目标检测面试指南之YOLOv4
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达
本文作者:高毅鹏
https://zhuanlan.zhihu.com/p/138824273
本文已由作者授权,不得擅自二次转载
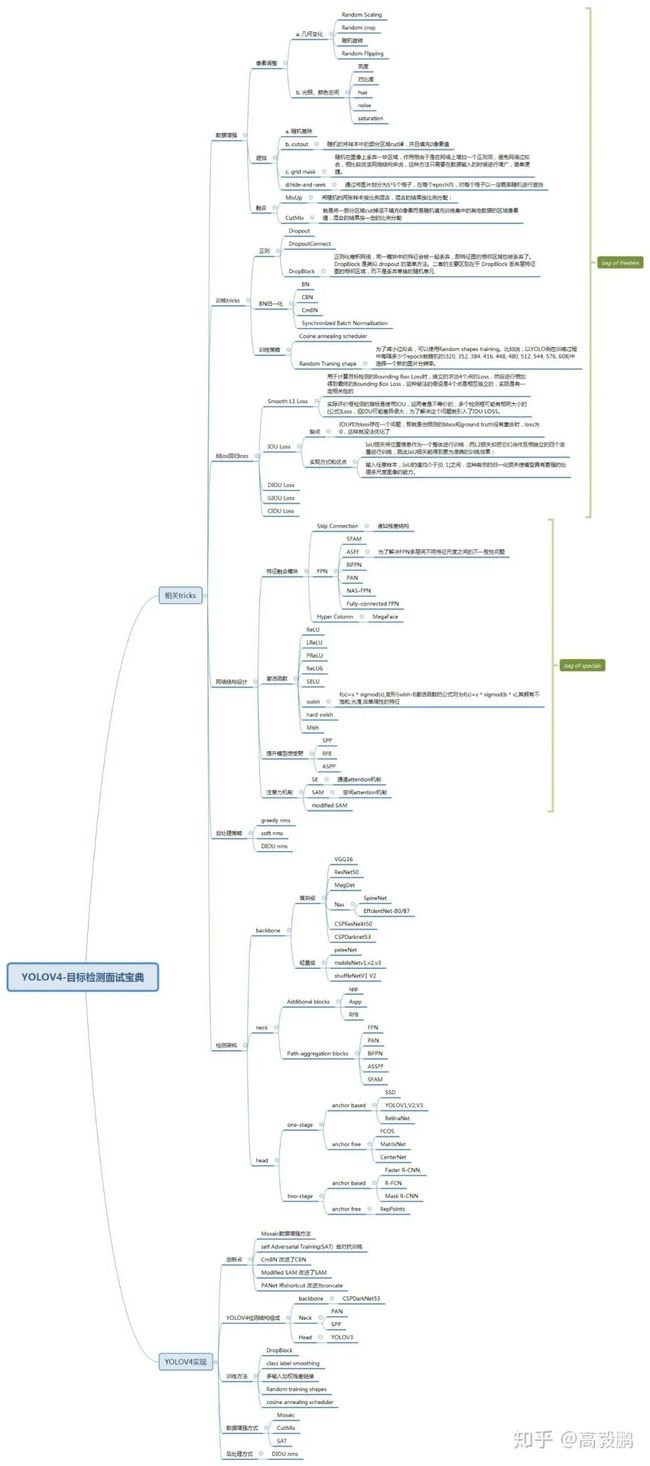
YOLOV4完全可以当做是目标检测面试宝典学习,跟之前编程面试的编程之美,编程珠玑系列丛书有得一拼,YOLOV4就是目标检测领域中的编程之美,编程珠玑。具体涉及到的知识点如思维导图所示。下面选择我认为较好的tircks进行学习然后再具体看看YOLOV4的实现过程。
数据增强tricks->mosaic
Yolov4的mosaic 数据增强是参考CutMix数据增强,理论上类似,CutMix的理论可以参考这篇CutMix,但是mosaic利用了四张图片,据论文其优点是丰富检测物体的背景,且在BN计算的时候一下子会计算四张图片的数据,使得mini-batch大小不需要很大,那么一个GPU就可以达到比较好的效果。
BBox回归loss
Bounding Box Regression Loss Function的演进过程,其演进路线是smooth L1 Loss->IOU Loss->GIOU Loss->DIOU Loss->CIOU Loss。下面文章中有比较详细的介绍。
目标检测回归损失函数简介:SmoothL1/IoU/GIoU/DIoU/CIoU Loss
特征融合模块
PAN
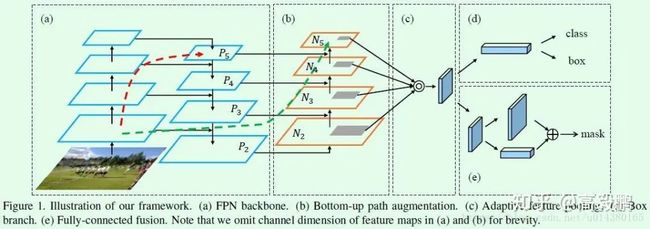
论文创新点:
引入bottom-up path augmentation结构,充分利用网络浅特征进行分割;引入adaptive feature pooling使得提取到的ROI特征更加丰富;引入fully-connected fusion,通过融合一个前背景二分类支路的输出得到更加精确的分割结果。
Bottom-up Path Augmentation的引入主要是考虑网络浅层特征信息对于实例分割非常重要,这个也非常容易理解,毕竟浅层特征多是边缘形状等特征,而实例分割又是像素级别的分类。网络模型经过多次传递,在深层特征基本上无法保留浅层特征。Bottom-up Path Augmentation的做法是通过FPN的小网络将浅层特征融合到深层去,这样深度特征也就有浅层特征的特性,图像分割效果更好。如图中绿色箭头所示。具体实现如下:
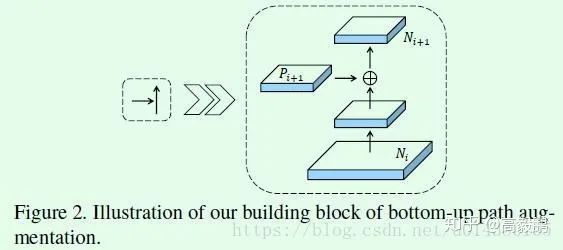
是比较常规的特征融合操作,比如Ni经过卷积核尺寸为3*3,stride=2的卷积层,特征图尺寸缩减为原来的一半,然后和Pi+1做element-wise add,得到的结果再经过一个卷积核尺寸为3*3,stride=1的卷积层得到Ni+1,特征图尺寸不变。
Adaptive Feature Pooling主要做的还是特征融合。
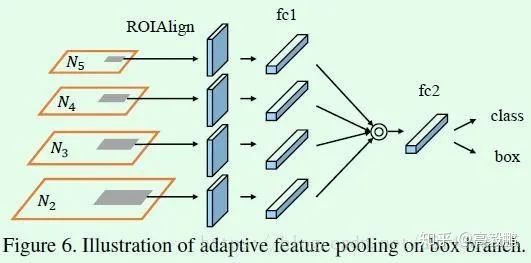
引入adaptive feature pooling其实是基于FPN中提取ROI特征的思考,虽然FPN网络基于多层特征做预测,但是每个ROI提取特征时依然是基于单层特征,基于单层特征做预测效果不是最佳选择,因此就有了特征融合的思考,也就是每个ROI提取不同层的特征并做融合,这对于提升模型效果显然是有利无害。
Fully-connected Fusion是针对原有的分割支路(FCN)引入一个前背景二分类的全连接支路,通过融合这两条支路的输出得到更加精确的分割结果
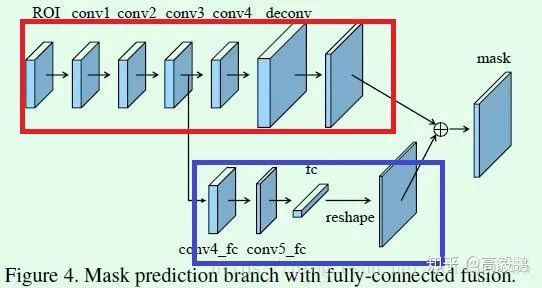
主要是在原来的mask支路(红框所示)上增加了Figure4下面那条支路(蓝框所示)做融合。增加的这条支路包含2个3*3的卷积层(其中第二个为了降低计算量还将通道缩减为原来的一半),然后接一个全连接层,再经过reshape操作得到维度和上面支路相同的前背景mask,也就是说下面这条支路做的是前景和背景的二分类,因此输出维度类似文中说到的28*28*1。上面这条支路,也就是传统的FCN结构将输出针对每个类别的二分类mask,因此输出的通道就是类别的数量,输出维度类似28*28*K,K表示类别数。最终,这两条支路的输出mask做融合得到最终的结果。因此可以看出这里增加了关于每个像素点的前背景分类支路,通过融合这部分特征得到更加精确的分割结果。
NAS-FPN
通过NAS方法得到的FPN{\rm FPN}FPN结构中融合方法进一步提高了网络性能。详情关注以下博客内容。
NAS+Det第一弹:NAS-FPN
ASFF
FPN融合方式存在的问题
FPN中特征直接融合方法仍遗漏了大量语义信息。
SNIP中使用尺度归一化方法,在多尺度图像金字塔中选择性地训练和推理使用合适的目标尺寸。但这种方法显著地增加了推理时间。相比于图像金字塔,特征金字塔的一大缺点是不同尺度特征的不一致性,特别是对于一阶段检测器。
