Python源码剖析(03 Python中的字符串对象)
考虑整数对象PyIntObject,其维护的数据的长度在对象定义时就已经确定了,它是一个C中long变量的长度;而可变对象维护的数据的长度只能在对象创建时才能确定,举个例子来说,我们只能在创建一个字符串或一个列表时知道它们所维护的数据的长度。
在变长对象中,实际上也还可分为可变对象和不可变对象。可变对象维护的数据在对象被创建后还能再变化,比如一个list被创建后,可以向其中添加元素或删除元素,这些操作都会改变其维护的数据;而不可变对象所维护的数据在对象创建之后就不能再改变了,比如Python中的string和tuple,它们都不支持添加或删除的操作。本章我们将研究Python变长对象中的不可变对象——字符串对象。
3.1 PyStringObject与PyString_Type
PyStringObject是一个拥有可变长度内存的对象。同时,PyStringObject对象又是一个不变对象。当创建了一个PyStringObject对象之后,该对象内部维护的字符串就不能再被改变了。这一点特性使得PyStringObject对象可作为dict的键值,但同时也使得一些字符串操作的效率大大降低,比如多个字符串的连接操作。
[stringobject.h]
typedef struct {
PyObject_VAR_HEAD
long ob_shash;
int ob_sstate;
char ob_sval[1];
} PyStringObject;在PyStringObject的定义中我们看到,在PyStringObject的头部实际上是一个PyObject_VAR_HEAD,其中有一个ob_size变量保存着对象中维护的可变长度内存的大小。虽然在PyStringObject的定义中,ob_sval是一个字符的字符数组。但是ob_sval实际上是作为一个字符指针指向一段内存的,这段内存保存着这个字符串对象所维护的实际字符串,显然,这段内存不会只是一个字节。而这段内存的实际长度(字节),正是由ob_size来维护的,这个机制是Python中所有变长对象的实现机制。比如对于PyStringObject对象“Python”,ob_size的值为6。
同C中的字符串一样,PyStringObject内部维护的字符串在末尾必须以’\0’结尾,但是由于字符串的实际长度是由ob_size维护的,所以PyStringObject表示的字符串对象中间是可能出现字符’\0’的。
所以,实际上,ob_sval指向的是一段长度为ob_size+1个字节的内存,而且必须满足ob_sval[ob_size] == ‘\0’。
PyStringObject中的ob_shash变量之作用是缓存该对象的hash值,这样可以避免每一次都重新计算该字符串对象的hash值。如果一个PyStringObject对象还没有被计算过hash值,那么ob_shash的初始值是―1。
在计算一个字符串对象的hash值时,采用如下的算法:
[stringobject.c]
static long string_hash(PyStringObject *a)
{
register int len;
register unsigned char *p;
register long x;
if (a->ob_shash != -1)
return a->ob_shash;
len = a->ob_size;
p = (unsigned char *) a->ob_sval;
x = *p << 7;
while (--len >= 0)
x = (1000003*x) ^ *p++;
x ^= a->ob_size;
if (x == -1)
x = -2;
a->ob_shash = x;
return x;
}PyStringObject对象的ob_sstate变量标记了该对象是否已经过intern机制的处理,关于PyStringObject的intern机制,在后面会详细介绍。在Python源码中的注释显示,预存字符串的hash值和这里的intern机制将Python虚拟机的执行效率提升了20%。
下面列出了PyStringObject对应的类型对象——PyString_Type:
[stringobject.c]
PyTypeObject PyString_Type = {
PyObject_HEAD_INIT(&PyType_Type)
0,
"str",
sizeof(PyStringObject),
sizeof(char),
……
(reprfunc)string_repr, /* tp_repr */
&string_as_number, /* tp_as_number */
&string_as_sequence, /* tp_as_sequence */
&string_as_mapping, /* tp_as_mapping */
(hashfunc)string_hash, /* tp_hash */
0, /* tp_call */
……
string_new, /* tp_new */
PyObject_Del, /* tp_free */
};对于Python中的任何一种变长对象,tp_itemsize这个域是必须设置的,tp_itemsize指明了由变长对象保存的元素(item)的单位长度,所谓单位长度即是指一个元素在内存中的长度。这个tp_itemsize和ob_size共同决定了应该额外申请的内存之总大小是多少。
