第二十课.CART
目录
- 回归树的生成
-
- 回归树的定义
- 预测值的确定
- 特征空间的划分
- 算法流程
- 分类树的生成
-
- 分类树的对比总结
- 基尼指数的计算
- 算法流程
- CART剪枝
-
- ID3、C4.5 剪枝的不足
- ID3、C4.5 剪枝改进:CART 剪枝
- CART 剪枝的案例
- CART 剪枝过程图解
- CART 剪枝算法总结
分类与回归树(classification and regression tree,简称 CART)既可以用于分类,也可以用于回归。与 ID3 和 C4.5 算法(回顾 第十一课决策树)不同,CART 是 二叉决策树,内部结点特征的取值为是和否,左分支的取值为是,右分支的取值为否。
CART 算法包含特征选择、决策树的生成和决策树的剪枝三个部分,这个流程与 ID3、C4.5算法是一样的。回归树使用平方误差进行特征选择,而分类树使用基尼指数进行特征选择。
回归树的生成
回归树的定义
回归树属于决策树的一种,准确来说是用来解决回归问题的二叉决策树。既然是解决回归问题,那么回归树的预测值就是一个连续值。下面是回归树的简单图示:

从图中可以看出,已经构建好的回归树可以根据身高和年龄这两个特征来预测体重的取值。例如:输入的特征向量 [168,24] 满足:身高小于等于 175cm,年龄大于 18岁,故预测体重的取值为 58kg;
一棵回归树对应着特征空间的一个划分以及在划分的单元上的输出值。假设已将特征空间划分为 M M M 个单元 R 1 R_{1} R1, R 2 R_{2} R2,…, R M R_{M} RM,并且在每个单元 R m R_{m} Rm 上有一个固定的输出值 c m c_{m} cm,则回归树模型可以表示为:
f ( x ) = ∑ m = 1 M c m I ( x ∈ R m ) f(x)=\sum_{m=1}^{M}c_{m}I(x\in R_{m}) f(x)=m=1∑McmI(x∈Rm)
其中 I I I 为指示函数,当输入的条件成立时,指示函数取值为 1;否则取值为 0;
上面的回归树将二维特征空间 [身高,年龄] 划分为 3 个单元,由于特征向量 [168,24] 属于 R 2 R_{2} R2 单元,故体重的预测值为 58:

预测值的确定
假设特征空间的划分已确定,如上图所示, R 2 R_{2} R2 单元对应的预测值 c 2 c_{2} c2 应该尽量使其中的训练样本的预测损失最小。使用平方误差作为损失函数,假设 R 2 R_{2} R2 中有三个训练样本(值为 y y y) ,则预测值为 c 2 c_{2} c2 产生的损失为:
l o s s ( c 2 ) = ∑ i = 1 3 ( y i − c 2 ) 2 loss(c_{2})=\sum_{i=1}^{3}(y_{i}-c_{2})^{2} loss(c2)=i=1∑3(yi−c2)2
令损失函数的导数为零,可以求出损失函数取最小值时对应的预测输出值:
l o s s ′ ( c 2 ) = − 2 ∑ i = 1 3 ( y i − c 2 ) = 0 ⇒ c 2 = 1 3 ∑ i = 1 3 y i loss^{'}(c_{2})=-2\sum_{i=1}^{3}(y_{i}-c_{2})=0\Rightarrow c_{2}=\frac{1}{3}\sum_{i=1}^{3}y_{i} loss′(c2)=−2i=1∑3(yi−c2)=0⇒c2=31i=1∑3yi
由此可知,划分单元 R m R_{m} Rm 上的最优预测值为该单元中所有训练样本标记值的平均值:
c ^ m = 1 ∣ R m ∣ ∑ x i ∈ R m y i \widehat{c}_{m}=\frac{1}{|R_{m}|}\sum_{x_{i}\in R_{m}}y_{i} c m=∣Rm∣1xi∈Rm∑yi
其中, ∣ R m ∣ |R_{m}| ∣Rm∣为 R m R_{m} Rm中训练样本的数量
特征空间的划分
上面讨论了在特征空间的划分已确定的前提下,如何确定最优的预测值。下面是划分特征空间的具体方法。
特征空间的划分是递归地二分每个特征,从而将特征空间划分为有限个单元。要解决的问题有两个:
- 第一,选择哪个特征对样本进行划分?
