python async socket_Python异步IO实现全过程(2)

生成器中异步IO的起源
之前,你看到了基于生成器的旧式风格的协程示例,虽然它已经被更为明确的原生协程所取代,但是还是值得回顾一下:
可以实验一下,如果你只纯粹的调用 py34_core() 或者 py35_core() 而不使用 await, 或者不调用 asyncio.run() 方法或其他高级函数,运行结果会怎样?单独调用一个协程会返回一个协程对象:
![]()
这表面上看起来有些无趣,协程调用的结果是一个协程对象。
一个小测验:Python还有哪些功能和这个比较像?(Python的什么功能是自身被调用的时候实际却“没做什么”?)
希望你能想到生成器作为答案,因为协程是在生成器之上做了一些增强扩展,其中还有一些行为是类似的:
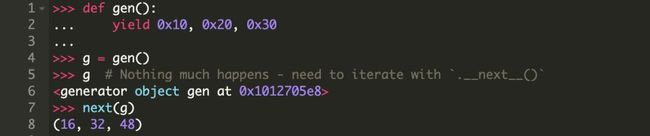
事实证明,异步IO的基础是生成器函数(无论是使用 async 还是旧式的 @asyncio.coroutine 声明协程)。从技术上讲,相比于 yield,await 更接近于 yield from。(但是有一点要记住,yield from 仅仅是用来替换 for i in x(): yield i 的语法糖。)
为什么生成器适合用来实现异步IO,就是它可以随意的停止和重启。例如,你可以在迭代一个生成器对象时暂停,然后在迭代器剩余的值上恢复迭代。当一个生成器函数运行到 yield 时,它会抛出这个值,然后将处于空闲状态,直到需要抛出新的值。
可以通过一个例子加深理解:
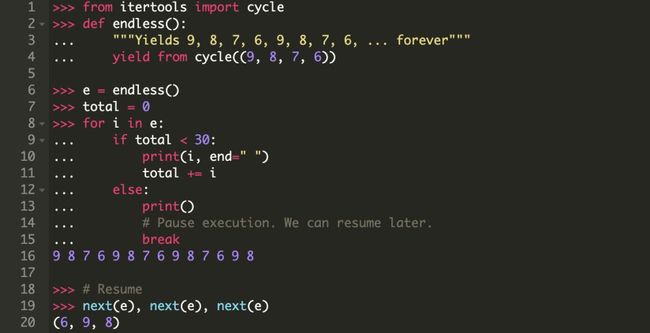
关键字 await 与之行为类似,在协程自身被挂起并告知其他协程开始工作的时候会标记一个断点。这里的”挂起“是指暂时交出控制权限,但却不是完全退出或结束。记住,yield,以及拓展出的 yield from 和 await 都会在协程执行的时候标记一个断点。
这是函数与生成器之间的根本区别。函数是要么都执行,要么都不执行。函数一旦开始执行,除非是遇到 return,否则不会停止,然后将值返回并推给调用方(函数的调用者)。与之相对,生成器每当遇到 yield 都会暂停不在运行,它不仅可以将值返回给调用堆栈,还可以在使用 next() 恢复调用时保留其中的局部变量。
生成器的另一个少为人知的重要功能。你可以通过 .send() 向生成器中发送一个值,这就允许生成器(以及协程)调用(await)其他方法而不会阻塞。我不会深入探究这个功能实现的细节,因为它主要是为了在幕后实现协程,你不需要也不应该直接使用这种方式。
如果你有兴趣了解更多内容,可以看一看PEP 342,Python从PEP 342开始正式引入了协程。Brett Cannon 的Python中async-await工作原理也值得一读,还有PYMOTW对asyncio的评述。最后,还有 David Beazley 的协程与并发的探讨,深入探讨了关于协程运行的机制。
将上面的文章精简成几句话:协程通过一种非常规的机制运行,当协程调用 .send() 时,返回的结果是调用返回时抛出的异常对象的属性。这些还有一些更复杂的细节,但是对于实践却没有什么帮助,我们继续讲下面的。
为了方便总结,这里列出了一些协程作为生成器的关键点:
1. 协程是根据生成器方法的高级特性并重新规划后的方法
