李宏毅DLHLP.08.Speech Recognition.7/7. LANGUAGE MODELING
文章目录
- 介绍
- 为什么需要LM
-
- N-gram
- Challenge of N-gram
- Continuous LM
- NN-based LM
- RNN-based LM
- Use LM to improve LAS
-
- Shallow Fusion
- Deep Fusion
- Cold Fusion
介绍
本门课程是2020年李宏毅老师新课:Deep Learning for Human Language Processing(深度学习与人类语言处理)
课程网站
B站视频
公式输入请参考:在线Latex公式
本节是语音识别的最后一节,主要讲解如何将语言模型应用到语音识别上。
为什么需要LM
Language model (LM): Estimated the probability of token sequence.
• Token sequence: Y = y 1 , y 2 , . . . . . . , y n Y=y_1,y_2,......,y_n Y=y1,y2,......,yn
估测Token sequence出现的概率: P ( y 1 , y 2 , . . . . . . , y n ) P(y_1,y_2,......,y_n) P(y1,y2,......,yn)
注意这里的单位是token,一般的NLP中是用word为单位。
对于HMM
Y ∗ = a r g max Y P ( X ∣ Y ) P ( Y ) Y^*=arg\underset{Y}{\text{max}}P(X|Y)P(Y) Y∗=argYmaxP(X∣Y)P(Y)
后面那个 P ( Y ) P(Y) P(Y)就是LM
对于end-to-end的DL模型LAS来说:
Y ∗ = a r g max Y P ( Y ∣ X ) Y^*=arg\underset{Y}{\text{max}}P(Y|X) Y∗=argYmaxP(Y∣X)
从公式上看貌似不需要LM,实际上写成:
Y ∗ = a r g max Y P ( Y ∣ X ) P ( Y ) Y^*=arg\underset{Y}{\text{max}}P(Y|X)P(Y) Y∗=argYmaxP(Y∣X)P(Y)
也就是加上LM后会使得效果更加好。原因在于:LM is usually helpful when your model outputs text.
P ( Y ∣ X ) P(Y|X) P(Y∣X)通常需要成对的训练数据,比较难收集;例如:谷歌给出的文献中提到:
Words in Transcribed Audio:12,500 hours transcribed audio= 12,500 小时x 60分钟 x 130字/分钟≈1亿
P ( Y ) P(Y) P(Y)只需要有文字就可以,容易获得。Just Words,例如:BERT (一个巨大的 LM) 用了
30 亿个以上的词
下面来看如何估计 P ( y 1 , y 2 , . . . . . . , y n ) P(y_1,y_2,......,y_n) P(y1,y2,......,yn)
N-gram
Collect a large amount of text data as training data
• However, the token sequence y 1 , y 2 , . . . . . . , y n y_1,y_2,......,y_n y1,y2,......,yn may not appear in the training data. 意思就是我们的词语组合太多,有些句子的组合没有在训练数据中出现过,但是并不带代表这个句子出现的概率为0
2-gram:
P ( y 1 , y 2 , . . . . . . , y n ) = P ( y 1 ∣ B O S ) P ( y 2 ∣ y 1 ) . . . P ( y n ∣ y n − 1 ) P(y_1,y_2,......,y_n)=P(y_1|BOS)P(y_2|y_1)...P(y_n|y_{n-1}) P(y1,y2,......,yn)=P(y1∣BOS)P(y2∣y1)...P(yn∣yn−1)
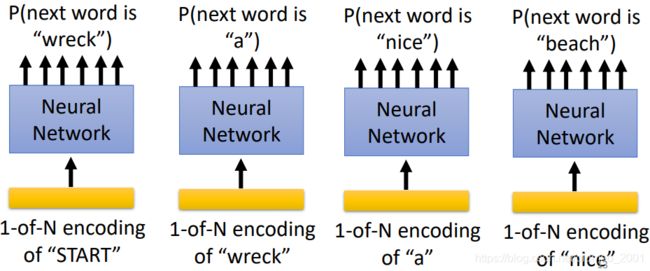
例如:
P ( “wreck a nice beach” ) = P ( w r e c k ∣ S T A R T ) P ( a ∣ w r e c k ) P ( n i c e ∣ a ) P ( b e a c h ∣ n i c e ) P(\text{“wreck a nice beach”})=P(wreck|START)P(a|wreck)P(nice|a)P(beach|nice) P(“wreck a nice beach”)=P(wreck∣START)P(a∣wreck)P(nice∣a)P(beach∣nice)
其中计算 P ( b e a c h ∣ n i c e ) P(beach|nice) P(beach∣nice)的方式为:
P ( b e a c h ∣ n i c e ) = C ( nice beach ) C ( nice ) P(beach|nice)=\cfrac{C(\text{nice beach})}{C(\text{nice})} P(beach∣nice)=C(nice)C(nice beach)
分子是【nice beach】出现的次数,分母是【nice】出现的次数。
• It is easy to generalize to 3-gram, 4-gram ……
Challenge of N-gram
这里很简单,不解释
The estimated probability is not accurate.
• Especially when we consider n-gram with large n
• Because of data sparsity (many n-grams never appear in training data)