- 第二,切分点如何选取?
还是体重预测的例子,从根节点开始对特征空间进行划分。在根节点选择了身高这个特征,切分点为 175,身高小于等于 175 的样本被划分到左子树,否则被划分到右子树。实际上也可以选择年龄这个特征对样本进行划分,并且切分点的取值也是可选的。问题来了,在回归树的某个结点进分裂(或者叫特征空间的划分)时,如何判断划分的好坏?
回归树的生成是递归地将训练样本二分到左右子树中,并且每个子树对应的划分单元都有一个固定的最优预测值(训练样本标记值的均值),所以我们可以使用左右子树中训练样本的平方误差和来衡量划分的好坏。
假设选择特征 x j x_{j} xj 和它取的值 s s s 作为划分变量和切分点,则左右子树对应的划分区域定义为:
R 1 ( j , s ) = { x ∣ x j ≤ s } , R 2 ( j , s ) = { x ∣ x j > s } R_{1}(j,s)=\left\{ x|x_{j}\leq s\right\},R_{2}(j,s)=\left\{ x|x_{j}>s\right\} R1(j,s)={ x∣xj≤s},R2(j,s)={ x∣xj>s}
根据如上划分, R 1 R_{1} R1 和 R 2 R_{2} R2 中训练样本的平方损失和为 l o s s ( j , s ) loss(j,s) loss(j,s),计算公式如下:
l o s s ( j , s ) = ∑ x i ∈ R 1 ( j , s ) ( y i − c ^ 1 ) 2 + ∑ x i ∈ R 2 ( j , s ) ( y i − c ^ 2 ) 2 loss(j,s)=\sum_{x_{i}\in R_{1}(j,s)}(y_{i}-\widehat{c}_{1})^{2}+\sum_{x_{i}\in R_{2}(j,s)}(y_{i}-\widehat{c}_{2})^{2} loss(j,s)=xi∈R1(j,s)∑(yi−c 1)2+xi∈R2(j,s)∑(yi−c 2)2
c ^ 1 = 1 ∣ R 1 ( j , s ) ∣ ∑ x i ∈ R 1 ( j , s ) y i \widehat{c}_{1}=\frac{1}{|R_{1}(j,s)|}\sum_{x_{i}\in R_{1}(j,s)}y_{i} c 1=∣R1(j,s)∣1xi∈R1(j,s)∑yi
c ^ 2 = 1 ∣ R 2 ( j , s ) ∣ ∑ x i ∈ R 2 ( j , s ) y i \widehat{c}_{2}=\frac{1}{|R_{2}(j,s)|}\sum_{x_{i}\in R_{2}(j,s)}y_{i} c 2=∣R2(j,s)∣1xi∈R2(j,s)∑yi
每次进行特征空间的划分时,只要遍历训练样本所有的特征和可能的取值,然后选择平方损失最小的特征和切分点即可
算法流程
输入:训练数据集
输出:回归树 f ( x ) f(x) f(x)
在训练数据集所在的特征空间里,递归地将每个区域划分为两个子区域,并确定每个子区域的输出值,构建二叉决策树,训练过程如下:
- 1.使用如下公式选择当前结点最优的切分变量 x j x_{j} xj 和切分点 s s s,并确定左右分支的预测值;
j ∗ , s ∗ = a r g m i n { j , s } [ ∑ x i ∈ R 1 ( j , s ) ( y i − 1 ∣ R 1 ( j , s ) ∣ ∑ x i ∈ R 1 ( j , s ) y i ) 2 + ∑ x i ∈ R 2 ( j , s ) ( y i − 1 ∣ R 2 ( j , s ) ∣ ∑ x i ∈ R 2 ( j , s ) y i ) 2 ] j^{*},s^{*}=argmin_{\left\{j,s \right\}}[\sum_{x_{i}\in R_{1}(j,s)}(y_{i}-\frac{1}{|R_{1}(j,s)|}\sum_{x_{i}\in R_{1}(j,s)}y_{i})^{2}+\sum_{x_{i}\in R_{2}(j,s)}(y_{i}-\frac{1}{|R_{2}(j,s)|}\sum_{x_{i}\in R_{2}(j,s)}y_{i})^{2}] j∗,s∗=argmin{ j,s}[xi∈R1(j,s)∑(yi−∣R1(j,s)∣1xi∈R1(j,s)∑yi)2+xi∈R2(j,s)∑(yi−∣R2(j,s)∣1xi∈R2(j,s)∑yi)2]
