YOLOv5利用ncnn部署系列(三)
五、pc端使用C++调用ncnn
由于有很多人再问一个输出层对不上的bug问题,在此我在开头重点提点,请各位大佬仔细看好我的标红字体!!!!!!!!
由于yolov5转ncnn不包括后处理部分,因此在c++的代码里需要重构整个后处理部分,不多说,直接上代码了:
cmake_minimum_required(VERSION 3.17)
project(yolov5s)
find_package(OpenCV REQUIRED core highgui imgproc)
#这里链接的时编译后的ncnn的include和lib文件夹,根据自己的路径去更改
include_directories(./CLion-2020.2/clion-2020.2/ncnn-master/build/install/include/ncnn)
link_directories(./CLion-2020.2/clion-2020.2/ncnn-master/build/install/lib)
find_package(ncnn)
FIND_PACKAGE( OpenMP REQUIRED)
if (OPENMP_FOUND)
message("OPENMAP FOUND")
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} ${OpenMP_C_FLAGS}")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${OpenMP_CXX_FLAGS}")
set(CMAKE_EXE_LINKER_FLAGS "${CMAKE_EXE_LINKER_FLAGS} ${OpenMP_EXE_LINKER_FLAGS}")
endif()
project(yolov5s)
set(CMAKE_CXX_STANDARD 14)
set(CMAKE_BUILD_TYPE Debug)
add_executable(yolov5s yolov5.cpp)
target_link_libraries(yolov5s ncnn ${
OpenCV_LIBS})
这部分代码时cmakelist里的,大家可以参考着去配置cmake!!
接下来是头文件.h的代码:
#ifndef YOLO_V5_H
#define YOLO_V5_H
#include "net.h"
#include 这一个文件是一个.h文件,主要是定义一些结构体和类,供cpp里调用,这里面需要注意几个点,如下图:
 这里的input_size要设置为640,即onnx模型输入的两倍,具体为啥不清楚,反正设置为320后了效果会有偏差! 这里这三个输出层的名称,每个人转出来都不太一样,需要自己的情况去改,这三个名字怎么找,在ncnn的官方git社区里有一个netron的可视化工具可以直接看转换后onnx模型的结构,里面可以找到这三个输出层的名称,传送门:netron可视化网络结构
这里的input_size要设置为640,即onnx模型输入的两倍,具体为啥不清楚,反正设置为320后了效果会有偏差! 这里这三个输出层的名称,每个人转出来都不太一样,需要自己的情况去改,这三个名字怎么找,在ncnn的官方git社区里有一个netron的可视化工具可以直接看转换后onnx模型的结构,里面可以找到这三个输出层的名称,传送门:netron可视化网络结构
接下来是cpp的代码:
#include "yolov5.h"
#include
//printf("[grid size=%d, stride = %d]x y w h %f %f %f %f\n",grid_size,stride,record[0],record[1],record[2],record[3]);
BoxInfo box;
box.x1 = std::max(0,std::min(frame_size.width,int((cx - w / 2.f) * (float)frame_size.width / (float)net_size))); //左上角坐标
box.y1 = std::max(0,std::min(frame_size.height,int((cy - h / 2.f) * (float)frame_size.height / (float)net_size)));
box.x2 = std::max(0,std::min(frame_size.width,int((cx + w / 2.f) * (float)frame_size.width / (float)net_size))); //右下角坐标
box.y2 = std::max(0,std::min(frame_size.height,int((cy + h / 2.f) * (float)frame_size.height / (float)net_size)));
box.score = score;
box.label = cls;
result.push_back(box);
}
}
}
for(auto& ptr:mat_data){
ptr+=(num_classes + 5);
}
}
}
return result;
}
void Yolov5Detector::Nms(std::vector<BoxInfo> &input_boxes, float nms_thresh) {
std::sort(input_boxes.begin(), input_boxes.end(), [](BoxInfo a, BoxInfo b){
return a.score > b.score;});
std::vector<float>vArea(input_boxes.size()); //定义box面积容器
for (int i = 0; i < int(input_boxes.size()); ++i) //遍历所有的box
{
vArea[i] = (input_boxes.at(i).x2 - input_boxes.at(i).x1 + 1) //计算面积(x2-x1)×(y2-y1)
* (input_boxes.at(i).y2 - input_boxes.at(i).y1 + 1);
}
for (int i = 0; i < int(input_boxes.size()); ++i) //遍历所有的面积
{
for (int j = i + 1; j < int(input_boxes.size());)
{
float xx1 = std::max(input_boxes[i].x1, input_boxes[j].x1); //求解两个box相交处的左上角坐标
float yy1 = std::max(input_boxes[i].y1, input_boxes[j].y1);
float xx2 = std::min(input_boxes[i].x2, input_boxes[j].x2); //求解两个box相交处的右下角坐标
float yy2 = std::min(input_boxes[i].y2, input_boxes[j].y2);
float w = std::max(float(0), xx2 - xx1 + 1); //计算相交矩形的宽