需要注意的是,我们看到,tp_as_number、tp_as_sequence、tp_as_mapping,三个域都被设置了。这表示PyStringObject对数值操作、序列操作和映射操作都支持。
3.2 创建PyStringObject对象
Python提供了两条路径,从C中原生的字符串创建PyStringObject对象。我们先考察一下最一般的PyString_FromString(见代码清单3-1)。
代码清单3_1
[stringobject.c]
PyObject* PyString_FromString(const char *str)
{
register size_t size;
register PyStringObject *op;
//[1]: 判断字符串长度
size = strlen(str);
if (size > PY_SSIZE_T_MAX) {
return NULL;
}
//[2]: 处理null string
if (size == 0 && (op = nullstring) != NULL) {
return (PyObject *)op;
}
//[3]: 处理字符
if (size == 1 && (op = characters[*str & UCHAR_MAX]) != NULL) {
return (PyObject *)op;
}
/* [4]: 创建新的PyStringObject对象,并初始化 */
/* Inline PyObject_NewVar */
op = (PyStringObject *)PyObject_MALLOC(sizeof(PyStringObject) + size);
PyObject_INIT_VAR(op, &PyString_Type, size);
op->ob_shash = -1;
op->ob_sstate = SSTATE_NOT_INTERNED;
memcpy(op->ob_sval, str, size+1);
……
return (PyObject *) op;
}传给PyString_FromString的参数必须是一个指向以NUL(‘\0’)结尾的字符串的指针。在从一个原生字符串创建PyStringObject时,首先在代码清单3-1的1处检查该字符数组的长度,如果字符数组的长度大于了PY_SSIZE_T_MAX,那么Python将不会创建对应的PyStringObject对象。
接下来,在代码清单3-1的2处,检查传入的字符串是不是一个空串。对于空串,Python并不是每一次都会创建相应的PyStringObject。Python运行时有一个PyStringObject对象指针nullstring专门负责处理空的字符数组。如果第一次在一个空字符串基础上创建PyStringObject,由于nullstring指针被初始化为NULL,所以Python会为这个空字符建立一个PyStringObject对象,将这个PyStringObject对象通过intern机制进行共享,然后将nullstring指向这个被共享的对象。如果在以后Python检查到需要为一个空字符串创建PyStringObject对象,这时nullstring已经存在了,那么就直接返回nullstring的引用。
如果不是创建空字符串对象,那么接下来需要进行的动作就是申请内存,创建PyStringObject对象。可以看到,代码清单3-1的4处申请的内存除了PyStringObject的内存,还有为字符数组内的元素申请的额外内存。然后,将hash缓存值设为―1,将intern标志设为SSTATE_NOT_INTERNED。最后将参数str指向的字符数组内的字符拷贝到PyStringObject所维护的空间中,在拷贝的过程中,将字符数组最后的’\0’字符也拷贝了。加入我们对于字符数组“Python”建立PyStringObject对象,那么对象建立完成后在内存中的状态如图3-1所示:

在PyString_FromString之外,还有一条创建PyStringObject对象的途径——PyString_FromStringAndSize:
[stringobject.c]
PyObject* PyString_FromStringAndSize(const char *str, int size)
{
register PyStringObject *op;
//处理null string
if(size == 0 && (op = nullstring) != NULL) {
return (PyObject *)op;
}
//处理字符
if(size == 1 && str != NULL && (op = characters[*str & UCHAR_MAX]) !=
NULL)
{
return (PyObject *)op;
}
//创建新的PyStringObject对象,并初始化
//Inline PyObject_NewVar
op = (PyStringObject *)PyObject_MALLOC(sizeof(PyStringObject) + size);
PyObject_INIT_VAR(op, &PyString_Type, size);
op->ob_shash = -1;
