逻辑回归,决策树,随机森林,KNN,高斯贝叶斯模型在智联招聘招聘信息的机器学习表现
1.算法讲解:
决策树(Decision Tree)
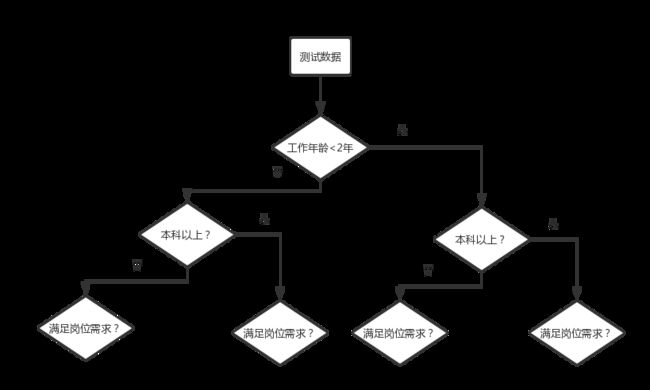
决策树很通俗直观哈。我们在一次次按条件将训练数据分割的过程,就是一个训练的过程。就像我们不停地问问题,不停地用排除法,最后得出结果。
如图所示,工作年龄小于2是第一个分割节点。把所有招聘信息工作年龄小于2年的放到图的左边分支,大于等于2年的放到右边。一个点产生两个分支(我们也可以设置多个分支)。然后对于学历小于本科年的和大于本科的接着问第二个问题进行分割。以此递归类推。最后数据越分越少,最后我们就建成了一棵树。树的末端叫做叶子。最后每一条招聘信息都会分到一个的叶子节点上,一个叶子节点可以有一个或者多个招聘信息组成。这个例子是一个回归问题,我们可以取分到同一个叶子点的招聘信息类别作为最后结果。对于分类问题,每个叶子是一个类别,如果分到这个叶子点的数据类别不一致,一般取个数最多的类作为这个叶子的输出类。
Random Forest
随机森林,顾名思义就是由很多决策树组成的森林。随机意味着每棵树之间没有任何联系,都是独立的。Random Forest其实就是在Bagging的基础上加一个条件。它也是按照Bagging的方法重复取样,但是抽取的数量和样本总量相等 (n)。但是在训练树的时候并不是把所有features都用上。假设我们总共有M个features。每次训练一棵树的时候,我们随机抽取其中的m(m << M)个features进行训练。随机森林中的树不需要进行剪枝操作。因为样本的抽取,特征的抽取已经保证了随机性,大大减少了overfitting的可能性。
KNeighborsClassifier
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法可以说是整个数据挖掘分类技术中最简单的方法了。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用她最接近的k个邻居来代表。
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
LogisticRegression
参考我的上一篇文章:点击进入 https://blog.csdn.net/qq_41664845/article/details/79956111
GaussianNB
贝叶斯模型就不做介绍了,这些都是机器学习入门算法,但是贝叶斯是我毕设设计,所以相对其他我觉得贝叶斯更好理解:参考可以阅读这篇:https://blog.csdn.net/anneqiqi/article/details/59666980
2.数据集展示:
数据集,这里在数据库读出保存成csv,好方便数据分析处理。

数据预处理后表格:
 |
3.源码展示:
直接贴源码了:(改进了之前的代码)
import os
import re
import pandas as pd
import numpy as np
import nltk
from nltk.text import TextCollection
from random import randint
from sklearn.feature_extraction.text import TfidfVectorizer
from LRModletools import proc_text,remove_whitespace,DataManipulation,split_train_test,clean_text,\
get_word_list_from_data,extract_tf_idf,tonumber,cal_acc
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from random import sample
from sklearn import tree
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.cross_validation import cross_val_score
from sklearn import metrics
dataset_path = './dataset'
# 原始数据的csv文件
output_text_filename = '51job.csv'
# 清洗好的文本数据文件
output_cln_text_filename = 'clean_text.csv'
# 处理和清洗文本数据的时间较长,通过设置is_first_run进行配置
# 如果是第一次运行需要对原始文本数据进行处理和清洗,需要设为True
# 如果之前已经处理了文本数据,并已经保存了清洗好的文本数据,设为False即可
is_first_run = False
if is_first_run:
text_df = pd.read_csv(os.path.join(dataset_path, output_text_filename),usecols = ['岗位分类','经验要求',\
'学历要求','招聘人数','职能类别','公司性质','公司行业','岗位需求'],encoding = 'gbk').dropna()
Data = DataManipulation(text_df)
#清洗招聘人数
Data['招聘人数'] = Data['招聘人数'].apply(lambda x:x.replace('人',''))
Data['招聘人数'] = Data['招聘人数'].apply(lambda x:x.replace('若干',str(randint(1,30)))).astype(int)
#清洗公司行业
Data['公司行业'] = Data['公司行业'].fillna('Unknown')
Data['公司行业'] = Data['公司行业'].map(lambda x:'计算机软件' if '计算机软件' in x else x)
Data['公司行业'] = Data['公司行业'].map(lambda x:'通信/电信/网络设备' if '通信' in x else x)
