S12X微处理器的XGATE协处理器使用指南
S12X MCU上有一个协处理器,嗯,一个准双核处理器,但是之前都不会用,最近准备学习下怎么使用它。于是乎开始研究官方文档。
翻译的资料是公开的,在这里下载https://www.nxp.com/products/microcontrollers-and-processors/additional-processors-and-mcus/8-16-bit-mcus/16-bit-s12-and-s12x-mcus/ultra-reliable-s12xe-high-performance-automotive-and-industrial-microcontrollers:S12XE?tab=Documentation_Tab,我想应该不会有什么版权问题,如涉及版权问题,请联系我删除文章。另感谢NXP提供的学习资料。
Tutorial: Introducing the XGATE Module to Consumer and Industrial Application Developers
by:Ross Mitchell
Systems Engineering Manager, Transportation and Standard Products Group
译者注:译者博客(http://blog.csdn.net/lin_strong),转载请保留这条。此为官方文档AN3224,仅供学习交流使用,请勿用于商业用途。
介绍
许多嵌入式应用需要以很低的延迟处理大量的任务。直接内存访问模块(Direct Memory Access modules,DMA)使得中断源用到的数据能够自动地由硬件控制进行读写,这构成了解决方案的一部分。然而DMA的功能很有限,基本只是在等待下一次中断之前执行读或写命令。这硬件可以用于在各个模块中清零标志位,但是基本也没什么其他功能了。在嵌入式系统中,中断事件中常会需要进行其他逻辑处理步骤,比如在把信号或者数据发送到最终目标之前进行验证或者修改。因此,一个使用了DMA的中断常常只做了半件事,CPU需要暂停主函数的执行以完成整个任务。中断处理其实会影响CPU处理其他函数的效率,而且中断处理常常会有一定的实时性要求,这也会使得应用的软件更加复杂。
XGATE就是为了大大提升应用的响应速度和一致性而设计的,它能够独立于主CPU地执行中断指令序列,这样就降低了主CPU处理中断的压力。
XGATE的作用?
XGATE的设计目标是进行快速的中断处理,这样就降低了主CPU进行中断处理的负担。
大部分嵌入式实时应用程序需要许多由中断驱动的进程来完成许多简单的功能,这些进程的使用率常常特别高。比如人机交互接口函数、执行器控制反馈以及与系统其它部分的通讯。XGATE就是设计来帮助主CPU处理这些事件的。
XGATE的一个特别赞的特性就是它的通用指令集,这个指令集可以实现复杂的指令序列。XGATE不只是一个智能DMA控制器,它还是一个专业的I/O协处理器。当然,在开发在XGATE中与CPU12X内核并行执行的应用程序时,还有一些限制需要考虑。后面会涉及这些限制;但是,这些限制很好理解,并且不会影响XGATE的典型功能。
通过减轻CPU处理中断例程的负荷,我们知道这些例程中的大部分都不是很耗时,XGATE使得应用程序具有一定程度的确定性行为。
XGATE的概念
来自中断控制器硬件中的中断可以被路由到XGATE或者CPU12X。把任意中断路由到XGATE其实就相应地降低了CPU的负担,XGATE会处理整个中断例程。
如图1所示,一个开关决定了中断信号会发送给XGATE还是CPU12X。如果选择了XGATE,它就会执行对应的例程,然后在执行完成后等待下一个中断请求。
在图1中我们可以看到,有一个用于使能XGATE处理特定中断的寄存器,并且中断的优先级分为七个等级。同时发生的中断请求会根据优先级来处理 — 最高优先级的最重要,会被首先处理。这优先级在CPU12X和XGATE上是一样的。
XGATE本身就是一个CPU。它可以由软件编程,并且受到ANSI C编译器的完整支持。一旦出现发送给它的中断,它就会开始运行。在完成中断任务后,XGATE就会再次停止它的时钟以等待下一个事件,这样就降低了能耗。
XGATE是一个协处理器。它可以直接使用和直接访问几乎所有的主CPU可以访问的映射到内存的寄存器以及片上存储资源。XGATE的最大创新点是它独特的接入MCU现有片上RAM的方式。MCU的内部总线允许在多种总线访问状态下对RAM的交叉访问,这样当主CPU全速访问RAM时会占用一半的时间,另一半时间则是XGATE来访问RAM;当CPU不访问RAM时,那两半的时间就都给了XGATE。