2. 旧式的基于生成器的协程使用 yield from 等待协程的结果。新式的Python语法中原生协程只是将等待协程结果的方式,由 yield from 替换为 await。await 与 yield from 用法比较像,而且理解起来也是如此。
3. await 的作用是标记一个断点信号,它允许协程暂时停止执行并允许程序稍后再回到这里执行。
其他功能:async for ,异步生成器和异步推导式
Python还与 async/await 一起发布了 async for,用来支持迭代一个 异步迭代器 。使用异步迭代器的目的是在迭代器进行迭代的时候可以分阶段调用异步代码。
这个概念是由 异步生成器 引申出来的。回顾一下,原生协程中可以使用 await,return 或者 yield。Python 3.6(通过PEP 525)引入了异步生成器,开始允许在协程中使用 yield,目的是在函数体中允许同时使用 await和 yield

后,还有一点很重要,Python允许使用 async for 创建异步推导式。与其它异步特性一样,也是一个比较好用的语法糖:
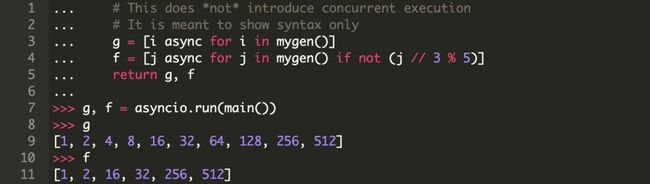
与协程相比,有一个明显的区别:无论是异步生成器还是异步推导式都不会并发迭代。它们所做的只是提供了一个异步形式的观感,但是在循环问题中却能够放弃对时间循环的控制,并运行其他协程。
换句话说,异步迭代器和异步生成器不是为了并发的映射序列或者迭代器而设计的,它们只是为了让封闭的协程可以允许其他任务轮流调用。async for 和 async with 语句仅在 for 或 with 会”破坏“ await 原生协程时才需要。这是一个需要掌握的异步与并发的区别。
事件循环和 asyncio.run()
你可以将事件循环看作一个监控协程的 while True 循环,获取协程被闲置期间的反馈,以及可以在此期间执行的内容。它可以在处于等待态的协程可用时唤起闲置协程。
到目前为止,事件循环的整个管理过程由一个函数调用隐式处理:
![]()
在Python 3.7中引入的 asyncio.run() 负责获取事件循环,在任务被标记完成前运行任务,然后关闭事件循环。
使用 get_event_loop() 管理 asyncio 事件循环还有一种更为繁复的方式,典型的示例如下所示:

可能经常在旧的示例中看到 loop.get_event_loop(),但是除非你需要对事件循环进行精细的控制,使用 asyncio.run() 应该足以满足大多数程序的需要。
如果你需要在Python程序中与事件循环交互,那么旧式风格的 loop 是一个不错的选择,它支持使用 loop.is_running() 和 loop.is_closed() 进行自省。如果需要获得更精细的控制也可以进行操作,例如通过循环参数传递来 调度回调函数。
更重要的是理解事件循环的底层实现机制,这里有几点关于事件循环需要强调的:
#1:协程在与事件循环绑定之前不会自行处理。
你已经在关于生成器的解释中看到过这一点,但是这仍值得重申一遍。如果有一个需要等待其它协程的主协程,那么简单的单独调用它几乎没有效果:
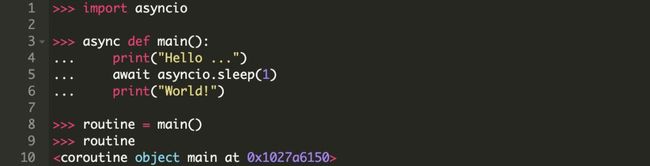
记住,在调度 main() 协程(future对象)时使用 asyncio.run() 会真正强制执行事件循环。

(其它协程可以通过 await 执行,通常会在 asyncio.run() 中包装 main() 函数,然后在这里使用 await 调用链式协程。)