float h = std::max(float(0), yy2 - yy1 + 1); //计算相交矩形的高
float inter = w * h; //计算相交矩形的面积
float ovr = inter / (vArea[i] + vArea[j] - inter); //overlap
if (ovr >= nms_thresh)
{
input_boxes.erase(input_boxes.begin() + j); //若overlap大于阈值,删除该box
vArea.erase(vArea.begin() + j); //若overlap大于阈值,删除该面积
}
else
{
j++;
}
}
}
}
int main()
{
//cv::VideoCapture cap;
const char *yolov5_param = "/home/zhangyi/CLionProjects/yolov5s/last_500_320.param";
const char *yolov5_bin = "/home/zhangyi/CLionProjects/yolov5s/last_500_320.bin";
float nms_threshold = 0.4;
float threshold = 0.3;
Yolov5Detector ret(yolov5_param, yolov5_bin);
/*****************************************将预测结果写入txt中*************************************************************/
// std::vector filename;
// cv::String folder = "/home/zhangyi/CLionProjects/yolov5s/img_val";
// cv::glob(folder, filename);
// std::ofstream out("out.txt");
// for(size_t i=0; i
// {
// std::cout << filename[i] << std::endl;
// cv::Mat frame = cv::imread(filename[i]);
// std::vector result = ret.Detect(frame, threshold, nms_threshold);
//
// std::ofstream write("out.txt", std::ios::app);
// out << filename[i] << " ";
// for(int j=0; j
// {
// const auto obj = result[j];
// //std::ofstream write("out.txt", std::ios::app);
// std::cout << obj.x1 << "," << obj.y1 << "," << obj.x2 << "," << obj.y2 << "," << obj.label << "\n";
// out << obj.score << "," << obj.x1 << "," << obj.y1 << "," << obj.x2 << "," << obj.y2 << "," << obj.label << " ";
// }
// //std::ofstream write("out.txt", std::ios::app);
// out << "\n";
// }
/*****************************************************************************************************/
cv::Mat frame;
const char *img_path = "/home/zhangyi/CLionProjects/yolov5s/img_val/2008_000243.jpg";
std::cout << img_path << std::endl;
cv::Mat img = cv::imread(img_path, 1);
frame = cv::imread(img_path, 1);
std::vector<BoxInfo> result = ret.Detect(frame, threshold, nms_threshold);
/*画图部分*/
for(int i=0; i<result.size(); i++)
{
const auto obj = result[i];
fprintf(stderr, "%d = %.5f at %.2f %.2f %.2f x %.2f\n", obj.label, obj.score,
obj.x1, obj.y1, obj.x2, obj.y2);
cv::rectangle(frame, cvPoint(obj.x1, obj.y1), cvPoint(obj.x2, obj.y2), cv::Scalar(255, 0, 0));
char text[256];
static const char* labels[] = {
"person", "aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair",
"cow", "diningtable", "dog", "horse", "motorbike", "pottedplant", "sheep", "sofa", "train", "tvmonitor"};
sprintf(text, "%s %.1f%%", labels[obj.label], obj.score * 100);
int baseLine = 0;
cv::Size label_size = cv::getTextSize(text, cv::FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
int x = obj.x1;
int y = obj.y1 - label_size.height - baseLine;
if (y < 0)
y = 0;
if (x + label_size.width > frame.cols)
x = frame.cols - label_size.width;
cv::rectangle(frame, cv::Rect(cv::Point(x, y), cv::Size(label_size.width, label_size.height + baseLine)),
cv::Scalar(255, 255, 255), -1);
cv::putText(frame, text, cv::Point(x, y + label_size.height),
cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 0, 0));
}
cv::imshow("image", frame);
cv::waitKey(0);
return 0;
}
这里面也有个地方需要注意,如下:
 因为.h文件里设置输入size为640,而转出的ncnn模型接受输入为320,所以这里需要除以2!
