python数据分析————数据聚合与分组运算
-
分组:使用特定的条件将原数据划分为多个组
-
聚合:对每个分组中的数据执行某些操作,最后将计算的结果进行整合
整个过程就是拆分(split)—应用(apply)—合并(combine)的过程
数据分组
-
groupby方法:将数据集按某些标准划分成若干组, 返 回 一 个 新 的 G r o u p B y 对 象 \color{red}{返回一个新的GroupBy对象} 返回一个新的GroupBy对象
| groupby方法参数 | 说明 |
|---|---|
| by | 用于确定进行分组的依据 |
| axis | 表示分组轴的方向 |
| sort | 是否对分组标签进行排序,默认True |
通过Series对象进行分组
data = pd.DataFrame({
'k1':['one','two','two','one'],
'k2':['first','second','first','second'],
'data1':[1,2,3,4],'data2':[5,6,7,8]})
# 单键分组
grouped1 = data['data1'].groupby(data['k1'])
grouped2 = data.groupby(data['k1'])
# 多键分组
means = data['data1'].groupby([data['k1'], data['k2']]).mean()
# 任意Series分组
grouped3 = data['data1'].groupby(pd.Series(['a','a','b','a']))
我们可以看到,他返回的是一个GroupBy对象,而且根据被分组的类型来区分
# 输出
print(type(grouped1))
<class 'pandas.core.groupby.generic.SeriesGroupBy'>
print(type(grouped2))
<class 'pandas.core.groupby.generic.DataFrameGroupBy'>
print(grouped1)
<pandas.core.groupby.generic.SeriesGroupBy object at 0x000002A1B1D24AF0>
如果我们直接输出,出来的其实是一个地址,如果想让它输出内容的话可以使用如下方法
# 输出
print(tuple(grouped1))
print(list(grouped1))
[('one', 0 1
3 4
Name: data1, dtype: int64),
('two', 1 2
2 3
Name: data1, dtype: int64)]
数据应用
# 求每个组的均值
print(grouped1.mean())
k1
one 2.5
two 2.5
Name: data1, dtype: float64
通过列名进行分组
print(list(data.groupby('k1')))
[('one', k1 k2 data1 data2
0 one first 1 5
3 one second 4 8),
('two', k1 k2 data1 data2
1 two second 2 6
2 two first 3 7)]
print(list(data.groupby(['k1','k2'])))
[(('one', 'first'),
k1 k2 data1 data2
0 one first 1 5),
(('one', 'second'),
k1 k2 data1 data2
3 one second 4 8),
(('two', 'first'),
k1 k2 data1 data2
2 two first 3 7),
(('two', 'second'),
k1 k2 data1 data2
1 two second 2 6)]
分组对象
# 多键分组的遍历方式
for (k1, k2), group in data.groupby(['k1', 'k2']):
print(k1, k2)
print(group)
# 聚合一列
print(list(data.groupby('k1')['data2']))
print(list(data['data2'].groupby(data['k1'])))
通过字典进行分组
data = pd.DataFrame({
'a':range(0,5),'b':range(5,10),
'c':range(10,15),'d':range(15,20)})
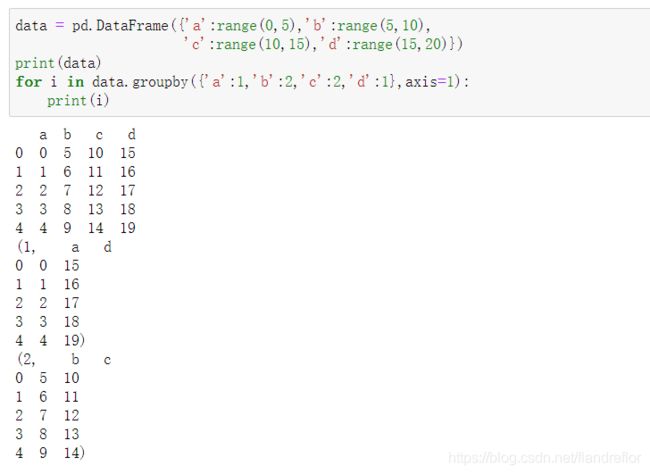
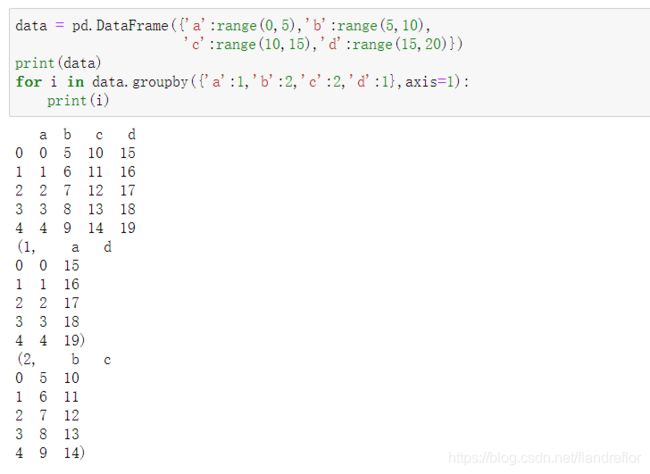
for i in data.groupby({
'a':1,'b':2,'c':2,'d':1},axis=1):
print(i)
通过函数进行分组
data = pd.DataFrame({
'a': [1, 2, 3, 4],'b': [5, 6, 7, 8],
'c': [9, 10, 11, 12]},index=['first', 'second', 'third', 'fourth'])
for group in data.groupby(len):
print(group)
数据聚合
使用内置统计方法聚合
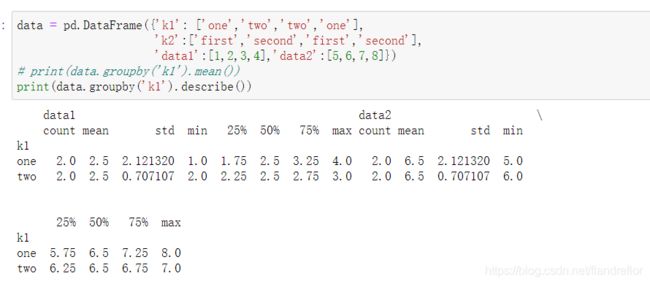
data = pd.DataFrame({
'k1': ['one','two','two','one'],
'k2':['first','second','first','second'],
'data1':[1,2,3,4],'data2':[5,6,7,8]})
print(data.groupby('k1').mean())
data1 data2
k1
one 2.5 6.5
two 2.5 6.5
print(data.groupby('k1').sum())
data1 data2
k1
one 5 13
two 5 13
面向列的聚合
-
agg方法可以传入自定义函数来实现Pandas对象的聚合运算
| agg | 说明 |
|---|---|
| func | 用于汇总数据的函数 |
| axis | 作用轴的方向,默认是0或index(列) |
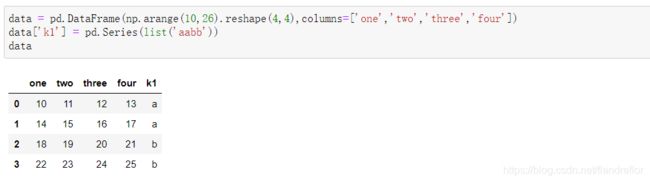
data = pd.DataFrame(np.arange(10,26).reshape(4,4),columns=['one','two','three','four'])
data['k1'] = pd.Series(list('aabb'))
# print(data)
data_group = data.groupby('k1')
for k,da_ta in data_group:
print(k)
print(da_ta)

