Spark机器学习的三剑客:RDD、DataFrame和Dataset API
Spark有效处理大规模数据的3个主要工具是RDD、DataFrame和Dataset API。虽然每个API都有自己的优点,但新范式转变支持Dataset作为统一数据API,以满足在单个界面中所有数据处理需求。
新的Spark 2.0 Dataset API是一个类型安全的领域对象集合,可以使用函数运算或关系操作方式执行(类似于RDD的filter、map和flatMap()等)并行转换。为了向后兼容,Dataset有一个称为DataFrame的视图,它是无类型的行集合。在本章中,我们将演示3个API集。图3-1总结了Spark用于数据处理的关键组件的优缺点。
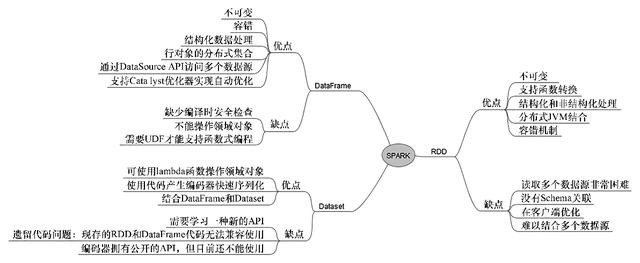
图3-1
由于算法扩充或历史遗留原因,机器学习的高级开发人员必须理解并能够使用所有3个API而不会出现任何问题。尽管我们建议每个开发人员都应该迁移到高级的Dataset API,但你仍需要知道对Spark核心系统如何使用RDD编程。例如,投资银行和对冲基金通常会阅读机器学习、数学规划、金融、统计或人工智能等领先期刊,然后在低级API中编写代码以获得竞争优势。
3.1.1 RDD—— 一切是从什么开始
RDD API是Spark开发人员需要使用的一个关键工具包,它同时提供了对数据的低层次控制和函数式编程范式。RDD的强大之处也让许多新程序员难以使用。尽管RDD API和手动优化技术比较容易理解,但是编写高质量代码仍需要经过长期练习。
当数据文件、块或数据结构转换为RDD时,数据被拆分为许多称为“分区”的更小单元(类似于Hadoop中的分裂),并分布在大量节点之上,使得它们可以同时并行操作。对于大规模数据,Spark目前已经提供了很多功能,开发人员无须任何额外的编码。该框架将处理所有细节,开发人员可以专注于编写代码而无须担心数据。
如果想要更好地理解RDD底层的精巧和优美,必须查阅RDD的原始论文,这是掌握这一内容最好的办法。
Spark中有许多可用的RDD类型,可以简化编程。图3-2描述RDD的部分分类情况。建议Spark程序员至少知道现有的RDD类型,哪怕是RandomRDD、VertexRDD、HadoopRDD、JdbcRDD和UnionRDD等这些鲜为人知的RDD,以避免不必要的编码问题。

图3-2
3.1.2 DataFrame——使用高级API统一API和SQL的自然演变
从伯克利的AMPlab实验室时代开始,Spark开发人员社区一直致力于为社区提供易于使用的高级API。当Michael Armbrust向社区提供SparkSQL和Catalyst优化器时,数据API的下一次演变开始具体化,该优化器使用简单且易于理解的SQL接口使Spark能够实现数据可视化。DataFrame API是一种自然演变,通过将数据组织成列(例如关系表)的形式来使用SparkSQL。
DataFrame API使用SQL进行数据处理,可供众多熟悉R(data.frame)或Python/Pandas(pandas.DataFrame)中的DataFrame的数据科学家和开发人员使用。
3.1.3 Dataset—— 一个高级的统一数据API
Dataset是一个不可变的对象集合,被建模/映射到传统的关系模式。作为未来的首选方法,有4个属性用以区分。我们特别发现Dataset API很有吸引力,因为它的用法与RDD常用的转换运算符(例如filter()、map()、flatMap()等)很相似。Dataset将遵循类似于RDD的惰性执行范式。一种统一DataFrame和Dataset的最佳方法是将DataFrame视作Dataset [Row]的别名。
1.强类型安全
统一的Dataset API中同时具备编译时(语法错误)和运行时安全特性,这不仅可以给机器学习开发人员在开发期间提供帮助,还可以在运行时防止发生意外。开发人员采用Scala或Python使用DataFrame或RDD Lambda,在遇到意外运行时错误(数据存在缺陷)时将会更好地理解和欣赏Spark社区和Databricks的这一新贡献。
2.Tungsten内存管理
Tungsten让Spark将硬件性能压榨到极限(即利用sun.misc.Unsafe接口)。编码器将JVM对象映射到表格格式(请参见图3-3)。如果使用Dataset API,Spark会将JVM对象映射到内部Tungsten堆外二进制格式,这样更有效。虽然Tungsten内部的细节超出了机器学习手册的范围,但基准测试显示使用堆外内存管理比JVM对象更有效。值得一提的是,堆外内存管理的概念在用于Spark之前,就一直是Apache Flink固有的。Spark 1.4、1.5、1.6到现在的Spark 2.0,Spark开发人员已经意识到Tungsten项目的重要性。尽管我们强调DataFrame在编写时会受到支持,并且已经有详细介绍(大多数生产系统仍然是Spark 2.0之前的版本),但我们鼓励你开始探索和思考Dataset范式。图3-3显示了RDD、DataFrame和Dataset如何与Tungsten项目演变的路线图。
3.编码器
编码器是Spark 2.0中序列化和反序列化(也就是SerDe)的框架。编码器能无缝地处理JVM对象到表格格式的映射,通过编码器可以获取底层信息,并根据需要进行修改(专家级别)。
与标准Java序列化和其他序列化方案(例如Kryo)不同,Spark编码器不使用运行时反射来检测内部对象进行实时序列化。相反,Spark的编译器代码在编译期间生成,并编译为指定对象的字节码,这使得序列化和反序列化对象的操作更快。内部对象的运行时反射机制(例如查找字段及格式)会导致额外的开销,这种机制不存在于Spark 2.0中。但是如有需要,Kryo、标准Java序列化或任何其他序列化技术仍然可以作为一种配置选择(极端示例和向后兼容)。