#2:默认情况下,一个异步IO事件循环会运行在单核CPU的单线程中,通常,单核CPU运行一个单线程的事件循环是绰绰有余的。跨多核运行事件循环也是可行的。更多信息可以参考 John Reese 的演讲,同时要关注你的笔记本可能会超负荷运载转。
#3:事件循环是可插拔的。就是说,如果你想,你可以实现自己的事件循环并执行相同的任务。CPython实现的 uvloop 包就很好的说明了这一点。
”可插拔式事件循环“可以可以理解为:你可以使用任何可用的事件循环的实现,这与协程本身的结构无关。asyncio 包自带了两个不同的事件循环实现,默认实现基于 selectors 模块。(第二种实现仅适用于Windows系统。)
一个完整的程序:异步请求
到了现在,是时候做一些有趣且没有痛点的部分了。在本节中,你将使用 aiohttp 构建一个基于URL的网页抓取收集器 areq.py。这是一个非常快的C/S(客户端/服务器)框架。(我们只需要使用客户端部分。)这样的工具可以映射网站集群之间的链接关系,并形成有向图。
----------
注:你可能想知道Python中的 requests 包与异步IO为什么不兼容。实际上 requests 是建立在 urllib3 之上的,而 urllib3 又使用Python的 http 和套接字 socket 模块。
默认情况下,套接字操作是阻塞的。这意味着Python不会使用 await requests.get(url),因为 .get() 不是可等待的。相比之下,aiohttp 模块中几乎所有内容都是一个可等待的协程。例如 session.request() 和 response.text()。requests 是一个不错的包,只要你不使用它写异步代码。
----------
比较有水平的程序结构就像下面这样:
1. 从本地文件 urls.txt 读取URL序列。
2. 根据这些URL发送GET请求并解码相应结果内容,如果请求失败,则停止当前的URL请求。
3. 搜索响应结果中 href 标签中的URL信息。
4. 将结果写入 foundurls.txt。
5. 尽可能使用异步和并发的方式执行上述操作。(使用 aiohttp 发送请求,使用 aiofiles 写入文件。这是IO操作的两个主要示例,非常适合异步IO模型。)
以下是 urls.txt 中的内容,数量不多,但是大多是包含大量访问流量的网站:
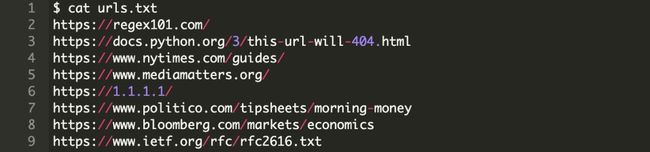
表中的第二个URL返回一个404响应信息,你需要优雅的处理它。如果你正在运行本程序的扩展版本,你可能需要处理比这更多的事情,比如服务器断开连接或无限重定向。
请求本身使用单个会话进行,以便重用会话内部的连接池。
我们来看看完整的程序,并在稍后逐步说明
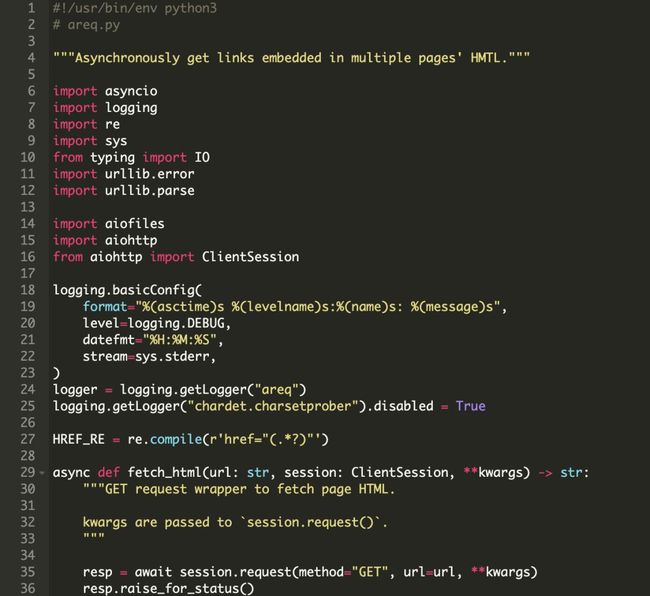
这个脚本远比我们最初的示例脚本要长,所以要将它分解开。
常量 HREF_RE 是一个正则表达式,用于提取我们最终想要搜索的,HTML中有 href 标记的内容。
![]()
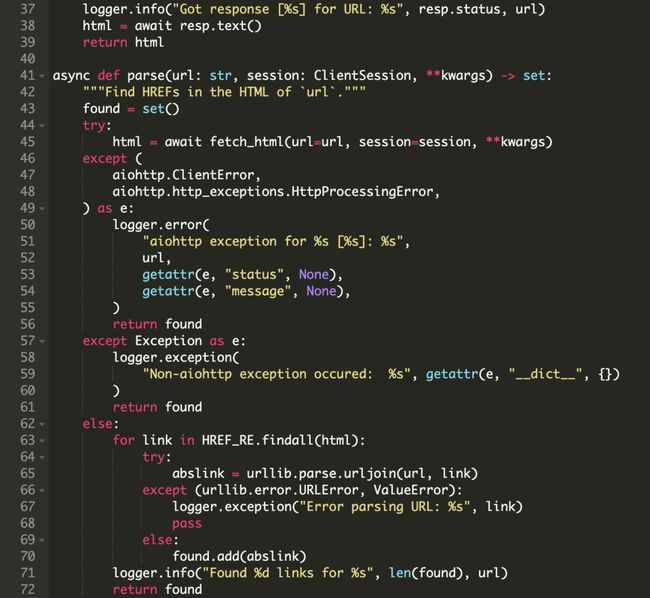
协程 fetch_html() 包装了一个 GET 请求,用于发起请求并解析生成页面的HTML文本。它会在发起请求后等待响应,并在非200状态时立即抛出。