op->ob_sstate = SSTATE_NOT_INTERNED;
if (str != NULL)
memcpy(op->ob_sval, str, size);
op->ob_sval[size] = '\0';
……
return (PyObject *) op;
}PyString_FromStringAndSize的操作过程和PyString_FromString一般无二,只是有一点,PyString_FromString传入的参数必须是以NUL(‘\0’)结尾的字符数组的指针,而PyString_FromStringAndSize不会有这样的要求,因为通过传入的size参数就可以确定需要拷贝的字符的个数。
3.3 字符串对象的intern机制
无论是PyString_FromString还是PyString_FromStringAndSize,我们都注意到,当字符数组的长度为0或1时,需要进行一个特别的动作:PyString_InternInPlace。这就是前面所提到的intern机制。
[stringobject.c]
PyObject* PyString_FromString(const char *str)
{
register size_t size;
register PyStringObject *op;
……//创建PyStringObject对象
// intern(共享)长度较短的PyStringObject对象
if (size == 0) {
PyObject *t = (PyObject *)op;
PyString_InternInPlace(&t);
op = (PyStringObject *)t;
nullstring = op;
} else if (size == 1) {
PyObject *t = (PyObject *)op;
PyString_InternInPlace(&t);
op = (PyStringObject *)t;
characters[*str & UCHAR_MAX] = op;
}
return (PyObject *) op;
}PyStringObject对象的intern机制之目的是:对于被intern之后的字符串,比如“Ruby”,在整个Python的运行期间,系统中都只有唯一的一个与字符串“Ruby”对应的PyStringObject对象。
a = "Python"
b = "Python"
print a, bPyString_InternInPlace正是负责完成对一个对象进行intern操作的函数(见代码清单3-2)。
代码清单3_2
[stringobjec.c]
void PyString_InternInPlace(PyObject **p)
{
register PyStringObject *s = (PyStringObject *)(*p);
PyObject *t;
//对PyStringObject进行类型和状态检查
if (!PyString_CheckExact(s))
return;
if (PyString_CHECK_INTERNED(s))
return;
//创建记录经intern机制处理后的PyStringObject的dict
if (interned == NULL) {
interned = PyDict_New();
}
//[1] : 检查PyStringObject对象s是否存在对应的intern后的PyStringObject对象
t = PyDict_GetItem(interned, (PyObject *)s);
if (t) {
//注意这里对引用计数的调整
Py_INCREF(t);
Py_DECREF(*p);
*p = t;
return;
}
//[2] : 在interned中记录检查PyStringObject对象s
PyDict_SetItem(interned, (PyObject *)s, (PyObject *)s);
//[3] : 注意这里对引用计数的调整
s->ob_refcnt -= 2;
//[4] : 调整s中的intern状态标志
PyString_CHECK_INTERNED(s) = SSTATE_INTERNED_MORTAL;
}PyString_InternInPlace首先会进行一系列的检查,其中包括两项检查内容:
- 检查传入的对象是否是一个PyStringObject对象,intern机制只能应用在PyString- Object对象上,甚至对于它的派生类对象系统都不会应用intern机制。
- 检查传入的PyStringObject对象是否已经被intern机制处理过了,Python不会对同一个PyStringObject对象进行一次以上的Intern操作。
interned在stringobject.c中被定义为:static PyObject *interned。
interned实际上指向的是PyDict_New创建的一个对象。而PyDict_New实际上创建了一个PyDictObject对象。现在,对于一个PyDictObject对象,我们完全可以看作是C++中的map,即map。