图3-3
标准数据类型和对象(由标准数据类型组成)的编码器目前已经可以在Tungsten中使用。使用一个快速非正式的程序基准,和编码器相比,采用Kryo序列化机制来回反复序列化对象(Hadoop MapReduce开发人员的流行做法)有4~8倍的效率提升。当深入查看源代码时,却发现编码器实际上使用运行时代码生成(在字节码级别)来打包和解包对象。为了完整起见,你只需要知道Spark编码器生成的对象大小似乎更小,但进一步的细节以及原因解释已经超出了本书的范围。
Encoder[T]是构成Dataset[T]的一个内部组件,仅仅是一个记录模式。如果有需要,你可以使用基本数据元组(例如Long、Double和Int)自定义编码器。在开始自定义编码器之前(例如在 Dataset[T]中存储自定义对象),请确保已经查看 Spark 源代码目录中的Encoders.scala和SQLImplicits.scala文件。在Spark的计划和战略方向中,会在将来版本中提供公共API。
4.友好的Catalyst优化器
使用Catalyst可以将API动作转换为catalog表示(用户自定义函数)的逻辑查询计划,逻辑查询计划转换为物理计划,这种方式比使用原始模式更有效(即使在filter()之前放置groupBy(),Catalyst可以聪明到将前面2个函数调换位置)。更清晰的解释请参考图3-4。

图3-4
对于使用Spark 2.0以前版本的用户需要注意以下几点。
- SparkSession 现在是系统的单一入口点,SQLContext 和 HiveContext 已经被SparkSession取代。
- 对于Java用户,请确保将DataFrame替换为Dataset< Row >。
- 通过SparkSession使用新的catalog接口来执行cacheTable()、dropTempView()、createExternalTable()、ListTable()等。
- 对于DataFrame和Dataset API有:unionALL()已经被抛弃,现在应该使用union();explode()应该替换为functions.explode()和select()或flatMap();registerTempTable已经被弃用,并替换为createOrReplaceTempView()。
本文摘自《Spark机器学习实战》

提供Apache,Spark机器学习API的全面解决方案,步骤清晰,讲解细致,帮助读者学习实用的机器学习算法,并用Spark快速动手实践
本书提供了Apache Spark机器学习API的全面解决方案,不仅介绍了用Spark完成机器学习任务所需的基础知识,也涉及一些Spark机器学习的高级技能。全书共有13章,从环境配置讲起,陆续介绍了线性代数库、数据处理机制、构建机器学习系统的常见攻略、回归和分类、用Spark实现推荐引擎、无监督学习、梯度下降算法、决策树和集成模型、数据降维、文本分析和Spark Steaming的使用。
本书是为那些掌握了机器学习技术的Scala开发人员准备的,尤其适合缺乏Spark实践经验的读者。本书假定读者已经掌握机器学习算法的基础知识,并且具有使用Scala实现机器学习算法的一些实践经验。但不要求读者提前了解Spark ML库及其生态系统。