 bean 定义是否有资格作为候选组件
*
* @param beanDefinition 要检查的bean定义
* @return bean 定义是否有资格作为候选组件
*/
protected boolean isCandidateComponent(AnnotatedBeanDefinition beanDefinition) {
AnnotationMetadata metadata = beanDefinition.getMetadata();
/*
* metadata.isIndependent()
* 如果该类是独立的,即它是顶级类或者是静态内部类,可以独立于封闭类构造,这一步就把非静态内部类排除了
* 并且 &&
* (metadata.isConcrete() ||(metadata.isAbstract() && metadata.hasAnnotatedMethods(Lookup.class.getName())))
* 如果该类是表示具体类,即既不是接口也不是抽象类,或者(该类是抽象的,并且该类具有持有@Lookup注解的方法)
*
* 这两个条件都满足,那么就算有资格作为候选组件
*/
return (metadata.isIndependent() && (metadata.isConcrete() ||
(metadata.isAbstract() && metadata.hasAnnotatedMethods(Lookup.class.getName()))));
}
2.3.2. generateBeanName生成beanName
使用Spring的beanName生成器beanNameGenerator来生成beanName,这里的beanNameGenerator是AnnotationBeanNameGenerator类型的实例,而前面讲的DefaultBeanNameGenerator类型的生成器则是基于XML的配置的bean使用的,它们的beanName生成规则不一样。AnnotationBeanNameGenerator相比于DefaultBeanNameGenerator出现的更晚,现在基本上都是注解配置,因此AnnotationBeanNameGenerator用得更多。
AnnotationBeanNameGenerator的generateBeanName方法支持@Component以及它所有的派生注解,以及JavaEE的javax.annotation.@ManagedBean、以及JSR 330的javax.inject.@Named注解。
它首先调用determineBeanNameFromAnnotation方法尝试从注解中直接获取设置的beanName,如果没有设置,则调用buildDefaultBeanName 方法使用Spring自己的规则生成beanName。所使用的beanName生成器是AnnotationBeanNameGenerator。
注意,这里的生成的都是前面findCandidateComponents查找到的BeanDefinition的name,而实际上普通内部类的beanName不在这里生成。
/**
* AnnotationBeanNameGenerator的属性
*
* 默认AnnotationBeanNameGenerator的实例常量,用于组件扫描目的。单例模式的应用
*/
public static final AnnotationBeanNameGenerator INSTANCE = new AnnotationBeanNameGenerator();
/**
1. AnnotationBeanNameGenerator的方法
2.
3. 支持@Component以及它所有的派生注解,以及JavaEE的javax.annotation.@ManagedBean、以及JSR 330的javax.inject.@Named注解
4. 从注解中获取设置的beanName,如果没有设置,则使用Spring自己的规则生成beanName
5. 6. @param definition BeanDefinition
7. @param registry BeanDefinitionRegistry
8. @return beanName
*/
@Override
public String generateBeanName(BeanDefinition definition, BeanDefinitionRegistry registry) {
//如果definition属于AnnotatedBeanDefinition,一般都是这个逻辑
if (definition instanceof AnnotatedBeanDefinition) {
//从类上的注解中查找指定的 beanName,就是看有没有设置注解的value属性值
String beanName = determineBeanNameFromAnnotation((AnnotatedBeanDefinition) definition);
if (StringUtils.hasText(beanName)) {
// Explicit bean name found.
return beanName;
}
}
//否则自动生成唯一的默认 bean 名称。
return buildDefaultBeanName(definition, registry);
}
2.3.2.1 determineBeanNameFromAnnotation查找beanName
从类上的符合条件的注解中查找指定的 beanName。支持@Component以及它所有的派生注解,以及JavaEE的javax.annotation.@ManagedBean、以及JSR 330的javax.inject.@Named注解。
- 要查找的beanName就是对应着注解的value属性的值,如果没有设置value属性的值则返回null,表示没有设置beanName。
- 如果存在多个注解都指定了beanName,并且指定的beanName不相同,那么直接抛出IllegalStateException。
/**
* AnnotationBeanNameGenerator的属性
*
* 注解全路径名 到 注解上的元注解全路径名(除了四个元注解)集合 的map缓存
*/
private final Map<String, Set<String>> metaAnnotationTypesCache = new ConcurrentHashMap<>();
/**
1. AnnotationBeanNameGenerator的方法
2.
3. 从类上的符合条件的注解中查找指定的 beanName
4. 支持@Component以及它所有的派生注解,以及JavaEE的javax.annotation.@ManagedBean、以及JSR 330的javax.inject.@Named注解
5. 6. @param annotatedDef 注解感知的 bean 定义
7. @return bean name,如果未找到则返回null
8. @throws IllegalStateException 如果存在多个注解都指定了不同的beanName,那么直接抛出IllegalStateException
*/
@Nullable
protected String determineBeanNameFromAnnotation(AnnotatedBeanDefinition annotatedDef) {
//获取此 bean 定义的 bean 类的注解元数据
AnnotationMetadata amd = annotatedDef.getMetadata();
//获取该类上的全部注解的全路径名称集合
Set<String> types = amd.getAnnotationTypes();
//保存获取到的beanName,以及用于多个beanName的唯一性校验
String beanName = null;
/*遍历所有注解,获取beanName,并进行beanName唯一性校验*/
for (String type : types) {
//返回一个包含该注解的全部属性的映射实例,属性名 -> 属性值
AnnotationAttributes attributes = AnnotationConfigUtils.attributesFor(amd, type);
if (attributes != null) {
//设置 注解全路径名称 -> 注解上的元注解全路径名集合 的map缓存
Set<String> metaTypes = this.metaAnnotationTypesCache.computeIfAbsent(type, key -> {
/*
* 获取该注解上的除了四个元注解之外的元注解集合
* 比如@Service获取到的就是[org.springframework.stereotype.Component,org.springframework.stereotype.Indexed]
* 比如@Component获取到的就是[org.springframework.stereotype.Indexed]
* 比如@Description获取到的就是[]
*/
Set<String> result = amd.getMetaAnnotationTypes(key);
//如果是空的,那么存入空集合
return (result.isEmpty() ? Collections.emptySet() : result);
});
/*
* 当前注解是否有资格作为获取组件名称的候选注解
*/
if (isStereotypeWithNameValue(type, metaTypes, attributes)) {
//如果有资格,那么获取value属性的值
Object value = attributes.get("value");
//如果是String类型
if (value instanceof String) {
String strVal = (String) value;
//如果不为空
if (StringUtils.hasLength(strVal)) {
//如果beanName不为null,并且此前的beanName和刚获取的beanName不相等,那么抛出异常
//即,如果设置了多个beanName,那么必须相等
if (beanName != null && !strVal.equals(beanName)) {
throw new IllegalStateException("Stereotype annotations suggest inconsistent " +
"component names: '" + beanName + "' versus '" + strVal + "'");
}
//beanName保存strVal
beanName = strVal;
}
}
}
}
}
//返回beanName
return beanName;
}
7.3.9.4.3.2.1.1. isStereotypeWithNameValue筛选注解
isStereotypeWithNameValue方法用于筛选类上的注解,判断当前注解是否有资格作为获取组件名称的候选注解。
筛选规则如下:
- 首先是一系列判断,使用isStereotype变量接收结果:
- 注解类型是否是"org.springframework.stereotype.Component",即是否是@Component注解
- 或者注解上的元注解类型集合中是否包含"org.springframework.stereotype.Component",即当前注解是否将@Component注解当成元注解
- 或者注解类型是否是"javax.annotation.ManagedBean",即是否是JavaEE的@ManagedBean注解
- 或者注解类型是否是"javax.inject.Named",即是否是JSR 330的@Named注解。
- 第一个判断的四个条件满足一个,isStereotype即为true,否则为false。
- 如果isStereotype为true,并且给定注解的属性映射attributes不为null,并且给定注解的属性映射中具有value属性。那么给定注解就有资格作为获取组件名称的候选注解。
/**
* AnnotationBeanNameGenerator的属性
*
* 支持查找的基本的注解(包括其派生注解)
*/
private static final String COMPONENT_ANNOTATION_CLASSNAME = "org.springframework.stereotype.Component";
/**
1. AnnotationBeanNameGenerator的方法
2.