Data['公司行业'] = Data['公司行业'].map(lambda x:'教育/培训/院校' if '教育/培训/院校' in x else x)
Data['公司行业'] = Data['公司行业'].map(lambda x:'互联网/电子商务' if '互联网/电子商务' in x else x)
Data['公司行业'] = Data['公司行业'].map(lambda x:'多元化业务集团公司' if '多元化业务集团公司' in x else x)
Data['公司行业'] = Data['公司行业'].map(lambda x:'电子技术/半导体/集成电路' if '电子技术/半导体/集成电路' in x else x)
Data['公司行业'] = Data['公司行业'].map(lambda x:'金融/投资/证券' if '金融/投资/证券' in x else x)
Data['公司行业'] = Data['公司行业'].map(lambda x:'专业服务(咨询、人力资源、财会)' if '专业服务(咨询、人力资源、财会) ' in x else x)
Data['公司行业'] = Data['公司行业'].map(lambda x:'房地产' if '房地产' in x else x)
Data.loc[(Data['公司行业']!='计算机软件')&(Data['公司行业']!='通信/电信/网络设备')&(Data['公司行业']!='教育/培训/院校')\
&(Data['公司行业']!='互联网/电子商务')&(Data['公司行业']!='多元化业务集团公司')&(Data['公司行业']!='电子技术/半导体/集成电路')\
&(Data['公司行业']!='金融/投资/证券')&(Data['公司行业']!='专业服务(咨询、人力资源、财会)')\
&(Data['公司行业']!='房地产'), '公司行业'] = "其它"
#清洗岗位类别
Data.loc[(Data['职能类别']!='软件工程师')&(Data['职能类别']!='销售代表')&(Data['职能类别']!='数据库工程师/管理员')\
&(Data['职能类别']!='互联网软件开发工程师')&(Data['职能类别']!='算法工程师')&(Data['职能类别']!='大数据开发/分析')\
&(Data['职能类别']!='系统架构设计师')&(Data['职能类别']!='产品经理/主管')&(Data['职能类别']!='销售经理')\
&(Data['职能类别']!='大客户销售')&(Data['职能类别']!='技术支持/维护工程师')&(Data['职能类别']!='售前/售后技术支持工程师')\
&(Data['职能类别']!='高级软件工程师'), '职能类别'] = "其它"
# 处理文本数据
Data['岗位需求'] = Data['岗位需求'].apply(clean_text)
cln_text = Data['岗位需求'].apply(proc_text)
Data['岗位需求'] = cln_text
# 保存处理好的文本数据
Data.to_csv(os.path.join(dataset_path, output_cln_text_filename),\
index=None, encoding = 'gbk')
clean_data = pd.read_csv(os.path.join(dataset_path, output_cln_text_filename),\
encoding='gbk')
# 查看label的分布
print(clean_data.groupby('岗位分类').size())
# 替换'大数据' -> 0,'云计算' -> 1,'人工智能' -> 2,'物联网' -> 3
clean_data.loc[clean_data['岗位分类'] == '大数据', '岗位分类'] = 0
clean_data.loc[clean_data['岗位分类'] == '云计算', '岗位分类'] = 1
clean_data.loc[clean_data['岗位分类'] == '人工智能', '岗位分类'] = 2
clean_data.loc[clean_data['岗位分类'] == '物联网', '岗位分类'] = 3
clean_data['岗位分类'] = clean_data['岗位分类'].astype(int)
#打乱数据集
#clean_data = clean_data.sample(frac=1).reset_index(drop=True)
#分割数据集
df_train, df_test = split_train_test(clean_data)
# 获取训练集标签
tr_labels = df_train['岗位分类'].values
# 获取训练集标签
te_labels = df_test['岗位分类'].values
# 查看训练集测试集基本信息
print('训练集中各类的数据个数:', df_train.groupby('岗位分类').size())
print('测试集中各类的数据个数:', df_test.groupby('岗位分类').size())
# 特征工程
# 训练数据特征提取
# 文本数据
# 训练岗位需求数据
print('统计训练数据岗位需求词频...')
n_desc_common_words = 3000
desc_words_in_train = get_word_list_from_data(df_train['岗位需求'])
fdisk = nltk.FreqDist(desc_words_in_train)
desc_common_words_freqs = fdisk.most_common(n_desc_common_words)
# 提取岗位需求文本的TF-IDF特征
desc_collection = TextCollection(df_train['岗位需求'].values.tolist())
tr_desc_feat = extract_tf_idf(df_train['岗位需求'], desc_collection, desc_common_words_freqs)
print('完成')
print()