因为.h文件里设置输入size为640,而转出的ncnn模型接受输入为320,所以这里需要除以2!
其中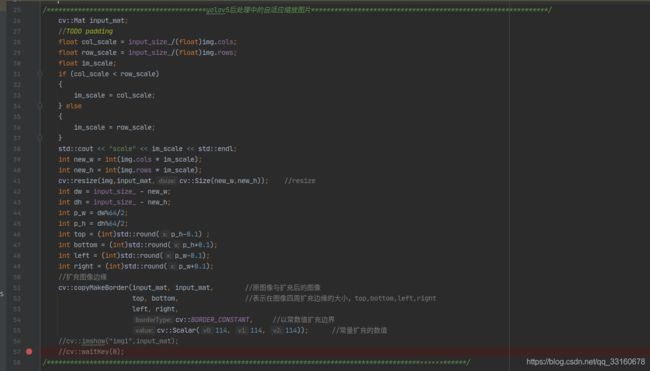 这块的代码是yolov5中后处理中加入的自适应图片缩放机制,具yolov5的paper说这个操作可以提速30%,在这里也会对ncnn模型的精度有影响,加了这个能提高map2.5个点!
这块的代码是yolov5中后处理中加入的自适应图片缩放机制,具yolov5的paper说这个操作可以提速30%,在这里也会对ncnn模型的精度有影响,加了这个能提高map2.5个点!
 这一部分代码是对测试集进行测试,将结果写入一个txt文本中,然后去测试map,因为map计算以python版本居多,我嫌麻烦,没有复写c++版的,有兴趣可以直接写一个c++版的测试map代码,直接在c++里测试即可!
这一部分代码是对测试集进行测试,将结果写入一个txt文本中,然后去测试map,因为map计算以python版本居多,我嫌麻烦,没有复写c++版的,有兴趣可以直接写一个c++版的测试map代码,直接在c++里测试即可!
这部分想要测试map的时候把这部分注释打开,然后这部分以下的代码注释掉就ok!
六、ncnn的map测试
对于转ncnn后测试map指标不是一个很好的选择,我只是想与之前的pt模型做一下对比,才搞了这么一个测试,很多测试指标都是看预测的tensor与原tensor之间查了几位小数来做测试指标!
上一节已经将测试集的测试结果保存为txt文本了,这时将结果拿到pycharm中进行map测试!
由于我使用的是voc数据集,voc计算map的开源代码有很多,搜一搜就有,里面需要将某一类的结果先提取出来保存为单独一个txt文本,所以最后一共有20个txt文本,分别时20类目标的预测结果,下面是这一步骤的代码:
import os
def file_name(file_dir):
with open("val.txt", 'w') as f:
for root, dirs, files in os.walk(file_dir):
for file in files:
img_name = file.split(".")[0]
f.write(img_name)
f.write("\n")
def cls_pred_file(pred_file):
with open(pred_file) as f:
lines = f.readlines()
classes_name = ["person", "aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair",
"cow", "diningtable", "dog", "horse", "motorbike", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
for cls in classes_name:
with open("./datasets/score/pred_out/%s.txt"%cls, 'w') as F:
print("Writing %s.txt"%cls)
for line in lines:
img_name = line.strip().split(" ")[0]
objects = line.strip().split(" ")[1:]
for i in range(len(objects)):
score = objects[i].split(",")[0]
x1 = objects[i].split(",")[1]
y1 = objects[i].split(",")[2]
x2 = objects[i].split(",")[3]
y2 = objects[i].split(",")[4]
label = int(objects[i].split(",")[5])
if classes_name[label] == cls:
F.write(img_name + " " + score + " " + x1 + " " + y1 + " " + x2 + " " + y2)
F.write("\n")
print("%s.txt is done!"%cls)
if __name__ == "__main__":
#file_name("./datasets/score/labels/val")
cls_pred_file("./out.txt")
这里就生成了20类目标的预测结果,接下来就是测试map的过程了,代码如下:
# --------------------------------------------------------
# Fast/er R-CNN
# Licensed under The MIT License [see LICENSE for details]
# Written by Bharath Hariharan
# --------------------------------------------------------
import xml.etree.ElementTree as ET
import os
import _pickle as cPickle
import numpy as np
def parse_rec(filename): # 通过ET解析xml后返回一个obj
""" Parse a PASCAL VOC xml file """
tree = ET.parse(filename)
objects = []
# 解析xml文件,将GT框信息放入一个列表
for obj in tree.findall('object'):
obj_struct = {
}
obj_struct['name'] = obj.find('name').text
obj_struct['pose'] = obj.find('pose').text
obj_struct['truncated'] = int(obj.find('truncated').text)
obj_struct['difficult'] = int(obj.find('difficult').text)
bbox = obj.find('bndbox')
obj_struct['bbox'] = [int(bbox.find('xmin').text),
int(bbox.find('ymin').text),
int(bbox.find('xmax').text),
int(bbox.find('ymax').text)]
objects.append(obj_struct)
return objects
def voc_ap(rec, prec, use_07_metric=False):
""" ap = voc_ap(rec, prec, [use_07_metric])
Compute VOC AP given precision and recall.