![]()
如果状态正常,则 fetch_html() 返回一个HTML页面的字符串。注意,这个功能没有做任何异常处理,逻辑是将异常传递给调用者,并让调用者来处理。
![]()
我们使用 await session.request() 和 resp.text(),因为他们都是可等待的协程。否则,一个请求/响应周期将成为应用程序尾大不掉的部分。但是,fetch_html() 使用异步IO允许事件循环执行其它可用的任务,例如解析和写入已经获取到的URL。
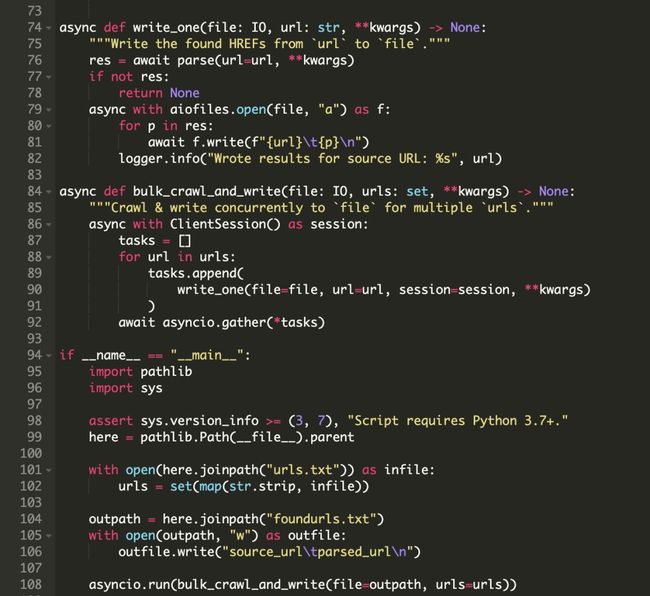
程序中的下一部分是 parse(),它会等待 fetch_html() 获取到给定URL的响应信息,然后从页面的HTML中解析所有的 href 标签中的URL链接,确保将每个可用的链接都被格式化为绝对路径。
不可否认,parse() 协程的后半部分是阻塞的,但是它包含一个高效匹配的正则表达式,并确保检索到的链接转成绝对路径。
在这种特定情况下,这里的同步代码应该是运行快速且不显眼。但还是要记住,给定协程中的任何一行代码都会阻塞其他协程,除非这一行使用了 yield,await 或 return。如果解析是是一个操作更复杂的过程,你可能需要考虑使用 loop.run_in_executor() 并在其自带的进程中运行这部分。
接下来,write() 协程接受一个文件对象以及一个URL,并等待 parse() 返回一组解析后的URL,通过使用一个操作异步文件IO的包 aiofiles 将每一个URL与其源URL异步地写入文件。
最后,bulk_crawl_and_write() 作为整个脚本中协程链的主要入口,它使用单个会话,并为最终从 urls.txt 文件中取出的URL创建请求任务。
还有几点值得提一下:
1. ClientSession 默认具有一个最多可以有100连接的适配器。如果需要修改它,需要将 asyncio.connector.TCPConnector 的实例传给 ClientSession。你还可以为每一个主机单独指定限制。
2. 你可以为整个会话以及单个请求指定最大超时时间。
3. 这个脚本还使用了 async with, 配合异步上下文管理器一起。因为从同步到异步的上下文管理器的转换非常简单,我们这里不对这个概念作专门的讨论。后者只需要定义 .__aenter__() 和 .__aexit__() 而非 .__exit__()和 .__enter__()。如你所料, async with 只能用于声明了 async def 的协程中。
如果你还想了解更多,Github上面有本教程相应的脚本文件,并且附有注释和文档描述。
下面欣赏一下执行结果,areq.py 在一秒内完成响应获取,解析,并保存9个URL的响应结果。
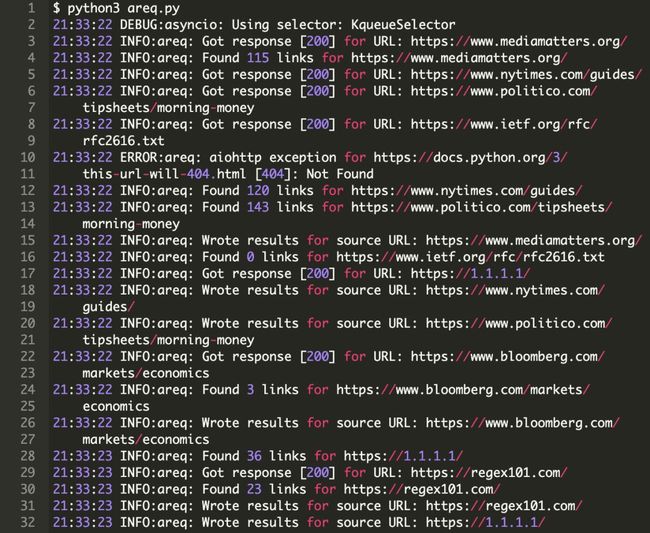
这并不算太简陋。你可以检查输出的行数作为完整性检查,我运行的结果是626行,但它是有可能会有波动的。

后续步骤:如果你想增加抓取的深度,可以将这个网页爬虫进行递归。可以使用 aio-redis 跟踪URL的爬取树,以避免重复请求,并使用Python的 networkx 库进行链接。
还要记得一点,向一个毫无防备的小型网站发送1000个并发请求是极不可取的。有一些可以限制你在批量发送请求时的并发数的方法,如使用 asyncio 的 sempahore对象 或是其他类似的模式。如果你忽略这个警告,你可能会遇到大量的 TimeoutError 异常,并最终会损坏你的程序。