ASFF论文的创新点
让网络自动学习滤除其它层无用的信息,保留有用信息以高效地融合特征。
确切地说,对于某一层的特征,其它层的特征首先整合并调整为相同分辨率,然后通过训练找到最佳融合方式。
如在不同层的相同位置处,有些特征包含无用信息被滤除,而有些特征包含有用信息被加强。
ASFF论文的特点
寻找最佳融合方式的过程是可微分的,可以应用于反向传播。
可以应用于任何FPN网络中。
实现简单,计算量小。
Adaptively Spatial Feature Fusion
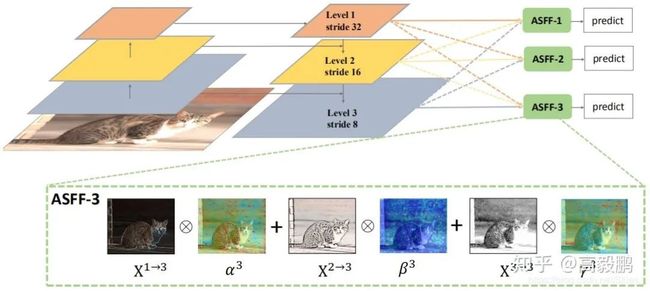
如上图是网络结构,它由两部分组成:固定尺寸和自适应融合。
固定尺寸,由于不同下采样倍数得到的特征图分辨率不同,所以在融合前需要固定大小。做法是首先使用1×1卷积降维、上采样使用插值实现、下采样使用步长为2的3×3卷积和最大池化实现。
自适应融合

BiFPN
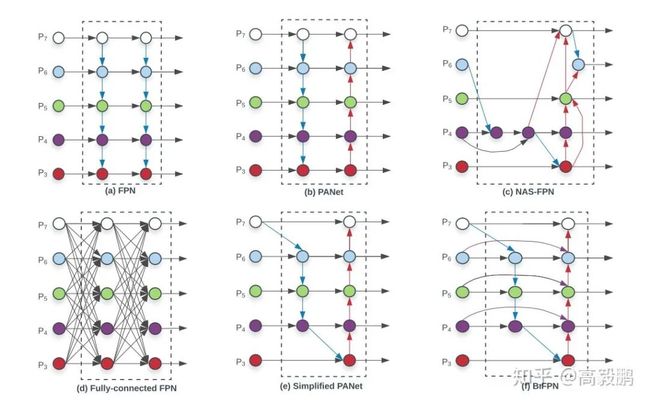
图a是FPN,图b是PAFPN(FPN的改进),主要是增强了P3到C7之间的信息流动,图c是NAS搜索出的FPN,图d是全连接的FPN,图e是简化的PAFPN,主要是将P3和P7的lateral卷积去掉了。图f是BiFPN,在图e的基础上增加了shortcut。其实shortcut的思想在libra rcnn中的BFPN也用到了。需要注意的是,此处会堆叠数个BiFPN,该思想在NAS-FPN中也提出了。详情阅读下面博客。
一骑绝尘的EfficientNet和EfficientDet
提升感受野模块
RFB
https://zhuanlan.zhihu.com/p/86772449
ASPP
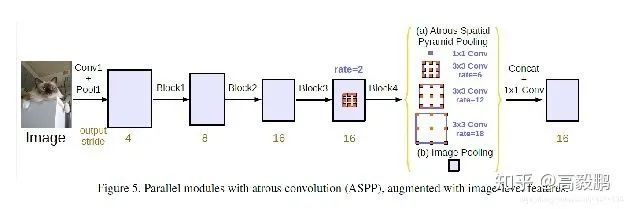
ASPP 实际上就是通过不同的atrous convolution 来对图像进行不同程度的缩放,得到不同大小的input feature map,因为ASPP拥有不同rate 的滤波器,再把子窗口的特征进行池化就生成了固定长度的表示。
注意力机制
SE
https://zhuanlan.zhihu.com/p/101688644
SAM

SAM实质就是CBAM中的空间attention机制,详情阅读博客