实际上,在一般的程序中,主CPU不会在每个总线周期都一直访问RAM,频率比这低得多了;这是因为它通常会从FLASH中取出指令,然后读写寄存器。典型地,XGATE可以在每8个总线周期中的7个访问RAM。
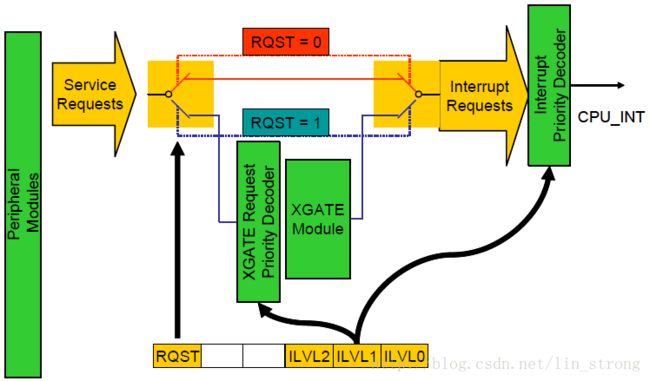
图 1.中断路径(CPU或XGATE)
可能你会觉得奇怪,”为什么XGATE的代码为什么不放在FLASH中?”我们必须考虑对不同存储器类型的访问速度。RAM对于寻址和传值的响应速度比FLASH快得多。FLASH的访问速度达不到80MHz总线访问频率的需求,然而RAM和MCU寄存器却可以达到需求。如果使用FLASH来存放XGATE代码而不是使用RAM的话,XGATE的性能至少会降低一半。此外,CPU花费了大量的时间在访问FLASH上(这不会降低性能,因为CPU的运行频率只有不到40MHz);然而,XGATE却会在每次访问FLASH存储器时被阻塞,因此选择使用RAM来存储XGATE代码。
XGATE的时钟被锁定为两倍的总线频率,它的性能典型地不会由于需要访问共享的RAM资源而受到影响。但是,你需要清楚的是,XGATE访问RAM的优先级低于主CPU。这会影响确定性;但是这是受控的,我们会在下一部分解释运作原理。
图2中展示了XGATE是怎么连接到微控制器的其他资源上的。
这里,我们可以看到XGATE与存储器和外设的接口的一个表示法。图中的“p”连接器是指在这个地方CPU的访问优先级高过XGATE(除了端口替代寄存器),并且XGATE的总线访问速度最大和CPU一样为40MHz。“t”则代表着XGATE可以以CPU两倍的访问速率来进行访问。XGATE可以访问FLASH存储器块、RAM以及外设,但是却不能直接访问S12X设备上的EEPROM。实践中,大部分内存地址在同个总线上,但是XGATE的角色通常是管理外设的数据流、传递中断处理例程的执行结果到RAM中的一个缓冲区或者内存地址中,以便主CPU随后进行处理。

图 2.数据总线与XGATE、CPU12X、存储器、外设模块间的接口
让我们看看我们可以怎么最好地使用这个附加的功能。
XGATE以MCU总线的两倍频率运行,换句话说就是你有一个两倍总线频率的CPU。大部分XGATE指令都只需要一个时钟周期就可以完成,因此从更快的总线访问中可以获得更优化的性能。XGATE CPU还有优化过的指令集以及一个寄存器配置,可以被短小的例程用于进行高效的位/字节操作,所以对于这一类中断处理任务,它的性能比主CPU高。确实,在一次对典型的字、字节和位操作的类比测试中,CPU12X(40MHz总线)的性能大约8MIPS(百万指令/秒),而XGATE(80MHz时钟)大约13MIPS — 协处理器比主CPU有着更佳的执行性能。
现在我们已经说了许多大部分嵌入式开发者关心的问题了。我们有两个独立的CPU,两个CPU有着不同的指令集和不同的CPU架构,以不同的速度运行,但是使用的是相同的内存资源和外设。
这是在考虑了许多设计选择后决定的。
一般来说,在争夺资源时主CPU总是胜利的,XGATE总要等待释放访问权。这意味着偶尔会有一些延迟,这会轻微的降低XGATE的性能。所有为XGATE编写的代码都应该考虑这个因素。
如果你使用C语言编程的话,那架构差异就主要变成C编译器开发者的事了。XGATE CPU架构致力于执行速度和小指令集。XGATE指令被开发为有着很高的速度、提供C上高度优化的实现。对于有着强迫症,还想进一步优化XGATE代码的开发者,可以很简单地在代码中插入XGATE汇编代码以强制使用特定的指令。
由于两个CPU的外设是完全一样的,移植S12X CPU的C代码到XGATE CPU上特别简单。这个特性实际上使得开发XGATE例程特别简单,因为二者的代码几乎完全一样 — 我们后面会讨论一下二者代码细微的差别。
所以,我们需要执行一些指令,并且我们想要它们以XGATE CPU的最大速度执行,所以它们的代码应该放到RAM中。由于RAM不是永久性存储器,代码实际上是先存放在FLASH存储器中,然后在MCU重置后被加载进RAM中的。为了避免XGATE代码在被加载进RAM后发生损坏,S12X能在其被下载后对这段地址范围进行针对主CPU的写保护,这样就避免了XGATE代码被跑飞的代码破坏的那微小的可能。这存储保护特性的运作方式与FLASH和EEPROM上的保护很相似。
总而言之,XGATE以与主CPU几乎一样的方式连接到了MCU的存储器上,并且在访问RAM时的速度是主CPU的两倍。
我们要看看怎么最大化地利用它,然后,之后就是要避免以及要理解的一些重要的事情。
虚拟外设
