Yolov4技巧学习
一些不错的资源:
一张图梳理YOLOv4论文
Yolov4论文翻译与解析
YOLOV4 论文原理 模型分析
机器学习36:YOLOV4相关理论知识整理
网络结构:

注意5,9,13为进行最大池化时的卷积核尺寸,其余的均为特征图尺寸。
骨干网络:CSPDarknet
找出输入网络分辨率、卷积层数量、参数量和层输入数量四者之间的最优平衡。
Neck:SPP,PAN
挑选能够增加感受野的额外块(additional block),以及针对不同级别的检测器从不同骨干层中挑选最佳的参数聚合方法。
YOLOv4网络解析
创新点:
1:Mosaic 数据增强 Yolov4 mosaic 数据增强
其来源于Cutmix 【论文阅读笔记】CutMix:数据增强

2:自对抗训练(Self-adversarial-training,SAT)
对抗样本和对抗训练笔记------简述
自对抗训练(SAT)也是一种新的数据增强方法,它包括两个阶段。第一个阶段中,神经网络更改原始图像;第二阶段中,训练神经网络以正常方式在修改后的图像上执行目标检测任务。
3:CmBN
李理:卷积神经网络之Batch Normalization的原理及实现


BN是对当前mini-batch进行归一化,CBN是对当前以及当前往前数3个mini-batch的结果进行归一化,而CmBN则是仅仅在这个Batch中进行累积。
4:modified SAM
【CV中的Attention机制】易于集成的Convolutional Block Attention Module(CBAM模块)

modified SAM中没有使用pooling,而是直接用一个卷积得到的特征图直接使用Sigmoid进行激活,然后对应点相乘,所以说改进后的模型是Point-wise Attention。
5: modified PAN
【CV中的特征金字塔】四,CVPR 2018 PANet
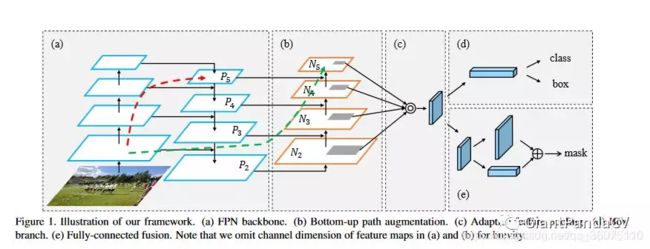

方案设计
(1) CSPDarknet53
检测模型需要具有以下特性:
1)更高的输入分辨率,为了更好的检测小目标;
2)更多的层,为了具有更大的感受野;
3)更多的参数,更大的模型可以同时检测不同大小的目标。
也就是选择具有更大感受野、更大参数的模型作为backbone。CSPResNeXt50仅仅包含16个卷积层,其感受野为425x425,包含20.6M参数;而CSPDarkNet53包含29个卷积层,725x725的感受野,27.6M参数。这从理论与实验角度表明:CSPDarkNet53更适合作为检测模型的Backbone。
记一下CSPNet: 增强CNN学习能力的Backbone:CSPNet
CSPNet (Cross Stage Partial Network)设计的主要目的是在减少计算量的同时实现更丰富的梯度组合。这一目标是通过将基础层的特征映射划分为两部分,然后通过提出的跨阶段层次结构将它们合并。作者的主要概念是通过对梯度流的分裂使梯度流通过不同的网络路径传播。通过这种方式,证实了通过切换级联和转换步骤,传播的梯度信息可以具有很大的相关性差异。此外,CSPNet可以大大减少计算量,提高推理速度和准确性。
(2) SPP
空间金字塔池化,使得任意大小的特征图都能够转换成固定大小的特征向量,送入全连接层。


SPP(Spatial Pyramid Pooling)详解
一文搞懂SPP(Spatial pyramid pooling)
(3) PANet 见上
(4) CmBN 见上
(5) 多输入加权残差连接(Multi-input weighted residual connections)
(6) Mish
Mish激活函数,ReLU的继任者
Mish=x * tanh(ln(1+e^x))

平滑的激活函数允许更好的信息深入神经网络,从而得到更好的准确性和泛化。
绘图网站:Fooplot,怎么自己上学的时候就没发现这个神奇网站?!
(7) loss
目标检测回归损失函数简介:SmoothL1/IoU/GIoU/DIoU/CIoU Loss
yolov3 loss函数探索(二):diou/ciou-darknet
训练相关
数据增强
(1) Mosaic 见上
(2) Cutmix
cutmix是采用cut部分区域再补丁的形式去混合图像,不会有图像混合后不自然的情形。
(3) SAT 见上
(4) Label Smoothing
2016年,Szegedy等人提出了inception v2的模型(论文:Rethinking the inception architecture for computer vision),其中提到了Label Smoothing技术,可以看作是一种正则化方法,对于ground truth(也就是标注数据)的分布进行混合,使得标签在某种程度上软化,增加了模型的泛化能力,一定程度上防止过拟合。
标签平滑Label Smoothing
(5) Dropblock
Dropout的主要问题就是随机drop特征,这一点在FC层是有效的,但在卷积层是无效的,因为卷积层的特征是空间相关的。当特征相关时,即使有dropout,信息仍能传送到下一层,导致过拟合。
在DropBlock中,特征在一个block中,例如一个feature map中的连续区域会一起被drop掉。当DropBlock抛弃掉相关区域的特征时,为了拟合数据网络就不得不往别处看以寻找新的证据。
正则化方法之DropBlock
如何看待谷歌研究人员提出的卷积正则化方法「DropBlock」?
『DropBlock: A regularization method for convolutional networks』论文笔记
策略
(1) Cosine annealing scheduler
使得学习率按照周期变化,在一个周期内先下降,后上升。

PyTorch学习之六个学习率调整策略
pytorch必须掌握的的4种学习率衰减策略
(2) Random Training Shapes
为了减小过拟合,在训练过程中每隔多少个epoch就随机的{320, 352, 384, 416, 448, 480, 512, 544, 576, 608}中选择一个新的图片分辨率。
目标检测任务的优化策略tricks
小知识:如何理解神经网络中通过add和concate的方式融合特征?
赞一个:使用netron工具可视化pytorch模型