##预处理经验要求 学历要求 职能类别 公司性质 公司行业训练数据
df_train = df_train.drop('岗位需求',axis =1)
df_train = df_train.drop('岗位分类',axis =1)
train_categorical_variables = df_train.select_dtypes(include=['object']).copy()
train_numeric_variables = df_train.select_dtypes(include=['float64']).copy()
#枚举
for column in train_categorical_variables:
train_categorical_variables[column] = train_categorical_variables[column].astype('category')
dictionary = dict(enumerate(train_categorical_variables[column].cat.categories) )
train_categorical_variables[column] = train_categorical_variables[column].cat.codes
Final_train_set = pd.merge(train_categorical_variables,train_numeric_variables,left_index = True,right_index = True)
tr_feat = np.hstack((tr_desc_feat,Final_train_set))
# 特征范围归一化
scaler = StandardScaler()
tr_feat_scaled = scaler.fit_transform(tr_feat)
# 测试数据特征提取
# 文本特征
te_desc_feat = extract_tf_idf(df_test['岗位需求'], desc_collection, desc_common_words_freqs)
print('完成')
print()
# 预处理经验要求 学历要求 职能类别 公司性质 公司行业测试数据
df_test = df_test.drop('岗位需求',axis =1)
df_test = df_test.drop('岗位分类',axis =1)
test_categorical_variables = df_test.select_dtypes(include=['object']).copy()
test_numeric_variables = df_test.select_dtypes(include=['float64']).copy()
for column in test_categorical_variables:
test_categorical_variables[column] = test_categorical_variables[column].astype('category')
dictionary = dict(enumerate(test_categorical_variables[column].cat.categories) )
test_categorical_variables[column] = test_categorical_variables[column].cat.codes
Final_test_set = pd.merge(test_categorical_variables,test_numeric_variables,left_index = True,right_index = True)
te_feat = np.hstack((te_desc_feat,Final_test_set))
# 特征范围归一化
te_feat_scaled = scaler.transform(te_feat)
# # 4.3 PCA降维操作 ----->(效果不好,3000维度,维度不高不需要降维)
# pca = PCA(n_components=0.95) # 保留95%累计贡献率的特征向量
# tr_feat_scaled_pca = pca.fit_transform(tr_feat_scaled)
# te_feat_scaled_pca = pca.transform(te_feat_scaled)
# 5. 模型建立训练,对比PCA操作前后的效果
# 使用未进行PCA操作的特征
lr_model = LogisticRegression()
lr_model.fit(tr_feat_scaled, tr_labels)
# # 使用PCA操作后的特征
# lr_pca_model = LogisticRegression()
# lr_pca_model.fit(tr_feat_scaled_pca, tr_labels)
# 6. 模型测试
pred_labels = lr_model.predict(te_feat_scaled)
#pred_pca_labels = lr_pca_model.predict(te_feat_scaled_pca)
#准确率
print('未进行PCA操作:')
print('样本维度:', tr_feat_scaled.shape[1])
print('准确率:{}'.format(cal_acc(te_labels, pred_labels)))
# print()
# print('进行PCA操作后:')
# print('样本维度:', tr_feat_scaled_pca.shape[1])
# print('准确率:{}'.format(cal_acc(te_labels, pred_pca_labels)))
tree_model = tree.DecisionTreeClassifier(max_depth=4)
# Fit a decision tree
tree_model = tree_model.fit(tr_feat_scaled, tr_labels)
# Training accuracy
tree_model.score(tr_feat_scaled, tr_labels)