3. 检查给定注解是否有资格作为获取组件名称的候选注解
4. 5. @param annotationType 要检查的注解全路径名
6. @param metaAnnotationTypes 给定注解上的元注解的全路径名集合
7. @param attributes 给定注解的属性映射
8. @return 该注解是否有资格作为具有组件名称的候选注解
*/
protected boolean isStereotypeWithNameValue(String annotationType,
Set<String> metaAnnotationTypes, @Nullable Map<String, Object> attributes) {
/*
* 判断isStereotype:
* 1 annotationType注解类型是否是"org.springframework.stereotype.Component",即是否是@Component注解
* 2 或者metaAnnotationTypes注解上的元注解类型集合中是否包含"org.springframework.stereotype.Component",即当前注解是否将@Component注解当成元注解
* 3 或者annotationType注解类型是否是"javax.annotation.ManagedBean",即是否是JavaEE的@ManagedBean注解
* 4 或者annotationType注解类型是否是"javax.inject.Named",即是否是JSR 330的@Named注解
*
* 以上条件满足一个,isStereotype即为true
*/
boolean isStereotype = annotationType.equals(COMPONENT_ANNOTATION_CLASSNAME) ||
metaAnnotationTypes.contains(COMPONENT_ANNOTATION_CLASSNAME) ||
annotationType.equals("javax.annotation.ManagedBean") ||
annotationType.equals("javax.inject.Named");
/*
* 继续判断:
* 1 如果isStereotype为true
* 2 并且给定注解的属性映射集合attributes不为null
* 3 并且给定注解的属性映射集合attributes中具有value属性
*
* 以上条件都满足,那么给定注解就有资格作为获取组件名称的候选注解
*/
return (isStereotype && attributes != null && attributes.containsKey("value"));
}
2.3.2.2 buildDefaultBeanName生成默认beanName
如果没有在注解中指定beanName,那么调用buildDefaultBeanName方法按照Spring自己的规则生成默认的beanName。所使用的beanName生成器是AnnotationBeanNameGenerator。
生成规则如下:
- 首先获取简单类名,请注意,静态内部类的简单类名为"OuterClassName.InnerClassName"
- 随后调用Java核心rt.jar包中的Introspector的decapitalize方法根据简单类名生成beanName:
- 默认将返回小写的简单类名,但是如果类名有多个字符并且前两个字符都是大写时,将直接返回简单类名。
/**
* 从给定的 bean 定义派生一个默认的 beanName
*
* @param definition 用于生成 bean 名称的 bean 定义
* @param registry 正在注册给定 bean 定义的注册表,没用
* @return 默认的 bean 名称,从不为null
*/
protected String buildDefaultBeanName(BeanDefinition definition, BeanDefinitionRegistry registry) {
return buildDefaultBeanName(definition);
}
/**
* 从给定的 bean 定义派生一个默认的 bean 名称。
*
* 默认实现是:
* 1 首先获取简单类名,请注意,内部类的名称为"outerClassName.InnerClassName"
* 2 随后调用Java核心rt.jar包中的Introspector.decapitalize方法根据简单类名生成beanName
* 2.1 默认将返回小写的简单类名,但是如果类名有多个字符并且前两个字符都是大写时,将直接返回简单类名
*
* @param definition 用于生成 bean 名称的 bean 定义
* @return 默认的 bean 名称,从不为null
*/
protected String buildDefaultBeanName(BeanDefinition definition) {
//获取beanClassName
String beanClassName = definition.getBeanClassName();
Assert.state(beanClassName != null, "No bean class name set");
//获取简单类名
String shortClassName = ClassUtils.getShortName(beanClassName);
//调用Java核心rt.jar包中的Introspector的decapitalize方法生成beanName
return Introspector.decapitalize(shortClassName);
}
/**
* Java核心rt.jar包中的Introspector.decapitalize方法
*
* 将第一个字符从大写转换为小写,但在特殊情况下,当有多个字符并且并且前两个字符都是大写时,将返回原值
* Thus "FooBah" becomes "fooBah" and "X" becomes "x", but "URL" stays as "URL".
*
* @param name 需要转换为小写的字符串
* @return 已经转换为小写的字符串
*/
public static String decapitalize(String name) {
if (name == null || name.length() == 0) {
return name;
}
//当有多个字符并且并且前两个字符都是大写时,将返回原值
if (name.length() > 1 && Character.isUpperCase(name.charAt(1)) &&
Character.isUpperCase(name.charAt(0))) {
return name;
}
//第一个字符转换为小写然后返回
char chars[] = name.toCharArray();
chars[0] = Character.toLowerCase(chars[0]);
return new String(chars);
}
2.3.3 postProcessBeanDefinition设置默认值
将进一步设置应用于给定的BeanDefinition,使用AbstractBeanDefinition的一些默认属性值,比如lazyInit、autowire、initMethodName、destroyMethodName等等。
/**
* ClassPathBeanDefinitionScanner的方法
*
* 将进一步设置应用于给定的BeanDefinition,使用AbstractBeanDefinition的一些默认属性值
*
* @param beanDefinition 扫描的bean定义
* @param beanName 给定 bean 生成的 bean 名称
*/
protected void postProcessBeanDefinition(AbstractBeanDefinition beanDefinition, String beanName) {
//设置一些默认值
beanDefinition.applyDefaults(this.beanDefinitionDefaults);
//autowireCandidatePatterns默认就是空的
if (this.autowireCandidatePatterns != null) {
beanDefinition.setAutowireCandidate(PatternMatchUtils.simpleMatch(this.autowireCandidatePatterns, beanName));
}
}
/**
* AbstractBeanDefinition的方法
*
* 将提供的默认值应用于此 bean。
*
* @param defaults 要应用的默认设置
*/
public void applyDefaults(BeanDefinitionDefaults defaults) {
//lazyInit属性
Boolean lazyInit = defaults.getLazyInit();
if (lazyInit != null) {
setLazyInit(lazyInit);
}
//设置autowire属性模式
setAutowireMode(defaults.getAutowireMode());
//设置dependencyCheck属性,表示属性强制检查,就是XML的dependency-check属性
//然而这个属性早在spring3.0的时候就被废弃了,代替它的就是构造器注入或者@Required
setDependencyCheck(defaults.getDependencyCheck());
//设置initMethodName属性,就是XML的init-method属性
setInitMethodName(defaults.getInitMethodName());
//设置enforceInitMethod属性为false,表示是否强制init方法不能为null,默认true
setEnforceInitMethod(false);
//设置destroyMethodName属性,就是XML的destroy-method属性
setDestroyMethodName(defaults.getDestroyMethodName());
//设置enforceDestroyMethod属性为false,表示是否强制destroy方法不能为null,默认true