现在,我们就可以用XGATE来实现一些功能了,如I/O和定时器外设功能,可以将其视作专用的硬件外设。
“虚拟外设”使S12X MCU有着巨大的灵活性,可以大大增加应用程序的灵活性,同时还能利用这个I/O协处理器的处理能力。
多通道PWM
脉宽调制模块(PWM)被MCU的硬件严格限制在固定的引脚上,否则我们就得用软件来驱动脉冲信号。由于我们希望在输出引脚上使用廉价的滤波器,通常会想使用短的PWM周期,这样由于大量的中断调用,会导致主CPU很重的负担。XGATE可以完全分担主CPU的这个负担,并且可以只占用区区一个硬件定时器来为许多通道生成PWM信号,这是对MCU资源非常高效的利用。
下面两个实现示例阐述了XGATE用于这类功能时的性能。
例子 1.灵活的例程,驱动117个通道的8位PWM,以80Hz频率更新,每个都可定制输出端口、占空比和周期。
这里,我们为每个PWM通道使用一个10字节大小的数据结构来控制端口赋值、占空比、周期等;另外还使用了一个很精简的例程,它读取数据并执行由数据表定义的函数。这个例程只有94字节大小并且执行它占用了XGATE 58.2%的性能。用于全部117个LED灯的整个数据表占用了1170字节,也就是说例程的大小只是数据表的8%。这是XGATE指令集灵活性的一个良好示例。+
这个例程有高达240万次每秒的实际中断率。在这个情况下,由于PWM是通过基于单个定时器比较的软件控制来生成的,为了在80Hz下维持8位分辨率,例程每49μs就会完整读一次数据表。例程会花费28.4μs来检查这117个PWM通道需不需要改变输出状态。这个时间和PWM通道数是呈线性相关的。因此,如果把通道数减到100个的话,这时间大约就是24.3μs。
在第二个示例例程中,也就是下面讨论的那个,优化了代码的执行速度以降低XGATE例程的耗时。
例子 2.100Hz下100个通道的10位PWM,能够分组输出,在最佳性能下是常用周期。可以作为备选方案。
这个例程对性能进行了优化,灵活性不如前面那个。可以理解的,它的长度达到了1010字节,但是每个PWM只需要使用两字节的数据结构,因此100个通道只需要202字节的数据。这时XGATE的负载达到了86%,但是分辨率高了4倍,并且PWM率比前面那个更快。
这个针对性能优化过的例程的实际中断率高达1020万次每秒,是前一个例子的四倍还多。
这个例程花费8.6μs来执行100个10位分辨率PWM通道。
我们可以从上面的PWM示例中看到,XGATE代码的优化是有代价的,对于任何CPU都一样。但是,如果我们想要较低的延迟时间以运行其他例程,我们必须降低XGATE执行代码并完成中断处理例程的耗时。平衡RAM的使用也是一个重要的考虑点。如果24μs的延迟对于其他例程是可接受的,大小优先的算法可以大大降低RAM占用并且如果可用的RAM量有限的话,这是很重要的。但是,大部分开发者会倾向于较大但高效的例程,因为它相对来说还是短的,并且有利于XGATE应用代码未来的扩展。
在两个例子中,S12X CPU都可以待在STOP模式下,PWM依然可以全速运行。
处理串行通信协议
XGATE还很常用于串行通信。我们接收消息,将标识符进行比较,然后将数据移动到内存中的适当区域,具体区域由标识符和载荷数据的任意匹配确定。
对于这类工作,XGATE例程通常会更长,因为可能需要搜索和比较数据,然后搜索消息目标表以决定分配荷载数据到哪。对于连接到msCAN模块上的XGATE,完整地实现CAN可能要检查100个以上的标识符,但是它可以在CAN总线消息的间隔期间处理这些事情,并且还有空闲。在这种情况下,对于低速CAN总线上典型的10ms CAN消息帧周期,XGATE有充分的时间来处理大数据表。由于CAN消息处理例程可以很复杂,常常它会花费比典型的中断例程更长的时间,因此会导致其他的中断有可能有很大的延迟。
实现CANOpen协议是强化标准外设的一个好例子。msCAN模块只有三个传输和五个接收缓存,然而CANOpen要求收发都最少要有十六个。可以使用软件扩展CAN的能力,但是为了实现这额外的功能会占用CPU12X大量的性能,而且会限制主应用程序代码的可用性能。
图 3.用XGATE分担CANOpen应用程序的负载
图3阐述了CANOpen功能上使用XGATE来增加msCAN缓存数以满足CANOpen的要求。CPU12X的负担大大地降低了。
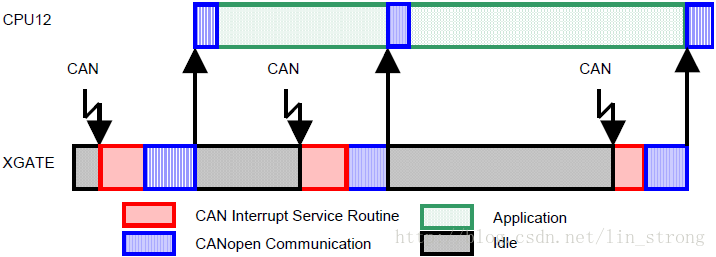
图 4.解放CPU的性能
