python爬虫系列下载_Python爬虫自学系列(三)

前言
上一篇是短了点,但是并不是草率了啊。
好的上一篇刚发两个小时,咱就不讨论了,这一篇主要是讲下载中的缓存,既然大家都喜欢用爬虫去批量下载图片、音频、视频之类的,那么我自然也喜欢呐。
缓存 or 不缓存?it’s a problem
做后端开发的小伙伴对缓存是不会陌生的了。
当然,其他小伙伴可能就不是很清楚缓存是什么了。
缓存,将数据暂时存储在内存中。
内存,不是你的那些硬盘。
内存资源是有限的,磁盘读取是比较慢的,所以该怎么选就得看你自己掂量掂量了。
如果你需要执行一个大型爬取工作,那么它可能会由于错误或异常被中断,缓存可以帮助你无须重新爬取那些可能已经抓取过的页面。缓存还可以让你在离线时访问这些页面(出于数据分析或开发的目的)。
不过,如果你的最高优先级是获得网站最新和当前的信息,那此时缓存就没有意义。此外,如果你没有计划实现大型或可重复的爬虫,那么可能只需要每次去抓取页面即可。
如果还有其他疑虑,可以先查一下,我们马上进入缓存操作阶段–>
简单框架
我这儿啊,有这么一个框架,
基本思路就是:
1、从url池里读取一个url之后,先判断一下是否已经有缓存了。
2、如果有缓存了,那就跳过。
3、如果没有缓存,那就解析这个url。
4、全部完事儿之后,记得释放该释放的缓存。
好,我们先来说一下requests_cache。
requests_cache 缓存中间件
Requests模块的扩展功能,通过Requests发送请求来生成相应的缓存数据。当Requests重复向同一个URL发送请求的时候,Requests-Cache会判断当前请求是否已产生缓存,若已有缓存,则从缓存里读取数据作为响应内容;若没有缓存,则向网站服务器发送请求,并将得到的响应内容写入相应的数据库里。
减少网络资源重复请求的次数,不仅减轻了本地的网络负载,而且还减少了爬虫对网站服务器的请求次数,这也是解决反爬虫机制的一个重要手段。
这个安装呢,在pycharm里面我是找不到了,就去终端下载吧。
缓存机制由install_cache()方法实现
install_cache()
参数
说明
cache_name
默认值为cache,这是对缓存的存储文件进行命名
backend
设置缓存的存储机制,默认值为None,即默认sqlite数据库存储
expire_after
设置缓存的有效时间,默认值None,即为永久有效
allowable_codes
设置HTTP的状态码,默认值为200
allowable_methods
设置请求方式,默认值是只允许GET请求才能生成缓存
session_factory
设置缓存的执行对象,由CachedSession类实现,该类是由Requests-Cache定义
**backend_options
设置存储配置,若缓存的存储选择sqlite、redis或mongoDB数据库,则该参数是设置数据库的连接方式
使用示例
import requests
import requests_cache
# 使用requests_cache()方法
requests_cache.install_cache('test_cache')
# 清除已有的缓存
requests_cache.clear()
# 访问自己用flask创建的简易系统
url = 'https://join.qq.com/post.html?pid=1'
# 创建session会话
session = requests.session()
# 执行两次访问:
for t in range(2): req = session.get(url) # from_cache是requests_cache的函数,如果输出True,说明生成缓存 print(req.from_cache)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
咱也没法去人家的后台看访问次数了,要是有想法测试可以自己建个站,flask快速建站。
运行上述代码,程序会依次输出False和True, False代表第一次访问还没有生成相关的缓存;True代表第二次访问就已有相关的缓存数据。同时代码所在的文件路径中会生成 test_cache.sqlite 文件,这是sqlite数据库文件,用于存储缓存信息。
关于requests_cache的其他问题
我认真的研究了,这个缓存吧,在你创建之后,就会自动的去纪录你的浏览足迹,记住,是浏览痕迹。
就是说,
1、不用你去手动纪录
2、浏览之后,你对网页数据干了什么,它不管。
3、不用你去手动释放
所以还有什么问题再提。所以这块儿也没什么好封装的了,撑死就那么两行☺☺
redis缓存
这,我要先推一波我的 redis 系列,我觉得很不错。
不过实践部分都是基于Linux平台的,所以我就放理论部分吧:
redis系列挑着看
集群啊,哨兵啊,主从复制啥的就不说啦,有兴趣的朋友可自行到我的redis底下的专栏翻一翻。
好吧,发现这篇才是最重要的,虽然它最不起眼,而且一个收藏量都没有:【redis入门】redis安装后相关知识串讲
Windows安装redis
打开终端,进入到刚才解压到的目录
临时服务:redis-server.exe redis.windows.conf (备注:通过这个命令,会创建Redis临时服务,不会在window Service列表出现Redis服务名称和状态,此窗口关闭,服务会自动关闭。)
安装服务:redis-server.exe --service-install redis.windows.conf --service-name redisserver1 --loglevel verbose
启动服务:redis-server.exe --service-start --service-name redisserver1 (整好之后终端可以关了)
关闭服务:redis-server.exe --service-stop --service-name redisserver1