setEnforceDestroyMethod(false);
}
2.3.4 processCommonDefinitionAnnotations解析其他注解
如果bean是AnnotatedBeanDefinition类型,ScannedGenericBeanDefinition是属于AnnotatedBeanDefinition类型的。那么调用processCommonDefinitionAnnotations方法。处理类上的其他通用注解:@Lazy, @Primary, @DependsOn, @Role, @Description,并为bean定义设置相关属性。
/**
* AnnotationConfigUtils工具类的方法
*
* 解析其他类上的注解:@Lazy, @Primary, @DependsOn, @Role, @Description
*
* @param abd AnnotatedBeanDefinition
*/
public static void processCommonDefinitionAnnotations(AnnotatedBeanDefinition abd) {
processCommonDefinitionAnnotations(abd, abd.getMetadata());
}
static void processCommonDefinitionAnnotations(AnnotatedBeanDefinition abd, AnnotatedTypeMetadata metadata) {
/*
* 尝试获取@Lazy注解,设置lazyInit属性的值为value的值,即XML的lazy-init属性
*/
AnnotationAttributes lazy = attributesFor(metadata, Lazy.class);
if (lazy != null) {
abd.setLazyInit(lazy.getBoolean("value"));
} else if (abd.getMetadata() != metadata) {
lazy = attributesFor(abd.getMetadata(), Lazy.class);
if (lazy != null) {
abd.setLazyInit(lazy.getBoolean("value"));
}
}
/*
* 尝试获取@Primary注解,设置primary属性的值为true,即XML的primary属性
*/
if (metadata.isAnnotated(Primary.class.getName())) {
abd.setPrimary(true);
}
/*
* 尝试获取@DependsOn注解,设置dependsOn属性的值为value的数组值,即XML的depends-on属性
* 容器会确保在实例化该bean之前实例化所有依赖的bean
*/
AnnotationAttributes dependsOn = attributesFor(metadata, DependsOn.class);
if (dependsOn != null) {
abd.setDependsOn(dependsOn.getStringArray("value"));
}
/*
* 尝试获取@Role注解,设置role属性的值为value的值
*/
AnnotationAttributes role = attributesFor(metadata, Role.class);
if (role != null) {
abd.setRole(role.getNumber("value").intValue());
}
/*
* 尝试获取@Description注解,设置description属性的值为value的值,即XML的description标签
*/
AnnotationAttributes description = attributesFor(metadata, Description.class);
if (description != null) {
abd.setDescription(description.getString("value"));
}
}
2.3.5 checkCandidate检查重复beanName
检查给定的 beanName,确定相应的bean 定义是否需要注册或与现有bean定义兼容。
如果beanDefinitionMap缓存中已注册同名的bean定义,并且当前bean定义和已注册的bean定义不兼容,那么直接抛出异常“……non-compatible bean definition of same name and class……”。
通常,如果我们为两个注解标注的类指定同一个beanName的时候就能复现这个异常。但是同样这里没有校验通过组件注解标注的普通内部类的beanName,也就是说如果普通内部类和其他类(比如外部类、静态内部类)设置了相同的beanName,那么将会造成bean定义的覆盖,而不会抛出遗产,但是使用时由于使用者不知道bean定义被覆盖了可能导致类型异常,因此一定要注意最好手动避免重名的bean定义。
实际上,在基于XML、组件注解标注的普通内部类、@Import等其他方式引入bean的时候,都没有checkCandidate这一步,因此基于普通组件注解注册的bean定义优先级最低,如果发现有其他已注册的bean定义时,将不会替换为自己的配置。比如,如果有两个同名bean定义,一个基于XML的,另一个是基于组件注解的普通类,那么将会使用基于XML的配置!
/**
* ClassPathBeanDefinitionScanner的方法
*
* 检查给定的 beanName,确定相应的bean 定义是否需要注册或与现有bean定义兼容
*
* @param beanName beanName
* @param beanDefinition 相应的beanDefinition
* @return 如果bean可以注册则返回true,如果应该跳过它,则返回false(因为已存在指定名称的bean)
*/
protected boolean checkCandidate(String beanName, BeanDefinition beanDefinition) throws IllegalStateException {
//如果注册表的beanDefinitionMap缓存中还没有该beanName的缓存,那么返回true
if (!this.registry.containsBeanDefinition(beanName)) {
return true;
}
//否则,从beanDefinitionMap缓存中获取已存在的同名beanName的bean定义
BeanDefinition existingDef = this.registry.getBeanDefinition(beanName);
//获取原始的BeanDefinition
BeanDefinition originatingDef = existingDef.getOriginatingBeanDefinition();
//如果原始的BeanDefinition不为null
if (originatingDef != null) {
//那么使用原始的BeanDefinition来比较
existingDef = originatingDef;
}
//检查当前的beanDefinition与原始的existingDef是否兼容,如果兼容则直接返回false,不需要继续注册了
//当现有beanDefinition和原始的beanDefinition来自同一源source或非扫描源non-scanning source时,默认实现将它们视为兼容
if (isCompatible(beanDefinition, existingDef)) {
return false;
}
/*
* 不兼容就直接抛出异常了,这里也就是使用@Component等组件注解标注bean的不能有重名的逻辑了
* 但是同样这里没有校验通过组件注解标注的普通内部类的beanName,也就是说如果普通内部类和其他类(比如外部类、静态内部类)设置了相同的beanName
* 那么将会造成bean定义的覆盖,而不会抛出遗产,但是使用时由于使用者不知道bean定义被覆盖了可能导致类型异常,因此一定要注意最好手动避免重名的bean定义
*/
throw new ConflictingBeanDefinitionException("Annotation-specified bean name '" + beanName +
"' for bean class [" + beanDefinition.getBeanClassName() + "] conflicts with existing, " +
"non-compatible bean definition of same name and class [" + existingDef.getBeanClassName() + "]");
}
2.3.6 Spring5的spring.components扩展点
前面讲doScan的findCandidateComponents方法时,我们介绍了,自Spring5开始,查找BeanDefinition有两条路径:一条是传统的扫描包,前面已经讲了它的源码,另一条就是直接从"META-INF/spring.components"组件索引文件中加载符合条件的bean,即addCandidateComponentsFromIndex方法,现在我们简单介绍一下该方法。
Spring5升级的其中一个重点就提升了注解驱动的启动性能,"META-INF/spring.components"这个文件类似于一个“组件索引”文件,我们将需要加载的组件(beean定义)预先的以键值对的样式配置到该文件中,当项目中存在"META-INF/spring.components"文件并且文件中配置了属性时,Spring不会进行包扫描,而是直接读取"META-INF/spring.components"中组件的定义并直接加载,从而达到提升性能的目的。
2.3.6.1 spring.components组件索引文件的读取
实际上,在configureScanner方法创建配置扫描器ClassPathBeanDefinitionScanner的时候,在ClassPathBeanDefinitionScanner 的构造器中,Spring就会尝试进行"META-INF/spring.components"文件的读取!