If use_07_metric is true, uses the
VOC 07 11 point method (default:False).
"""
if use_07_metric:
# 11 point metric
ap = 0.
for t in np.arange(0., 1.1, 0.1):
if np.sum(rec >= t) == 0:
p = 0
else:
p = np.max(prec[rec >= t])
ap = ap + p / 11.
else:
# correct AP calculation
# first append sentinel values at the end
mrec = np.concatenate(([0.], rec, [1.]))
mpre = np.concatenate(([0.], prec, [0.]))
# compute the precision envelope
for i in range(mpre.size - 1, 0, -1):
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
# to calculate area under PR curve, look for points
# where X axis (recall) changes value
i = np.where(mrec[1:] != mrec[:-1])[0]
# and sum (\Delta recall) * prec
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
return ap
def voc_eval(detpath,
annopath,
imagesetfile,
classname,
cachedir,
ovthresh=0.2,
use_07_metric=False):
"""rec, prec, ap = voc_eval(detpath,
annopath,
imagesetfile,
classname,
[ovthresh],
[use_07_metric])
Top level function that does the PASCAL VOC evaluation.
detpath: Path to detections
detpath.format(classname) should produce the detection results file.
annopath: Path to annotations
annopath.format(imagename) should be the xml annotations file.
imagesetfile: Text file containing the list of images, one image per line.
classname: Category name (duh)
cachedir: Directory for caching the annotations
[ovthresh]: Overlap threshold (default = 0.5)
[use_07_metric]: Whether to use VOC07's 11 point AP computation
(default False)
"""
# assumes detections are in detpath.format(classname)
# assumes annotations are in annopath.format(imagename)
# assumes imagesetfile is a text file with each line an image name 默认txt中是无后缀imgName
# cachedir caches the annotations in a pickle file
# first load gt
if not os.path.isdir(cachedir):
os.mkdir(cachedir) # 若无pkl文件的路径,生成cachedir路径
cachefile = os.path.join(cachedir, 'annots.pkl')
# read list of images
with open(imagesetfile, 'r') as f:
lines = f.readlines()
imagenames = [x.strip() for x in lines] # imagenames为所有imgName的list
if not os.path.isfile(cachefile): # cache路径下无pkl
# load annots
recs = {
} # recs是一个dict,以imagename为key,解析xml后的obj为value,详情见下两句
for i, imagename in enumerate(imagenames):
# imagename = imagename.split(' ')[0]
recs[imagename] = parse_rec(annopath.format(imagename)) # 依次写入format上imagename的xml路径到resc列表
if i % 100 == 0:
print('Reading annotation for {:d}/{:d}'.format(i + 1, len(imagenames))) # 显示进程
# save
print('Saving cached annotations to {:s}'.format(cachefile))
with open(cachefile, 'wb') as f:
cPickle.dump(recs, f) # 将resc列表中的内容写入pkl
else:
# load
with open(cachefile, 'rb') as f:
recs = cPickle.load(f) # 若存在pkl,直接load到recs
# extract gt objects for this class
class_recs = {
}
npos = 0
for imagename in imagenames:
R = [obj for obj in recs[imagename] if obj['name'] == classname] # 除去recs中其他类别