为了进一步解释,图4展示了CPU12X的活动(时间线从左到右)。当接收到了CAN消息帧,首先运行XGATE中断例程,然后就会执行CANOpen例程来辨认数据包并把数据放入合适的内存缓存以等待应用程序代码的访问。在CPU12X上的那部分代码可以在两次中断间的任意时间运行,把处理中断的任务交给了XGATE。这可以大大提升在接收到CAN消息,平均每100μs一个(高速CAN的理论最大值),时的应用程序代码的性能。可以由此受益的应用包括实时工业应用,如那些驱动自动化装备的,在这些应用中,闭环控制系统需要快速的系统响应。如果如果不使用XGATE,就需要更快的CPU,通常成本会高得多。
CAN网关
在工业控制系统中会出现CAN网关 — 典型地出现在有两个CAN网络拓扑的情况下。Freescale8位和16位MCU上的msCAN模块的过滤能力有限,而大型分布式工业系统可能有特别多消息标识符。
XGATE可以使用查询表来提供100%的过滤能力。对于每隔100μs到达一次的CAN消息(每个消息8个字节与一个29位标识符),处理两条这样CAN总线的负荷对于8位或16位MCU来说是十分大的。XGATE可以把这个负荷对于主CPU降到几乎为零,只需要258字节的代码就能实现。对于有着6字节数据的CAN消息,XGATE代码处理每条CAN消息大约要花费3μs — 最差情况下也只占用了6%的性能。
正交译码器
许多电机控制应用需要连续的来自位置和速度传感器的输入。正交译码器可以提供位置反馈并为小型快速旋转电机产生每秒成千上万次的脉冲(中断)。这是XGATE的一个理想应用,因为它可以独自处理中断事件,在中断事件中获得两个传感器提供的方向和位置参数的变化,不用劳驾主CPU。可以使用第三个传感器提供旋转参考点的系数信号。有一个中断用来完成每次读取两个传感器输入的任务,并基于随后输入的状态进行简单的前向/反向计算;使用XGATE来完成这事的话耗时很短(这个例程只会占用不到0.5μs),是XGATE功能的一个理想应用。

图 5.正交编码信号
正如我们在图5中看到的那样,中断十分频繁;然而只要达到最高的输入频率,检查输入引脚是会有一定延迟的。对于电机控制,这延迟可能太高了,所以如果你计划在XGATE上运行多个例程的话,检查这个例程可忍受的延迟是十分重要的。
同步串行通信
XGATE可以为许多串行通信提供一个底层驱动函数。
以主机模式运行的SPI很容易实现,因为时钟和数据是完全由XGATE驱动的,并且只需要一个定时器以提供波特率。

图 6.串行外设接口(SPI)主机
大部分情况下,在这个协议中,主机的时钟信号的周期是可以轻微地变化的,只要保持在从机能够接受的最小时钟周期之上就行。因此,XGATE运行另一个例程而轻微地延迟SPI主机例程一般是可接受的。但是,这个例程通常运行的特别频繁,可能会被另一个XGATE函数大大地延迟,这能导致这个软件SPI的比特率剧烈变化。在许多应用中,主机驱动的是一个SMOS产品或者一个无反馈外设,这时数据率低于100kBaud是没问题的。这种情况下,每一个bit都可以被独立地处理。
一定要小心 — 典型地,SPI时钟运行在1MHz,每次XGATE只有80个时钟周期,其他例程可以很轻易地延迟它,只要量稍微大点。为了避免延迟,一个可能的方法是不离开XGATE例程发完整个字节。这会花费大约9μs并且在例程中会有大量的无用时间,这大大的浪费了XGATE的性能;然而,如果所有的其他例程都可以接受最差9μs的延迟,这可能是最佳选择。
这个示例中,实现从机响应要考虑更多的事情,因为它必须迅速反应来自由SPI主机驱动的输入SPICLK信号的每次时钟。这决定了最差延迟时间,再次强调,我们需要确定其他例程不会干扰这个响应。
XGATE仍可以简单地管理SPI从机,这典型地就是每当在第三个引脚(SCLK)上发生时钟反向时在一个端口引脚(MOSI)上获取数据值或者在另一个端口引脚(MISO)上输出数据。一定要仔细考虑SPI的实现,因为丢失一次时钟边沿也就是半个时钟周期会产生错误地读取并导致传回SPI主机错误的数据。
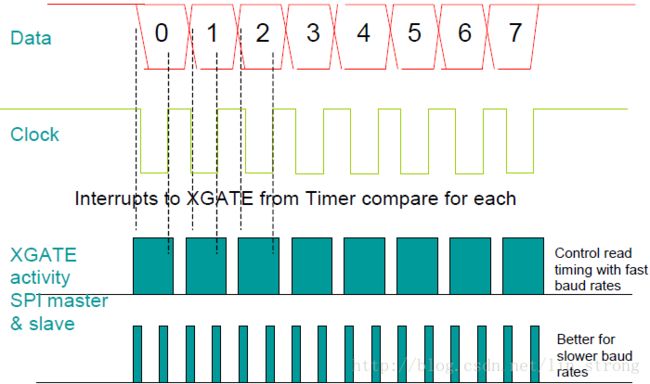
图 7.串行外设接口(SPI)从机
图7展示了处理混合主从SPI的两种方式。时序图的下半部分展示了XGATE的荷载并显示主机和从机有不同时间的事件。对于低速SPI,像最下面的那个两次追踪的方法是可接收的,但是对于高速通讯,其他XGATE例程的抖动效应或仅仅是CPU正常地访问RAM都可能导致延迟大到必须使用另一种方法以保证时序,即把主机发送和从机接收放到一个例程中。如我们在图7中看到的,对于高波特率通讯,这种方式实际上在传输和接收数据之间占用了XGATE。
因此,SPI从机的运行对XGATE十分苛刻,但这示例也很好的阐述了协处理器的一些限制,我们可以选择接受它并小心地管理它以实现我们想要的功能。大部分情况下,XGATE会使用专用的SPI外设,并提供队列机制以及可能有芯片选择功能。