组件索引文件的读取同样是委托ClassPathScanningCandidateComponentProvider来完成的。如果存在组件索引文件并且文件中定义了属性,那么将会返回一个包含找到的所有组件的属性的CandidateComponentsIndex实例,否则返回null,并且将返回结果赋值给ClassPathScanningCandidateComponentProvider的componentsIndex属性!
/**
* ClassPathBeanDefinitionScanner的构造器
*
* @param registry bean定义注册表
* @param useDefaultFilters 是否使用DefaultFilters
* @param environment 环境变量对象
* @param resourceLoader 资源加载器
*/
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry, boolean useDefaultFilters,
Environment environment, @Nullable ResourceLoader resourceLoader) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
//设置registry属性
this.registry = registry;
//如果使用默认的filter
if (useDefaultFilters) {
//那么注册默认的filter,父类ClassPathScanningCandidateComponentProvider的方法
registerDefaultFilters();
}
//设置相关属性,父类ClassPathScanningCandidateComponentProvider的方法
setEnvironment(environment);
/*
* 设置 ResourceLoader的时候,会尝试进行"META-INF/spring.components"文件的读取
* 委托调用父类ClassPathScanningCandidateComponentProvider的方法
*/
setResourceLoader(resourceLoader);
}
/**
* ClassPathScanningCandidateComponentProvider的方法
*/
@Override
public void setResourceLoader(@Nullable ResourceLoader resourceLoader) {
this.resourcePatternResolver = ResourcePatternUtils.getResourcePatternResolver(resourceLoader);
this.metadataReaderFactory = new CachingMetadataReaderFactory(resourceLoader);
//加载组件索引文件,将结果赋值给componentsIndex
this.componentsIndex = CandidateComponentsIndexLoader.loadIndex(this.resourcePatternResolver.getClassLoader());
}
/**
* CandidateComponentsIndexLoader的属性
*
* 要查找组件索引文件的位置常量,可以存在于多个 JAR 文件中
*/
public static final String COMPONENTS_RESOURCE_LOCATION = "META-INF/spring.components";
/**
* CandidateComponentsIndexLoader的方法
*
* 从默认的文件路径"META-INF/spring.components"加载索引文件成为一个CandidateComponentsIndex实例并返回
* 如果没有找到任何文件或者文件中没有定义组件,则返回null
*
* @param classLoader 给定的类加载器
* @return 将要使用的CandidateComponentsIndex实例,如果没有找到索引文件则返回null
*/
@Nullable
public static CandidateComponentsIndex loadIndex(@Nullable ClassLoader classLoader) {
ClassLoader classLoaderToUse = classLoader;
if (classLoaderToUse == null) {
classLoaderToUse = CandidateComponentsIndexLoader.class.getClassLoader();
}
return cache.computeIfAbsent(classLoaderToUse, CandidateComponentsIndexLoader::doLoadIndex);
}
@Nullable
private static CandidateComponentsIndex doLoadIndex(ClassLoader classLoader) {
if (shouldIgnoreIndex) {
return null;
}
try {
//加载全部组件索引文件
Enumeration<URL> urls = classLoader.getResources(COMPONENTS_RESOURCE_LOCATION);
//如果没有加载到组件索引文件,直接返回null
if (!urls.hasMoreElements()) {
return null;
}
List<Properties> result = new ArrayList<>();
while (urls.hasMoreElements()) {
URL url = urls.nextElement();
Properties properties = PropertiesLoaderUtils.loadProperties(new UrlResource(url));
result.add(properties);
}
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + result.size() + "] index(es)");
}
int totalCount = result.stream().mapToInt(Properties::size).sum();
//如果没有从组件索引文件中加载到属性,同样返回null,否则返回CandidateComponentsIndex实例
return (totalCount > 0 ? new CandidateComponentsIndex(result) : null);
} catch (IOException ex) {
throw new IllegalStateException("Unable to load indexes from location [" +
COMPONENTS_RESOURCE_LOCATION + "]", ex);
}
}
2.3.6.2 indexSupportsIncludeFilters组件索引支持
假设存在组件索引文件并且加载成功,那么componentsIndex属性就不会为null,随后就会走到indexSupportsIncludeFilters方法。
这个方法用于校验includeFilters中是否还存在除了AnnotationTypeFilter和AssignableTypeFilter类型的Filter之外的其他TypeFilter,如果存在,则依然不会走addCandidateComponentsFromIndex的逻辑,因为组件索引仅仅支持AnnotationTypeFilter和AssignableTypeFilter的过滤选项,其他类型的过滤目前不支持,这也是这种模式的一个缺点!
目前,组件索引支持存在@Indexed元注解的注解,比如@Component注解上就标注了@Indexed注解,以及类路径以javax.开头的注解,比如@ManagedBean或者@Named注解,以及直接标注了@Indexed注解的类或者接口。
/**
* 确定是否可以使用组件索引
*
* @return true, 可以;false,不可以
*/
private boolean indexSupportsIncludeFilters() {
//遍历includeFilters
for (TypeFilter includeFilter : this.includeFilters) {
//校验每一个includeFilter,只要有一个不符合要求就返回false
if (!indexSupportsIncludeFilter(includeFilter)) {
return false;
}
}
//校验都通过就返回true
return true;
}
/**
* 确定指定是否是AnnotationTypeFilter或者AssignableTypeFilter的类型过滤器,以及是否支持组件索引
*
* @param filter 要检查的过滤器
* @return 索引是否支持此包括过滤器
*/
private boolean indexSupportsIncludeFilter(TypeFilter filter) {
//AnnotationTypeFilter类型的TypeFilter
if (filter instanceof AnnotationTypeFilter) {
Class<? extends Annotation> annotation = ((AnnotationTypeFilter) filter).getAnnotationType();
//确定该注解类型是否包含@Indexed元注解 或者 该注解类型的名称是否以javax.开头,即ManagedBean或者Named注解
//如果满足一个,则支持组件索引,返回true,否则返回false
return (AnnotationUtils.isAnnotationDeclaredLocally(Indexed.class, annotation) ||
annotation.getName().startsWith("javax."));
}
//AssignableTypeFilter类型的TypeFilter
if (filter instanceof AssignableTypeFilter) {
Class<?> target = ((AssignableTypeFilter) filter).getTargetType();
//确定该类(接口)的类型上是否具有@Indexed元注解,如果具有,则支持组件索引,返回true,否则返回false
return AnnotationUtils.isAnnotationDeclaredLocally(Indexed.class, target);
}
//其它类型的TypeFilter,直接返回false
return false;
}
@Indexed就是Spring5位了支持组件索引而新增的一个注解,因为实际上spring.components文件可以自动生成。
添加如下依赖:
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-context-indexerartifactId>
<version>5.2.8.RELEASEversion>
<scope>optionalscope>
dependency>
随后运行项目即可自动在target中为满足了上面那些组件索引支持要求的类生成spring.components文件:
注意自动生成的文件将会覆盖我们自己在项目中定义的文件!
2.3.6.3 addCandidateComponentsFromIndex基于componentsIndex加载bean定义
假设存在组件索引文件并且加载成功,那么就会走addCandidateComponentsFromIndex方法,基于componentsIndex加载复合条件的bean定义。
addCandidateComponentsFromIndex中同样会使用到TypeFilter检验,以及会使用到我们设置的basePackage,但是这里并不是去扫描包,而是校验加载进来的bean组件的位置是否位于指定的basePackage中,相当于也是一种校验!其他的校验则和scanCandidateComponents方法的逻辑差不多,都有两个isCandidateComponent的校验!