bbox = np.array([x['bbox'] for x in R])
difficult = np.array([x['difficult'] for x in R]).astype(np.bool)
det = [False] * len(R)
npos = npos + sum(~difficult)
class_recs[imagename] = {
'bbox': bbox,
'difficult': difficult,
'det': det}
# read dets
detfile = detpath.format(classname)
with open(detfile, 'rb') as f: # 读批量验证的结果txt文件
lines = f.readlines()
splitlines = [x.decode().strip().split(' ') for x in lines] # split对txt每一行的数据做分割
image_ids = [x[0] for x in splitlines]
confidence = np.array([float(x[1]) for x in splitlines])
BB = np.array([[float(z) for z in x[2:]] for x in splitlines])
# sort by confidence
sorted_ind = np.argsort(-confidence)
sorted_scores = np.sort(-confidence)
BB = BB[sorted_ind, :]
image_ids = [image_ids[x] for x in sorted_ind]
# go down dets and mark TPs and FPs 以下为计算对比各参数
nd = len(image_ids)
tp = np.zeros(nd)
fp = np.zeros(nd)
for d in range(nd):
R = class_recs[image_ids[d]]
bb = BB[d, :].astype(float)
ovmax = -np.inf
BBGT = R['bbox'].astype(float)
if BBGT.size > 0:
# compute overlaps
# intersection
ixmin = np.maximum(BBGT[:, 0], bb[0])
iymin = np.maximum(BBGT[:, 1], bb[1])
ixmax = np.minimum(BBGT[:, 2], bb[2])
iymax = np.minimum(BBGT[:, 3], bb[3])
iw = np.maximum(ixmax - ixmin + 1., 0.)
ih = np.maximum(iymax - iymin + 1., 0.)
inters = iw * ih
# union
uni = ((bb[2] - bb[0] + 1.) * (bb[3] - bb[1] + 1.) +
(BBGT[:, 2] - BBGT[:, 0] + 1.) *
(BBGT[:, 3] - BBGT[:, 1] + 1.) - inters)
overlaps = inters / uni
ovmax = np.max(overlaps)
jmax = np.argmax(overlaps)
if ovmax > ovthresh:
if not R['difficult'][jmax]:
if not R['det'][jmax]:
tp[d] = 1.
R['det'][jmax] = 1
else:
fp[d] = 1.
else:
fp[d] = 1.
# compute precision recall
fp = np.cumsum(fp)
tp = np.cumsum(tp)
rec = tp / float(npos)
# avoid divide by zero in case the first detection matches a difficult
# ground truth
prec = tp / np.maximum(tp + fp, np.finfo(np.float64).eps)
ap = voc_ap(rec, prec, use_07_metric)
return rec, prec, ap
if __name__ == "__main__":
results_path = "./datasets/score/detection"
cls_result = os.listdir(results_path)
AP = []
for i in range(len(cls_result)):
class_name = cls_result[i].split(".txt")[0]
rec, prec, ap = voc_eval("./datasets/score/pred_out/{}.txt",
"./datasets/score/Annotations/{}.xml",
"./val.txt",
class_name,
'.')
print("{} :\t {}".format(class_name, ap))
AP.append(ap)
#map = sum(AP)/len(AP)
map = tuple(AP)
print("***************************")
print("mAP :\t {}".format(float(sum(map) / len(map))))
最终的测试结果,ncnn的map在46.8,原torch模型的精度在(一)里面已经说过了,为51.5,转为ncnn后map掉了4.7个点,这个误差还是蛮大的,但是看了很多大佬的结果,意思好像是掉不了这么多点,里面的原因就不得而知了!可能是本人后处理部分写的有问题,也可能是模型训练的时候迭代次数不够,这个torch模型从头只迭代了500个epoch,具体什么原因不知道,有知道的大佬,欢迎指点迷津啊!
最后放上ncnn的测试结果图:
 这与torch模型测试得是同一张图,大家可以对比一下!
这与torch模型测试得是同一张图,大家可以对比一下!
好了,到这里yolov5转ncnn就结束了,希望对大家能有帮助,毕竟里面的坑太多!!!!