predicted = pd.DataFrame(tree_model.predict(te_feat_scaled))
probs = pd.DataFrame(tree_model.predict_proba(te_feat_scaled))
tree_accuracy = metrics.accuracy_score(te_labels, predicted)
#tree_roc_auc = metrics.roc_auc_score(te_labels, probs[1])
tree_confus_matrix = metrics.confusion_matrix(te_labels, predicted)
tree_classification_report = metrics.classification_report(te_labels, predicted)
tree_precision = metrics.precision_score(te_labels, predicted, pos_label=1)
tree_recall = metrics.recall_score(te_labels, predicted, pos_label=1)
tree_f1 = metrics.f1_score(te_labels, predicted, pos_label=1)
#RANDOM FOREST
# Instantiate
rf = RandomForestClassifier()
# Fit
rf_model = rf.fit(tr_feat_scaled, tr_labels)
# training accuracy 99.74%
rf_model.score(tr_feat_scaled, tr_labels)
# Predictions/probs on the test dataset
predicted = pd.DataFrame(rf_model.predict(te_feat_scaled))
probs = pd.DataFrame(rf_model.predict_proba(te_feat_scaled))
# Store metrics
rf_accuracy = metrics.accuracy_score(te_labels, predicted)
#rf_roc_auc = metrics.roc_auc_score(te_labels, probs[1])
rf_confus_matrix = metrics.confusion_matrix(te_labels, predicted)
rf_classification_report = metrics.classification_report(te_labels, predicted)
rf_precision = metrics.precision_score(te_labels, predicted, pos_label=1)
rf_recall = metrics.recall_score(te_labels, predicted, pos_label=1)
rf_f1 = metrics.f1_score(te_labels, predicted, pos_label=1)
# Evaluate the model using 10-fold cross-validation
rf_cv_scores = cross_val_score(RandomForestClassifier(), te_feat_scaled, te_labels, scoring='precision', cv=10)
rf_cv_mean = np.mean(rf_cv_scores)
#KNN
# instantiate learning model (k = 3)
knn_model = KNeighborsClassifier(n_neighbors=3)
# fit the model
knn_model.fit(tr_feat_scaled, tr_labels)
# Accuracy
knn_model.score(tr_feat_scaled, tr_labels)
# Predictions/probs on the test dataset
predicted = pd.DataFrame(knn_model.predict(te_feat_scaled))
probs = pd.DataFrame(knn_model.predict_proba(te_feat_scaled))
# Store metrics
knn_accuracy = metrics.accuracy_score(te_labels, predicted)
#knn_roc_auc = metrics.roc_auc_score(te_labels, probs[1])
knn_confus_matrix = metrics.confusion_matrix(te_labels, predicted)
knn_classification_report = metrics.classification_report(te_labels, predicted)
knn_precision = metrics.precision_score(te_labels, predicted, pos_label=1)
knn_recall = metrics.recall_score(te_labels, predicted, pos_label=1)
knn_f1 = metrics.f1_score(te_labels, predicted, pos_label=1)
# Evaluate the model using 10-fold cross-validation
knn_cv_scores = cross_val_score(KNeighborsClassifier(n_neighbors=3), te_feat_scaled, te_labels, scoring='precision', cv=10)
knn_cv_mean = np.mean(knn_cv_scores)
#Bayes