异步串行通信
XGATE可以通过直接操作I/O端口数据位来实现软件SCI或说UART,就如实现SPI时那样。这与前面描述的同步通信函数很相似,但是,当然咯,每一bit的时序是非常重要的。
这对XGATE代码有严格的限制;然而,波特率通常最大仅为19,200。因为要求在不管是设置还是采样每一个bit时,偏移都不能超过波特率的20%,并且整体不超过2%,所以最差延迟时间是10.4μs。这是bit时序上可接受的偏移,这样在19,200波特率下就可以正确的发送和接收数据的8个bit了。
发送SCI数据的XGATE代码需要两个定时器值,这可以由单个定时器比较产生:一个用于bit周期;另一个用于断线检测时间,这常需要多个bit时间。传输一个bit的例程特别短,只需要设置输出端口的状态然后递增bit计数器。接收数据则需要在bit周期的正中间采样,这实际上使得中断频率翻倍了,因为需要另一个独立于发送中断的XGATE中断。再强调次,这个例程很短。由于两次中断间的最差时间间隔是26μs(在19,200波特率下发送/接收),其他例程的耗时绝对不能超过大约36μs(26+10.4μs的可接受延迟),否则就会影响19,200波特率下SCI的发送和接收了。
这个示例很好的展示了在混用XGATE例程时怎么允许其他例程运行并满足最大可接受延迟。
还有需要考虑一些事情;我们之后会讨论,但这里主要是为了让你明白你可以怎么使用XGATE。
处理LIN协议
本地互联网(LIN)协议在汽车应用中十分知名,并且,由于成本低廉并可与CAN并列部署,它已经开始出现在其他非汽车的应用中。
LIN假定一个略微修改的标准UART或说SCI。对于主节点来说,最大的不同是会生成比其他异步通信协议趋于使用的中断信号更长的中断信号。这就要求从机兼容变化的时钟频率。这协议的帧格式特别简单:中断、波特率同步字节、标识符、二到八字节的载荷数据以及一字节的校验和。
由于SCI外设是逐个字节控制的,协议受益于XGATE会处理中断并用队列传输数据、用缓冲区接收数据这个事实。
处理这协议的XGATE例程只有213字节大小,处理每个字节只需要占用0.9μs。对于两字节的荷载数据或说两字节LIN消息,它只会占用80MHz下XGATE性能的0.66%。
队列管理
为外设管理队列常是主CPU的一个重要负担。许多MCU架构选择在外设上弄个队列以降低CPU的负担。使用XGATE可以在不增加主CPU任何负担的前提下实现这个功能,同时还提供用户可定义的灵活性。
典型地,用于搜索的例程会花费一会时间,所以找到某种方式降低这些例程的执行时间是个好主意,这样就可以避免阻塞其他例程。在排序过的数据上使用二分查找的效率可以十分高,因为可以把任务拆分为许多步以避免单次很耗时的例程。
LCD显示控制
是有可能使用XGATE直接驱动多达4个背板的LCD面板的;图8是一个典型的示例。

图 8.XGATE直接控制LCD面板的PCB示例板
这个LCD有60个段,由4个背板和15个前面板驱动。刷新的帧率为64Hz。使用的控制算法能实现直接控制每一个段(开/关 — 每个段一个bit)和实现16位精度的对比度调整。
XGATE还会生成用于LCD半偏驱动的所有信号。
在这个例子中,XGATE的平均荷载是0.098%(40MHz总线),CPU则在STOP模式下。
这是驱动显示器的一个示例,其中,XGATE的性能远超所需的。这个例程会执行10个特别的函数以产生八个转变(transition)来维持4个背板以及两个转变来维持相对时序。每次更新都要花费1220个周期(每次刷新显示需要15.3μs执行时间),这使得每秒能进行640次转变,因此刷新频率是64Hz。在这个示例中,每个转变例程要花费大约1.25μs,这是XGATE上很小的负担。这个很棒的示例展示了怎么高效使用XGATE的同时还给其他例程保留大量的性能。
加密例程
XGATE并不是为加密设计的。但是,只要理解了长时间运行的例程的延迟考虑因素,这个CPU其实就是一个高性能移位机器,可以很好的用于实现AES、DES和3DES。
XGATE拥有优秀的16位字段上的位操作指令集,这使得实现像AES这样的算法时十分高效。即使这样,如果XGATE还要用于其他例程的话,超过100μs的执行时间很有可能是一个大问题,因为其他例程常常需要更短的延迟时间才能正确执行。因此,在执行如加密这类长耗时算法时要小心,这会对其他运行在XGATE上的功能造成直接的影响。
…把AES拆分成多步可以让其他中断能被处理。
for (i = 0; i = 8; i++) {
进入XGATE AES算法的第i步;
// 之后进入XGATE中断以执行AES的其他几步.