/**
* ClassPathScanningCandidateComponentProvider的方法
*
* 基于组件索引componentsIndex加载bean定义
*
* @param index componentsIndex
* @param basePackage 要扫描的包路径
* @return 符合条件的BeanDefinition集合
*/
private Set<BeanDefinition> addCandidateComponentsFromIndex(CandidateComponentsIndex index, String basePackage) {
//该集合用于保存注册的BeanDefinition
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
Set<String> types = new HashSet<>();
/*
* 1 遍历includeFilters过滤器,获取满足条件的组件索引文件中的bean类型(全路径类名)
*/
for (TypeFilter filter : this.includeFilters) {
//提取AnnotationTypeFilter和AssignableTypeFilter类型的过滤器指定的注解名和类(接口名)字符串。
//比如是Component注解的Filter,那么返回org.springframework.stereotype.Component
//如果是其它类型的TypeFilter,则返回null
String stereotype = extractStereotype(filter);
//如果stereotype为null,那么抛出异常,因为组件索引文件中只能指定注解或者类的全路径名,这也是一个局限
if (stereotype == null) {
throw new IllegalArgumentException("Failed to extract stereotype from " + filter);
}
//返回满足包含Filters过滤器以及basePackage包路径的所有类型
types.addAll(index.getCandidateTypes(basePackage, stereotype));
}
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
/*
* 2 遍历所有bean类型(全路径类名),进行校验,以及创建BeanDefinition
* 这一部分就类似于scanCandidateComponents方法的逻辑
*/
for (String type : types) {
//获取该类的MetadataReader,可以获取了类的元数据:ClassMetadata、AnnotationMetadata
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(type);
/*
* 和scanCandidateComponents方法一样
* 1 检查读取到的类是否可以作为候选组件,即是否符合TypeFilter类型过滤器的要求
*/
if (isCandidateComponent(metadataReader)) {
//如果符合,那么基于metadataReader先创建ScannedGenericBeanDefinition,
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(metadataReader.getResource());
/*
* 2 继续检查给定bean定义是否可以作为候选组件,即是否符合bean定义
*/
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Using candidate component class from index: " + type);
}
//如果符合,那么添加该BeanDefinition
candidates.add(sbd);
} else {
if (debugEnabled) {
logger.debug("Ignored because not a concrete top-level class: " + type);
}
}
} else {
if (traceEnabled) {
logger.trace("Ignored because matching an exclude filter: " + type);
}
}
}
} catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
//返回candidates
return candidates;
}
2.3.6.3.1 extractStereotype提取过滤类型
提取AnnotationTypeFilter和AssignableTypeFilter类型的过滤器指定的注解名和类(接口名)字符串。如果是其它类型的TypeFilter,则返回null,随后在外部方法中将抛出异常!
/**
* ClassPathScanningCandidateComponentProvider的方法
*
* 提取AnnotationTypeFilter和AssignableTypeFilter类型的过滤器指定的注解名和类(接口名)字符串
* 如果是其它类型的TypeFilter,则返回null
*
* @param filter 要处理的过滤器
* @return 匹配此筛选器的类型
*/
@Nullable
private String extractStereotype(TypeFilter filter) {
//如果是AnnotationTypeFilter类型
if (filter instanceof AnnotationTypeFilter) {
//那么返回注解的名字
return ((AnnotationTypeFilter) filter).getAnnotationType().getName();
}
//如果是AnnotationTypeFilter类型
if (filter instanceof AssignableTypeFilter) {
//那么返回类或者接口的名字
return ((AssignableTypeFilter) filter).getTargetType().getName();
}
//其它类型,返回null
return null;
}
2.3.6.3.2 getCandidateTypes返回满足条件的bean类型
返回满足条件的bean类型(全路径类名)。即要求加载进来的组件索引匹配指定TypeFilter中的注解或者类(接口)的全路径名,并且组件索引中的bean路径位于basePackage指定的路径之中!
/**
1. CandidateComponentsIndex的方法
2.
3. 返回满足条件的bean类型(全路径类名)
4. 5. @param basePackage 要检查的包路径
6. @param stereotype 要使用的类型
7. @return 满足条件的bean类型集合
*/
public Set<String> getCandidateTypes(String basePackage, String stereotype) {
//获取使用指定注解或者类(接口)的全路径名的作为key的value集合
List<Entry> candidates = this.index.get(stereotype);
//如果candidates不为
if (candidates != null) {
//使用lambda的并行流处理,如果当前bean类型属于指定的包路径中,则表示满足条件,并且收集到set集合中
return candidates.parallelStream()
//匹配包路径
.filter(t -> t.match(basePackage))
//获取type,实际上就是文件的key,即bean组件的类的全路径类名
.map(t -> t.type)
.collect(Collectors.toSet());
}
//返回空集合
return Collections.emptySet();
}
2.3.6.4 spring.components文件的格式以及加载格式
spring.components文件的编写格式非常的简单,即key=value类型的键值对:
- key:要注册的类的全限定名;
- value:includeFilters中的任何一个AnnotationTypeFilter和AssignableTypeFilter类型的过滤器的过滤类型的全限定类名,比如Component的TypeFilter的全路径类名:org.springframework.stereotype.Component;当然可以写多个类型,使用,分隔即可。
spring.components文件加载到CandidateComponentsIndex中之后,内部的键值对变成了一个LinkedMultiValueMap类型的映射,存入index属性中。
在解析的时候,value可以传递多个,使用,分隔,解析的时候将会拆分开,并且spring.components文件中的value在index映射中成为了key,而且由于是LinkedMultiValueMap类型的映射,它非常特别,对于相同的key,它的value不会被替换,而是采用一个LinkedList将value都保存起来。
/**
* 加载进来的组件索引文件
*/
public class CandidateComponentsIndex {
/**
* Ant路径匹配器,用来支持basePackage的模式匹配
*/
private static final AntPathMatcher pathMatcher = new AntPathMatcher(".");
/**
* 存放格式化之后的bean组件信息
*/
private final MultiValueMap<String, Entry> index;
/**