所谓的intern机制的关键,就是在系统中有一个(key,value)映射关系的集合,集合的名称叫做interned。在这个集合中,记录着被intern机制处理过的PyStringObject对象。当对一个PyStringObject对象a应用intern机制时,首先会在interned这个dict中检查是否有满足以下条件的对象b:b中维护的原生字符串与a相同。如果确实存在对象b,那么指向a的PyObject指针将会指向b,而a的引用计数减1,这样,其实a只是一个被临时创建的对象。如果interned中还不存在这样的b,那么就在代码清单3-2的2处将a记录到interned中。
图3-2展示了如果interned中存在这样的对象b,在对a进行intern操作时,原本指向a的PyObject*指针的变化:
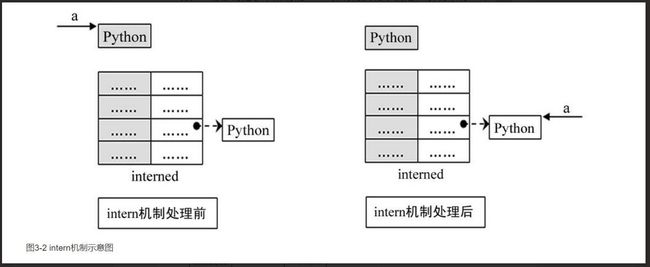
对于被intern机制处理了的PyStringObject对象,Python采用了特殊的引用计数机制。在将一个PyStringObject对象a的PyObject指针作为key和value添加到interned中时,PyDictObject对象会通过这两个指针对a的引用计数进行两次加1的操作。但是Python的设计者规定在interned中a的指针不能被视为对象a的有效引用,因为如果是有效引用的话,那么a的引用计数在Python结束之前永远都不可能为0,因为interned中至少有两个指针引用了a,那么删除a就永远不可能了,这显然是没有道理的。因此,interned中的指针不能作为a的有效引用。这也就是在代码清单3-2的3处会将引用计数减2的原因。在销毁a的同时,会在interned中删除指向a的指针,显然,这一点在下面列出的string_dealloc代码中得到了验证:
[stringobject.c]
static void string_dealloc(PyObject *op)
{
switch (PyString_CHECK_INTERNED(op)) {
case SSTATE_NOT_INTERNED:
break;
case SSTATE_INTERNED_MORTAL:
/* revive dead object temporarily for DelItem */
op->ob_refcnt = 3;
if (PyDict_DelItem(interned, op) != 0)
Py_FatalError(
"deletion of interned string failed");
break;
case SSTATE_INTERNED_IMMORTAL:
Py_FatalError("Immortal interned string died.");
default:
Py_FatalError("Inconsistent interned string state.");
}
op->ob_type->tp_free(op);
}事实上,从PyString_FromString中可以看到,无论如何,一个合法的PyStringObject对象是会被创建的,同样,我们可以注意到,PyString_ InternInPlace也只对PyStringObject起作用。事实正是如此,Python始终会为字符串s创建PyStringObject对象,尽管s中维护的原生字符数组在interned中已经有一个与之对应的PyStringObject对象了。而intern机制是在s被创建后才起作用的,通常Python在运行时创建了一个PyStringObject对象temp后,基本上都会调用PyString_ InternInPlace对temp进行处理,intern机制会减少temp的引用计数,temp对象会由于引用计数减为0 而被销毁,它只是作为一个临时对象昙花一现地在内存中闪现,然后湮灭。
现在读者可能有一个疑问了,是否可以直接在C的原生字符串上做intern的动作,而不需要再创建这样一个临时对象呢?事实上,Python确实提供了一个以char*为参数的intern机制相关函数,但是你会相当失望,嗯,因为它基本上是换汤不换药的:
[stringobject.c]
PyObject* PyString_InternFromString(const char *cp)
{
PyObject *s = PyString_FromString(cp);
PyString_InternInPlace(&s);
return s;
}临时对象照样被创建出来,实际上,仔细一想,就会发现在Python中,必须创建这样一个临时的PyStringObject对象来完成intern操作。为什么呢?答案就在PyDictObject对象interned中,因为PyDictObject必须以PyObject*指针作为键。
实际上,被intern机制处理后的PyStringObject对象分为两类,一类处于SSTATE_INTERNED_IMMORTAL状态,而另一类则处于SSTATE_INTERNED_MORTAL状态,这两种状态的区别在string_dealloc中可以清晰地看到,显然,SSTATE_INTERNED_IMMORTAL状态的PyStringObject对象是永远不会被销毁的,它将与Python虚拟机同年同月同日死。
PyString_InternInPlace只能创建SSTATE_INTERNED_MORTAL状态的PyString- Object对象,如果想创建SSTATE_INTERNED_IMMORTAL状态的对象,必须要通过另外的接口,在调用了PyString_InternInPlace后,强制改变PyStringObject的intern状态。