bayes_model = GaussianNB()
# Fit the model
bayes_model.fit(tr_feat_scaled, tr_labels)
# Accuracy
bayes_model.score(tr_feat_scaled, tr_labels)
# Predictions/probs on the test dataset
predicted = pd.DataFrame(bayes_model.predict(te_feat_scaled))
probs = pd.DataFrame(bayes_model.predict_proba(te_feat_scaled))
# Store metrics
bayes_accuracy = metrics.accuracy_score(te_labels, predicted)
#bayes_roc_auc = metrics.roc_auc_score(te_labels, probs[1])
bayes_confus_matrix = metrics.confusion_matrix(te_labels, predicted)
bayes_classification_report = metrics.classification_report(te_labels, predicted)
bayes_precision = metrics.precision_score(te_labels, predicted, pos_label=1)
bayes_recall = metrics.recall_score(te_labels, predicted, pos_label=1)
bayes_f1 = metrics.f1_score(te_labels, predicted, pos_label=1)
# Evaluate the model using 10-fold cross-validation
bayes_cv_scores = cross_val_score(KNeighborsClassifier(n_neighbors=3), te_feat_scaled, te_labels, scoring='precision', cv=10)
bayes_cv_mean = np.mean(bayes_cv_scores)
models = pd.DataFrame({
'Model': ['d.Tree', 'r.f.', 'kNN', 'Bayes'],
'Accuracy' : [ tree_accuracy, rf_accuracy, knn_accuracy, bayes_accuracy],
'Precision': [ tree_precision, rf_precision, knn_precision, bayes_precision],
'recall' : [ tree_recall, rf_recall, knn_recall, bayes_recall],
'F1' : [tree_f1, rf_f1, knn_f1, bayes_f1],
})
models.to_csv('训练模型对比.csv')LRModltools.py:模块
import jieba.posseg as pseg
import pandas as pd
import numpy as np
import re,os
import math
# 加载常用停用词
stopwords = [line.rstrip() for line in open('./StopWord.txt', 'r', encoding='utf-8')]
def clean_text(text):
"""
清洗文本数据
"""
# just in case
text = text.lower()
# 去除特殊字符
text = re.sub('\s\W', ' ', text)
text = re.sub('\W\s', ' ', text)
text = re.sub('\s+', ' ', text)
return text
def proc_text(raw_line):
"""
处理每行的文本数据
返回分词结果
"""
# 2. 结巴分词+词性标注
words_lst = pseg.cut(raw_line)
# 3. 去除停用词
meaninful_words = []
for word, flag in words_lst:
# if (word not in stopwords) and (flag == 'v'):
# 也可根据词性去除非动词等
if word not in stopwords:
meaninful_words.append(word)
return ' '.join(meaninful_words)
def remove_whitespace(x):
"""
Helper function to remove any blank space from a string
x: a string
"""
try:
# Remove spaces inside of the string
x = "".join(x.split(' '))
except:
pass
return x
def DataManipulation(x):
x = x.ix[:,~((x==1).all()|(x==0).all())]
for i in x.columns:
x[i][x[i].apply(lambda i: True if re.search('^\s*$', str(i)) else False)]=None #将空白格用None替换
title_store = x.columns
con_percentage = 0.7
if con_percentage> 1 or con_percentage<0:
raise ValueError('输入值因在0 和 1 之间')
I = (((float)(x.shape[0]) - x.count().values) / (float)(x.shape[0]))
suggest = I > con_percentage
missing_counts = (x.shape[0]) - x.count().values