}编写XGATE的代码
把为S12X CPU写的中断例程移植到XGATE上是十分直接的过程。
典型的过程如下:
- 决定XGATE要为CPU提供什么服务
- 决定中断的优先级
- 决定共享数据的分配以及共享机制
C代码必须被指定到XGATE C编译器上而不是主CPU的编译器;为了实现它,在使用CodeWarrior时,XGATE C代码文件有个独特的后缀名,“.cxgate”。链接器会通过识别不同的文件后缀名来处理两个处理器的控制。
为了进入中断例程,XGATE使用了两个字,一个字(一如既往的)是中断向量地址,而另一个字(16bit)是指向相关数据参数的特殊向量。
由于可执行代码是放在RAM中的,我们必须小心地优化对这个昂贵的MCU资源的使用。如果只有单个虚拟外设,那这无关紧要;但是常会想要创建多个虚拟外设。比如创建多个软件PWM通道。当在CPU12X上写软件PWM时,开发者通常会选择为每个PWM输出分别写个例程(译者内心mmp:个屁,这不是最初级的没学过数据结构和算法的人才会写这样冗余的代码么),由于这个例程会放到FLASH存储器中,所以这也没什么关系,因为FLASH是MCU上相对廉价的资源。但是,在RAM上运行的XGATE更加高效,而RAM是昂贵的资源,所以必须使用不同的方法。
使用单个PWM例程并让每个PWM输出都拥有关联数据以唯一地选择特定I/O引脚、周期和脉冲宽度会是个更好的方法。对于8个通道的软件PWM,可能需要8*4字节的数据(用于I/O引脚标识、周期、占空比),但是用于存储可执行代码所需的RAM则大得多 — 可能最少要100字节。
为了解决这类问题,XGATE提供了一个特性,这个特性能简易地赋值许多数据集给单个例程。XGATE的设计中除了中断例程指针,还设计一个指向数据的指针。换句话说,每次运行代码时,它可以基于一个由每个中断向量区分的独立的地址表来加载或存储不同的数据。当例程很复杂时,这个设计的效果很明显。图9中展示了这个功能。
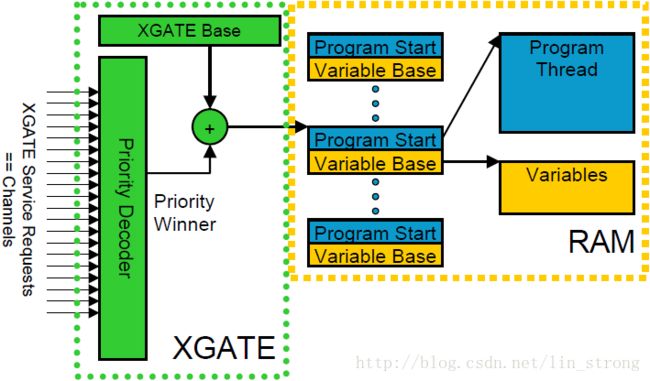
图 9.XGATE例程的向量和数据指针
中断例程可以为每个中断设置独立的数据指针和程序起始地址。由于CPU12X CPU并没有这个功能,所以这是在移植S12X CPU的例程到XGATE上时的少数几个变化之一。由于XGATE是一个单进程CPU,使用这个方案来降低RAM占用并不会产生数据一致性问题。
XGATE代码通常是从RAM中执行的,但是必须在MCU启动时从FLASH存储器中加载到RAM中。因此,一个小的bootloader例程也会被写入FLASH,XGATE可执行例程的数据包则会与这个bootloader例程一同加载进FLASH。
最后一个注意点…
要确保XGATE的快速执行不会导致整个系统的时序上的问题,如果你最初是为S12 CPU写的例程。一个好的编程实践在这会起到帮助,那就是不要依赖于周期计数来满足虚拟外设的时序要求。由于定时器和其他外设的行为与在S12 CPU上的一致,这通常不是一个问题。
对于任何双处理器系统来说,与运行在主处理器上的例程通讯是一个基本需求,这是通过8个信号量寄存器实现的。信号量这个概念使得两个独立的任务能够以可控的行为共享同样的数据元素;如果任务A控制了与数据关联的信号量,则任务B在对数据进行任何访问之前则必须先等待任务A清零信号量。对于XGATE,任务A可能运行在XGATE上,而任务B可以可能在主CPU上;因此,两个任务可能同时运行,因此需要这个硬件锁来避免对数据不正确的修改。
信号量硬件寄存器有两个重要状态:为XGATE保留,以及为主CPU保留。等待中的任务无法改变信号量寄存器的状态,必须等到寄存器被清零才可以继续,这样就使得软件能使用这个状态来确定是否可以访问共享的数据。这从另一个方向实现了CPU与XGATE间安全的数据共享。
事实上,大部分开发者选择使用软件信号量,它以同样的方式工作,并且灵活性更好。这里,可以使用双缓冲的数据来共享数据,软件中的标志位则表明了数据的“拥有者”以及其他函数的完成。
好啦,现在可以运行XGATE代码了。
预期性能
XGATE在每次中断处理时只有150-200ns(以80MHz运行时)的延迟 — 这是由硬件驱动的。在这之后,XGATE会执行对应的RAM地址处的代码。
在中断例程返回时,XGATE能立即无缝执行另一个中断。XGATE并不会为了服务中断而入栈和弹出寄存器。这导致在中断处理上XGATE比CPU12X优化了20个周期,这是XGATE在处理中断上一个不容忽略的优势。
由于XGATE典型地有85%的访问RAM时间(因为主CPU的优先级更高)并且有优化的指令集,函数的运行速度可以比S12X CPU快4.5倍。更典型的是,XGATE的运行速度是CPU12X的两倍。
表 1给出了性能的一些例子。
表 1.性能示例
| 功能 | 典型的大小(字节) | 数据大小(字节) | 典型的执行时间(μs) | 占用XGATE性能的比例 |