上下文中的异步IO
现在你已经看到了一份比较有效的代码,我们先退一步考虑,什么时候使用异步IO是比较理想的选择,以及如何进行比较并做出决定或选择另一种不同的并发模型。
何时以及为何异步IO会是正确的选择?
本教程不对异步IO,线程与多进程作扩展论述。但是,了解异步IO何时在三者中最为适合是很有用的。
异步IO与多进程之间不存在竞争。事实上,它们可以一起使用。如果你有多个十分一致的计算密集型任务(比如scikit-learn 或 keras 库中的网格搜索),多进程会是一个更好的选择。
如果所有的函数都使用阻塞调用,那么在每个函数之前简单的设置 async 体验并不好。(实际上这有可能会降低代码运行速度。)但结合前文,在某些地方结合使用异步IO和多进程可以协调的更好。
异步IO和线程之间竞争更直接一些。我在介绍中提到”线程很难“,完整的说法是,即使在线程容易实现的情况下,由于竞争条件以及内存使用等原因,它仍然可能导致出现无法跟踪的错误,以及其它的东西。
线程也比异步IO更难扩展,因为线程是系统内有限的可用性资源。在许多机器上创建数千个线程会出现错误,我不建议优先尝试使用它。而创建数千个异步IO任务是完全可行的。
当你有多个I/O密集型任务时,异步IO会交替执行,否则会受制于I/O密集型任务阻塞的时间。比如:
1. 网络IO,不论是程序的客户端还是服务端
2. 无服务设计,例如点对点,聊天室中的多用户网络
3. 读/写操作,你想模仿一个”发出后不管“的风格策略,但却仍然持有对内容的读或写锁定
不使用 await 最大的原因是它仅支持定义了一组特定方法的特定对象集。如果需要对某个DBMS(数据库管理系统)执行异步读取操作,你不仅需要针对该DBMS的Python封装方法,还需要方法支持 async/await 语法。含有同步调用的协程会阻塞其他协程和任务的运行。
有关使用 async/await 的库的列表,请参阅本教程末尾的列表。
异步IO究竟是什么?
本教程重点介绍了异步IO,async/await 语法,以及使用 asyncio 进行事件循环管理和指定任务。当然,asyncio 不是唯一的异步IO库。在 Nathaniel J. Smith 的演讲中还讲了其它的一些东西:
----------
近几年,不难发现 asyncio 已经像 urllib2 一样慢慢成为资深开发者避免使用的标准库。
实际上我想说的是,asyncio 成功的背后也导致了一些失败的设计:当它开始被设计时,它是最好的的方法;但之后,受到 asyncio 的启发,加入了如 async/await 的语法,我们可以在原有的基础上做的更好,而 asyncio 仍受到早期设计的限制。(资源)
----------
至此,尽管还有一些知名的 asyncio 的替代方案,如 curio 和 trio,都有不同的API及方法。但就我个人而言,如果你正在构建的是一个中等规模的简单程序,只需要使用 asyncio 就足够了,而且比较容易理解。这也避免了在使用Python标准库之外又增加其他的依赖库。
但无论如何,可以了解一下 curio 和 trio,你可能会发现它们完成任务的方式可能对用户更直观。这里介绍的无关乎包的概念也应该归入到异步IO包的备选中。
英文原文:https://realpython.com/async-io-python/
译者:冰川