* doLoadIndex方法调用的构造器
*
* @param content Properties的list集合,有几个文件就有几个Properties
*/
CandidateComponentsIndex(List<Properties> content) {
//调用parseIndex方法
this.index = parseIndex(content);
}
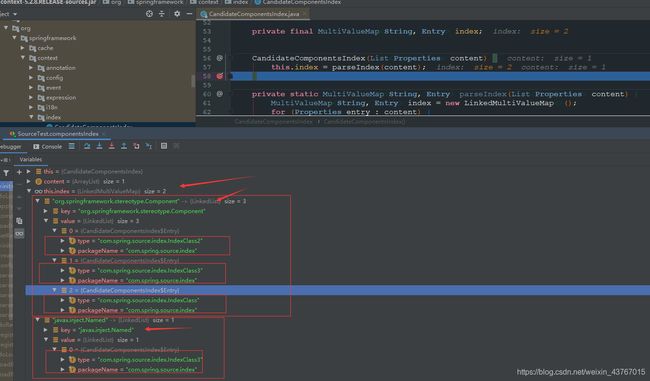
private static MultiValueMap<String, Entry> parseIndex(List<Properties> content) {
MultiValueMap<String, Entry> index = new LinkedMultiValueMap<>();
//遍历Properties
for (Properties entry : content) {
entry.forEach((type, values) -> {
//按照","拆分value为stereotypes数组
String[] stereotypes = ((String) values).split(",");
//遍历stereotypes数组
for (String stereotype : stereotypes) {
//将stereotype作为key,一个新Entry作为value加入到index映射中,这里的Entry是CandidateComponentsIndex的一个内部类
//注意,由于是LinkedMultiValueMap类型的映射,它非常特别,对于相同的key,它的value不会被替换,而是采用一个LinkedList将value都保存起来
//比如,如果有两个键值对,key都为a,value分别为b、c,那么添加两个键值对之后,map中仍然只有一个键值对,key为a,但是value是一个LinkedList,内部有两个值,即b和c
index.add(stereotype, new Entry((String) type));
}
});
}
return index;
}
private static class Entry {
/**
* type就是spring.components文件中的key,即要注册的类的全限定名
*/
private final String type;
private final String packageName;
/**
* 构造器
*
* @param type
*/
Entry(String type) {
//为type赋值
this.type = type;
//获取包路径名,即出去类名之后的路径
this.packageName = ClassUtils.getPackageName(type);
}
/**
* 匹配basePackage
*
* @param basePackage basePackage包路径
* @return true以匹配,false未匹配
*/
public boolean match(String basePackage) {
/*
* 如果basePackage存在模式字符,比如? * ** ,那么使用pathMatcher来匹配
*/
if (pathMatcher.isPattern(basePackage)) {
return pathMatcher.match(basePackage, this.packageName);
}
/*
* 否则,表示basePackage就是一个固定的字符串,那么直接看type是否是以basePackage为起始路径即可
*/
else {
return this.type.startsWith(basePackage);
}
}
}
}
2.3.6.5 spring.components扩展点案例
我们在com.spring.source.index路径下新建四个类IndexClass、IndexClass2、IndexClass3、IndexClass4,它们分别使用@Component、@Service、@Named、@Component注解装饰。注意@Named是属于JSR330 的注解,想要使用它,我们必须引入另一个maven依赖:
<dependency>
<groupId>javax.injectgroupId>
<artifactId>javax.injectartifactId>
<version>1version>
dependency>
测试类如下:
@Component
public class IndexClass {
}
@Service
public class IndexClass2 {
}
@Named
public class IndexClass3 {
}
@Component
public class IndexClass4 {
}
在一个配置文件spring-config-index.xml中配置component-scan:
<context:component-scan base-package="com.spring.source" />
测试:
@Test
public void componentsIndex() {
ClassPathXmlApplicationContext ac = new ClassPathXmlApplicationContext("spring-config-index.xml");
System.out.println(ac.getBean("indexClass"));
System.out.println(ac.getBean("indexClass2"));
System.out.println(ac.getBean("indexClass3"));
System.out.println(ac.getBean("indexClass4"));
}
结果当然是可以获取全部的bean:
com.spring.source.index.IndexClass@dbf57b3
com.spring.source.index.IndexClass2@384ad17b
com.spring.source.index.IndexClass3@61862a7f
com.spring.source.index.IndexClass4@441772e
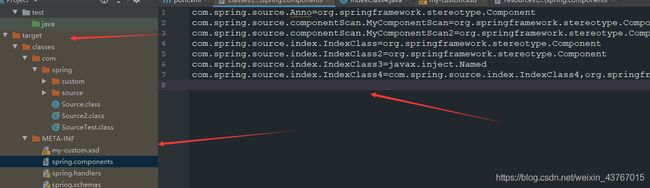
现在我们在resources目录下(我使用的idea)新增一个META-INF/spring.components文件:

加入如下配置:
#key为需要手动添加的bean组件类的全路径名,value为includeFilters中的一个TypeFilter过滤条件,比如Component的TypeFilter的全路径类名
com.spring.source.index.IndexClass=org.springframework.stereotype.Component
com.spring.source.index.IndexClass2=org.springframework.stereotype.Component
com.spring.source.index.IndexClass3=javax.inject.Named,org.springframework.stereotype.Component
可以看到,我们仅仅添加了三个bean组件,当我们再一次运行测试代码时,发现抛出了异常:
com.spring.source.index.IndexClass@3c153a1
com.spring.source.index.IndexClass2@b62fe6d
com.spring.source.index.IndexClass3@13acb0d1
org.springframework.beans.factory.NoSuchBeanDefinitionException: No bean named 'indexClass4' available
很明显,就是没有找到indexClass4,为什么呢?就是因为我们设置了META-INF/spring.components,但是只配置了三个bean定义,Spring在加载的时候就会从我们定义的组件索引文件中去加载bean定义,不会走扫描包的逻辑,导致indexClass4不能被加载和注册,我们自然无法获取对应的实例!
需要注意的是,在此模式下,作为组件扫描目标的所有模块都必须使用此机制,如果只有部分模块存在 spring.components 文件,则其他模块的 bean 也不会走包扫描。为此,可以我们可以在Spring环境变量中设置spring.index.ignore属性为true,这样就不会扫描spring.components 文件,而是走包扫描!
下面我们来deBug看看具体的情况!
首先我们在CandidateComponentsIndex中打上断点,就能看到我们的配置文件被夹在进来之后的样式:
随后在ClassPathScanningCandidateComponentProvider中打上断点,就能明显看到它走的是addCandidateComponentsFromIndex的逻辑,根本没有扫描包:
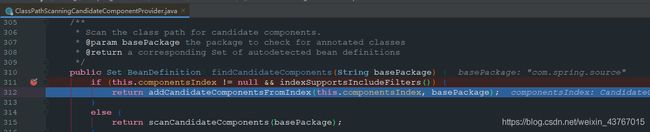
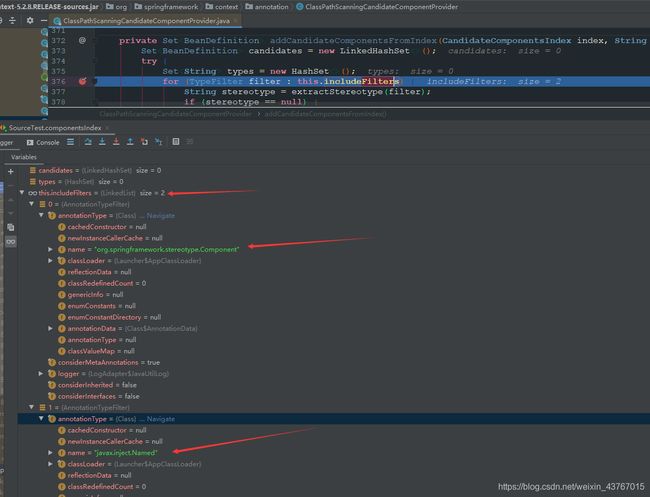
最后进入addCandidateComponentsFromIndex方法,我们能看到,includeFilters包含两个Filter,因为我们引入了javax.inject,因此除了Component注解的Filter之外,还有一个JSR330的Named注解的Filter,它们是在registerDefaultFilters方法中注册的,前面已经讲过了!
2.4 registerComponents注册组件
注册一些组件,主要就是一些注解配置处理器,用于通过解析bean定义内部的注解对Spring容器里已注册的bean进行装配、依赖注入,甚至添加新的bean(比如@Bean注解),因此这个方法是一个核心方法!