|---|---|---|---|---|
| 100个通道的10bit PWM,100Hz的固定周期&静态端口选择 | 1010 | 202 | 8.3 | 86% |
| 100个通道的8bit PWM,80Hz的刷新率,每个通道可灵活选择周期 | 94 | 800 | 24.3 | 49.7% |
| LCD — 60个段、64Hz帧频、4个背板、对比度可调 | 262 | 26 | 1.25 | 0.098% |
| LIN SCI每字节 | 213 | 每个通道14 | 0.9 | 0.17% |
| CAN网关消息路由,消息间隔1ms | 258 | 每个CAN消息+ID表 6 | 3.0 | 0.3% |
XGATE运行多个例程
对于程序员来说,XGATE有个重要的考虑因素 — 在XGATE中一旦一个任务开始了,例程会一直运行到结尾,结尾即“返回调度器”(RTS) 指令。因此,我们必须总是考虑一些代码无法在发生中断后立即被执行的可能性,因为在另一个XGATE例程可以开始之前,当前的XGATE例程必须先结束。
对于许多工业应用,典型地考虑XGATE性能的方法是在某一个时间段运行所有的操作,然后测量每个例程完成所需的时间。把它们放到一起就可以确定是否例程们总是可以在分配的时间内完成工作。如果可以,系统就是确定性的。可用的空余性能就会很明显。
表2展示了在XGATE上运行多个代码段的例子。
| 功能 | 总时间(μs) | 占100μs周期的% |
|---|---|---|
| 用于30Tx和30Rx IDs的网关tic | 17.1 | |
| 接收中找到帧ID | 2.4 | |
| 拷贝信号到消息缓存(字节值) | 1.9 | |
| 帧传输 | 0.7 | |
| CAN缓存空ISR | 1.2 | |
| CAN接收ISR(生成一个Tx帧) | 8.8 | |
| CAN通讯的总XGATE占用(μs) | 32.1 | 32 |
| 在8个信号上处理数据对象 | 25 | 25 |
| 32 x 10bit PWM通道,100Hz | 2.7 | 3 |
| XGATE上可用资源 | 40.2 | 40 |
如上例中所见,为两个CAN总线和30个消息进行CAN通讯占用了100μs时间片32%的时间。这使得其他例程能运行 — 在这个例子中,CANOpen PDO的执行 — 每条消息最多八个对象(每个一字节)以及32通道7bit的PWM信号,运行在100Hz以控制LED亮度。
这还留下了40%的空余性能。
可能会要求不要完全使用XGATE的性能,因为延迟时间也很重要。在表2中所示的例子中,最长的例程运行时间为25μs。这意味着例程的最差延迟至少是25μs。由于每个例程都有优先级,所以,如果所有例程都在运行最耗时的这个例程时发生了中断,延迟是有可能更长的。因此,优先级最低的例程可能不得不等待所有其他的函数都完成了才能被分配到XGATE CPU时间。如果最低优先级任务是PWM控制例程,那它的最差延迟时间就是57μs(加和所有其他执行时间)。LED亮度控制可能能够接受这种延迟,但是不是所有功能都能忍受这种延迟的。
调试XGATE代码
所以,现在我们写好了代码并想要测试它 — 但是有两个处理器,所以怎么简单地调试呢。
S12X开发工具IDE的调试器界面可以同时展示这两个CPU的信息。听起来有很多信息,但我们可以从图10中看到,所有细节都可以列出来了。
在CodeWarrior IDE 调试器的截屏中,S12X CPU在左侧,XGATE在右侧。
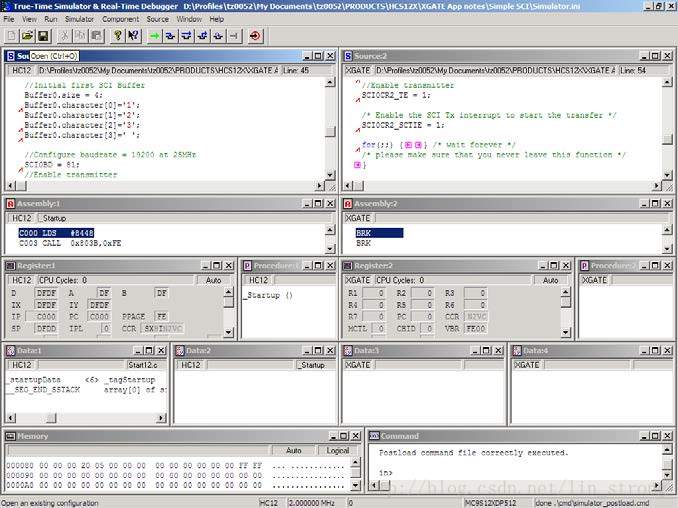
图 10.CodeWarrior IDE 调试器截屏
CodeWarrior工具与S12X的背景调试模式(BDM)会透明地处理两个处理器。XGATE的BDM接口与管理主S12X CPU的方式完全一样。因此,可以设置断点并独立地同时追踪两个处理器。
发送调试数据的数据率足够处理两个处理器了,并且还能高效地提供你开发和调试你的代码所需的所有信息。
最大化利用XGATE
XGATE最适合短小的例程,因为最初的版本在到达末尾(RTI)之前无法停止例程,除了与主CPU竞争同个内存或外设时的那个非常短的暂停。
如果我们要在XGATE上运行非常长的例程,XGATE上任何其他例程的最差延迟时间都会与最长例程的运行时间一样长。
以下示例会有所帮助…
假设XGATE上运行着一个短小的耗时80周期(1μs)的例程,它捕获四个定时器输入,还有一个AES加密算法要运行大约8000个周期(100μs)。如果AES算法不在运行,最差延迟时间是1μs(之前的中断刚发生)。然而,如果AES算法刚刚开始运行,我们必须耐心地等待100μs直到它完成,然后定时器中断才可以开始。在许多应用中,这对于系统是致命的,定时器很容易就会丢失中断(因为前一个捕获没有被置位,因此被阻塞了)。
因此,我们应该在XGATE中使用大量的短例程。
还需要考虑什么事情来让工作更高效呢?