[stringobject.c]
void PyString_InternImmortal(PyObject **p)
{
PyString_InternInPlace(p);
if (PyString_CHECK_INTERNED(*p) != SSTATE_INTERNED_IMMORTAL) {
PyString_CHECK_INTERNED(*p) = SSTATE_INTERNED_IMMORTAL;
Py_INCREF(*p);
}
}3.4 字符缓冲池
Python的设计者为PyStringObject中的一个字节的字符对应的PyStringObject对象也设计了这样一个对象池characters:
static PyStringObject *characters[UCHAR_MAX + 1];
其中的UCHAR_MAX是在系统头文件中定义的常量,这也是一个平台相关的常量,在Win32平台下:
#define UCHAR_MAX 0xff /* maximum unsigned char value */
在Python的整数对象体系中,小整数的缓冲池是在Python初始化时被创建的,而字符串对象体系中的字符缓冲池则是以静态变量的形式存在着的。在Python初始化完成之后,缓冲池中的所有PyStringObject指针都为空。
当我们在创建一个PyStringObject对象时,无论是通过调用PyString_FromString还是通过调用PyString_FromStringAndSize,如果字符串实际上是一个字符,则会进行如下的操作:
[stringobject.c]
PyObject* PyString_FromStringAndSize(const char *str, int size)
{
……
else if (size == 1 && str != NULL)
{
PyObject *t = (PyObject *)op;
PyString_InternInPlace(&t);
op = (PyStringObject *)t;
characters[*str & UCHAR_MAX] = op;
Py_INCREF(op);
}
return (PyObject *) op;
}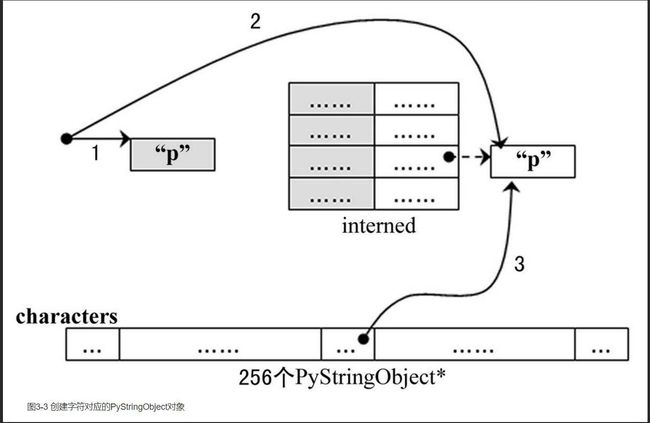
3条带有标号的曲线既代表指针,又代表进行操作的顺序:
(1) 创建PyStringObject对象;
(2) 对对象进行intern操作;
(3) 将对象缓存至字符缓冲池中。
在创建PyStringObject时,会首先检查所要创建的是否是一个字符对象,然后检查字符缓冲池中是否已经有了这个字符的字符对象的缓冲,如果有,则直接返回这个缓冲的对象即可:
[stringobject.c]
PyObject* PyString_FromStringAndSize(const char *str, int size)
{
register PyStringObject *op;
……
if(size == 1 && str != NULL && (op = characters[*str & UCHAR_MAX]) != NULL)
{
return (PyObject *)op;
}
……
}3.5 PyStringObject效率相关问题
在Python中举足轻重的问题——字符串连接。Python中通过“+”进行字符串连接的方法效率极其低下,其根源在于Python中的PyStringObject对象是一个不可变对象。这就意味着当进行字符串连接时,实际上是必须要创建一个新的PyStringObject对象。这样,如果要连接N个PyStringObject对象,那么就必须进行N-1次的内存申请及内存搬运的工作。毫无疑问,这将严重影响Python的执行效率。官方推荐的做法是通过利用PyStringObject对象的join操作来对存储在list或tuple中的一组PyStringObject对象进行连接操作,这种做法只需要分配一次内存,执行效率将大大提高。
通过“+”操作符对字符串进行连接时,会调用string_concat函数:
[stringobject.c]
static PyObject* string_concat(register PyStringObject *a, register
PyObject *bb)
{
register unsigned int size;
register PyStringObject *op;
#define b ((PyStringObject *)bb)
……
//计算字符串连接后的长度size
size = a->ob_size + b->ob_size;
/* Inline PyObject_NewVar */
//创建新的PyStringObject对象,其维护的用于存储字符的内存长度为size
op = (PyStringObject *)PyObject_MALLOC(sizeof(PyStringObject) + size);
PyObject_INIT_VAR(op, &PyString_Type, size);
op->ob_shash = -1;
op->ob_sstate = SSTATE_NOT_INTERNED;