j j j 是训练样本的第 j j j 个特征, s s s 是该特征的某一个取值,在有限的训练样本中, j j j 和 s s s 都是有限的,故可以遍历所有的组合,找到使得平方损失最小的切分变量(特征)和切分点,将样本划分到左右两个子区域中;
实例如下:
import numpy as np
# 构造一些训练样本
data = np.array([[2,6,9],
[2,8,4],
[3,3,8],
[3,6,7],
[5,3,5],
[5,8,2]])
# 提取训练样本的特征向量
X_train = data[:,:-1] # X_train.shape (6,2)
# 提取训练样本的标记值
y_train = data[:,-1]
# 寻找最优切分点
def find_split(X,label):
# 存储不同特征、切分点以及对应的训练样本损失
result = dict()
# 遍历每个特征的索引
for j in range(X.shape[1]):
# 遍历所选特征的不同取值
for s in set(X[:,j]):
# 初始化左右两个子区域和对应的预测损失
R1,R2,loss = dict(),dict(),0
# 遍历训练样本,根据特征切分点将样本划分到不同区域中
for x,y in zip(X,label):
if x[j]<=s:
R1[tuple(x)] = y
else:
R2[tuple(x)] = y
# 计算左右两个区域的预测值,并累加对应的平方损失值
if len(R1)!=0:
c1_hat = sum([y_i for y_i in R1.values()])/len(R1)
loss += sum([(y_i-c1_hat)**2 for y_i in R1.values()])
if len(R2)!=0:
c2_hat = sum([y_i for y_i in R2.values()])/len(R2)
loss += sum([(y_i-c2_hat)**2 for y_i in R2.values()])
# 存储当前特征索引和切分点以及对应的平方损失
result[loss] = (j,s)
# 返回平方损失最小时对应的特征索引和切分点取值
"""
min(dict)对字典的key进行操作:
print(min({1:"a",2:"b",3:"c"})) #1
print(min({"f":1,"b":2,"c":3})) #b
"""
return result[min(result)]
# 对当前结点中的训练数据,寻找最优的特征与切分点
>>> find_split(X_train,y_train)
# 输出结果表示 x1<=6 时,样本被划分到左子树中,否则被划分到右子树
(1, 6)
- 2.对左右两个子区域调用步骤1,直至满足停止条件。
- 3.将特征空间划分为 M M M 个区域 R 1 R_{1} R1, R 2 R_{2} R2,…, R M R_{M} RM,生成回归决策树:
f ( x ) = ∑ i = 1 M c ^ m I ( x ∈ R m ) f(x)=\sum_{i=1}^{M}\widehat{c}_{m}I(x\in R_{m}) f(x)=i=1∑Mc mI(x∈Rm)
CART算法中的回归树是通过最小化训练样本的平方损失得到的,因此又叫最小二乘回归树
分类树的生成
分类树的对比总结
分类决策树的生成算法有三种,除了第十一课决策树的 ID3 和 C4.5 算法,CART 算法也包含了分类树的生成算法;
使用 CART 算法生成分类决策树与 ID3、C4.5 算法的区别:
- 首先,CART 算法使用基尼指数选择最优特征,同时决定该特征的最优二值切分点;而 ID3 算法使用信息增益选择最优特征,C4.5 算法使用信息增益比选择最优特征;
- 其次,CART 算法生成的分类树是二叉决策树,而 ID3、C4.5 算法生成的分类树是多叉树
基尼指数的计算
基尼指数是离散变量概率分布的函数。在分类问题中,假设训练集样本类别取值的概率分布为 p p p,则对应的基尼系数可以通过如下公式进行计算:
G i n i ( p ) = ∑ k = 1 K p k ( 1 − p k ) = 1 − ∑ k = 1 K p k 2 Gini(p)=\sum_{k=1}^{K}p_{k}(1-p_{k})=1-\sum_{k=1}^{K}p_{k}^{2} Gini(p)=k=1∑Kpk(1−pk)=1−k=1∑Kpk2
其中, K K K为样本类别数, p k p_{k} pk为样本属于第 k k k类的概率;
如图所示, Y Y Y 表示训练样本的类别取值, p p p 是对应的概率,计算样本类别的基尼指数为:

1 − ( 0. 3 2 + 0. 4 2 + 0. 3 2 ) = 0.66 1-(0.3^{2}+0.4^{2}+0.3^{2})=0.66 1−(0.32+0.42+0.32)=0.66
基尼指数越小,样本类别的不确定性就越小,例如上面例子中,如果 Y = 0 Y = 0 Y=0 的概率为 1,其他两个类别的概率为 0 ,则 G i n i ( p ) = 1 − ( 1 2 + 0 2 + 0 2 ) = 0 Gini(p) = 1-(1^{2}+0^{2}+0^{2}) = 0 Gini(p)=1−(12+02+02)=0,表示样本类别的不确定性为 0 ;
对于给定的训练样本集合 D D D ,可以统计各类样本的占比,然后计算样本集合 D D D 关于样本类别的基尼指数:
G i n i ( D ) = 1 − ∑ k = 1 K ( ∣ C k ∣ ∣ D ∣ ) 2 Gini(D)=1-\sum_{k=1}^{K}(\frac{|C_{k}|}{|D|})^{2} Gini(D)=1−k=1∑K(∣D∣∣Ck∣)2
其中, K K K为样本类别数, C k C_{k} Ck为属于第 k k k类的样本子集;
对于某个离散特征 A A A,根据是否取某一个可能值 a a a ,可以将样本集合 D D D 划分为两个子集:
D 1 = { ( x , y ) ∈ D ∣ A ( x ) = a } , D 2 = D − D 1 D_{1}=\left\{ (x,y)\in D|A(x)=a\right\},D_{2}=D-D_{1} D1={ (x,y)∈D∣A(x)=a},D2=D−D1
在特征 A A A 的条件下,集合 D D D 的基尼指数定义为:
G i n i ( D , A ) = ∣ D 1 ∣ ∣ D ∣ G i n i ( D 1 ) + ∣ D 2 ∣ ∣ D ∣ G i n i ( D 2 ) Gini(D,A)=\frac{|D_{1}|}{|D|}Gini(D_{1})+\frac{|D_{2}|}{|D|}Gini(D_{2}) Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
前面说过,CART 算法使用基尼指数选择最优特征,同时决定该特征的最优二值切分点;具体来说就是遍历不同的特征和所有可能的取值,然后选择基尼指数最小的特征和切分点
算法流程
输入:训练数据集 D D D,算法停止的条件
输出:CART 分类树
根据训练数据集 D D D ,从根节点开始,递归地对每个结点进行以下操作,构建二叉决策树:
- 1.假设当前结点的训练集为 D D D ,对于现有的每一个特征 A A A 和可能的取值 a a a ,使用如下公式选出基尼指数最小的特征和切分点:
A ∗ , a ∗ = a r g m i n { A , a } G i n i ( D , A ) A^{*},a^{*}=argmin_{\left\{A,a\right\}}Gini(D,A) A∗,a∗=argmin{ A,a}Gini(D,A) - 2.将训练样本划分到左右两个子结点中,根据多数表决的原则确定当前结点的预测值。下面是根据最优特征和最优切分点划分样本子集的方法:
D 1 = { ( x , y ) ∈ D ∣ A ∗ ( x ) = a ∗ } , D 2 = D − D 1 D_{1}=\left\{ (x,y)\in D|A^{*}(x)=a^{*}\right\},D_{2}=D-D_{1} D1={ (x,y)∈D∣A∗(x)=a∗},D2=D−D1 - 3.对两个子结点递归地调用步骤1和2,直到满足算法停止的条件
算法停止的条件有:当前节点中的样本个数小于设定的阈值;当前结点的基尼指数小于设定的阈值(基本属于同一类样本);用于当前结点分裂的特征集合为空。
CART剪枝
ID3、C4.5 剪枝的不足
决策树的剪枝算法,其基本思想是:遍历决策树的内部结点,若剪枝后决策树的损失函数 C α ( T ) C_{\alpha}(T) Cα(T)小于剪枝前的决策树,则对该内部结点进行剪枝,同时该内部结点变为叶子结点,剪枝过程的示意图如下:

决策树的损失函数
决策树的叶子节点越多,模型越复杂。决策树的损失函数考虑了模型复杂度;可以通过优化其损失函数来对决策树进行剪枝。决策树的损失函数计算过程如下:
- 计算叶子结点 t t t 的样本类别经验熵:
H t ( T ) = − ∑ k = 1 K N t k N t l o g N t k N t H_{t}(T)=-\sum_{k=1}^{K}\frac{N_{tk}}{N_{t}}log\frac{N_{tk}}{N_{t}} Ht(T)=−k=1∑KNtNtklogNtNtk
其中, N t N_{t} Nt为叶子节点 t t t 包含的训练样本个数, N t k N_{tk} Ntk为叶子节点 t t t 中样本类别为 C k C_{k} Ck 的样本个数;对于叶子结点 t t t 来说,其样本类别的经验熵越小, t t t 中训练样本的分类误差就越小。当叶子结点 t t t 中的训练样本为同一类别时,经验熵为零,分类误差为零。 - 计算决策树 T T T 在所有训练样本上的损失之和 C ( T ) C(T) C(T):
C ( T ) = ∑ t = 1 ∣ T ∣ N t H t ( T ) C(T)=\sum_{t=1}^{|T|}N_{t}H_{t}(T) C(T)=t=1∑∣T∣NtHt(T)
N t N_{t} Nt为叶子节点 t t t 包含的训练样本个数, ∣ T ∣ |T| ∣T∣是决策树 T T T 包含的叶子节点个数;对于叶子结点 t t t 中的每一个训练样本,其类别标记都是随机变量 Y Y Y 的一个取值,这个取值的不确定性用信息熵来衡量,且可以用经验熵来估计。由上文可知,经验熵在一定程度上可以反映决策树在该样本上的预测损失,累加所有叶子结点上的训练样本损失即上面的计算公式。 - 计算考虑模型复杂度的的决策树损失函数:
C α ( T ) = C ( T ) + α ∣ T ∣ , α ⩾ 0 C_{\alpha}(T)=C(T)+\alpha |T|,\alpha \geqslant 0 Cα(T)=C(T)+α∣T∣,α⩾0
α \alpha α为正则化系数,控制模型复杂度;决策树的叶子结点个数表示模型的复杂度,通过最小化上面的损失函数,一方面可以减少模型在训练样本上的预测误差,另一方面可以控制模型的复杂度,保证模型的泛化能力。
但是, α \alpha α 仅靠人工经验值的判断还是很难保证模型在特定数据场景下的泛化性能。
ID3、C4.5 剪枝改进:CART 剪枝
针对 ID3 和 C4.5 剪枝算法的不足,CART 算法做了如下改进:对于 α \alpha α 取不同值进行剪枝后的决策树,在独立的验证数据集上进行测试,然后选择在验证集上表现最好的决策树作为最终的剪枝结果。
现在问题是: α \alpha α 是一个非负数,可以选择的值有很多,要选择哪些值来作为剪枝的候选超参?