XGATE要考虑的一个重要的时序特性是总线冲突。我们的代码在与主CPU访问同个内存地址时可能会停止数个周期。对于RAM,这是一个很短的延迟(通常),但是对于寄存器,这就重要的多了。如果CPU正在执行一个 读-修改-写 指令,如要花费主CPU五个周期的BSET指令,XGATE就得等待整个CPU指令完成。如果十分不幸地碰上了,就会导致最多10个周期的XGATE延迟。我们必须在测量XGATE性能时考虑到这个因素,因为这可能是个小概率事件,难以探测到。然而,如果XGATE的负载很高,或其他例程的可接受延迟特别小,这可能就是很重要的一件事了。
-
注意:
- 当访问端口替换寄存器时会发生多种特殊情况,XGATE在端口替换寄存器上的优先级高于CPU12X。查阅数据表来详细了解特殊地址范围上的时序是怎么受到影响的。
一个解决方案是尽可能地避免XGATE和CPU访问同样的地址。大部分功能都可以做到,但是这很容易被忽略。
现在,由于我们有一个飞快的时钟和许多逻辑操作,来谈谈能耗吧。
XGATE只在运行的时候才会有活跃的时钟。当没有活动时,XGATE只会消耗泄露电流,这与MCU的其他部分比起来很微不足道。
在执行代码时,它的电流值和MCU其他部分几乎一样,但会多出大约35%的能耗。对于在XGATE上很重的荷载,我们必须小心地确保在最差环境温度下的散热。
在XGATE上实现多个功能
理想状况下,我们尽可能全面地使用XGATE完成多个例程,但如我们所见的,有一些约束。
由于XGATE任务通常都有实时性要求,其他例程导致的延迟可以非常关键。要考虑最差情况,因为最长的延迟是很罕见的事件,在测试MCU性能时没那么容易遇见。
接下来,我们可能想要检查RAM够不够用以及对外设的访问没有冲突。
XGATE上的虚拟外设软件例程可能会频繁地使用定时器,所以为了避免寻址冲突,检查下你有没有错误地分配一个定时器到主CPU应用程序代码上。如之前讨论的,总线仲裁对代码执行有很大的影响。
考虑了所有的因素后,XGATE的平均荷载通常在40-60%这样。
哪些设备支持XGATE
现今,我们在S12X家族的MCU上支持XGATE。这个家族有着丰富的特性集,如你可在表3中的S12X家族设备清单中看到的。
表 3.S12X家族设备和他们有用的外设特性

怎么获得更多帮助和信息
有一些应用笔记能帮助你理解XGATE的典型使用。如今,主要聚焦于汽车通讯接口如CAN和LIN。但是,通用目的例程的清单在不断增长,闲着没事可以多看看Freescale的网站上有没有新的例子和应用笔记。
XGATE应用开发的应用笔记
| 应用笔记的ID | 软件的ID | 描述 |
|---|---|---|
| AN2708 | 介绍HCS12X上的外部总线接口 | |
| AN3015 | AN3015SW | 将XGATE用于曼彻斯特编码 |
| AN3144 | AN3144SW | 使用XGATE实现一个简单缓存的SCI |
| AN2726 | AN2726SW | 使用MC9S12XDP512上XGATE实现的MSCAN驱动 |
| AN2685 | 怎么配置和使用S12X设备上的XGATE | |
| AN2732 | 在HCS12X上使用XGATE实现LIN通讯 | |
| AN2734 | HCS12X家族的存储器组织结构 | |
| AN3145 | XGATE库:使用Freescale XGATE软件库 | |
| AN3219 | AN3219SW | XGATE库:TN/STN LCD驱动(使用GPIO引脚驱动裸TN和STN LCD) |
| AN3225 | AN3225SW | XGATE库:PWM驱动 |
| AN3226 | AN3226SW | XGATE库:ATD平均 |
提供帮助的网站
Freescale Semiconductor, Inc. 在其上寻找微控制器的数据手册、工具和应用笔记。
www.freescale.com/mcu
特性总结
现在正是复习我们学过的东西的时候。
- XGATE是一个I/O协处理器,可以访问与主CPU相同的外设资源。
- 对于中断,更低延迟的响应和无延迟的退出。
- XGATE必须先等待主CPU释放对地址的访问后才可以访问同个地址。
- 当用于短的例程时,XGATE可以最好地提供确定性的应用行为。
- XGATE只在运行时消耗能量。
- 许多一般运行在主CPU上的功能或例程都可以用XGATE实现,并且它还提供比单独使用S12X CPU更好的性能。
- XGATE十分地灵活,用户可以不断探索怎么使用这个低成本双处理器MCU来实现更多可能性。
鸣谢
要感谢…
Daniel Malik、Steve McAslan和Martyn Gallop对这篇文档的贡献。