改进就是:
Continuous LM
这个东西借鉴了推荐系统中的思路,例如下图中ABCDE五个用户分别有对4个动漫有打分,那么可以根据其他用户的打分和本身打分的特征推断一些空白位置的分数(可以用Matrix Factorization):
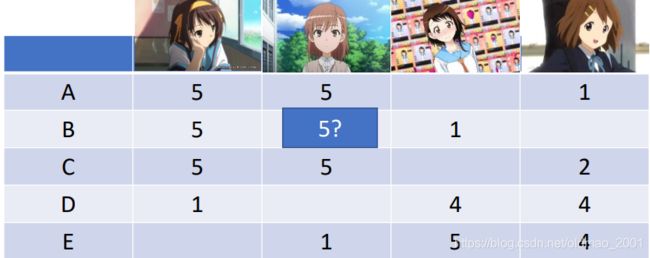
把这个思想引入到LM上,创建一张表格列举出每个词(第一行)后面跟另外一个词(第一列)在语料库出现过次数(中间的数字),0代表在语料库没有出现过这个组合,但是并不代表这个组合出现的几率为0
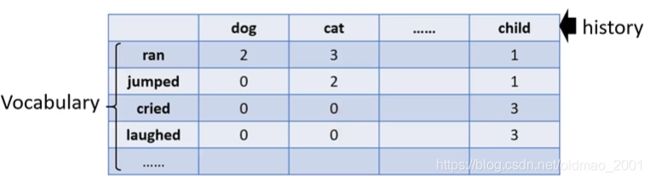
现在我们分别用向量h和v表示第一行和第一列的词的属性

这两组向量是从上面的表格中估算出来的,步骤如下:
用 n i j n_{ij} nij表示第i个词后面接第j个词的次数,我们要学习 v i , v j v^i,v^j vi,vj,并假定:
n 12 = v 1 ⋅ h 2 n 21 = v v ⋅ h 1 ⋯ n_{12}=v^1\cdot h^2\\ n_{21}=v^v\cdot h^1\cdots n12=v1⋅h2n21=vv⋅h1⋯
那么就可以写出损失函数:
L = ∑ ( i , j ) ( v i ⋅ h j − n i j ) 2 L=\sum_{(i,j)}(v^i\cdot h^j-n_{ij})^2 L=(i,j)∑(vi⋅hj−nij)2
v i , v j v^i,v^j vi,vj found by gradient descent
然后就可以有如下操作:
History “dog” and “cat” can have similar vector h d o g h^{dog} hdog and h c a t h^{cat} hcat.
If v j u m p e d ⋅ h c a t v^{jumped}\cdot h^{cat} vjumped⋅hcat is large, v j u m p e d ⋅ h d o g v^{jumped}\cdot h^{dog} vjumped⋅hdog would be large accordingly.
Smoothing is automatically done.
其实Continuous LM可以看做是只有一个隐藏层的NN的简化版本。
输入是独热编码,下面例子是橙色向量,表示只有狗这个单词,然后中间是要学习的蓝色 h d o g h^{dog} hdog 向量,它和绿色的单词向量相乘得到的结果要和ground truth越接近越好。

因此,在这个上面进行扩展,就得到:
NN-based LM
其训练过程就是先收集数据:

然后就根据数据Learn to predict the next word:
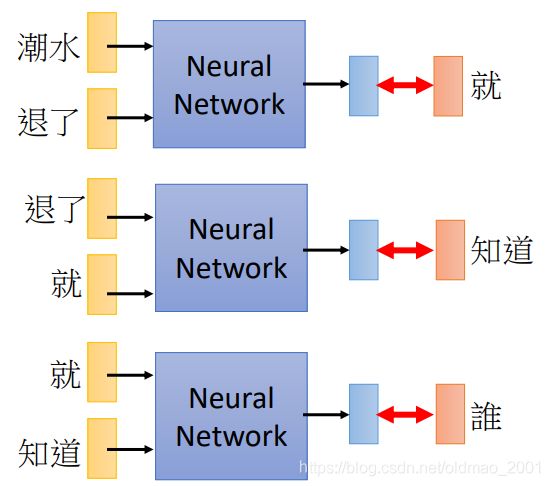
回到前面那个例子就是:
P(“wreck a nice beach”)=P(wreck|START)P(a|wreck)P(nice|a)P(beach|nice)
P(b|a): the probability of NN predicting the next word.
当然最早把NN用于LM的还是大佬Bengio,具体可以参考相关论文,李老师提到说这个论文的实验在当时算力很难实现,但是现在已经可以很容易实现。