CART 剪枝算法的做法是在 α \alpha α 的特定区间内得到剪枝后的子树,然后将所有区间内的子树拿到验证集上测试,从而选出验证集上平方误差或基尼指数最小的最优子树。
CART 剪枝的案例
下面来看一个例子:

如上图所示, T 0 T_{0} T0 是 CART 算法生成的二叉决策树。除根结点外,图中标出了每个子结点的损失,若为分类树,则损失为结点中训练样本类别的基尼指数;若为回归树,则损失为结点中训练样本的平方误差和;
对于整个决策树 T 0 T_{0} T0,它的损失为叶子结点经验损失的和,从前面决策树的损失函数表达式可知,正则化系数 α \alpha α 越大,剪枝后的决策树结构就越简单,叶子结点数就越少。极端情况下,当 a l p h a = 0 alpha = 0 alpha=0 时,不剪枝;当 α \alpha α 取正无穷时,剪枝结果是以根节点为叶子结点的单结点树;
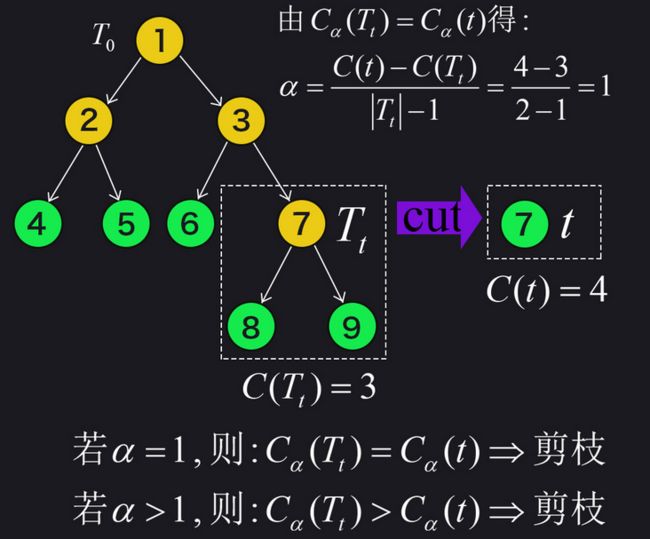
如下图所示,对 T 0 T_{0} T0 任意内部结点 t t t(这里取7号结点)构成的子树 T t T_{t} Tt 进行剪枝:

α = 0 \alpha = 0 α=0 时,剪枝后的损失大于剪枝前,故不剪枝。对比上面的两个虚线框,由于剪枝前的 T t T_{t} Tt 叶子结点更多一些,而每个叶子结点都会产生一个 α \alpha α 的损失,故当 α \alpha α 增大时, T t T_{t} Tt 的损失增大量要比 t t t 的多,当 α \alpha α 增大到某个临界点时,剪枝前后的损失相同。
为了方便对比,这里给出7号结点构成的子树 T t T_{t} Tt 剪枝前后的损失:
C α ( T t ) = C ( T t ) + α ∣ T t ∣ , C α ( t ) = C ( t ) + α ∣ t ∣ C_{\alpha}(T_{t})=C(T_{t})+\alpha |T_{t}|,C_{\alpha}(t)=C(t)+\alpha |t| Cα(Tt)=C(Tt)+α∣Tt∣,Cα(t)=C(t)+α∣t∣
令二者的损失相同,可以求出对应的 α \alpha α 值:

当 α \alpha α 大于 1 时,比如 α = 1.5 \alpha=1.5 α=1.5,对比两个虚线框中决策树的损失,只有正则化项增加了,且 T t T_{t} Tt 比 t t t 多增加了 1个 α \alpha α 的变化量(0.5)
将上面剪枝后的决策树记为 T 1 T_{1} T1。对于 T 1 T_{1} T1 ,采取和 T 0 T_{0} T0 一样的处理方式,先计算内部结点剪枝前后结构风险相同的 α \alpha α 值,当 α \alpha α 大于等于这个临界值时,对 T 1 T_{1} T1 进行剪枝,如下图所示:

将上图 3 号结点剪枝后得到的子树记为 T 2 T_{2} T2,增大 α \alpha α,达到临界点后对 T 2 T_{2} T2 继续剪枝:

直到剪枝后的决策树变成由根节点和两个叶子结点构成的子树为止,本例中记为 T 3 T_{3} T3,如图所示:

CART 剪枝过程图解
对于上述的剪枝过程,可以用一幅图来展示:

从图中可以看出,当 α = [ 0 , 1 ) \alpha = [0,1) α=[0,1) 时,不剪枝;当 α = [ 1 , 2 ) \alpha = [1,2) α=[1,2) 时,剪枝得到子树 T 1 T_{1} T1;当 α = [ 2 , 3 ) \alpha = [2,3) α=[2,3) 时,剪枝得到子树 T 2 T_{2} T2;当 α = [ 3 , ∞ ) \alpha = [3,\infty) α=[3,∞) 时,剪枝得到 T 3 T_{3} T3;
其中, α = 1 , 2 , 3 \alpha = 1,2,3 α=1,2,3 为剪枝前后损失相同的临界点。需要注意的一点是:每次计算 α \alpha α 的临界点时,是在未剪枝决策树的所有内部结点进行的,每个内部结点都可以计算出一个临界 α \alpha α 值,但我们需要选择最小的那个;举例说明,如下图所示:
对于 T 0 T_{0} T0,我们需要根据图中 α \alpha α 的计算公式,对所有的内部结点 1,2,3,7 计算出一个值,然后取最小值。为了方便展示与理解,假设在所有示例中,虚线框里的内部结点所计算出的 α \alpha α 值最小;
再回顾 CART 剪枝过程图,图中横坐标为超参数 α \alpha α,纵坐标为决策树 T T T 的结构风险(损失)。从图中可以看出, T 0 T_{0} T0 结构风险的取值范围是:[21,26], T 1 T_{1} T1 结构风险的取值范围是:[26,30], T 0 T_{0} T0 和 T 1 T_{1} T1 在 α = 1 \alpha =1 α=1 时,结构风险都是 26;
观察上图,还有一个规律: T 0 T_{0} T0 的经验风险为 21,它有 5 个叶子结点,所有右边界的结构风险为 21 + 5 × 1 = 26 21+5\times 1=26 21+5×1=26; T 1 T_{1} T1 的经验风险为 22,它有 4 个叶子结点,所以右边界的结构风险为 22 + 4 × 2 = 30 22+4\times 2=30 22+4×2=30。所以对于图中不同的决策树,当决策树的结构固定时,引起结构风险发生变化的是横坐标 α \alpha α;
假如将 T 0 T_{0} T0 和 T 1 T_{1} T1 同时从 α = 1 \alpha =1 α=1 处向右平移 δ \delta δ 个单位( δ < 1 \delta <1 δ<1),则二者结构风险中的正则化项将同时增加,其中 T 0 T_{0} T0 结构风险的正则化项增加 5 个 δ \delta δ, T 1 T_{1} T1 结构风险的正则化项增加 4 个 δ \delta δ。可见, T 0 T_{0} T0 平移到 [1,2) 区间中的 结构风险是要大于 T 1 T_{1} T1 的,因而需要剪枝成为 T 1 T_{1} T1;
上述过程得到的是 α \alpha α 在不同区间下剪枝后的子树,如示例中的 T 1 T_{1} T1、 T 2 T_{2} T2、 T 3 T_{3} T3,这些子树是依次嵌套的。使用独立的验证集选出这些子树中经验损失(如平方误差、基尼指数)最小的子树,就是剪枝后的最优子树
CART 剪枝算法总结
输入:CART 算法生成的决策树 T 0 T_{0} T0
输出:剪枝后的最优子树 T α T_{\alpha} Tα
- 1.初始化 k = 0 k = 0 k=0, T = T 0 T = T_{0} T=T0;
- 2.初始化 α = ∞ \alpha = \infty α=∞,遍历 T T T 的内部结点 t t t ,依次计算:
g ( t ) = C ( t ) − C ( T t ) ∣ T t − 1 ∣ , α = m i n ( α , g ( t ) ) g(t)=\frac{C(t)-C(T_{t})}{|T_{t}-1|},\alpha=min(\alpha,g(t)) g(t)=∣Tt−1∣C(t)−C(Tt),α=min(α,g(t))
这里每遍历一个内部结点,都把其对应的 g ( t ) g(t) g(t) 值记录下来,方便下一步和最小的 α \alpha α 对比; - 3.对 g ( t ) = α g(t) = \alpha g(t)=α 的内部结点 t t t 进行剪枝,得到剪枝后的决策树 T T T;且内部结点 t t t 变为叶子结点,通过取平均或多数表决的方法决定叶子结点的预测值;
- 4.令 k + = 1 k += 1 k+=1 , α k = α \alpha_{k} = \alpha αk=α , T k = T T_{k} = T Tk=T;
- 5.若 T k T_{k} Tk 不是由根结点和两个叶子结点构成的树,则返回步骤2,否则令 T k = T n T_{k} = T_{n} Tk=Tn;
- 6.采用交叉验证法,在子树序列 T 0 T_{0} T0, T 1 T_{1} T1,…, T n T_{n} Tn 中选择最优子树 T α T_{\alpha} Tα