# 调用自定义函数来实现agg聚合
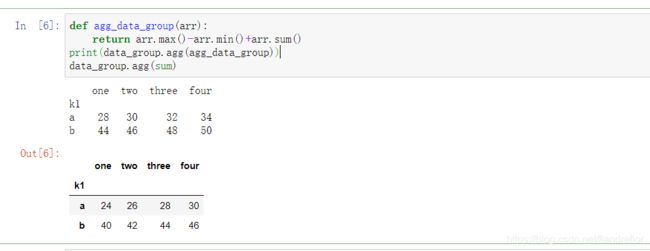
def agg_data_group(arr):
return arr.max()-arr.min()+arr.sum()
print(data_group.agg(agg_data_group))
# 直接内置函数实现聚合
print(data_group.agg(sum))
多函数聚合
-
对一列应用多个函数聚合
print(data_group.agg([agg_data_group,sum]))
print(data_group.agg([agg_data_group,"sum"]))

print(data_group.agg([('极差和',agg_data_group),('和',"sum")]))

-
对不同列数据分别应用不同函数
print(data_group.agg({
'one':agg_data_group,'two':'sum','three':'mean','four':'max'}))

分组运算
数据转换transform
-
transfm方法将聚合后的结果应用到分组的每一条数据中,使与原数据集的形状保持相同
- transf()方法会把func函数应用到分组中,若聚合结果为标量,则将标量广播到分组;若聚合结果与分组大小相同,则使用聚合结果
data = pd.DataFrame(np.arange(36).reshape((6, 6)),
columns=list('ABCDEF'))
data['key'] = pd.Series(list('aaabbb'), name='key')
# print(data)


数据应用apply
-
apply方法应用到GroupBy对象上,可以在许多标准用例中替代聚合和转换
-
apply(func,axis=0)
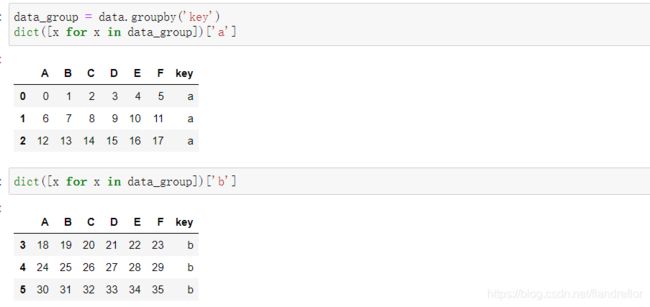
data_group = data.groupby('key')
print(dict([x for x in data_group])['a'])
print(dict([x for x in data_group])['b'])
# 代替聚合
print(data_group.apply(max))