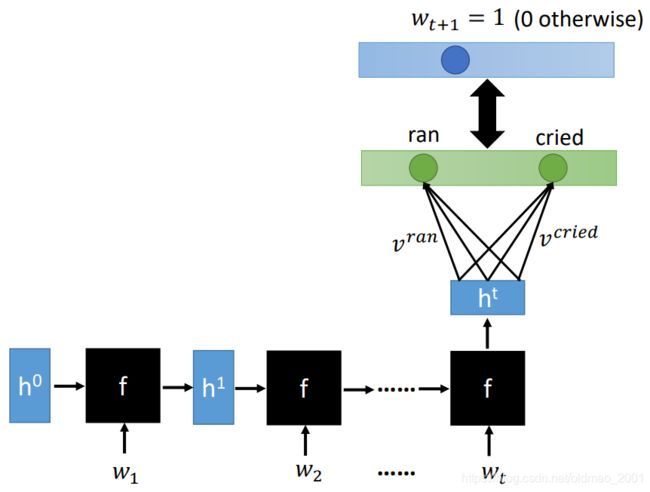
RNN-based LM
If we use 1-of-N encoding to represent the history, history cannot be very long.
由于输入的句子长度各种不一样,因此使用普通的NN模型无法很好处理这种变长的输入,因此就有了基于RNN的LM
Use LM to improve LAS
可以把LM和DL的模型结合分为三种情况,具体看下面表格:

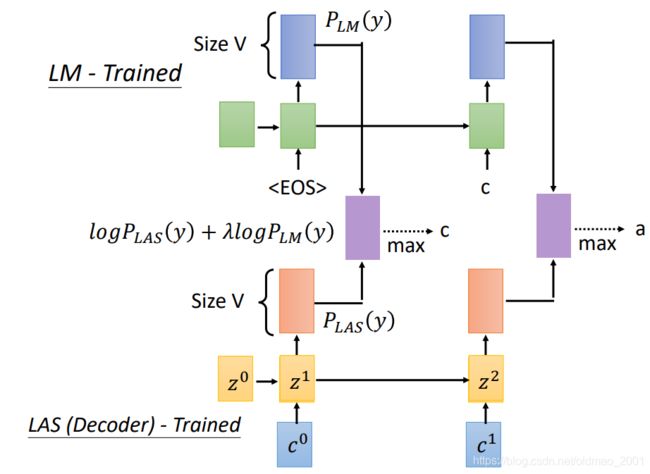
Shallow Fusion
[Kannan, et al., ICASSP’18]
有两个模型LM和LAS,都是训练好的,然后把两个模型的输出的两个概率分布取log后按权重(用来调整是哪个模型所占比重更大一些)相加。然后再从结果中取最大(当然也可以用Beam Search)的结果作为token
Deep Fusion
[Gulcehre, et al., arXiv’15]
把两个模型LM和LAS(都是训练好的)的隐藏层拉出来,丢到一个network(灰色那个),再由network输出概率分布。
灰色那个network还需要进行再一次训练
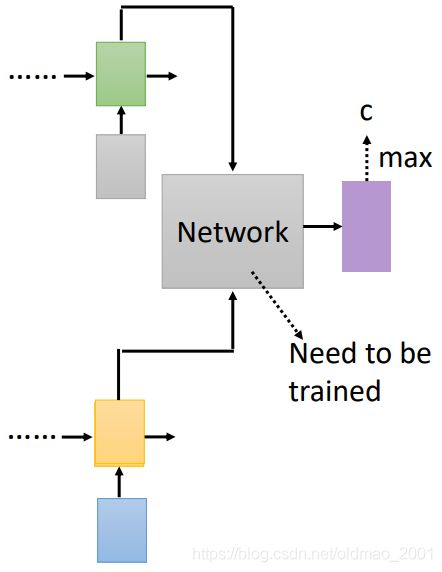
但是这里有一个地方要注意,就是当我们需要换LM的时候,需要重新训练灰色那个模块:

为什么需要换LM?
应为每个语料都有应用范围,例如计算机类的术语和普通术语不一样,老师举例:
程式和城市发音一样,但是一个是计算机用语(台湾的程序的说法),一个是普通术语。
在不同领域进行识别的时候就要切换LM,否则可能识别不准确。
如果不想更换LM后重新训练network模块,那么就不要抽取模型的隐藏层,而是抽取softmax前的一层,这一层的大小是和输入向量大小size一样,因为在不同LM中,不同中间的隐藏层每个维度代表的含义可能是不一样的,但是不同LM的最后一层因为要接入softmax的同一个维度含义肯定都一样,而且大小都一样。
当然这样做还是有一个缺点就是词表很大的时候V就很大,接入softmax的维度就很大,计算量比较大。
还有一点这里的LM可以用传统的N-GRAM模型也可以,因为N-GRAM模型也可以生成词表大小的概率分布。
Cold Fusion
[Sriram, et al., INTERSPEECH’18]

这个模式先训练好LM,LAS是还没有训练,是和灰色模块一起训练的,这个模型可以加快LAS的收敛速度。因为语言顺序部分已经有LM来搞定了,LAS只用关注语音对应词部分即可,所以收敛速度快。
缺点是不能随便换LM,换LM要重新训练LAS。