实际上这是< context:annotation-config/> 标签的功能,而< context:component-scan/>标签中的annotation-config属性也有这个功能,因此< context:component-scan/>标签具有< context:annotation-config/>标签的全部功能,所以建议直接配置< context:component-scan/>标签就行了。
/**
* ComponentScanBeanDefinitionParser的属性
*
* annotation-config属性名称常量
*/
private static final String ANNOTATION_CONFIG_ATTRIBUTE = "annotation-config";
/**
1. ComponentScanBeanDefinitionParser的方法
2.
3. 注册一些组件,主要就是注册一些注解后处理器
4. 用于通过注解对spring容器里已注册的bean进行装配、依赖注入,甚至添加新的bean(比如@Bean注解)
5. 6. @param readerContext reader上下文
7. @param beanDefinitions 已注册的beanDefinition集合
8. @param element 标签元素节点
*/
protected void registerComponents(
XmlReaderContext readerContext, Set<BeanDefinitionHolder> beanDefinitions, Element element) {
//使用标签的名称和source构建一个CompositeComponentDefinition
Object source = readerContext.extractSource(element);
CompositeComponentDefinition compositeDef = new CompositeComponentDefinition(element.getTagName(), source);
//将每一个注册的beanDefHolder封装成为BeanComponentDefinition,并添加到compositeDef的nestedComponents集合属性中
for (BeanDefinitionHolder beanDefHolder : beanDefinitions) {
compositeDef.addNestedComponent(new BeanComponentDefinition(beanDefHolder));
}
/*
* 如有必要,注册注解处理器
* annotationConfig表示是否开启class内部的注解配置支持的标志位,用于通过注解对Spring容器里已注册的bean进行装配、依赖注入,默认true
*
* 这就是2.4.1 registerAnnotationConfigProcessors注册注解配置处理器
在给定注册表中注册所有注解配置处理器的bean定义,用于后续步骤中对相关注解的处理,这个方法非常的重要。后面讲到的invokeBeanFactoryPostProcessors方法会回调所有的BeanFactoryPostProcessor,而创建bean实例的时候会回调所有的BeanPostProcessor。这里注册的这些bean定义在后面会先于普通bean定义被初始化,并在某个该它出手的阶段就会被调用相关方法,随后就会处理相关的注解!
- ConfigurationClassPostProcessor -> 用于处理@Configuration、@ComponentScan、@ComponentScans @Import 、@Bean注解-> 一个BeanDefinitionRegistryPostProcessor,非常重要。
- AutowiredAnnotationBeanPostProcessor -> 用于处理@Autowired、@Value、@Inject、@Lookup注解 -> 一个BeanPostProcessor,非常重要。
- CommonAnnotationBeanPostProcessor(要求支持JSR 250,默认支持) -> 用于处理@Resource、@PostConstruct、@PreDestroy、@WebServiceRef、@EJB等注解 -> 一个BeanPostProcessor,非常重要。
- PersistenceAnnotationBeanPostProcessor(要求支持JPA,默认不支持,需要引入JPA依赖) -> 用于处理JPA的相关注解,比如@PersistenceContext和@PersistenceUnit -> 一个BeanPostProcessor
- EventListenerMethodProcessor -> 用于处理@EventListener注解 -> 一个 SmartInitializingSingleton
- DefaultEventListenerFactory ->用于注册为解析@EventListener注解的方法而创建ApplicationListener的策略接口对应 -> 一个EventListenerFactory
- 注意,自Spring5.1开始,RequiredAnnotationBeanPostProcessor后处理器不被自动注册,因为Spring不赞成使用@Required注解,对于必须的依赖推荐使用构造器注入。
该方法zh注册的这些处理器,在后面bean实例化的时候将会被非常频繁的使用到,用于解析个注解对于bean进行装配和增强。
//------------AnnotationConfigUtils工具类的相关属性
/**
* ConfigurationClassPostProcessor的bean name常量
*/
public static final String CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME =
"org.springframework.context.annotation.internalConfigurationAnnotationProcessor";
/**
* AutowiredAnnotationBeanPostProcessor的bean name常量
*/
public static final String AUTOWIRED_ANNOTATION_PROCESSOR_BEAN_NAME =
"org.springframework.context.annotation.internalAutowiredAnnotationProcessor";
/**
* CommonAnnotationBeanPostProcessor的bean name常量
*/
public static final String COMMON_ANNOTATION_PROCESSOR_BEAN_NAME =
"org.springframework.context.annotation.internalCommonAnnotationProcessor";
/**
* PersistenceAnnotationBeanPostProcessor的bean name常量,用于JPA 注解支持
*/
public static final String PERSISTENCE_ANNOTATION_PROCESSOR_BEAN_NAME =
"org.springframework.context.annotation.internalPersistenceAnnotationProcessor";
/**
* PersistenceAnnotationBeanPostProcessor的bean class常量,用于JPA 注解支持
*/
private static final String PERSISTENCE_ANNOTATION_PROCESSOR_CLASS_NAME =
"org.springframework.orm.jpa.support.PersistenceAnnotationBeanPostProcessor";
/**
* EventListenerMethodProcessor的bean name常量
*/
public static final String EVENT_LISTENER_PROCESSOR_BEAN_NAME =
"org.springframework.context.event.internalEventListenerProcessor";
/**
* DefaultEventListenerFactory的bean name常量
*/
public static final String EVENT_LISTENER_FACTORY_BEAN_NAME =
"org.springframework.context.event.internalEventListenerFactory";
/**
* AnnotationConfigUtils工具类的方法
*
* 在给定注册表中注册所有注解配置处理器的bean定义,用于后续步骤中对相关注解的处理
*
* ConfigurationClassPostProcessor -> 用于处理@Configuration注解 -> 一个BeanDefinitionRegistryPostProcessor
* AutowiredAnnotationBeanPostProcessor -> 用于处理@Autowired、@Value、@Inject、@Lookup注解 -> 一个BeanPostProcessor
* CommonAnnotationBeanPostProcessor(要求支持JSR 250,默认支持) -> 用于处理@Resource、@PostConstruct、@PreDestroy、@WebServiceRef、@EJB等注解 -> 一个BeanPostProcessor
* PersistenceAnnotationBeanPostProcessor(要求支持JPA,默认不支持,需要引入JPA依赖) -> 用于处理JPA的相关注解,比如@PersistenceContext和@PersistenceUnit -> 一个BeanPostProcessor
* EventListenerMethodProcessor -> 用于处理@EventListener注解 -> 一个 SmartInitializingSingleton
* DefaultEventListenerFactory ->用于注册为解析@EventListener注解的方法而创建ApplicationListener的策略接口对应 -> 一个EventListenerFactory
*
* 注意,自Spring5.1开始,RequiredAnnotationBeanPostProcessor后处理器不被自动注册,因为Spring不赞成使用@Required注解,对于必须的依赖推荐使用构造器注入
*
* @param registry 要操作的注册表
* @param source 触发此注册的配置源
* @return 此方法实际注册的所有注解后处理器的 Bean 定义
*/
public static Set<BeanDefinitionHolder> registerAnnotationConfigProcessors(
BeanDefinitionRegistry registry, @Nullable Object source) {
//获取beanFactory,就是registry自身
DefaultListableBeanFactory beanFactory = unwrapDefaultListableBeanFactory(registry);
if (beanFactory != null) {
//设置比较器,可以看到设置的是AnnotationAwareOrderComparator比较器,可以支持PriorityOrdered接口、Ordered接口、@Ordered注解、@Priority注解的排序,比较优先级为PriorityOrdered>Ordered>@Ordered>@Priority