https://zhuanlan.zhihu.com/p/65529934
YOLOV4实现
AdversarialTraining自对抗训练
这是一种新的数据扩充技术,该技术分前后两个阶段进行。
在第一阶段,神经网络改变原始图像而不是网络权值。通过这种方式,神经网络对自身执行一种对抗性攻击,改变原始图像,从而造成图像上没有目标的假象。
在第二阶段,训练神经网络对修改后的图像进行正常的目标检测。
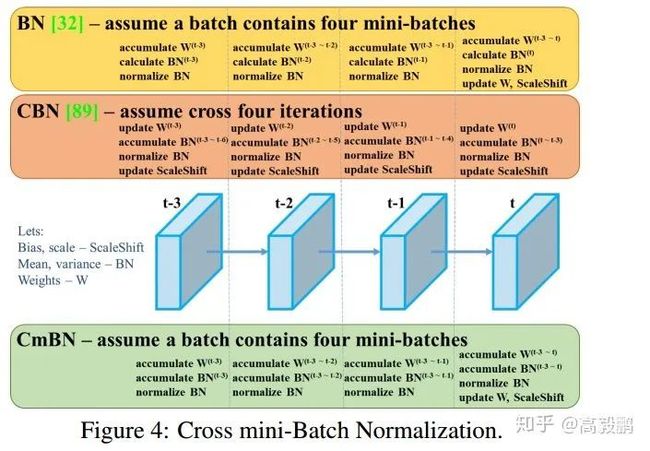
CmBN
表示CBN的修改版本,如下图所示,定义为跨微批量标准化(CmBN)。这仅收集单个批中的小批之间的统计信息。
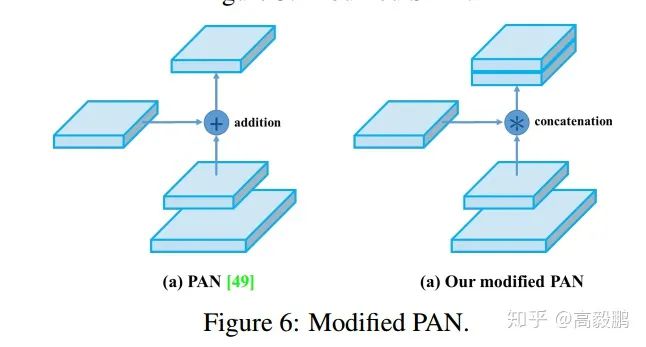
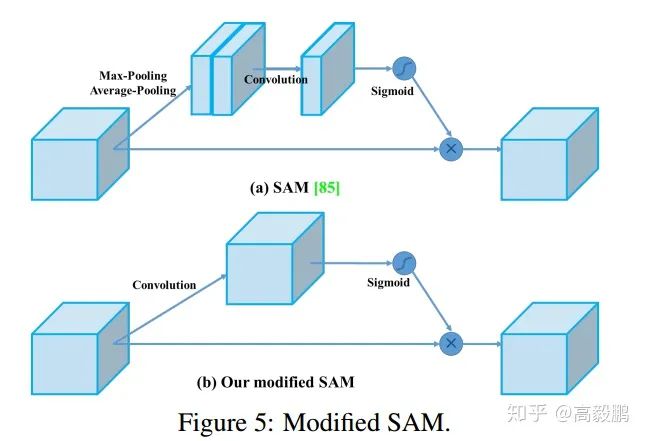
SAM改进 将SAM从空间上的attention修改为点上的attention,并将PAN的short-cut连接改为拼接
一个完整的YOLOv4 由以下三部分组成:CSPDarknet53 (backbone) + SPP+PAN(Neck,也就是特征增强模块)+ YoloV3组成。
另外,YOLOv4使用了“赠送”技巧有CutMix、Mosaic 数据增强, DropBlock正则化,标签平滑,CIoU-loss,CmBN,自对抗训练,每个目标分配给多个anchor,(这点和v3有差别,v3版本每个目标只有一个正样本)。
使用的“特价”技巧:Mish activation、跨阶段空间连接 (CSP),多输入权重残差连接,SPP-block、SAM-block,PAN,DIoU-NMS。
目标检测综述下载
后台回复:目标检测二十年,即可下载39页的目标检测最全综述,共计411篇参考文献。
下载2
后台回复:CVPR2020,即可下载代码开源的论文合集
后台回复:ECCV2020,即可下载代码开源的论文合集
后台回复:YOLO,即可下载YOLOv4论文和代码
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2400+人,旨在交流顶会(CVPR/ICCV/ECCV/NIPS/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI、中文核心等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!