卸载服务:redis-server.exe --service-uninstall–service-name redisserver1
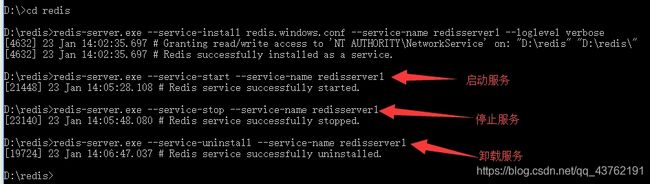
再打开一个终端,依旧进入安装目录,打开客户端:redis-cli.exe -h 127.0.0.1 -p 6379(开不开都可以)
Python获得redis支持
pip install redis1
简单测试一下:
import redis
r = redis.StrictRedis(host='localhost', port=6379, db=0)
r.set('ping','pong')
print(r.get('ping'))1
2
3
4
5
6
7
从 get 输出中可以看到,我们从 Redis 存储中接收到的是 bytes 类型,即使我们插入的是字典或字符串。
其他的问题,都很最原始的redis相差无几,可以先在上面的链接中求解。
如果set的时候有值存在,Redis的set命令只是简单地覆盖了之前的值,这对于类似网络爬虫这样的简单存储来说非常合适。对于我们的需求而言,我们只需要每个 URL 有一个内容集合即可,因此它能够很好地映射为键值对存储。
keys 方法返回了所有可用键的列表,而 delete 方法可以让我们传递一个(或多个)键并从存储中删除它们。我们还可以删除所有的键(flushdb)。
import redis
r = redis.StrictRedis(host='localhost', port=6379, db=0)
r.set('ping','pong')
print(r.keys())
r.flushdb()
print(r.keys())1
2
3
4
5
6
7
8
9
10
11
拿去试试看。
redis 存取与序列化封装
先封装一套:
import json
from datetime import timedelta
from redis import StrictRedis
class RedisCache: def __init__(self, client=None, expires=timedelta(days=30), encoding='utf-8'): self.client = StrictRedis(host='localhost', port=6379, db=0) if client is None else client#这个操作有点骚气 self.expires = expires self.encoding = encoding def __getitem__(self, url): record = self.client.get(url) if record: return json.loads(record.decode(self.encoding)) else: raise KeyError(url + ' does not exist') def __setitem__(self, url, result): data = bytes(json.dumps(result), self.encoding) self.client.setex(url, self.expires, data)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
在这里我们使用了 json 模块控制序列化,并使用了 setex 方法,能够使我们在设置键值时附带过期时间。
压缩
别问我为什么要压缩,问就是省空间呐!!!
先对数据进行序列化,然后使用 zlib 进行压缩。
import json
from datetime import timedelta
from redis import StrictRedis
import zlib
class RedisCache: def __init__(self, client=None, expires=timedelta(days=30), encoding='utf-8',compress=True): self.client = StrictRedis(host='localhost', port=6379, db=0) if client is None else client self.expires = expires self.encoding = encoding self.compress = compress def __getitem__(self, url): record = self.client.get(url) if record: if self.compress: record = zlib.decompress(record) return json.loads(record.decode(self.encoding)) else: raise KeyError(url + ' does not exist') def __setitem__(self, url, result): data = bytes(json.dumps(result), self.encoding) if self.compress: data = zlib.compress(data) self.client.setex(url, self.expires, data)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
缓存部分到此告一段落,其实还有个办法:
将数据存储到硬盘上,然后再redis缓存中以网址为键,硬盘地址为值进行存储。
想了想。图片,音频,视频等下载部分还是放到下一篇吧,这篇有点难了已经。
喜欢的小伙伴可以点赞评论收藏哦,跟紧我,爬虫路上不孤单。

文章来源: lion-wu.blog.csdn.net,作者:看,未来,版权归原作者所有,如需转载,请联系作者。
原文链接:lion-wu.blog.csdn.net/article/details/112886972