//后面会学习的OrderComparator 比较器只支持PriorityOrdered、Ordered接口的排序,比较优先级为PriorityOrdered>Ordered
//如果最终没找到设置的排序值,那么返回Integer.MAX_VALUE,即最低优先级。
if (!(beanFactory.getDependencyComparator() instanceof AnnotationAwareOrderComparator)) {
beanFactory.setDependencyComparator(AnnotationAwareOrderComparator.INSTANCE);
}
//设置一个ContextAnnotationAutowireCandidateResolver,以决定是否应将 Bean 定义视为主动注入的候选项。
if (!(beanFactory.getAutowireCandidateResolver() instanceof ContextAnnotationAutowireCandidateResolver)) {
beanFactory.setAutowireCandidateResolver(new ContextAnnotationAutowireCandidateResolver());
}
}
Set<BeanDefinitionHolder> beanDefs = new LinkedHashSet<>(8);
/*
* 如果注册表的beanDefinitionMap缓存中没有"org.springframework.context.annotation.internalConfigurationAnnotationProcessor"为name的缓存
* 那么创建并且注册一个BeanDefinitionRegistryPostProcessor后处理器的bean定义,用于处理@Configuration注解
*/
if (!registry.containsBeanDefinition(CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(ConfigurationClassPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME));
}
/*
* 如果注册表的beanDefinitionMap缓存中没有"org.springframework.context.annotation.internalAutowiredAnnotationProcessor"为name的缓存
* 那么创建并且注册一个AutowiredAnnotationBeanPostProcessor后处理器的bean定义,用于处理@Autowired、@Value、@Inject、@Lookup注解
*/
if (!registry.containsBeanDefinition(AUTOWIRED_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(AutowiredAnnotationBeanPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, AUTOWIRED_ANNOTATION_PROCESSOR_BEAN_NAME));
}
/*
* 检查 JSR-250 支持,如果存在JSR-250的依赖,并且注册表的beanDefinitionMap缓存中没有"org.springframework.context.annotation.internalCommonAnnotationProcessor"为name的缓存
* 那么创建并且注册一个CommonAnnotationBeanPostProcessor后处理器的bean定义,用于处理@Resource、@PostConstruct、@PreDestroy、@WebServiceRef、@EJB等注解
*/
// Check for JSR-250 support, and if present add the CommonAnnotationBeanPostProcessor.
if (jsr250Present && !registry.containsBeanDefinition(COMMON_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(CommonAnnotationBeanPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, COMMON_ANNOTATION_PROCESSOR_BEAN_NAME));
}
/*
* 检查 JPA 支持,如果存在JPA的依赖,并且注册表的beanDefinitionMap缓存中没有"org.springframework.context.annotation.internalPersistenceAnnotationProcessor"为name的缓存
* 那么创建并且注册一个PersistenceAnnotationBeanPostProcessor后处理器的bean定义,用于处理JPA的相关注解,比如@PersistenceContext和@PersistenceUnit
*/
// Check for JPA support, and if present add the PersistenceAnnotationBeanPostProcessor.
if (jpaPresent && !registry.containsBeanDefinition(PERSISTENCE_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition();
try {
def.setBeanClass(ClassUtils.forName(PERSISTENCE_ANNOTATION_PROCESSOR_CLASS_NAME,
AnnotationConfigUtils.class.getClassLoader()));
} catch (ClassNotFoundException ex) {
throw new IllegalStateException(
"Cannot load optional framework class: " + PERSISTENCE_ANNOTATION_PROCESSOR_CLASS_NAME, ex);
}
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, PERSISTENCE_ANNOTATION_PROCESSOR_BEAN_NAME));
}
/*
* 如果注册表的beanDefinitionMap缓存中没有"org.springframework.context.event.internalEventListenerProcessor"为name的缓存
* 那么创建并且注册一个EventListenerMethodProcessor后处理器的bean定义,用于处理@EventListener注解
*/
if (!registry.containsBeanDefinition(EVENT_LISTENER_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(EventListenerMethodProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, EVENT_LISTENER_PROCESSOR_BEAN_NAME));
}
/*
* 如果注册表的beanDefinitionMap缓存中没有"org.springframework.context.event.internalEventListenerFactory"为name的缓存
* 那么创建并且注册一个DefaultEventListenerFactory后处理器的bean定义,用于为使用@EventListener注解的方法而创建ApplicationListener的策略接口
*/
if (!registry.containsBeanDefinition(EVENT_LISTENER_FACTORY_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(DefaultEventListenerFactory.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, EVENT_LISTENER_FACTORY_BEAN_NAME));
}
return beanDefs;
}
/**
1. AnnotationConfigUtils工具类的方法
2. 3. 注册相关注解后处理器的bean定义到注册表缓存中
4. 5. @param registry 注册表
6. @param definition 注解后处理器的bean定义
7. @param beanName beanName
8. @return 当前bean定义的BeanDefinitionHolder
*/
private static BeanDefinitionHolder registerPostProcessor(
BeanDefinitionRegistry registry, RootBeanDefinition definition, String beanName) {
definition.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
//调用registerBeanDefinition方法注册BeanDefinition到注册表的缓存中,该方法此前已经讲过了
registry.registerBeanDefinition(beanName, definition);
//将definition和beanName封装成为一个BeanDefinitionHolder对象并返回
return new BeanDefinitionHolder(definition, beanName);
}
3 小结
- 我们主要学习了ComponentScanBeanDefinitionParser的parser方法,也就是对
- 在解析的最后,在
registerComponents方法中还会注册一系列的注解处理器,这些处理器专门用于解析、支持特定的注解,将会在后面bean实例化的时候大放异彩,我们后面的文章中将经常遇见这些处理器。 - Spring 5开始,除了包路径组件扫描之外,还支持
spring.components组件索引扩展点。 当项目中存在"META-INF/spring.components"组件索引文件并且配置了属性时,Spring不会进行包扫描,而是直接读取"META-INF/spring.components"中的组件的定义并直接加载,从而达到提升性能的目的,因为如果一个项目的包路径和组件很多,那么扫描将会是一个非常耗时的工序。但是组件索引有它自己的局限,并且用的公司和项目还不是很多,这部分知识点不做要求。 - 我们还讲解了自定义
命名空间扩展点 ,该过程涉及到:xsd——Schema约束文件、spring.handlers ——定义命名空间到NamespaceHandler的实现的映射文件、spring.schemas——定义schema约束文件的位置、BeanDefinitionParser解析器、NamespaceHandlerSupport支持器、XML配置等等文件的编写。过程比较繁杂,这部分知识点不做要求。
我们知道,Spring可配置的自定义标签非常的多,因此剩余的其它比较重要的标签,将会在后面适当的时机再补充解析,比如学习aop源码的时候,我们可能会讲aop相关标签的解析源码。
相关文章:
https://spring.io/
Spring Framework 5.x 学习
Spring Framework 5.x 源码
如有需要交流,或者文章有误,请直接留言。另外希望点赞、收藏、关注,我将不间断更新各种Java学习博客!