suggest = pd.Series(suggest)
missing_counts = pd.Series(missing_counts)
I = pd.Series(I)
Data_Frame = pd.DataFrame({'Suggest': suggest, 'Missingness': missing_counts, 'Missingpercentage': I})
Data_Frame.index = title_store
# 获取要移除行的名称
var_remove = pd.Series((Data_Frame.query('Suggest == True')).index).values
newList = []
for item in var_remove:
if type(item) == list:
tmp = ''
for i in item:
newList.append(i)
else:
newList.append(item)
# 移除丢失数据占比高的行
filter_result = x.drop(newList, axis=1)
print(("输出结果为丢失数据统计表和移除丢失占比高于%s后的数据集") % (str(con_percentage * 100) + '%'))
return filter_result
def split_train_test(df_data, size=0.8):
"""
分割训练集和测试集
"""
# 为保证每个类中的数据能在训练集中和测试集中的比例相同,所以需要依次对每个类进行处理
df_train = pd.DataFrame()
df_test = pd.DataFrame()
labels = [0, 1 , 2 , 3]
for label in labels:
# 找出gender的记录
text_df_w_label = df_data[df_data['岗位分类'] == label]
# 重新设置索引,保证每个类的记录是从0开始索引,方便之后的拆分
text_df_w_label = text_df_w_label.reset_index()
# 默认按80%训练集,20%测试集分割
# 这里为了简化操作,取前80%放到训练集中,后20%放到测试集中
# 当然也可以随机拆分80%,20%(尝试实现下DataFrame中的随机拆分)
# 该类数据的行数
n_lines = text_df_w_label.shape[0]
split_line_no = math.floor(n_lines * size)
text_df_w_label_train = text_df_w_label.iloc[:split_line_no, :]
text_df_w_label_test = text_df_w_label.iloc[split_line_no:, :]
# 放入整体训练集,测试集中
df_train = df_train.append(text_df_w_label_train)
df_test = df_test.append(text_df_w_label_test)
df_train = df_train.reset_index()
df_test = df_test.reset_index()
return df_train, df_test
def get_word_list_from_data(text_s):
"""
将数据集中的单词放入到一个列表中
"""
word_list = []
for _, text in text_s.iteritems():
word_list += text.split(' ')
return word_list
def extract_tf_idf(text_s, text_collection, common_words_freqs):
"""
提取tf-idf特征
"""
# 这里只选择TF-IDF特征作为例子
# 可考虑使用词频或其他文本特征作为额外的特征
n_sample = text_s.shape[0]
n_feat = len(common_words_freqs)
common_words = [word for word, _ in common_words_freqs]
# 初始化
X = np.zeros([n_sample, n_feat])
print('提取tf-idf特征...')
for i, text in text_s.iteritems():
feat_vec = []
for word in common_words:
if word in text:
# 如果在高频词中,计算TF-IDF值
tf_idf_val = text_collection.tf_idf(word, text)
else:
tf_idf_val = 0
feat_vec.append(tf_idf_val)
# 赋值
X[i, :] = np.array(feat_vec)
return X
def tonumber(categorical_variables):
dicts = []
for column in categorical_variables:
categorical_variables[column] = categorical_variables[column].astype('category')
dictionary = dict(enumerate(categorical_variables[column].cat.categories) )
dicts.append(dictionary)
categorical_variables[column] = categorical_variables[column].cat.codes
return dicts
def cal_acc(true_labels, pred_labels):
"""
计算准确率
"""
n_total = len(true_labels)
correct_list = [true_labels[i] == pred_labels[i] for i in range(n_total)]
acc = sum(correct_list) / n_total
return acc