//将a和b中的字符拷贝到新创建的PyStringObject中
memcpy(op->ob_sval, a->ob_sval, (int) a->ob_size);
memcpy(op->ob_sval + a->ob_size, b->ob_sval, (int) b->ob_size);
op->ob_sval[size] = '\0';
return (PyObject *) op;
#undef b
}对于任意两个PyStringObject对象的连接,就会进行一次内存申请的动作。而如果利用PyStringObject对象的join操作,则会进行如下的动作(假设是对list中的PyStringObject对象进行连接):
[stringobject.c]
static PyObject* string_join(PyStringObject *self, PyObject *orig)
{
char *sep = PyString_AS_STRING(self);
//假设调用”abc”.join(list),那么self就是“abc”对应的PyStringObject对象
//所以seplen中存储这“abc”的长度
const int seplen = PyString_GET_SIZE(self);
PyObject *res = NULL;
char *p;
int seqlen = 0;
size_t sz = 0;
int i;
PyObject *seq, *item;
……//获得list中PyStringObject对象的个数,保存在seqlen中
//遍历list中每一个字符串,累加获得连接list中所有字符串后的长度
for (i = 0; i < seqlen; i++)
{
//seq为Python中的list对象,这里获得其中第i个字符串
item = PySequence_Fast_GET_ITEM(seq, i);
sz += PyString_GET_SIZE(item);
if (i != 0)
sz += seplen;
}
//创建长度为sz的PyStringObject对象
res = PyString_FromStringAndSize((char*)NULL, (int)sz);
//将list中的字符串拷贝到新创建的PyStringObject对象中
p = PyString_AS_STRING(res);
for (i = 0; i < seqlen; ++i)
{
size_t n;
item = PySequence_Fast_GET_ITEM(seq, i);
n = PyString_GET_SIZE(item);
memcpy(p, PyString_AS_STRING(item), n);
p += n;
if (i < seqlen - 1)
{
memcpy(p, sep, seplen);
p += seplen;
}
}
return res;
}通过在string_concat和string_join中添加输出代码,我们可以在图3-4中形象地看到两种连接字符串的方法的区别:

3.6 Hack PyStringObject
首先,观察intern机制,在Python Interactive环境中,创建一个PyStringObject后,就会对这个PyStringObject对象进行intern操作,所以我们预期内容相同的PyString_Object对象在intern后应该是同一个对象,图3-5是观察的结果:
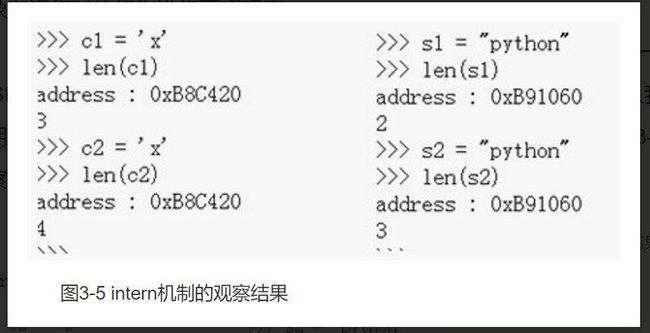
在address下一行输出的不是字符串的长度信息,我们已经将之更换为引用计数信息。从观察结果中可以看到,无论是对于一般的字符串,还是对于单个字符,intern机制最终都会使不同的PyStringObject*指针指向相同的对象。
我们观察Python中进行缓冲处理的字符对象,同样是通过在string_length中添加代码,打印出缓冲池中从a到e的字符对象的引用计数信息。需要注意的是,为了避免执行len(…)对引用计数的影响,我们并不会对a到e的字符对象调用len操作,而是对另外的PyStringObject对象调用len操作:
static void ShowCharacter()
{
char chA = 'a';
PyStringObject** posA = characters+(unsigned short)chA;
int i;
char values[5];
int refcnts[5];
for(i = 0; i < 5; ++i)
{
PyStringObject* strObj = posA[i];
values[i] = strObj->ob_sval[0];
refcnts[i] = strObj->ob_refcnt;
}
printf(" value : ");
for(i = 0; i < 5; ++i)
{
printf("%c\t", values[i]);
}
printf("\nrefcnt : ");
for(i = 0; i < 5; ++i)
{
printf("%d\t", refcnts[i]);
}
printf("\n");
}
在创建字符对象时,Python确实只是使用了缓冲池里的对象,而没有创建新的对象。